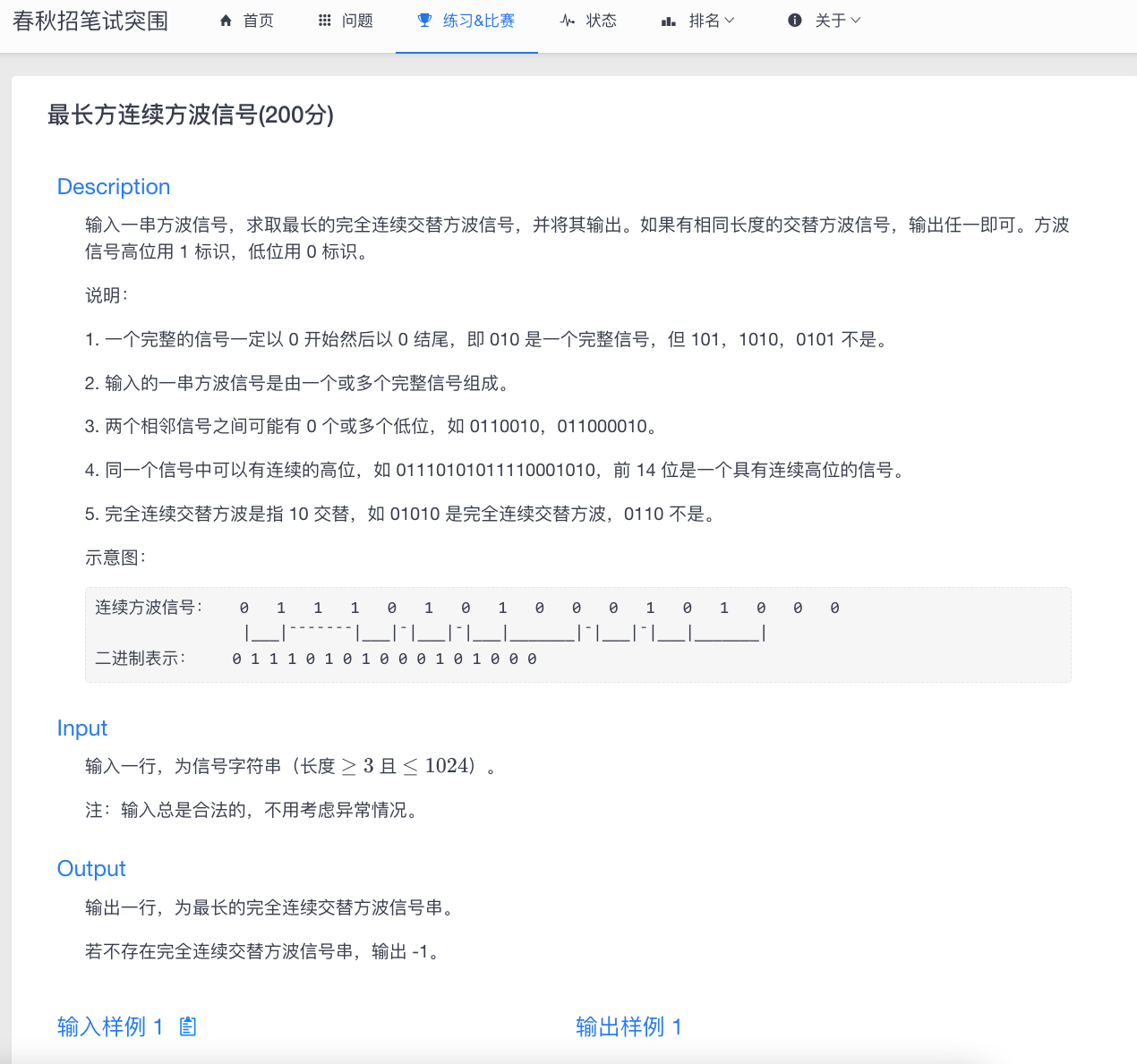
深度强化学习(Deep Reinforcement Learning, DRL)结合了深度学习和强化学习的优点,能够处理具有高维状态和动作空间的复杂任务。它的核心思想是利用深度神经网络来逼近强化学习中的策略函数和价值函数,从而提高学习能力和决策效率。
一、关键算法分类
1.1 深度 Q 网络(Deep Q-Network, DQN)
- 概念:将 Q 学习(一个值函数方法)与深度神经网络结合,用于近似 Q 值函数。
- 特点:使用经验回放和固定 Q 目标网络来稳定训练过程。
- 应用:成功应用于 Atari 游戏等环境。
1.2 双重 Q 学习(Double Q-Learning)
- 概念:解决 DQN 中 Q 值过估计的问题,通过引入两个 Q 网络来减少过估计。
- 特点:使用两个独立的 Q 网络交替更新,以减少 Q 值的过高估计。
1.3 优先经验回放(Prioritized Experience Replay)
- 概念:对经验回放进行优先级排序,以更频繁地训练那些“重要”的样本。
- 特点:提高了训练的效率和稳定性。
1.4 深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)
- 概念:适用于连续动作空间的策略梯度算法。
- 特点:使用策略网络和价值网络来逼近策略和价值函数,并利用经验回放和目标网络来稳定训练。
1.5策略梯度方法(Policy Gradient Methods)
- 概念:直接优化策略函数,通过梯度上升来最大化预期累积回报。
- 特点:适合处理大规模或连续动作空间。
1.6近端策略优化(Proximal Policy Optimization, PPO)
- 概念:通过引入一个“剪切”操作来限制每次策略更新的幅度,确保训练稳定。
- 特点:简单且有效,广泛应用于各种任务。
1.7演员-评论家方法(Actor-Critic Methods)
- 概念:结合了策略优化(演员)和价值函数(评论家)的方法。
- 特点:演员负责更新策略,而评论家负责估计价值函数,用于指导演员更新策略。
二、近端策略优化(Proximal Policy Optimization, PPO)公式推导
近端策略优化(Proximal Policy Optimization, PPO)是强化学习中的一种重要算法,它通过引入“剪切”机制来保证策略更新的稳定性。下面是PPO算法的详细公式推导过程。
2.1策略梯度基础
强化学习中,我们的目标是最大化策略的累积期望回报。策略梯度定理用于计算优化策略的梯度:

