刚入职公司,就发现公司项目跑sql特别慢,差不多一万条数据插入到数据库要5秒以上(没有听错,就是这个速度),查询修改删除也是特别慢。直到22年年底实在是受不了了,我就去排查了一下。
用的是Oracle数据库,mybatis、mybatis plus,其中mybatis是引入的平台的依赖。平台封装了一些工具和插件。
做个对照试验
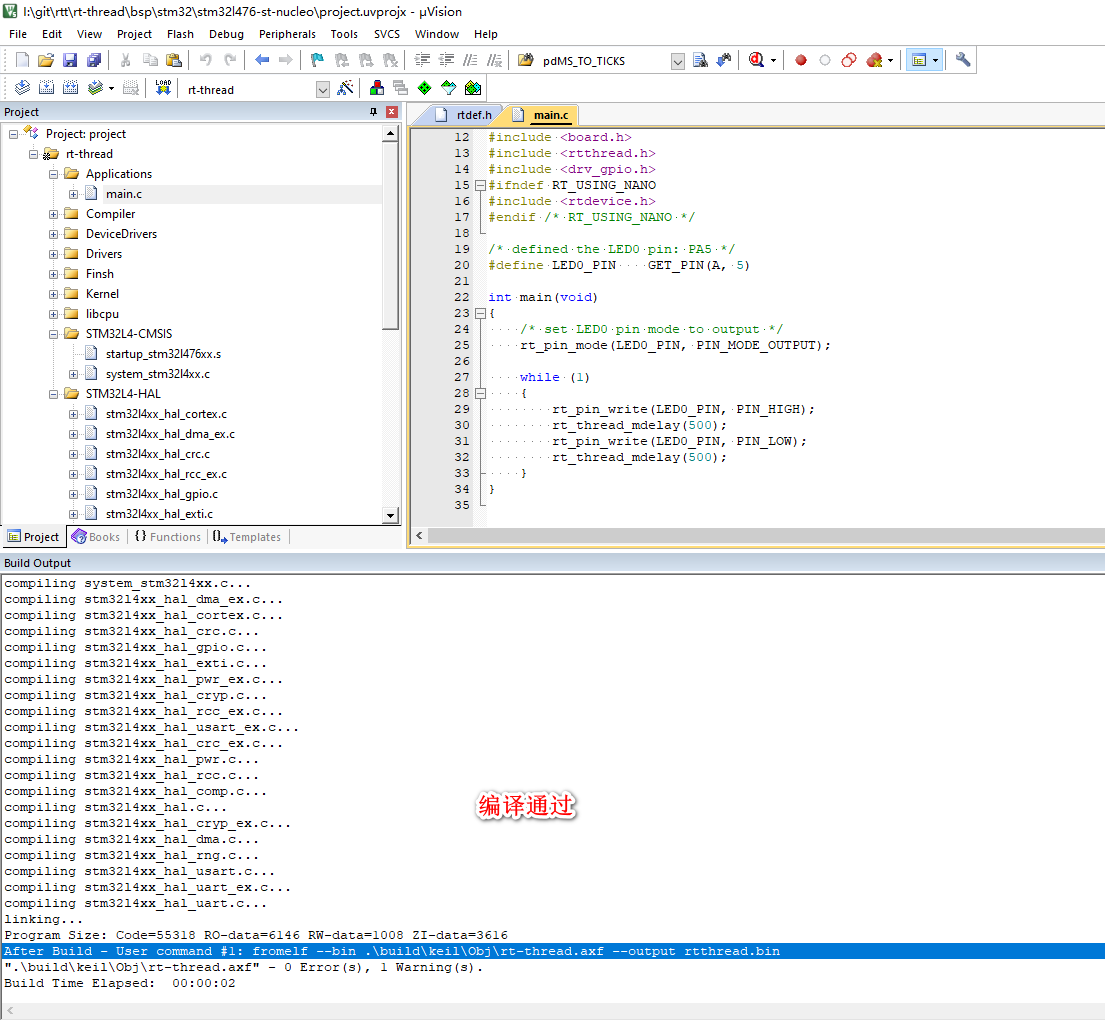
首先为了做对照试验,自己新建了一个SpringBoot项目T,里面引入了官方的mybatis。在自己项目中序列化一万条数据搞成文件,然后在T项目中反序列再插入到数据库。只花了100毫秒(一年了,具体我忘了,反正特别快),从5秒往上到现在这个速度,简直相差太大了。
然后又在T项目中引入了mybatis plus,使用mp的批量保存,速度也是100毫秒以内。接着我又把平台的mybatis依赖引入,重新插入数据,好家伙,单位成了秒。所以这下我就确定是平台的这个mybatis依赖有问题了。其实最开始百度了很多,用了很多种方法来写sql,但是效果都不是特别好.
