目录
0. 回忆
1.隐式类型转化
特性 1.统一的列表初始化
1.{}初始化
2.2 std::initializer_list
二、声明
1.auto
2.decltype
3.nullptr
宏定义的例子
使用 const 和 enum 替代宏
4. 范围 for 循环
5.final与override
final 关键字
override 关键字
示例代码
智能指针
6. STL 中的一些变化
array
forward_list
unordered_map
使用 unordered_map 的基本步骤:
示例:
unordered_set
使用 unordered_set 的基本步骤:
示例:
注意事项:
新接口(4 点)
- 1998 C++98 5 年计划
- 2003 C++03 修复之前问题
- 2007 C++07 为爱发电的语言,并没有出来
Java sun->甲骨文收购 商业化语言
- 2011 C++11
查询链接:cppreference.com
- 关于 C++23 的展望与对网络库的期待:C++23的目标 - 知乎 (zhihu.com)
0. 回忆
1.隐式类型转化
隐式类型转化(Implicit Type Conversion):编译器自动将一种数据类型转换为另一种数据类型的过程,而无需程序员明确指示。这种转换通常发生在以下几种情况下:
- 赋值兼容性:当一个值被赋给另一个类型兼容的变量时,编译器可能会自动进行类型转换。例如,将一个
int类型的值赋给一个double类型的变量。
int a = 5;
double b = a; // 隐式类型转换:int 转换为 double- 表达式中的类型提升:在表达式中,编译器可能会将较小的数据类型自动提升为较大的数据类型,以避免数据丢失。
int a = 5;
double b = 3.14;
double result = a + b; // 隐式类型转换:a 从 int 转换为 double- 函数调用:当传递给函数的实参与函数参数类型不匹配时,如果存在隐式转换路径,编译器会自动进行类型转换。
void func(double x) {// ...
}
int a = 10;
func(a); // 隐式类型转换:a 从 int 转换为 double- 算术运算:在进行算术运算时,编译器可能会将操作数转换为同一类型,以确保运算的正确性。
int a = 5;
float b = 2.5f;
float result = a * b; // 隐式类型转换:a 从 int 转换为 float隐式类型转换虽然方便,但也可能导致一些潜在的问题,比如精度损失、意外行为或难以发现的错误。因此,C++11 引入了 explicit 关键字来禁止某些构造函数或转换函数的隐式转换。
以下是一个使用 explicit 的例子:
class MyClass {
public:explicit MyClass(int value) {// ...}
};
MyClass obj = 10; // 错误:不允许隐式类型转换
MyClass obj(10); // 正确:显式调用构造函数在这个例子中,MyClass 的构造函数被标记为 explicit,因此不能使用隐式类型转换来初始化 MyClass 的对象。
