前情回顾:
【C++11 新增语法(1):1~6 点】
C++11出现与历史、花括号统一初始化、initializer_list初始化列表、 auto、decltype、nullptr、STL的一些新变化
【C++11 新增语法(2):7~8 点】
右值引用和移动语义∶移动构造和移动赋值、move 函数、左值引用的短板、万能引用、完美转发、push_back 函数重载右值引用版本(借助list的push-back 使用举例)﹔新增两个默认类函数与delete关键字
【C++11 新增语法(3):9~10 点】
可变参数模板:参数包的用法、参数包展开的几种方法;
emplace_back 函数:为什么该函数会比 push_back 高效
⭐⭐本文会使用到自己模拟实现的 string 和 list 类,为了更好的观察各种函数的构造过程,建议先将本文最后的 string 和 list 代码拷贝下来创建一个 string.h / list.h 文件
11 lambda表达式
11.1 C++98 中的一个例子
在 C++98 中,如果想要对一个数据集合中的元素进行排序,可以使用函数模板 std::sort方法。
#include <algorithm>
#include <functional>
int main()
{int array[] = { 4,1,8,5,3,7,0,9,2,6 };// 默认按照小于比较,排出来结果是升序std::sort(array, array + sizeof(array) / sizeof(array[0]));// 如果需要降序,需要改变元素的比较规则std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());return 0;
}如果待排序元素为自定义类型,需要用户定义排序时的比较规则:
#include<algorithm>
struct Goods
{string _name; // 名字double _price; // 价格int _evaluate; // 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}
};// 小于号:价格升序
struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};// 大于号:价格降序
struct ComparePriceGreater
{bool operator()(const Goods& gl, const Goods& gr){return gl._price > gr._price;}
};int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };sort(v.begin(), v.end(), ComparePriceLess()); // 按价格升序sort(v.begin(), v.end(), ComparePriceGreater()); // 按价格降序
}随着 C++ 语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法,
都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,
这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式。
11.2 lambda表达式
使用 lambda 表达式后的 sort:想要按照什么排序,直接自定义,也无需多写一个结构体
int main()
{vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } };// 想要按照什么排序,直接自定义,也无需多写一个结构体// 价格升序sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price < g2._price; });// 价格降序sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._price > g2._price; });// 评价分数升序sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._evaluate < g2._evaluate;});// 评价分数降序sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {return g1._evaluate > g2._evaluate;});
}上述代码就是使用C++11中的lambda表达式来解决,可以看出lambda表达式实际是一个匿名函
数。
11.3 lambda表达式使用语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }

1. lambda表达式各部分说明
⭐[capture-list] : 捕捉列表,该列表总是出现在 lambda 函数的开始位置,编译器根据[]
来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供 lambda
函数使用。
⭐(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以
连同()一起省略
⭐mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。
使用该修饰符时,参数列表不可省略(即使参数为空)。
⭐->return-type:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回
值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
⭐{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获
到的变量。
举个例子:
借助一个仿函数写出一个 lambda表达式

注意:
在 lambda 函数定义中,借助一个函数来理解和讲解:
因为一个函数可以没有 函数参数 和 返回值(即void),因此也可以省略不写
(注意:lambda 表达式的返回值它会自动识别,因此返回值可写可不写,为了可读性,建议写)
方括号的那个 捕捉列表必须写出方括号,至于这个怎么用,下面会讲解
因此C++11中最简单的lambda函数为下面这样,该lambda函数不能做任何事情。
[]() {//....