mybatis Interceptor拦截器排查
排查自定义的mybatis Interceptor拦截器插件1
正好之前开通了平台代码的git权限,就去看了平台的代码,发现好多自定义的拦截器插件,还有一些其他的类,所以大概就是这些地方有问题了。
想到之前每次执行sql的时候,控制台都会输出一堆sql日志,还有执行时间,大概批量保存100条就会输出100条日志。后面我用arthas去看这个日志插件的执行速度,单条的话不算慢,但是量级一大,这个就很慢了。这个日志插件实现思路和【Mybatis】MybatisSqlInterceptor Interceptor 拦截器打印完整的sql语句这篇文章差不多,就是多了对不同厂商数据库连接池的处理。后面我关闭了这个插件,发现保存速度快了将近一秒。
正常的批量保存之所以快,是因为底层复用了PreparedStatement对象,一次批量保存多条数据,会先编译sql,后面都是发送占位符?的实际值就行了,但是调试发现用了平台的这个日志插件之后,会导致每次都生成一个新的PreparedStatement对象来执行,这相当于每插入一条数据都要编译一次sql。但是有些场景有需要用到sql日志(不是debug级别),所以我就想了其他办法来输出日志,具体参考这篇文章mybatis自定义日志实现,换成我这种的之后,测试发现对插入数据的速度影响不大。
排查自定义的mybatis Interceptor拦截器插件2
在移除掉平台的日志插件之后,速度快了一秒,但是还是很慢,然后接着排查。用了arthas的一些命令比如watch和trace等(安利一个插件arthas idea,真的好用),发现一个叫空集合处理的插件每次都会被调用,而且速度还不快。打开这个类发现里面是有两个处理,一是给没有是否删除条件的sql加上IS_DELETED,二是给有是否删除条件的sql检查值是否正确(这个是因为之前改过是否删除的枚举,为了兼容旧代码)。因为我们这边都是带了是否删除的标识,而且全部都是新的枚举,所以就跟平台协调能否去掉这个插件,最后是平台那边把他们那边的代码全部加上了这个标识,然后给这个插件加上了一个开关。拉新依赖之后,我这边直接关了,然后又关闭了一些其他不需要的插件(另外的插件其实没用调用,只是我们系统里面没有用到)。关闭这个空集合插件之后,重新保存,速度直接到了1秒多一点,相比之前快了很多。虽然说相比正常的还是很慢,但是没时间排查了。
查询很慢排查改造
fetchSize配置
保存的速度已经正常了,但是查询的速度还是异常的慢。但是因为项目比较忙,就搁置了。大概过了半年,正好安排优化报表项目,就顺带研究了一下查询为什么那么慢。
查询一万条数据,他要好几秒(数据量少很慢,数据量大更慢,想一秒查出来几乎不可能),但是我去DataGrip里面跑这条sql,几十毫秒,查询执行计划,发现这条sql是走了索引的。
后面去查了一下平台的mybatis默认配置,是没有配置fetchSize大小的,所以就很慢,
fetchSize的作用,文心一言:
JDBC中的fetchSize是一个重要的配置参数,它决定了每次从数据库中检索并传输到客户端的记录数。以下是对fetchSize的详细解释和配置方法:
一、fetchSize的作用
内存管理:通过控制每次从数据库检索的记录数,fetchSize有助于减少客户端的内存占用,特别是在处理大量数据时。如果fetchSize设置得过大,可能会导致内存溢出;如果设置得过小,则可能增加网络往返次数,影响性能。
性能优化:合理设置fetchSize可以在内存使用和性能之间找到平衡点。对于需要快速响应的应用,较小的fetchSize可能更合适;而对于可以容忍一定延迟的应用,较大的fetchSize可能有助于减少网络开销。
后面我在mapper文件的select标签中里面加上了fetchSize="600",相较于之前速度果然变的特别快,但是和DataGrip里面执行的速度还是相差挺多的

添加fetchSize有三种方式
- xml中在select标签里面加
fetchSize属性 - mybatis注解方式写查询sql的可以加上
@Options注解,配置fetchSize属性 - mybatis plus可以通过
mybatis-plus.configuration.default-fetch-size属性来配置默认的,这个针对于mp自有的方法
jdbcType是否配置测试
在小组的项目中测试了一些查询语句,发现了一个问题,配置了jdbcType的和没有配置jdbcType的sql查询速度相差很大(之前我只有部分用IDEA的mybatis插件生成的sql脚本加了这些,其他人代码都没加),加了jdbcType的sql执行速度只比Data Grip里面执行慢一点点,几乎可以忽略不记。
做对照试验
在T项目中,同样的查询sql(xml方式),使用的平台mybatis依赖,添加jdbcType和不加jdbcType效果等同于小组的项目。
然后去除了平台的mybatis依赖,再次运行,不加的速度和加的一样快了。到这里我已经有点麻木了。
