最近无论是斯坦福机器人炒虾,还是特斯拉官宣机器人进厂,都赚足了眼球,实力证明了具身智能的火爆。
先不说具身智能是实现AGI的关键环节,也是未来研究的重要方向,我们就从发论文的角度来看,今年的各大顶会,比如CVPR,具身智能就排了热门研究领域前三,可见入局具身智能早已成了必然趋势。
目前具身智能主要四个研究目标:具身感知、具身互动、具身智能体、虚拟到现实。如果大家想冲顶会,建议从这四个角度入手,我这边也整理了20篇具身智能顶会开源论文给各位参考,都是2024年最新,包括CVPR、ECCV、ICML等。
另外我还准备了40多个具身智能经典数据集,以及规模达到三百万的具身大规模数据集,帮大家搞定数据太贵/不够的问题。
论文原文+开源代码需要的同学看文末
具身感知
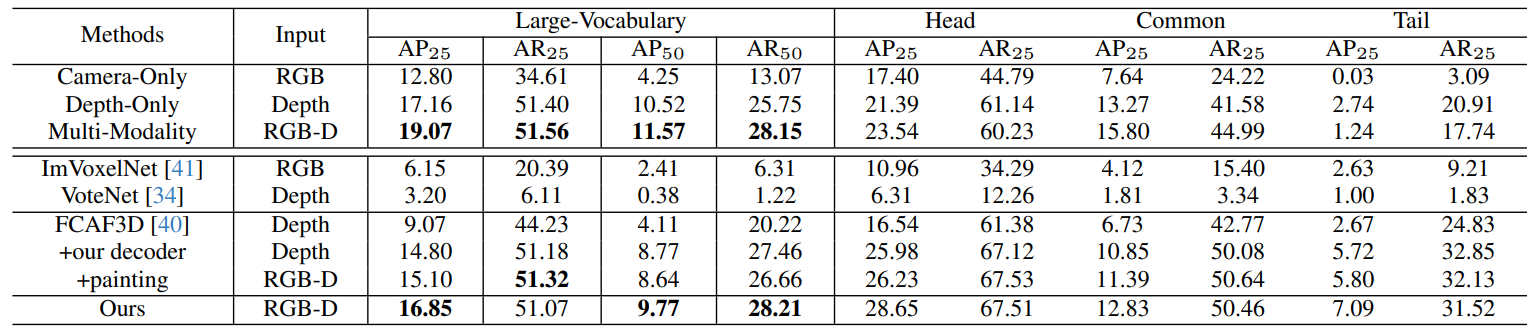
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai
方法:EmbodiedScan是一个新的多模态3D感知数据集,提供了丰富的室内场景注释,支持自我中心视角下的语言基础的全面3D场景理解。基于此数据集,论文提出了Embodied Perceptron框架,用于处理多视图输入,并在3D感知和语言基础任务上表现出色。
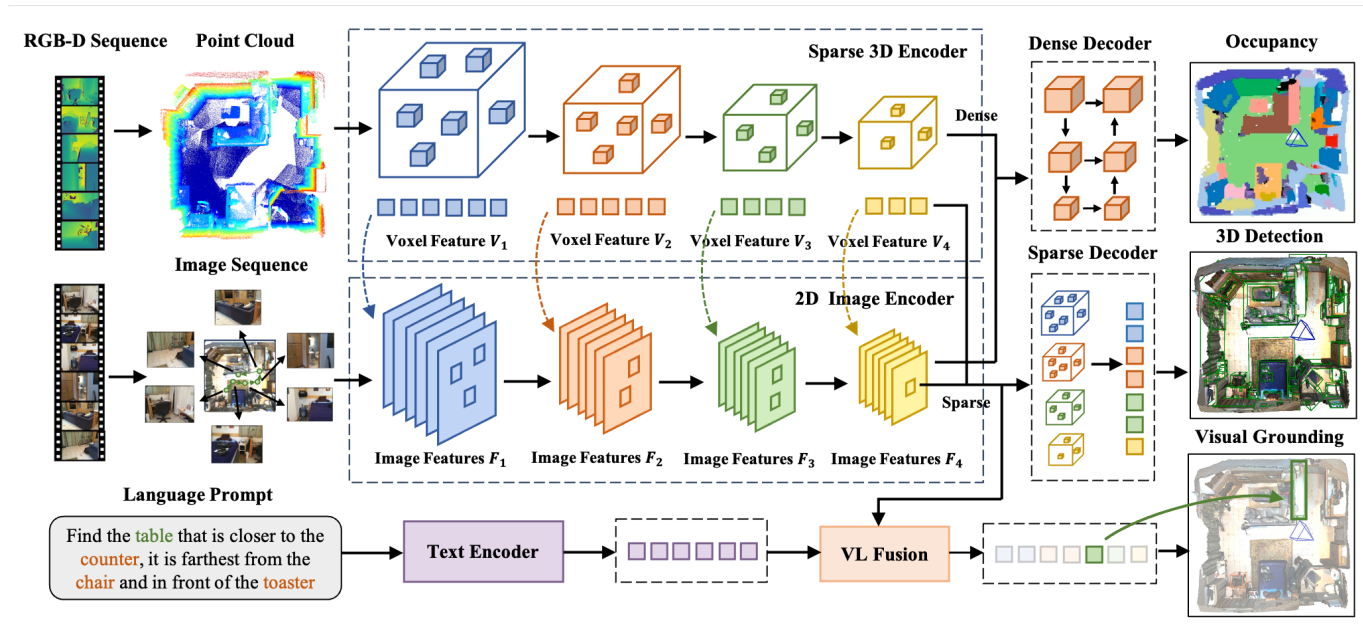
创新点:
-
EmbodiedScan:从自我中心视图实现基于语言的整体三维场景理解的多模态感知套件。
-
基于一个大规模的数据集,提出了一个基准框架,能够处理任意数量的视图输入,使用统一的多模态编码器和任务特定的解码器。
具身交互
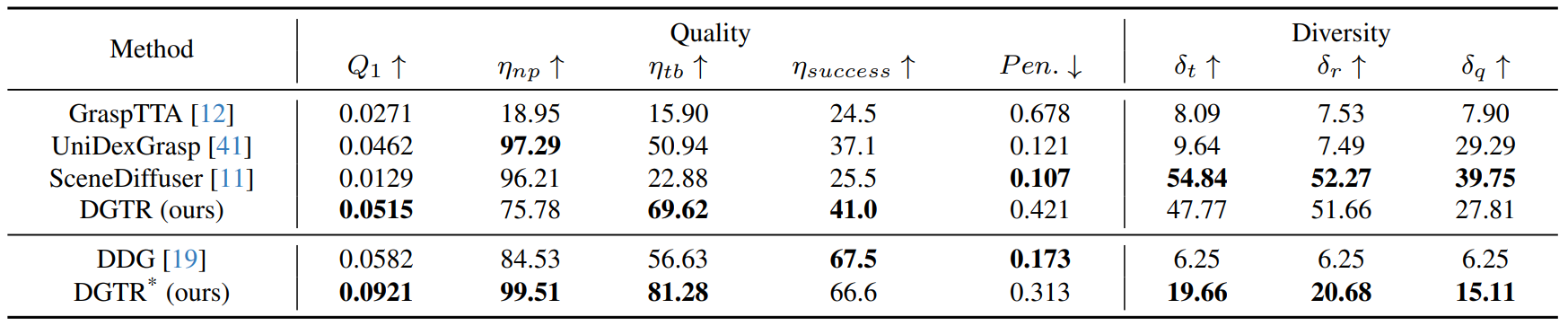
Dexterous Grasp Transformer