};各种结构的 lambda表达式
int main()
{// 最简单的lambda表达式, 该lambda表达式没有任何意义[] {};// 省略参数列表和返回值类型,返回值类型由编译器推导为intint a = 3, b = 4;[=] {return a + 3; };// 省略了返回值类型,无返回值类型auto fun1 = [&](int c) {b = a + c; };fun1(10)cout << a << " " << b << endl;// 各部分都很完善的lambda函数auto fun2 = [=, &b](int c)->int {return b += a + c; };cout << fun2(10) << endl;// 复制捕捉xint x = 10;auto add_x = [x](int a) mutable { x *= 2; return a + x; };cout << add_x(10) << endl;return 0;
}通过上述例子可以看出,lambda 表达式实际上可以理解为无名函数,或者理解成 匿名函数
(和匿名对象类似)该函数无法直接调用,如果想要直接调用,可借助 auto 将其赋值给一个
变量。
2. 捕捉列表说明
捕捉列表描述了上下文中哪些数据可以被 lambda 使用,以及使用的方式传值还是传引用
(通俗讲,lambda只能使用捕捉列表、lambda域 和 全局域的数据,若想要使用外部的局部域的变量,可以使用 捕捉列表 捕捉进来使用)
[var]:表示值传递方式捕捉变量 var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量 var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:
a. 父作用域指 包含 lambda 函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
演示:
(1)演示 lambda表达式的 哪些数据可以被使用 以及 传值和传引用
int main() {// 1、lambda 表达式中只能使用 当前 lambda 局部域 和 捕捉的对象int a = 0, b = 1;auto swap1 = [](int& x, int& y) {// x = a; // 报错:a 存在父作用域,即外面的main函数局部域中的变量,不属于 lambda 局部域 和 捕捉的对象,因此不能使用int tmp = x;x = y;y = tmp;};swap1(a, b);// 2、使用捕捉列表捕捉想要使用的变量:[a, b]// 