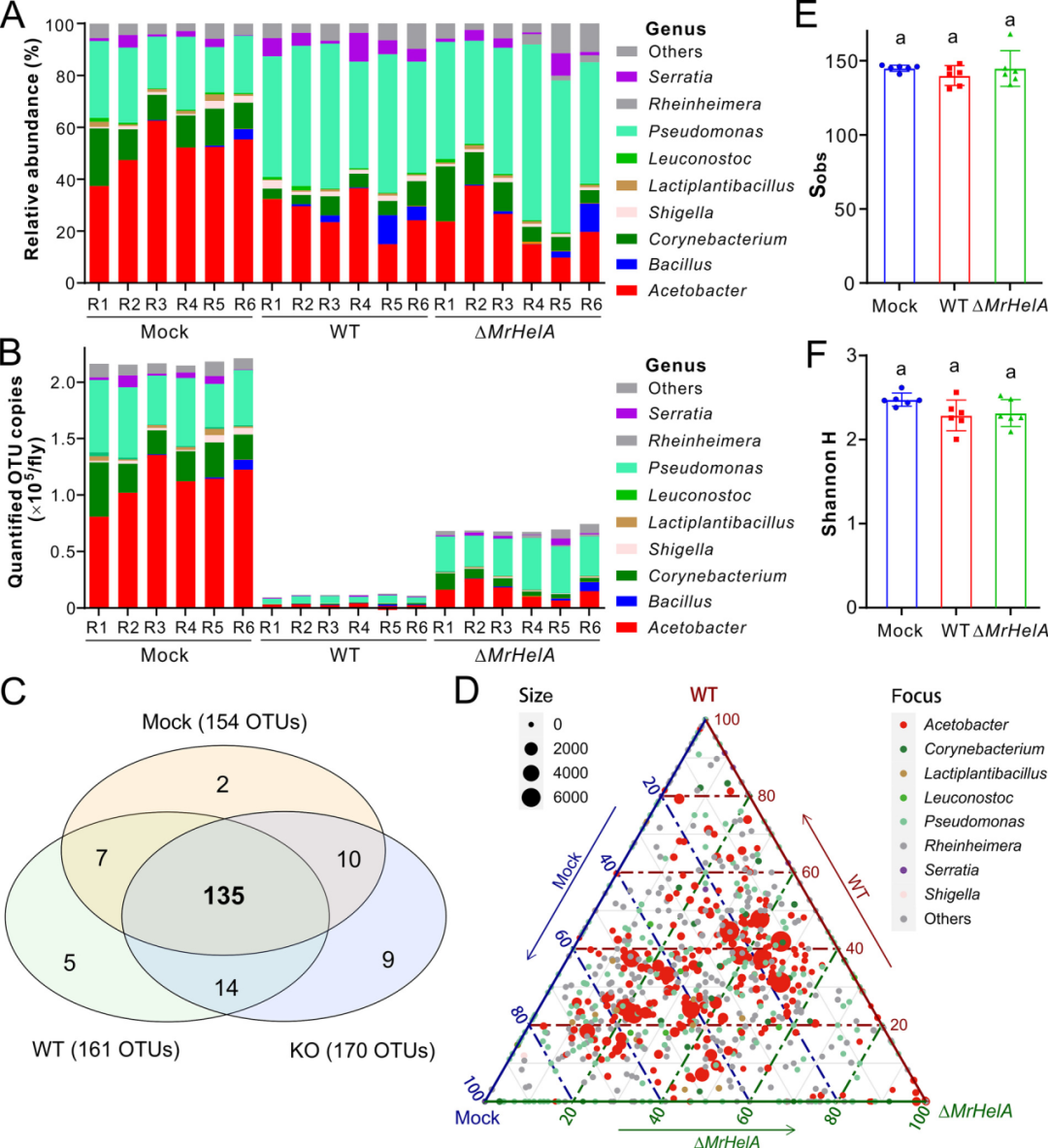
一、概述
摘要:本文我们继续分析源码,并聚焦在预选策略的调度过程的执行。
二、正文
说明:基于 kubernetes
v1.12.0源码分析
上文我们说的(g *genericScheduler) Schedule()函数调用了findNodesThatFit()执行预选策略。
2.1 findNodesThatFit
先找到改函数对应的源码
// k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go// Filters the nodes to find the ones that fit based on the given predicate functions
// Each node is passed through the predicate functions to determine if it is a fit
func (g *genericScheduler) findNodesThatFit(pod *v1.Pod, nodes []*v1.Node) ([]*v1.Node, FailedPredicateMap, error) {var filtered []*v1.NodefailedPredicateMap := FailedPredicateMap{}// 如果没有载入预选调度算法,直接返回所有node节点if len(g.predicates) == 0 {filtered = nodes} else {// 计算所有node节点的数量allNodes := int32(g.cache.NodeTree().NumNodes)numNodesToFind := g.numFeasibleNodesToFind(allNodes)// Create filtered list with enough space to avoid growing it// and allow assigning.// 创建名为filtered的切片,容量大小足够的大,避免后面空间不足再对齐扩容。这里是一个性能的优化小点。filtered = make([]*v1.Node, numNodesToFind)errs := errors.MessageCountMap{}var (predicateResultLock sync.MutexfilteredLen int32equivClass *equivalence.Class)ctx, cancel := context.WithCancel(context.Background())// We can use the same metadata producer for all nodes.meta := g.predicateMetaProducer(pod, g.cachedNodeInfoMap)if g.equivalenceCache != nil {// getEquivalenceClassInfo will return immediately if no equivalence pod foundequivClass = equivalence.NewClass(pod)}checkNode := func(i int) {var nodeCache *equivalence.NodeCache// 从 cache 中取出一个 node 节点nodeName := g.cache.NodeTree().Next()if g.equivalenceCache != nil {nodeCache, _ = g.equivalenceCache.GetNodeCache(nodeName)}// 核心!!! 这里执行预选过程fits, failedPredicates, err := podFitsOnNode(pod,meta,g.cachedNodeInfoMap[nodeName],g.predicates,g.cache,nodeCache,g.schedulingQueue,g.alwaysCheckAllPredicates,equivClass,)// 如果执行预选时出现错误,则记录错误次数并返回if err != nil {predicateResultLock.Lock()errs[err.Error()]++predicateResultLock.Unlock()return}// 如果fits为真,表示找到预选过程完成if fits {length := atomic.AddInt32(&filteredLen, 1)if length > numNodesToFind {cancel()atomic.AddInt32(&filteredLen, -1)} else {filtered[length-1] = g.cachedNodeInfoMap[nodeName].Node()}} else {predicateResultLock.Lock()failedPredicateMap[nodeName] = failedPredicatespredicateResultLock.Unlock()}}// Stops searching for more nodes once the configured number of feasible nodes// are found.workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)filtered = filtered[:filteredLen]if len(errs) > 0 {return []*v1.Node{}, FailedPredicateMap{}, errors.CreateAggregateFromMessageCountMap(errs)}}if len(filtered) > 0 && len(g.extenders) != 0 {for _, extender := range g.extenders {if !extender.IsInterested(pod) {continue}filteredList, failedMap, err := extender.Filter(pod, filtered, g.cachedNodeInfoMap)if err != nil {if extender.IsIgnorable() {glog.Warningf("Skipping extender %v as it returned error %v and has ignorable flag set",extender, err)continue} else {return []*v1.Node{}, FailedPredicateMap{}, err}}for failedNodeName, failedMsg := range failedMap {if _, found := failedPredicateMap[failedNodeName]; !found {failedPredicateMap[failedNodeName] = []algorithm.PredicateFailureReason{}}failedPredicateMap[failedNodeName] = append(failedPredicateMap[failedNodeName], predicates.NewFailureReason(failedMsg))}filtered = filteredListif len(filtered) == 0 {break}}}return filtered, failedPredicateMap, nil
}
进过简单的对findNodesThatFit 的分析,发现它 的主要逻辑包括:
- 定义一个filtered 切片,用于保存满足预选算法的node节点。
- 定义filteredLen,用于记录满足预选调度算法的 node 的数量。
- 定义一个函数checkNode(),函数中的 podFitsOnNode()方法,先从缓存中取出一个node节点, 判断这个node节点是否满足调度pod的预选策略。
- workqueue.ParallelizeUntil启动16个并发任务,同时执行checkNode(),一起发力,从allnodes选出满足预选策略的node节点
- 每个并发任务会将满足预选策略的node节点,放入filtered切片。最后将filtered切片返回,就是所有满足预选调度策略的node节点的集合。
func (g *genericScheduler) findNodesThatFit(pod *v1.Pod, nodes []*v1.Node) ([]*v1.Node, FailedPredicateMap, error) {// filtered 切片是记录满足预算算法的所有node的数组var filtered []*v1.Node// failedPredicateMap 记录 node 不满足预选调度算法的原因failedPredicateMap := FailedPredicateMap{}// 如果没有载入预选调度算法,直接返回所有node节点if len(g.predicates) == 0 {filtered = nodes} else {// 