一.统一的列表初始化
1.{}初始化
- 一切皆可用 {} 初始化
- 并且可以不写=
- 建议日常定义,不要去掉=,
int main()
{int x = 1;int y = { 2 };int z{ 3 };int a1[] = { 1,2,3 };int a2[] { 1,2,3 };// 本质都是调用构造函数Point p0(0, 0);Point p1 = { 1,1 }; // 多参数构造函数隐式类型转换Point p2{ 2,2 };const Point& r = { 3,3 };int* ptr1 = new int[3]{ 1,2,3 };Point* ptr2 = new Point[2]{p0,p1};Point* ptr3 = new Point[2]{ {0,0},{1,1} };return 0;
}- 优化的原理:多参数构造函数 隐式类型转换
- 括中括:初始化
Point* ptr3 = new Point[2]{ {0,0},{1,1} }; - 说明一点C++给{ }一个类型,是initializer_list类型,它会去匹配自定义类型的构造函数。
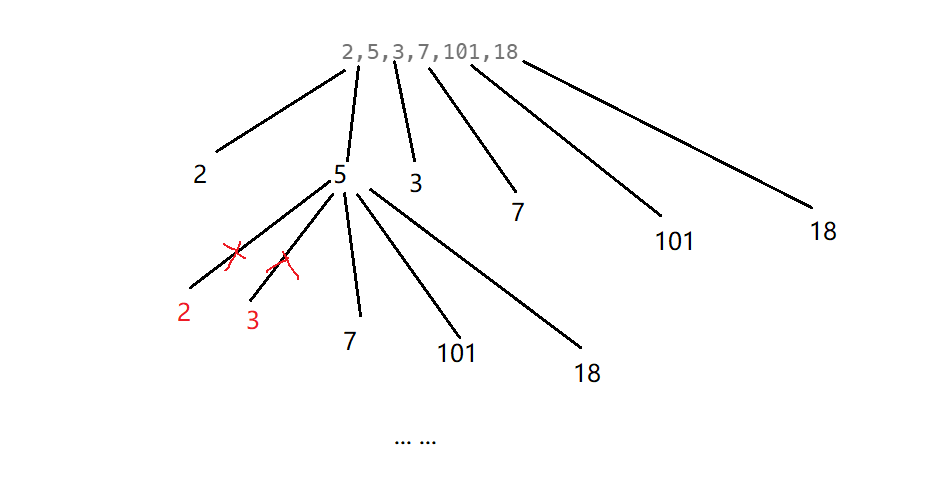
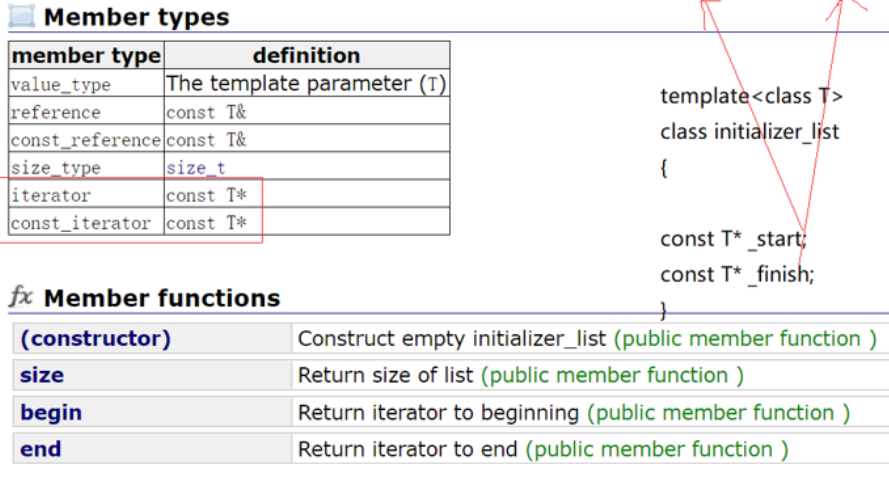
2.2 std::initializer_list
initializer_list<int> il = { 10, 20, 30 };的实现
- {10,20,30} 常量区数组,存在常量区的
- 本质还是调用 initializer_list 的构造函数,两个指针指向 空间的开始和结束,可以类型识别
- auto 也是这个默认 10 30
不同的规则
vector<int> v1 = { 1,2,3,4,3};// 默认调用initializer_list构造函数,隐式类型转换,可扩容
隐式类型转换是指编译器自动将初始化列表转换为一个 initializer_list 类型的对象,然后传递给 vector 的构造函数。这个转换过程是自动的。
Point p1 = { 1,1};// 直接调用两个参数的构造 -- 隐式类型转换,所以无法无限扩容
int main()
{vector<int> v1 = { 1,2,3,4,3}; // 默认调用initializer_list构造函数,隐式类型转换Point p1 = { 1,1}; auto il = { 10, 20, 30 };//initializer_list<int> il = { 10, 20, 30 };cout << typeid(il).name() << endl;cout << sizeof(il) << endl;bit::vector<int> v2 = { 1,2,3,4,54};for (auto e : v2){cout << e << " ";}cout << endl;return 0;
}- vector 底层调用的也是 initializer_list 的构造