捕捉 a 和 b,这里没有传参,而是专门对 a 和 b 进行操作// 其次,捕捉的变量,默认为 const 类型,要加上 mutable ,表示去除 const 常性// 传值:lambda表达式中的 a 和 b,本质是外面的 a 和 b 临时拷贝,相当于函数传形参,对形参的 a 和 b 操作不会影响外面的 a 和 b,因此 这里交换操作实际上没有进行auto swap2 = [a, b]()mutable {int tmp = a;a = b;b = tmp;};swap2();// 传引用:取别名,相当函数传实参// 这里就不用写 mutable 了,mutable 是为了解除参数的常性,引用本就不是常性auto swap3 = [&a, &b] {int tmp = a;a = b;b = tmp;};swap3();return 0;
}(2)演示 [data]、[=]、[&data]、[&] 的使用 即 混合搭配使用
int x = 0; // 全局变量
int main()
{// 只能用当前lambda局部域和捕捉的对象和全局对象int a = 0, b = 1, c = 2, d = 3;// 1、所有值传值捕捉// 将外面区域中所有变量,以传值的方式 捕捉auto func1 = [=]{int ret = a + b + c + d + x; // x 是全局的return ret;};// 2、所有值传引用捕捉// 将外面区域中所有变量,以传引用的方式 捕捉auto func2 = [&]{a++;b++;c++;d++;int ret = a + b + c + d;return ret;};// 3、混合捕捉:可以自己根据需求搭配// 变量b 以传值捕捉,其他的所有变量 传引用捕捉auto func3 = [&a, b]{a++;// b++;int ret = a + b;return ret;};// 所有值以传引用方式捕捉,d用传值捕捉auto func4 = [&, d]{a++;b++;c++;//d++;int ret = a + b + c + d;};// 所有值以传值方式捕捉,d用传引用捕捉auto func5 = [=, &d]() mutable{a++;b++;c++;d++;int ret = a + b + c + d;};return 0;
}(3)【总结与本质】捕捉列表的运用
lambda 只能使用 当前 lambda 局部域 和 捕捉的对象 以及 全局域的
如下不能使用 外面的 main 函数局部变量
一般不会使用 mutable,容易使程序具有误导性
如果要修改外面的变量,直接传引用 [&]、[&a, &b]