但是起码发现加上了速度会变快,最后项目组的项目xml里面的sql全部加上了这个jdbcType,mp的也加上了,通过@TableField的jdbcType属性指定了
mp的还可以通过@TableName注解的两个属性来配置这个,这样就不用在每个类属性上配置了,具体可以去官网看一下

平台代码导致的赋值方法调用错误
本以为加上了这个,CRUD语句的速度都能变正常,但是他总能给我惊喜,用自定义sql方式跑速度都很快,用mp的批量删除跑速度也很快,但用mp的selectXXX系列方法,速度竟然和最开始一样,慢的离谱,秒级以上。
到这我已经想不到还有哪里有问题了,于是乎开始不停的debugmybatis还有mybatis plus的源码,一层套一层,看的人都麻了。后面发现一个问题,自己在xml里面写的sql,里面参数a如果指定了jdbcType,那么在MybatisDefaultParameterHandler类setParameters方法里面是可以拿的到,他就会调用StringTypeHandler(设置了VARCHAR的情况下)来设置占位符的值,实际上就是调用PreparedStatement实现类的setString方法。
但是我如果用mp的查询方法(实体类中已经通过注解方式指定),他这里拿到的竟然是个null,接下来他就调用了一个CustomNStringTypeHandler类来设置占位符的值,数据库中的字段是VARCHAR2类型,这个类里面实际调用了setNString,而setNString对应的数据库类型应该是NVARCHAR。所以,就导致了隐式转换,他就不会走索引,隐式转换加上不走索引,执行语句就很慢,特别是查询和删除,数据量一大,不走索引执行SQL应该知道那速度得有多慢吧。mybatis plus查询方法jdbcType为什么null的下一篇再说
隐式转换是啥?文心一言:
数据库隐式转换,也称为自动转换,是指在执行SQL语句时,数据库管理系统(DBMS)自动进行的数据类型转换。这种转换通常发生在数据类型不匹配但需要进行比较、计算或赋值等操作时。不同数据库系统(如MySQL、Oracle等)中的隐式转换机制可能有所不同,但基本原理相似。以下是对数据库隐式转换的详细解析:
一、隐式转换的场景
字符串与数字的混合比较:
当字符串与数字进行比较时,数据库会尝试将字符串转换为数字(如果可能)。例如,在MySQL中,SELECT * FROM table WHERE column = ‘123’; 如果column是数字类型,MySQL会尝试将字符串’123’转换为数字123进行比较。
插入操作中的类型转换:
当尝试将字符串插入到数字类型的列时,数据库会尝试将字符串转换为相应的数字类型。反之亦然,如果尝试将数字插入到字符串类型的列中,数据库也会进行隐式转换。
数据库隐式转换是指在不显式指定数据类型转换的情况下,数据库系统根据上下文自动进行数据类型转换的过程。这种转换通常发生在SQL查询中,当操作符两边的数据类型不一致时,数据库会尝试将它们转换为一种共同的数据类型以便进行比较或计算。
然而,隐式转换有时会导致数据库查询不使用索引,从而影响查询性能。这主要是因为索引是基于特定数据类型的列创建的,当查询条件中的数据类型与索引列的数据类型不匹配时,数据库可能无法直接利用索引来加速查询。以下是几个导致隐式转换不走索引的常见原因:

接着就去看了一下这个CustomNStringTypeHandler类,这个类实现了BaseTypeHandler类。嗯~,又是平台的类,类上面的注解
@MappedJdbcTypes(value = {JdbcType.NVARCHAR},includeNullJdbcType = true
)
@Component
这个意思就是说,如果jdbcType是NVARCHAR类型的,就会调用这个类来进行占位符赋值,重点是这个includeNullJdbcType = true,如果jdbcType为null的时候,也会使用这个。这就能解释的通为什么xml里面没加jdbcType就会很慢。因为数据库里面是VARCHAR2类型,然后又因为没有配置jdbcType,所以导致调用了这个类的赋值方法。
后面就去找平台沟通说这个代码有问题,平台说当初加上个是为了解决部分中文乱码问题(VARCHAR2有些中文字符存放的话会乱码,要用NVARCHAR),后面平台是把includeNullJdbcType = true给去掉了,我当时是建议直接删除这个类,因为mybatis那边是自带的。
之所以前面会发生乱码其实是同样的原因,之前没有这个类,然后写的sql里面没有配置jdbcType,所以导致他字符串类型的值默认使用了PS实现类的setString方法赋值,而数据库中又是NVARCHAR类型。
后面项目中引入了平台新的mybatis依赖,CRUD的速度都正常了。














![[解决]Invalid configuration `aarch64-openwrt-linux‘: machine `aarch64-openwrt](https://i-blog.csdnimg.cn/direct/c07f401a825d4dbd82948999c1c875e8.png)