计算所有node节点的数量allNodes := int32(g.cache.NodeTree().NumNodes)// 多少节点参与预算策略记录,这是一个性能优化的技巧// 当集群的节点数小于 100 时, 则直接使用集群的节点数作为扫描数据量// 当大于 100 时, 则使用公式计算 `numAllNodes * (50 - numAllNodes/125) / 100`numNodesToFind := g.numFeasibleNodesToFind(allNodes)glog.Infof("Wrote configuration to: %s\n", opts.WriteConfigTo)// Create filtered list with enough space to avoid growing it// and allow assigning.// 创建名为filtered的切片,容量大小足够的大,避免后面空间不足再对齐扩容。这里是一个性能的优化小点。filtered = make([]*v1.Node, numNodesToFind)errs := errors.MessageCountMap{}var (predicateResultLock sync.Mutex// filteredLen 记录满足预选调度算法的 node 的数量filteredLen int32equivClass *equivalence.Class)checkNode := func(i int) {// 从 cache 中取出一个 node 节点nodeName := g.cache.NodeTree().Next()// 核心!!! 这里执行预选过程fits, failedPredicates, err := podFitsOnNode(pod,meta,g.cachedNodeInfoMap[nodeName],g.predicates,g.cache,nodeCache,g.schedulingQueue,g.alwaysCheckAllPredicates,equivClass,)// 如果fits为真,表示node满足预选算法。并会把filteredLen计数加1,同时把node节点放入列表filteredif fits {length := atomic.AddInt32(&filteredLen, 1)filtered[length-1] = g.cachedNodeInfoMap[nodeName].Node()} else {// 如果fits为false,表示这个node不满足预选调度算法,并把不失败的原因记录到failedPredicateMappredicateResultLock.Lock()failedPredicateMap[nodeName] = failedPredicatespredicateResultLock.Unlock()}}// Stops searching for more nodes once the configured number of feasible nodes// are found.// 重要!!! 并行16个任务,同时执行函数checkNode,从allNodes 过滤出满足预选算法的node节点workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)filtered = filtered[:filteredLen]if len(errs) > 0 {return []*v1.Node{}, FailedPredicateMap{}, errors.CreateAggregateFromMessageCountMap(errs)}}// 返回 过滤后的节点的列表return filtered, failedPredicateMap, nil
}findNodesThatFit的执行过程示意图

2.1.1 性能优化之numFeasibleNodesToFind
问题来了,当 k8s 的 node 节点特别多时, 这些节点都要参与预先的调度过程么 ?
比如大集群有 5000 个节点, 注册的插件有 10 个, 那么 筛选 Filter 和 打分 Score 过程需要进行 5000 * 10 * 2 = 500000 次计算, 最后选定一个最高分值的节点来绑定 pod. k8s scheduler 考虑到了这样的性能开销, 所以加入了百分比参数控制参与预选的节点数.
numFeasibleNodesToFind 方法根据当前集群的节点数计算出参与预选的节点数量, 把参与 Filter 的节点范围缩小, 无需全面扫描所有的节点, 这样避免 k8s 集群 nodes 太多时, 造成无效的计算资源开销.