如果不要修改,直接传值 [=]、[a, b]
如果针对某个变量,直接其他的传值,a 传引用 或 其他的传引用,a 传值 [=, &a] 或 [&, a]
本质:
只有 lambda 表达式里面用到的变量,会被传进来,不会因为使用 [=] 或 [&] 而把所有变量都传进来(编译器提高效率的技巧)
捕捉列表的对象是作为成员变量存在 lambda 类对象中
捕捉的本质是构造函数的初始化参数
11.4 lambda表达式的底层
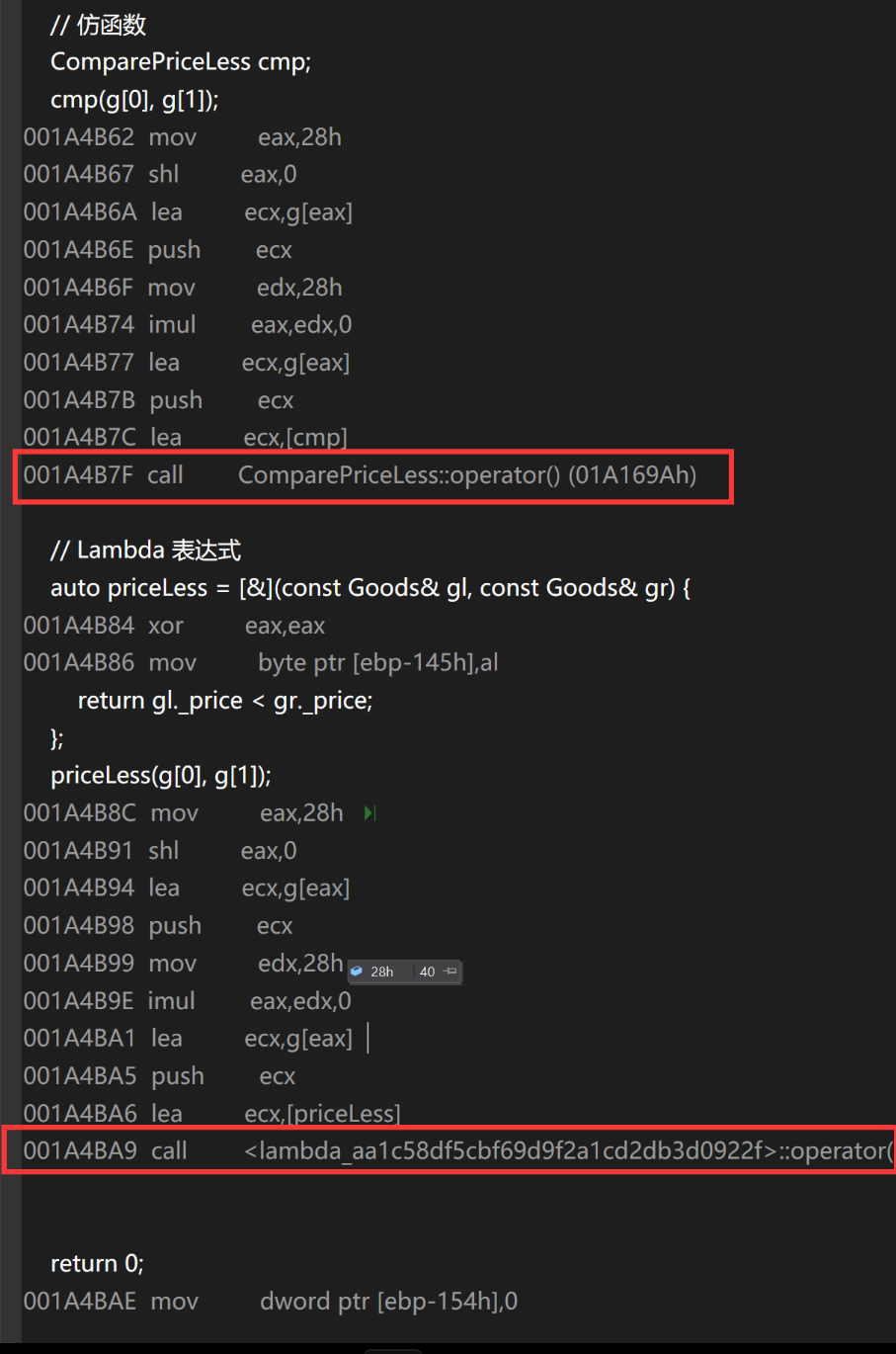
(1)底层其实就是仿函数
汇编层面看,底部都调用了 类中的 operator() ,即仿函数
函数对象,又称为仿函数,即可以想函数一样使用的对象,就是在类中重载了operator()运算符的
类对象。
lambda表达式其实底层就是一个 函数对象
在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如
果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
struct Goods
{string _name; // 名字double _price; // 价格Goods(const char* str, double price):_name(str), _price(price){}
};struct ComparePriceLess
{bool operator()(const Goods& gl, const Goods& gr){return gl._price < gr._price;}
};int main() {Goods g[] = { {"apple", 11}, {"pear", 9} };// 仿函数ComparePriceLess cmp;cmp(g[0], g[1]);// Lambda 表达式auto priceLess = [&](const Goods& gl, const Goods& gr) {return gl._price < gr._price;};priceLess(g[0], g[1]);return 0;
}
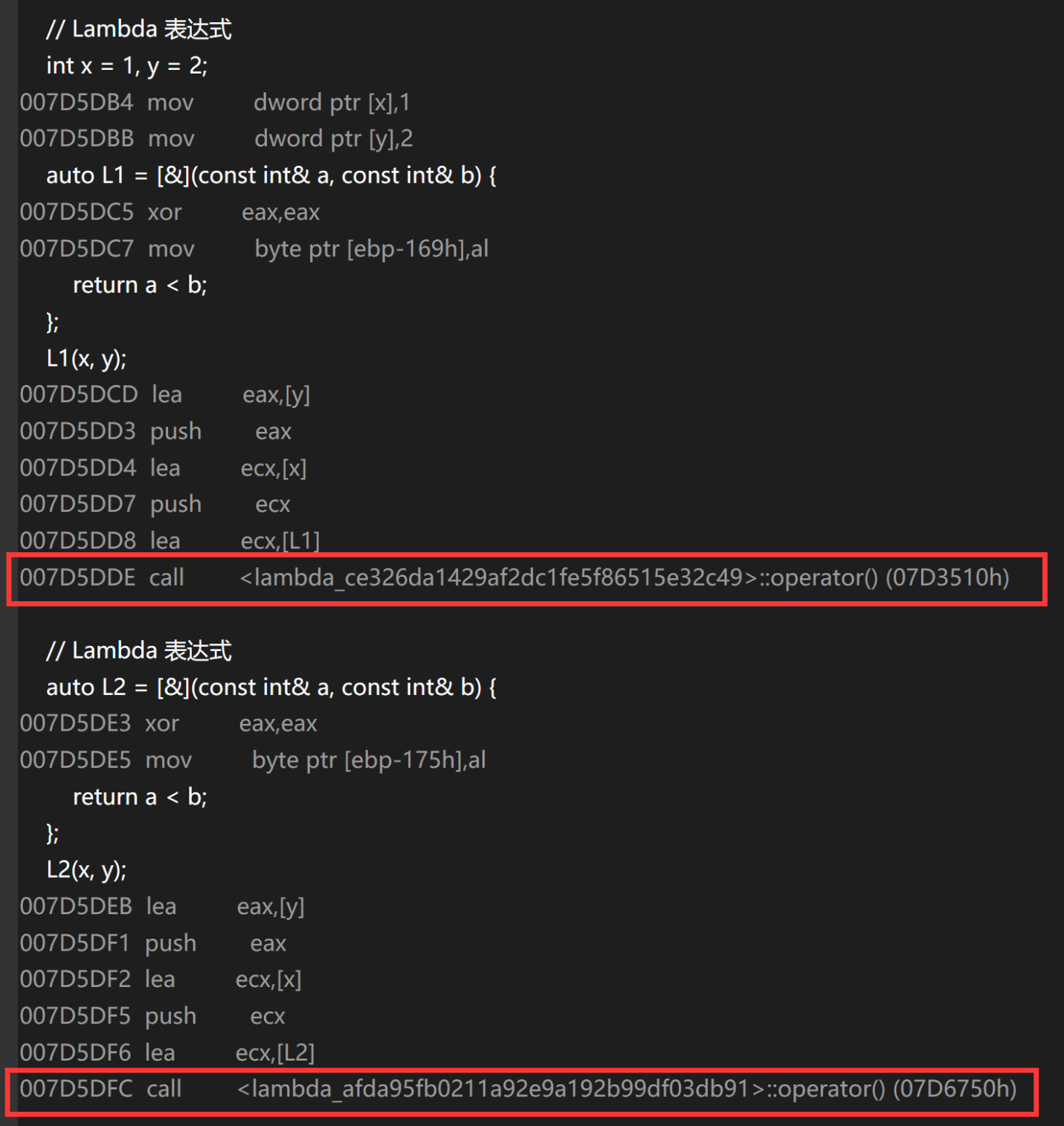
(2)每个lambda 表达式都是唯一的
每个 lambda 表达式都有自己唯一的名字(即带有一个很长的字符串 uuid 码)
即使内容完全相同,也是唯一的
因此:lambda表达式之间不能相互赋值,即使看起来类型相同
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写