2.对于 map 隐式类型转化也要括中括,因为默认有 pair 和 initializer 两个识别类型
//里面{}是调用日期类的构造函数生成匿名对象
//外面{}是日期类常量对象数组,去调用vector支持initializer_list的构造函数
vector<Date> v = { {1,1,1},{2,2,2},{3,3,3} };//里面{}调用pair的构造函数生成pair匿名对象
//外面{}是pair常量对象数组,去调用map支持initializer_list的构造函数
map<string, string> dict = { {"sort","排序"},{"string","字符串"} };
3.注意容器initializer_list不能直接引用,必须加const,因为可以认为initializer_list是由常量数组转化得到的,临时对象具有常性。
//构造
List(const initializer_list<T>& l1)
{empty_initialize();for (auto& e : l1){push_back(e);}
}二、声明
1.auto
自动识别,定义变量
2.decltype
typeid().name() 打印识别类型,只能看一看
decltype 相对于 auto 就不一定要定义时传值了,主要有三点运用场景如下
template<class Func>
class B
{
private:Func _f;
};
int main()
{int i = 10;auto p = &i;auto pf = malloc;//auto x;cout << typeid(p).name() << endl;cout << typeid(pf).name() << endl;// typeid(pf).name() ptr; typeid推出类型是一个字符串,只能看不能用auto pf1 = pf;// decltype推出对象的类型,再定义变量,或者作为模板实参//1. 单纯先定义一个变量出现decltype(pf) pf2;//2.传类函数B<decltype(pf)> bb1;const int x = 1;double y = 2.2;//3.识别返回值类型B<decltype(x * y)> bb2;return 0;
}3.nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示 整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
这里是C++的一个bug,使用NULL可能在类型匹配的时候出现问题,比如你期望匹配成指针结果匹配成了0。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif尽量用const enum inline去替代宏,如下
宏定义的例子
传统的宏定义可能如下所示:
#define PI 3.14159
#define MAX_SIZE 100
#define ADD(a, b) ((a) + (b))使用 const 和 enum 替代宏
使用 const 和 enum 关键字可以提供类型安全,并且能够更好地与命名空间和作用域规则集成。
// 使用 const 替代数值宏
const double PI = 3.14159;// 使用 enum 替代数值宏
enum { MAX_SIZE = 100 };// 函数宏可以使用 inline 函数替代
inline int add(int a, int b) {return a + b;
}4. 范围 for 循环
这个我们在前面的课程中已经进行了非常详细的讲解,这里就不进行讲解了,请参考 C++ 入门 + STL 容器部分的课件讲解。
5.final与override
详见在继承和多态的时候说过。
在C++中,final 和 override 关键字是在C++11标准中引入的,用于增强对继承和多态的支持。下面将通过一个简单的例子来演示这两个关键字的使用。
final关键字
final 关键字用于指定一个类不能被继承,或者一个虚函数不能被重写。
override关键字
override 关键字用于指示一个成员函数打算重写一个虚函数。如果基类中没有匹配的虚函数,编译器将报错。
示例代码
#include <iostream>
// 基类
class Base {
public:// 声明一个虚函数virtual void show() {std::cout << "Base show function called." << std::endl;}// 声明一个虚析构函数virtual ~Base() {}
};
// 派生类
class Derived : public Base {
public:// 使用 override 关键字表明这是对基类虚函数的重写void show() override {std::cout << "Derived show function called." << std::endl;}// 使用 final 关键字表明这个函数不能在子类中被重写virtual void print() final {std::cout << "Derived print function called." << std::endl;}
};
// 尝试从 Derived 派生一个新的类
class MoreDerived : public Derived {
public:// 尝试重写 final 函数,这将导致编译错误// void print() {// std::cout << "MoreDerived print function called." << std::endl;// }
};
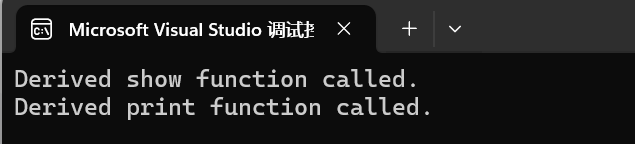
int main() {Base* b = new Derived();b->show(); // 输出 "Derived show function called."Derived* d = new Derived();d->print(); // 输出 "Derived print function called."delete b;delete d;return 0;
}
智能指针
后面专门说这个智能指针。
6. STL 中的一些变化
- 新容器
-
- 用橘色圈起来的是 C++11 中的一些新容器,但实际上最有用的是
unordered_map和unordered_set。这两个我们前面已经进行了非常详细的讲解,其他的大家可以了解一下即可。
- 用橘色圈起来的是 C++11 中的一些新容器,但实际上最有用的是