在v1.12.4版本中,numFeasibleNodesToFind 策略是这样的, 当集群节点小于 100 时, 集群中的所有节点都参与预选. 而当大于 100 时, 则使用下面的公式: numAllNodes * g.percentageOfNodesToScore / 100计算扫描数. scheudler 的 percentageOfNodesToScore 参数默认为 50。即一半的节点参与预选的调度过程。
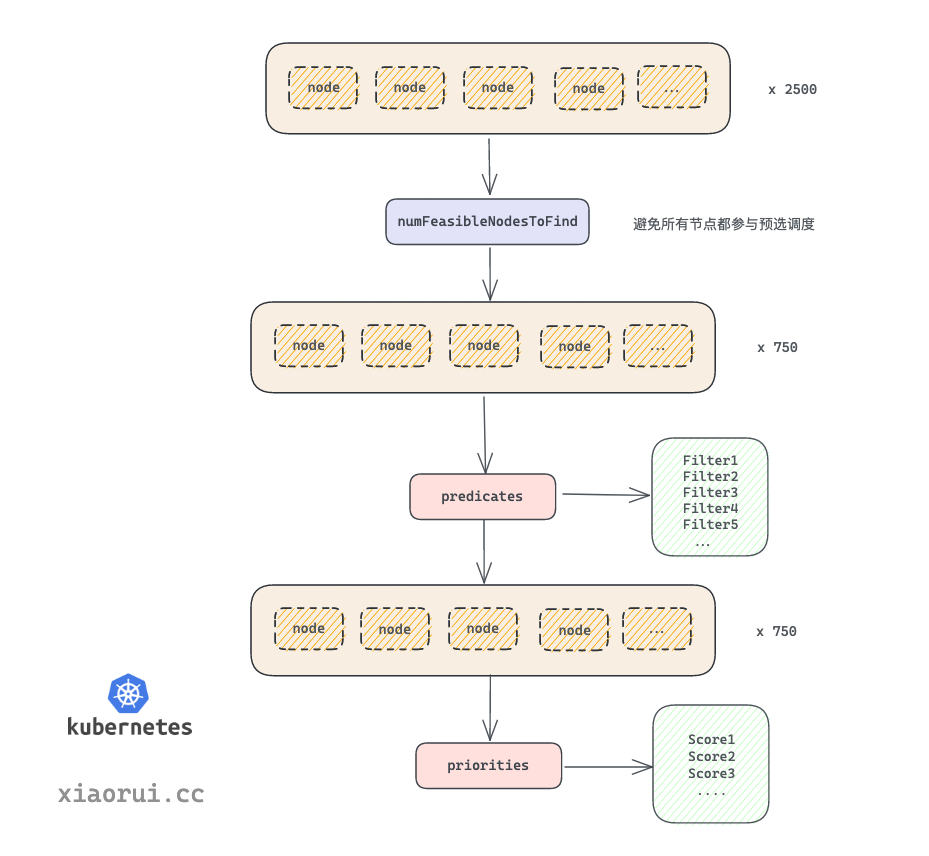
(图片来自网络,如有侵权请联系作者)
计算参与预选策略的核心代码
// k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.goallNodes := int32(g.cache.NodeTree().NumNodes)
numNodesToFind := g.numFeasibleNodesToFind(allNodes)
// numFeasibleNodesToFind returns the number of feasible nodes that once found, the scheduler stops
// its search for more feasible nodes.
func (g *genericScheduler) numFeasibleNodesToFind(numAllNodes int32) int32 {// 如果节点数小于100,参与调度的节点就是所有节点numAllNodesif numAllNodes < minFeasibleNodesToFind || g.percentageOfNodesToScore <= 0 ||g.percentageOfNodesToScore >= 100 {return numAllNodes}// g.percentageOfNodesToScore 是配置文件中定义的一个百分比值。如果用户不指定,默认是50%// numAllNodes = numAllNodes * 50 / 100numNodes := numAllNodes * g.percentageOfNodesToScore / 100if numNodes < minFeasibleNodesToFind {return minFeasibleNodesToFind}return numNodes
}
那么g.percentageOfNodesToScore 从哪里来呢?