方法:论文提出了一种名为Dexterous Grasp Transformer(DGTR)的新框架,用于生成灵巧抓取姿势。DGTR利用transformer解码器和可学习的抓取查询,仅通过一次前向传播就能从物体的点云中预测出多样化的可行抓取姿势集合。
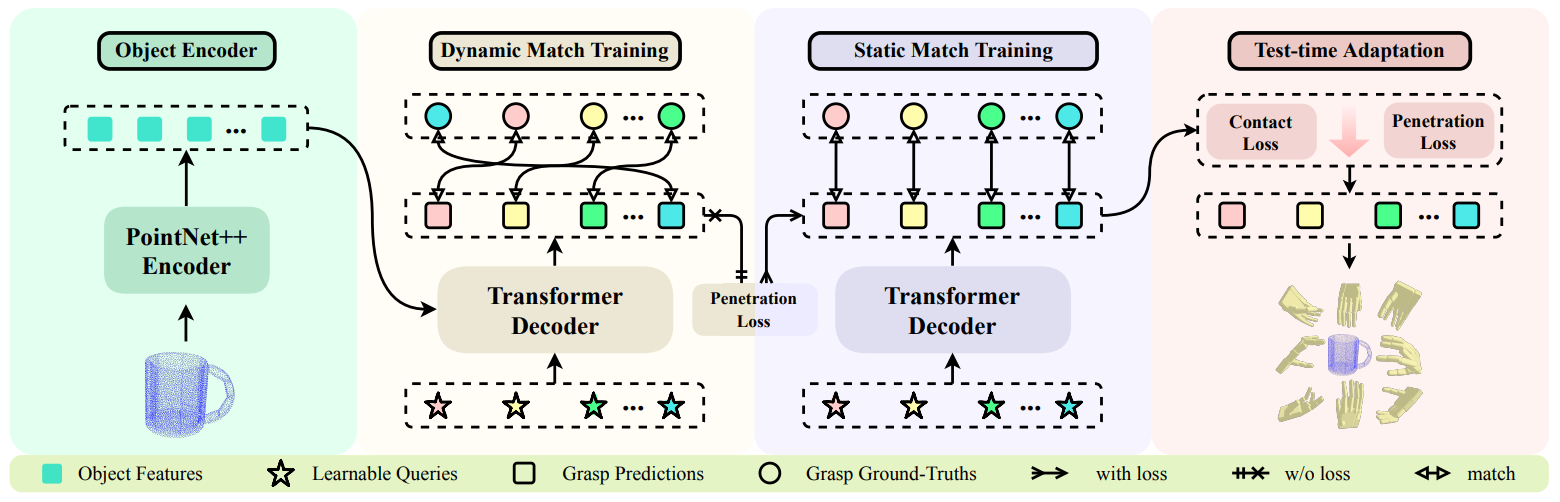
创新点:
-
动-静匹配训练策略(DSMT):通过引入动-静匹配训练策略,在显著提高Q1的同时,减少了约50%的穿透损失。
-
对抗平衡的测试时适应(AB-TTA):通过引入对抗平衡的测试时适应模块(AB-TTA),显著提高了Q1值,并同时增强了ηnp和ηtb的性能。
具身智能体
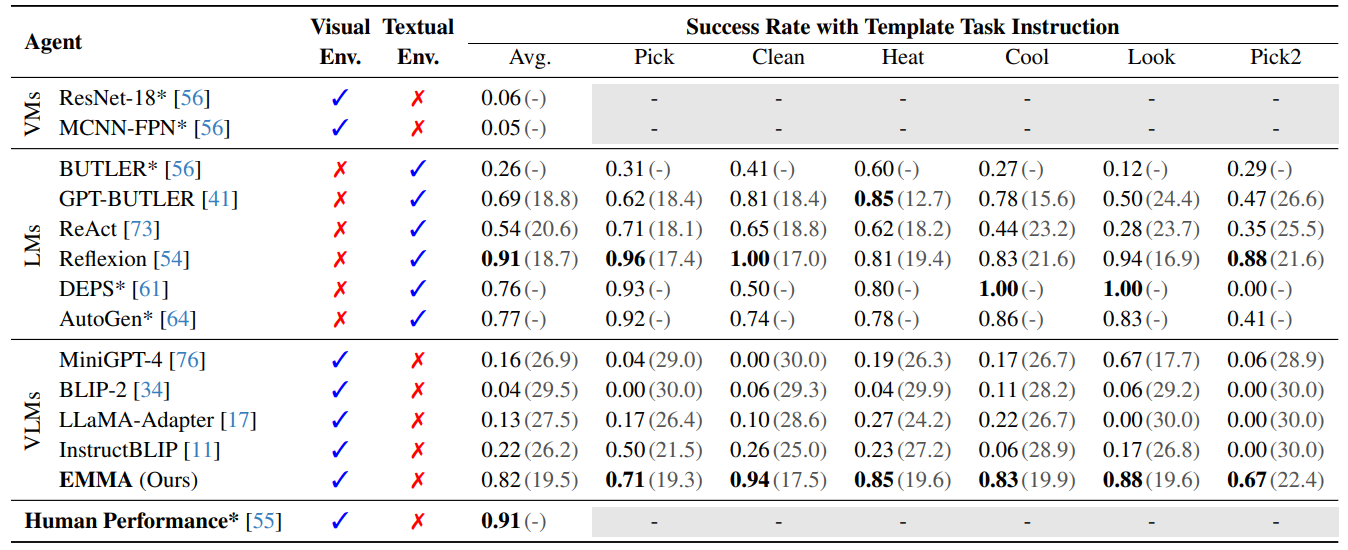
Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld
方法:论文提出了一种名为EMMA(Embodied Multi-Modal Agent)的方法,通过跨模态交互模仿学习,将一个在文本世界中表现出色的大型语言模型(LLM)专家的知识迁移到一个在视觉世界中的具身多模态代理上。