相当于每一个 lambda 表达式有自己的身份证号
int main() {// Lambda 表达式int x = 1, y = 2;auto L1 = [&](const int& a, const int& b) {return a < b;};L1(x, y);// Lambda 表达式auto L2 = [&](const int& a, const int& b) {return a < b;};L2(x, y);
}
12 包装器
12.1 function 包装器
(1)概念与具体实操使用(借助 游戏运行 与 LeetCode 题目 讲解用法)
function包装器 也叫作适配器。C++中的 function 本质是一个类模板,也是一个包装器。
那么我们来看看,我们为什么需要function呢?

可调用类型对象都可以使用 function 包装
可调用类型对象包括:函数名(函数指针)、函数对象(仿函数对象)、lamber表达式对象
function 包装可调用对象的 写法:
参数列表:括号外面的 int 对应可调用对象的返回值类型,括号里面的 int 则一一对应可调用对象参数的 类型(按顺序写)

#include <functional>size_t Function(const size_t& a, const size_t& b) {return a + b;
}struct Functor
{size_t operator()(const size_t& a, const size_t& b) {return a + b;}
};int main() {// 将可调用对象包装在一个 包装器中function<int(int, int)> f1 = Function; // 函数指针:普通函数名就是函数指针,成员函数需要取地址&function<int(int, int)> f2 = Functor(); // 函数对象:仿函数对象function<int(int, int)> f3 = [](const size_t& a, const size_t& b)->int { // lambda 表达式return a + b;};int x = 10, y = 20;cout << f1(x, y) << '\n';cout << f2(x, y) << '\n';cout << f3(x, y) << '\n';return 0;
}
包装器,将 一个可调用的功能接口 包装成一个 模块,直接需要时调用该模块即可,相当于工具包,你无需知道这个工具的具体实现逻辑(即无需像使用 lambda表达式,需要重新写一遍),直接可以拿来用,还是很方便的!