回到CreateFromKeys函数,里面初始化通用调度器 NewGenericScheduler时,指定了c.percentageOfNodesToScore,也就是说从配置文件加载而来的,如果配置文件没有指定这个参数的值,那么就使用源码中的默认值。
// k8s.io/kubernetes/pkg/scheduler/factory/factory.go
func (c *configFactory) CreateFromKeys(predicateKeys, priorityKeys sets.String, extenders []algorithm.SchedulerExtender) (*scheduler.Config, error) {glog.V(2).Infof("Creating scheduler with fit predicates '%v' and priority functions '%v'", predicateKeys, priorityKeys)// 代码省略// 初始化一个通用调度器 NewGenericScheduleralgo := core.NewGenericScheduler(c.schedulerCache,c.equivalencePodCache,c.podQueue,predicateFuncs,predicateMetaProducer,priorityConfigs,priorityMetaProducer,extenders,c.volumeBinder,c.pVCLister,c.alwaysCheckAllPredicates,c.disablePreemption,// 从配置文件中读取 percentageOfNodesToScore 的值c.percentageOfNodesToScore,)// 代码省略
}
我们接着看 KubeSchedulerConfiguration 配置文件的对应的类型的定义。从注释说明默认的值是50%。
// k8s.io/kubernetes/pkg/scheduler/apis/config/types.go// KubeSchedulerConfiguration configures a scheduler
type KubeSchedulerConfiguration struct {metav1.TypeMeta// 代码省略// PercentageOfNodeToScore is the percentage of all nodes that once found feasible// for running a pod, the scheduler stops its search for more feasible nodes in// the cluster. This helps improve scheduler's performance. Scheduler always tries to find// at least "minFeasibleNodesToFind" feasible nodes no matter what the value of this flag is.// Example: if the cluster size is 500 nodes and the value of this flag is 30,// then scheduler stops finding further feasible nodes once it finds 150 feasible ones.// When the value is 0, default percentage (50%) of the nodes will be scored.// PercentageOfNodesToScore是所有节点的百分比,一旦发现运行pod可行,调度器就会停止在集群中搜索更多可行的节点。// 这有助于提高调度器的性能。无论这个标志的值是多少,调度器总是试图找到至少“minFeasibleNodesToFind”可行节点。// 例如:如果集群大小为500个节点,并且此标志的值为30,则调度程序一旦找到150个可行节点就停止寻找进一步的可行节点。// 当该值为0时,节点的默认百分比(根据集群的大小,5%- 50%)将为b// 默认percentage是50%,PercentageOfNodesToScore int32// 代码省略
}
源码中关于默认值 DefaultPercentageOfNodesToScore 的设置
// k8s.io/kubernetes/pkg/scheduler/api/types.go
const (// 代码省略// DefaultPercentageOfNodesToScore defines the percentage of nodes of all nodes// that once found feasible, the scheduler stops looking for more nodes.DefaultPercentageOfNodesToScore = 50
)
2.1.2 PercentageOfNodesToScore值的修改
问题又来了,随着集群节点数的增大,参与预选节点的总数也会增加,这会给master带来较大的负载压力。那么如何调整PercentageOfNodesToScore的值呢?
通过源码的阅读,我们自然想到有2种方式:
-
修改源码中关于DefaultPercentageOfNodesToScore的默认值。(不推荐)
-
修改kube-scheduler的启动配置文件。(推荐)
-
使用配置文件修改PercentageOfNodesToScore的值
- 修改/etc/kubernetes/kube-scheduler.yaml中percentageOfNodesToScore的值
vmi /etc/kubernetes/kube-scheduler.yaml
---
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:provider: DefaultProvider
bindTimeoutSeconds: 600
clientConnection:burst: 200kubeconfig: "/home/kube/kubernetes/conf/kubelet.kubeconfig"qps: 100
enableContentionProfiling: false
enableProfiling: true
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: 127.0.0.1:10251
leaderElection:leaderElect: true
metricsBindAddress: 127.0.0.1:10251# 修改参与预选调度任务的节点的比例
percentageOfNodesToScore: 60
- 重启生效kube-scheduler进程,作者实验环境是用supervisor管理kube-schedule进程。所以使用
supervirstorctl restart kube-scheduler进行重新。

-
重启进程后,percentageOfNodesToScore的值就更新。 但是为了观察实际是否真正的生效,我们需要对源码进行修改,加入debug信息。
-
下载kubernetes-1.12.4源码
git clone https://github.com/kubernetes/kubernetes.git
git checkout release-1.12- 加入debug信息
找到k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go中的numFeasibleNodesToFind函数中,加入debug信息
// k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.goglog.Infof("in numFeasibleNodesToFind() g.percentageOfNodesToScore is %v", g.percentageOfNodesToScore)

- 重新编译二进制文件
root@ubuntu1604:/opt/go/src/kubernetes-1.12.4# make WHAT=cmd/kube-scheduler
+++ [0901 15:40:47] Building go targets for linux/amd64:cmd/kube-scheduler
root@ubuntu1604:/opt/go/src/kubernetes-1.12.4#
root@ubuntu1604:/opt/go/src/kubernetes-1.12.4# ls -l _output/bin/kube-scheduler
-rwxr-xr-x 1 root root 55216709 Sep 1 15:40 _output/bin/kube-scheduler
- 重新启动kube-scheduler进程
先用新编译的二进制文件kube-scheduler替换掉/usr/local/bin/kube-scheduler,再重启kube-scheduler进程
- 观察日志
观察kube-scheduler进程对应的运行日志,可以发现percentageOfNodesToScore,已经修改为60了。

2.1.3 v1.18版本中的PercentageOfNodesToScore的值
如果我们查看kubernetes较新版本的源码例如v1.18,发现改版本和v1.12不同,默认的PercentageOfNodesToScore调整为0,而且参与预选的节点的数量计算逻辑也不同,计算公式是: numNodes = numAllNodes * (50 - numAllNodes/125) / 100
v1.18源码版本中关于DefaultPercentageOfNodesToScore 默认值
// k8s.io/kubernetes/pkg/scheduler/apis/config/types.goconst (// DefaultPercentageOfNodesToScore defines the percentage of nodes of all nodes// that once found feasible, the scheduler stops looking for more nodes.// A value of 0 means adaptive, meaning the scheduler figures out a proper default.// 默认值为0DefaultPercentageOfNodesToScore = 0// 代码省略
)// k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go// 计算参与预选调度策略的节点的数量
// numFeasibleNodesToFind returns the number of feasible nodes that once found, the scheduler stops
// its search for more feasible nodes.