其中:
是策略
在状态
下选择动作
的概率。
是优势函数,通常定义为
,其中
是从状态
是状态值函数。
2.2重要性采样
为了避免每次都重新采样策略,PPO使用了重要性采样。使用旧策略 和新策略
的概率比率来估计梯度:

定义重要性采样比率为:

则策略梯度可以写为:

2.3PPO目标函数
PPO算法引入了目标函数中的剪切机制来稳定优化。具体的目标函数设计如下:

其中:
![]() 是重要性采样比率
是重要性采样比率
是一个将 x限制在
区间内的函数。
是剪切超参数,用于控制更新幅度。
2.3.1剪切机制的动机
剪切机制的动机是防止新旧策略之间的比率过大,从而避免策略更新过大的问题。具体来说,PPO目标函数的剪切部分:
确保了当 超出
区间时,目标函数的值不会过高。这样,优化过程可以更稳定地进行,因为在比率
过大或过小时,目标函数不会被放大,从而避免了梯度更新过大。
2.3.2剪切目标函数的解释
PPO的目标函数考虑了两个部分:
1.:这是标准的策略梯度项,表示新策略的改进。
2.:这是剪切后策略的改进部分,防止策略比率过大
目标函数选择这两个部分中的最小值来进行优化,确保策略更新的稳定性。
2.4实际算法步骤
在实际应用中,PPO的算法步骤如下:
- 数据收集:使用当前策略
与环境交互,收集状态、动作、奖励等数据。
- 计算优势函数:根据收集的数据计算优势函数
- 优化目标函数:通过优化目标函数
更新策略网络
的参数 θ,通常使用随机梯度下降(SGD)或其他优化方法。
- 更新策略:将更新后的策略保存为旧策略
三、MATLAB模拟仿真
下面是一个简单的 MATLAB 实现,演示了如何使用 Proximal Policy Optimization (PPO) 算法进行强化学习。这个示例基于一个简化的环境模型,例如一个线性二次高斯(LQR)控制问题,以便能够在 MATLAB 中实现和测试。
3.1环境模型
在实际应用中,您需要将以下代码与实际的环境模型结合使用。这只是一个演示示例。对于实际问题,您需要根据具体的环境需求进行修改。
3.2MATLAB 代码
% PPO Implementation in MATLAB% Parameters
num_episodes = 1000;
max_steps_per_episode = 200;
gamma = 0.99; % Discount factor
lambda = 0.95; % GAE lambda
epsilon = 0.2; % PPO clipping parameter
learning_rate = 1e-3; % Learning rate for the policy network
hidden_units = 64; % Number of units in the hidden layer% Define the environment
state_dim = 4; % Number of state dimensions
action_dim = 1; % Number of action dimensions% Initialize policy network
policy_net = build_policy_net(state_dim, action_dim, hidden_units);
optimizer = optimizers.Adam(learning_rate);% Training loop
for episode = 1:num_episodes[states, actions, rewards, next_states, dones] = collect_data(policy_net, max_steps_per_episode);% Compute advantages[advantages, returns] = compute_advantages(rewards, states, next_states, dones, gamma, lambda);% Update policy networkupdate_policy(policy_net, optimizer, states, actions, advantages, returns, epsilon);% Print episode statisticsfprintf('Episode %d completed\n', episode);
end% Helper Functionsfunction policy_net = build_policy_net(state_dim, action_dim, hidden_units)% Define a simple feedforward neural network for policy approximationpolicy_net = @(states) tanh(states * randn(state_dim, hidden_units) + randn(hidden_units, 1));
endfunction [states, actions, rewards, next_states, dones] = collect_data(policy_net, max_steps)% Collect data from the environment using the policy network% This is a placeholder function and needs to be replaced with actual environment interactionstates = rand(max_steps, state_dim);actions = rand(max_steps, action_dim);rewards = rand(max_steps, 1);next_states = rand(max_steps, state_dim);dones = rand(max_steps, 1) > 0.5;