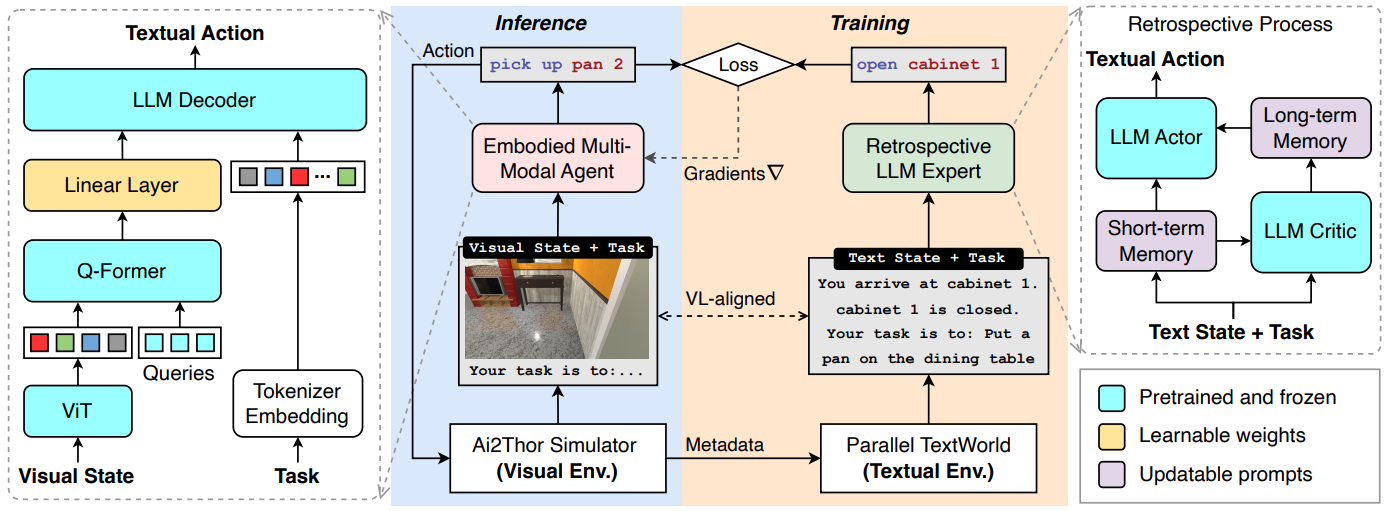
创新点:
-
通过回顾反思,EMMA在时间上得到了改进。通过比较EMMA和去掉回顾机制的EMMA的平均成功率,作者发现EMMA的回顾机制显著优于没有回顾机制的EMMA。
-
通过在特定噪声率下对EMMA和SOTA LLM代理(Reflexion)进行比较,作者发现随着噪声率的增加,EMMA的性能仍然比Reflexion更具鲁棒性。
虚拟到现实
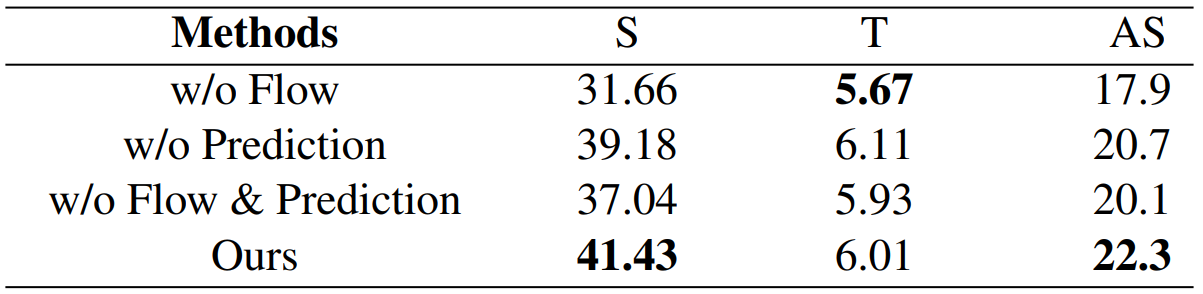
GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation
方法:论文提出了GenH2R,一个用于学习通用的基于视觉的人机交互(Human-to-Robot, H2R)交接技能的框架。该框架通过可扩展的模拟环境GenH2R-Sim、自动化的演示生成方法和一种辅助预测的4D模仿学习方法,实现了对机器人接收人类以各种复杂轨迹递交的不同几何形状物体的能力的培训。
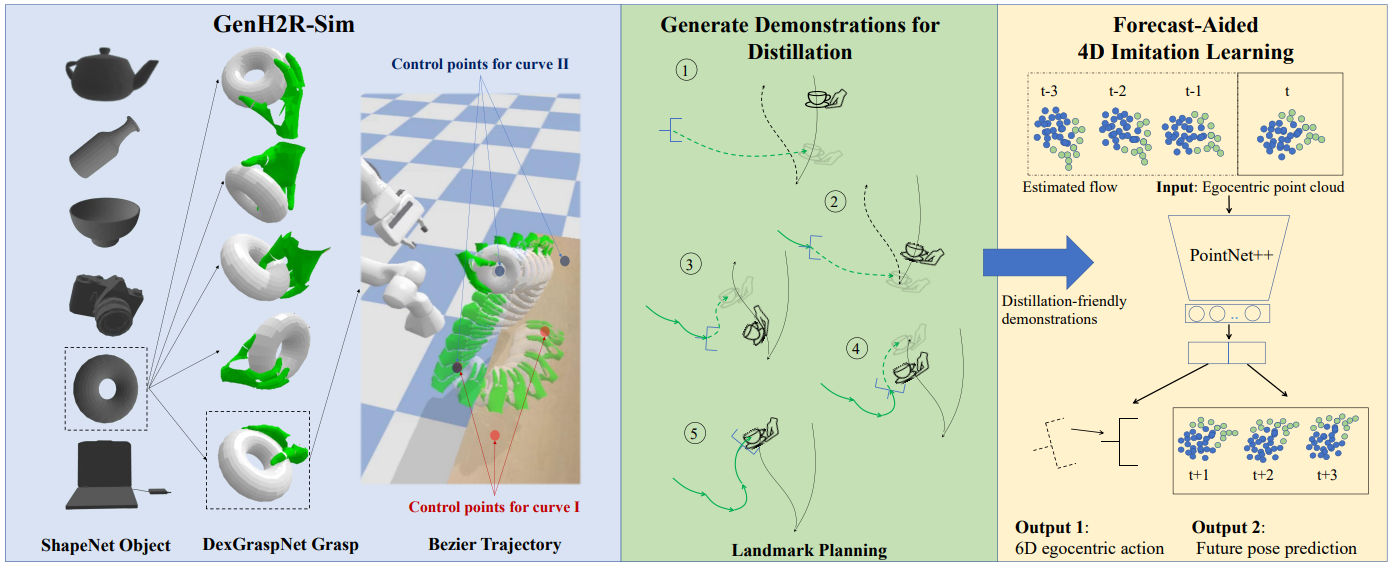
创新点:
-
GenH2R-Sim是一个新的仿真环境,包含了数百万个人与机器人交接的动画,用于支持一般化的H2R交接学习。
-
文中介绍了一种适用于大规模演示生成的方法,可以自动生成适合学习的高质量演示。
-
文中还提出了一种基于预测的4D模仿学习方法,用于将演示提炼为视觉-运动交接策略。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“具身顶会”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