func (g *genericScheduler) numFeasibleNodesToFind(numAllNodes int32) (numNodes int32) {// 如果节点数小于100(minFeasibleNodesToFind),则返回全部参与预选// 或者如果percentageOfNodesToScore的值设置为大于等100,则返回全部参与预选if numAllNodes < minFeasibleNodesToFind || g.percentageOfNodesToScore >= 100 {return numAllNodes}// 计算参与预选节点数量的方法adaptivePercentage := g.percentageOfNodesToScoreif adaptivePercentage <= 0 {basePercentageOfNodesToScore := int32(50)adaptivePercentage = basePercentageOfNodesToScore - numAllNodes/125if adaptivePercentage < minFeasibleNodesPercentageToFind {adaptivePercentage = minFeasibleNodesPercentageToFind}}// 重要!!!参与预选的节点 numNodes 的计算方法:// numNodes = numAllNodes * (50 - numAllNodes/125) / 100numNodes = numAllNodes * adaptivePercentage / 100if numNodes < minFeasibleNodesToFind {return minFeasibleNodesToFind}return numNodes
}
根据公司我们计算出节点总数与参与预选调度过程的节点数量的表格,这样可以有个大致的认识。
| 数量 | 计算公式 | numNodes |
|---|---|---|
| 500 | 500 * (50 - 500/125)/100 | 230 |
| 1000 | 1000 * (50 - 1000/125)/100 | 420 |
| 2000 | 2000 * (50 - 2000/125)/100 | 680 |
| 3000 | 3000 * (50 - 3000/125)/100 | 780 |
| 4000 | 4000 * (50 - 4000/125)/100 | 720 |
| 5000 | 5000 * (50 - 5000/125)/100 | 500 |
| 6000 | 6000 * 5 /100 (adaptivePercentage最小值为5) | 300 |
| 8000 | 8000 * 5 /100 (adaptivePercentage最小值为5) | 400 |
| 10000 | 10000 * 5 /100 (adaptivePercentage最小值为5) | 500 |
2.2 podFitsOnNode
podFitsOnNode的逻辑是,一次从注册的预选函数,依次对node进行判断,判断node是否适合pod的调度。
func podFitsOnNode(pod *v1.Pod,meta algorithm.PredicateMetadata,info *schedulercache.NodeInfo,predicateFuncs map[string]algorithm.FitPredicate,cache schedulercache.Cache,nodeCache *equivalence.NodeCache,queue SchedulingQueue,alwaysCheckAllPredicates bool,equivClass *equivalence.Class,
) (bool, []algorithm.PredicateFailureReason, error) {// 需要执行2次for i := 0; i < 2; i++ {// 第一次做特殊处理if i == 0 {podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue)} else if !podsAdded || len(failedPredicates) != 0 {break}// 依次执行 predicates 预选算法。predicates.Ordering()返回需要按顺序执行的预选算法for _, predicateKey := range predicates.Ordering() {// 通过key找到预选函数if predicate, exist := predicateFuncs[predicateKey]; exist {// 利用预选函数,判断node能时候pod的调度fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)} }}}}return len(failedPredicates) == 0, failedPredicates, nil
}
在执行预选算法时,需要按定义的顺序来执行预选算法。predicatesOrdering保存了需要执行预选算法的key。而真正的预算算法是注册在fitPredicateMap这个字典中。关于预选算法是如何注册到这个map中的,之前文章已经介绍这里就不赘述。如有需要请查看文章:kube-scheduler组件的启动流程与源码走读
// k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/predicates.go// Ordering returns the ordering of predicates.