endfunction [advantages, returns] = compute_advantages(rewards, states, next_states, dones, gamma, lambda)% Compute advantages and returns using Generalized Advantage Estimation (GAE)num_steps = length(rewards);advantages = zeros(num_steps, 1);returns = zeros(num_steps, 1);% Compute returnslast_gae_lambda = 0;for t = num_steps:-1:1if t == num_stepsnext_value = 0;elsenext_value = returns(t + 1);enddelta = rewards(t) + gamma * next_value - value_function(states(t, :));advantages(t) = last_gae_lambda = delta + gamma * lambda * last_gae_lambda;returns(t) = advantages(t) + value_function(states(t, :));end
endfunction value = value_function(state)% Placeholder value function; replace with your value networkvalue = state * rand(state_dim, 1);
endfunction update_policy(policy_net, optimizer, states, actions, advantages, returns, epsilon)% Update policy network using the PPO objective functionnum_steps = length(states);for i = 1:num_steps% Compute probability ratioold_prob = policy_net(states(i, :))' * actions(i, :)';new_prob = policy_net(states(i, :))' * actions(i, :)';ratio = new_prob / old_prob;% Compute clipped objectiveclipped_ratio = min(ratio, max(1 - epsilon, min(1 + epsilon, ratio)));loss = -min(ratio * advantages(i), clipped_ratio * advantages(i));% Perform optimization stepoptimizer.step(@() loss);end
end% Utility functions and optimizers
classdef optimizersmethods (Static)function optimizer = Adam(learning_rate)optimizer.learning_rate = learning_rate;endfunction step(obj, loss_fn)% Placeholder for optimization step% You should replace this with an actual optimization step for your networkfprintf('Optimization step\n');endend
end
3.3代码说明
-
环境模型:
collect_data函数和其他与环境交互的函数是占位符,需要替换为实际的环境模型。您可以根据具体的环境进行修改。 -
政策网络:
build_policy_net函数是一个简单的示例,实际应用中,您可以使用 MATLAB 的 Deep Learning Toolbox 来定义和训练更复杂的神经网络模型。 -
优势函数:
compute_advantages函数实现了广义优势估计(GAE)。请根据实际需求调整计算方法。 -
策略更新:
update_policy函数实现了PPO的目标函数和更新过程。实际应用中,您可以使用 MATLAB 的优化工具来进行网络参数的更新。 -
优化器:
optimizers类是一个占位符,您需要根据实际需求选择合适的优化算法(如 Adam)并实现其优化步骤。
3.4扩展
为了使这个示例更符合实际应用,您可以:
- 替换占位符函数以与实际环境进行交互。
- 使用 MATLAB 的 Deep Learning Toolbox 实现复杂的神经网络。
- 实现和优化 PPO 算法中的其他组件,例如值函数网络和优化步骤。
这个简单的示例提供了一个基础框架,您可以在此基础上进行扩展和改进,以满足具体的强化学习任务需求。
四、总结
近端策略优化(Proximal Policy Optimization, PPO)是一种现代强化学习算法,旨在在策略优化过程中保持稳定性和有效性。PPO算法的核心思想是通过对策略更新的控制来避免过大的变动,从而提高训练过程的稳定性和可靠性。PPO是一种有效且稳定的策略优化算法,通过引入剪切机制来控制策略更新幅度,从而保证了训练过程的稳定性。它的简单实现和良好的性能使其成为强化学习领域中常用的算法之一。
注意:回顾以往算法可以从以下链接进入:
1、深度 Q 网络(Deep Q-Network, DQN):
深度强化学习算法(一)(附带MATLAB程序)-CSDN博客
2、双重 Q 学习(Double Q-Learning):
深度强化学习算法(二)(附带MATLAB程序)-CSDN博客
3.优先经验回放(Prioritized Experience Replay):
深度强化学习算法(三)(附带MATLAB程序)-CSDN博客
4、深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)
深度强化学习算法(四)(附带MATLAB程序)-CSDN博客
5、策略梯度方法(Policy Gradient Methods)
深度强化学习算法(五)(附带MATLAB程序)-CSDN博客