array

数组是直接的指针解引用,array 的设置就存在了越界的内部监查
说比较鸡肋是因为 vector<int> a(10,0)更香,甚至还能初始化
int a1[10];array<int, 10> a2;cout << sizeof(a1) << endl;cout << sizeof(a2) << endl;a1[15] = 1; // 指针的解引用a2[15] = 1; // operator[]函数调用,内部检查// 用这个也可以,显得array很鸡肋vector<int> a3(10, 0);forward_list
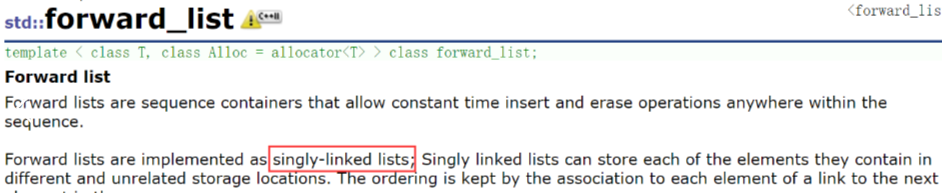
- 只有单向迭代器
只提供头插头删,没有提供尾插尾删,因为每次都要找尾不方便!并且insert,erase也是在结点后面插入和删除。 - 对比list只有每个结点节省一个指针的优势,其他地方都没有list好用!
C++11更新真正有用的是unordered_map和unordered_set,前面都学过这里不细说了。
unordered_map 和 unordered_set 是 C++ 标准库中的两个容器,它们都是基于哈希表实现的。这两个容器提供了平均常数时间复杂度的查找、插入和删除操作,前提是哈希函数能够很好地分布元素。
unordered_map
unordered_map 是一种关联容器,它存储键值对,其中键是唯一的。它允许快速检索与每个键相关联的数据。
使用 unordered_map 的基本步骤:
- 包含头文件
<unordered_map>。 - 创建
unordered_map容器。 - 使用
insert或operator[]插入键值对。 - 使用
find或operator[]查找元素。 - 使用迭代器遍历容器。
示例:
#include <iostream>
#include <unordered_map>
int main() {// 创建一个unordered_map,键和值都是int类型std::unordered_map<int, int> umap;// 插入键值对umap.insert(std::make_pair(1, 100));umap[2] = 200; // 使用operator[]插入,如果键不存在则创建// 查找元素auto search = umap.find(2);if (search != umap.end()) {std::cout << "Found " << search->first << " with value " << search->second << std::endl;} else {std::cout << "Not found" << std::endl;}// 遍历unordered_mapfor (const auto& pair : umap) {std::cout << pair.first << ": " << pair.second << std::endl;}return 0;
}
unordered_set
unordered_set 是一种集合容器,它存储唯一的元素,并且这些元素是无序的。
使用 unordered_set 的基本步骤:
- 包含头文件
<unordered_set>。 - 创建
unordered_set容器。 - 使用
insert插入元素。 - 使用
find查找元素。 - 使用迭代器遍历容器。
示例:
#include <iostream>
#include <unordered_set>
int main() {// 创建一个unordered_set,存储int类型std::unordered_set<int> uset;// 插入元素uset.insert(100);uset.insert(200);// 查找元素if (uset.find(200) != uset.end()) {std::cout << "Found 200" << std::endl;} else {std::cout << "Not found" << std::endl;}// 遍历unordered_setfor (const auto& element : uset) {std::cout << element << std::endl;}return 0;
}
注意事项:
unordered_map和unordered_set的性能高度依赖于哈希函数的质量和桶的数量。如果哈希函数导致许多冲突,性能可能会下降到与链表相似。是无序的- 当插入元素时,如果元素已经存在,
unordered_map会更新该键的值,而unordered_set会忽略新插入的元素,因为它只存储唯一的元素。 unordered_map和unordered_set通常比基于树的容器(如map和set)在大多数操作上更快,因为它们提供了平均常数时间复杂度的性能。然而,在某些特定情况下,基于树的容器可能提供更好的性能,特别是当元素数量较少时。
容器中的一些新方法
- 如果我们再细细去看,会发现基本上每个容器中都增加了一些 C++11 的方法,但实际上很多都是用得比较少的。
- 比如提供了
cbegin和cend方法返回 const 迭代器等等,但实际上意义不大,因为begin和end也是可以返回 const 迭代器的,这些都是属于锦上添花的操作。 - 实际上 C++11 更新后,容器中增加的新方法最常用的是插入接口函数的右值引用版本。
新接口(4 点)
- iterators 中觉得调用迭代器的const版本和非const版本不明显,就新增下面的,不过确实很鸡肋。

2. 所有容器均支持{}列表初始化的构造函数,包括自定义的类

⭕3. 黑科技:所以容器均新增了 emplace 系列接口-->性能提升

右值引用,模板的可见参数
甚至对于 push/insert,增加了一个重载的右值引用
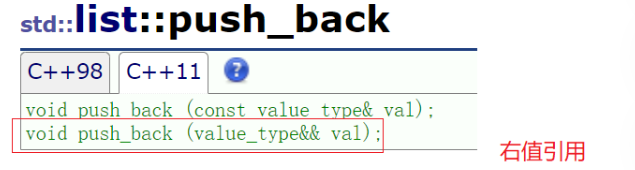
4.增加了移动构造和移动赋值,提高了深拷贝的效率
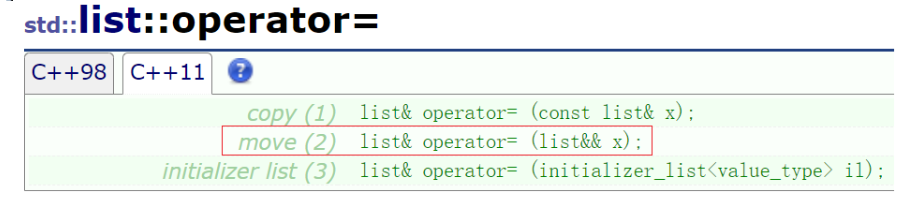
❓ move 是实现了常量化吗?还有关于右值引用,移动构造的知识,下篇我们将详细讲到~





![[米联客-XILINX-H3_CZ08_7100] FPGA程序设计基础实验连载-24 TPG图像测试数据发生器设计](https://i-blog.csdnimg.cn/direct/96f5dbecc8654442a4ac28421b147546.png)