func Ordering() []string {return predicatesOrdering
}var (predicatesOrdering = []string{CheckNodeConditionPred, CheckNodeUnschedulablePred,GeneralPred, HostNamePred, PodFitsHostPortsPred,MatchNodeSelectorPred, PodFitsResourcesPred, NoDiskConflictPred,PodToleratesNodeTaintsPred, PodToleratesNodeNoExecuteTaintsPred, CheckNodeLabelPresencePred,CheckServiceAffinityPred, MaxEBSVolumeCountPred, MaxGCEPDVolumeCountPred, MaxCSIVolumeCountPred,MaxAzureDiskVolumeCountPred, CheckVolumeBindingPred, NoVolumeZoneConflictPred,CheckNodeMemoryPressurePred, CheckNodePIDPressurePred, CheckNodeDiskPressurePred, MatchInterPodAffinityPred}
)2.3 预选调度算法
预选算法很多,我们这里挑选一个预选算法,看它是如何被注册,以及如何被使用的。
2.3.1 注册CheckNodeUnschedulablePred算法
server.Run() 调用algorithmprovider.ApplyFeatureGates()
// k8s.io/kubernetes/cmd/kube-scheduler/app/server.go// Run runs the Scheduler.
func Run(c schedulerserverconfig.CompletedConfig, stopCh <-chan struct{}) error {algorithmprovider.ApplyFeatureGates()
}
// ApplyFeatureGates applies algorithm by feature gates.
func ApplyFeatureGates() {defaults.ApplyFeatureGates()
}
注册预选算法CheckNodeUnschedulablePred,注册的逻辑是把算法加入fitPredicateMap中
// ApplyFeatureGates applies algorithm by feature gates.
func ApplyFeatureGates() {// 注册预选算法CheckNodeUnschedulablePredfactory.InsertPredicateKeyToAlgorithmProviderMap(predicates.CheckNodeUnschedulablePred)
}
定义fitPredicateMap用于保存预选算法
// k8s.io/kubernetes/pkg/scheduler/factory/plugins.govar (// maps that hold registered algorithm typesfitPredicateMap = make(map[string]FitPredicateFactory)
)
2.3.2 执行CheckNodeUnschedulablePred调度算法
源码可以看到,改算法实际是判断pod.Spec.Tolerations和node.spec.Unschedulable的值
// k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/predicates.go// CheckNodeUnschedulablePredicate checks if a pod can be scheduled on a node with Unschedulable spec.
func CheckNodeUnschedulablePredicate(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {// 参数检查if nodeInfo == nil || nodeInfo.Node() == nil {return false, []algorithm.PredicateFailureReason{ErrNodeUnknownCondition}, nil}// If pod tolerate unschedulable taint, it's also tolerate `node.Spec.Unschedulable`.// 判断pod是否有node.Spec.Unschedulable对应的"容忍"podToleratesUnschedulable := v1helper.TolerationsTolerateTaint(pod.Spec.Tolerations, &v1.Taint{Key: algorithm.TaintNodeUnschedulable,Effect: v1.TaintEffectNoSchedule,})// TODO (k82cn): deprecates `node.Spec.Unschedulable` in 1.13.// 检查node.spec.Unschedulable的值,如果node不可调度那么node.spec.Unschedulable的值为真if nodeInfo.Node().Spec.Unschedulable && !podToleratesUnschedulable {return false, []algorithm.PredicateFailureReason{ErrNodeUnschedulable}, nil}return true, nil, nil
}通过kubectl get node xxx -oyaml 观察某node节点中关于spec字段,CheckNodeUnschedulablePred就是通过改字段进行判断该节点是否会被过滤。

三、总结
本文我们分析源码中预选策略的调度过程的执行,同时看到了kube-scheduler为了解决节点数量太多而导致负载问题,而引入了PercentageOfNodesToScore控制参与预算调度过程的节点数量。之后介绍了如何修改该值,也介绍了通过修改源码并重新编译,观察debug过程。最后我还以CheckNodeUnschedulablePred预选算法,追溯了该算法的注册到执行的过程。