举个例子,像是王者荣耀操作英雄,每个英雄有几个技能,当你键盘或手指点击某个技能,则底层就会对应向系统发送某个指令,调用该技能 运行展示的函数,如 亚瑟一技能是强化普攻和加速追踪,若按键按下,响应了就会向系统发送某个 字符指令,系统就调用这个技能 的运行模块,使英雄具有这个效果展示
这其中展示出一种,命令与相关功能相互映射的关系,命令发出,则调用该命令映射的功能模块
我们以具体例题讲解:
像是 LeetCode 150. 逆波兰表达式求值 中每种运算符,对应一种计算逻辑,我们就可以将 运算符 和 计算逻辑 形成映射关系,需要该使用运算符,就调用对应的功能
150. 逆波兰表达式求值
题目:
写法思路是:遍历字符串数组,遇到数字放进栈,遇到运算符 取出栈顶的两个数字出来计算结果,结果再放回去,最后遍历完成后,栈中的最后一个数字即为 最终结果
下面是两种代码写法:
一般代码写法是:
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<long long>stk;long long a, b;long long result;for (int i = 0; i < tokens.size(); ++i) {if(tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/"){a = stk.top(); stk.pop();b = stk.top(); stk.pop();// 注意是先b后a:和数值放入栈的顺序有关if (tokens[i] == "+") stk.push(b + a);if (tokens[i] == "-") stk.push(b - a);if (tokens[i] == "*") stk.push(b * a);if (tokens[i] == "/") stk.push(b / a);}else {stk.push(stoll(tokens[i]));}}long long ans = stk.top();return ans;}
};使用 function 包装器的写法:
将各个运算符 及其 对应功能 建立map映射关系,遍历到该运算符,直接调用对应功能,直接了断
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int>stk;int a, b;map<string, function<int(int, int)>> opFuncMp = {{"+", [](const int& x, const int& y){return x + y;}},{"-", [](const int& x, const int& y){return x - y;}},{"*", [](const int& x, const int& y){return x * y;}},{"/", [](const int& x, const int& y){return x / y;}}};for (int i = 0; i < tokens.size(); ++i) {//if(tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/")if(opFuncMp.count(tokens[i])) // 使用 count 检查当前的map是否有这个键值{a = stk.top(); stk.pop();b = stk.top(); stk.pop();// 注意是先b后a:和数值放入栈的顺序有关int ret = opFuncMp[tokens[i]](b, a); // operator[] 调用运算符对应的 function 操作stk.push(ret);}else {stk.push(stoi(tokens[i]));}}int ans = stk.top();return ans;}
};(2)function 包装成员函数(静态和非静态)
成员函数分为:静态成员函数 和 非静态成员函数(普通成员函数)
使用 function 包装 成员函数都要加上 类域指定(类内就不用)
包装 非静态成员函数, 取函数指针时 要加上 取地址&:可以理解成一种语法规定
包装 静态成员函数可以不用加,也可以加上,建议加上,和非静态的保持一致
class Cal
{
public:size_t add(const size_t& a, const size_t& b) {return a + b;}static size_t mul(const size_t& a, const size_t& b) {return a * b;}};int main() {int x = 10, y = 20;// 包装静态成员函数function<int(int, int)> f1 = Cal::mul;f1(x, y);// 包装普通成员函数// 直接写会报错:因为参数没有对齐,还有一个隐含的 this 指针function<int(int, int)> f2 = &Cal::add; // 报错:按照常理这里参数应该都匹配上了,报错是因为忽略了非静态成员函数还有一个隐含的 this 指针,因此下面的使用都加上第一个// 1、创建类对象,调用时传该类对象的&, 表示this指针function<int(Cal*, int, int)> f2 = &Cal::add;Cal c1;f2(&c1, x, y);// 2、直接传匿名对象地址function<int(Cal*, int, int)> f3 = &Cal::add;f3(&Cal(), x, y);// 3、只传对象及其类型也行function<int(Cal, int, int)> f4 = &Cal::add;Cal c2;f4(c2, x, y); // 传普通对象f4(Cal(), x, y); // 传匿名对象// 为什么传 this 指针 和 传对象都行?// 注意,function 的底层是获取到 右边的函数指针或仿函数等其他的可调用对象,然后将其设置成 function的成员变量(function底层是仿函数)// 当需要使用该函数指针时,再通过 第一个参数 对象或this指针 来调用该 函数指针// 因此这里的 this指针 及其他参数并不是被function直接传给 右边的可调用对象的// 总结:为什么传 this 指针 和 传对象都行,是因为不是直接传参,而是使用 this 指针 和 传对象 为了调用对应的函数指针 return 0;
}12.2 bind 包装器(绑定)
std::bind 函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可
调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。
一般而言,我们用它可以把一个原本接收 N 个参数的函数 fn,通过绑定一些参数,返回一个接收M个(M可以大于N,但这么做没什么意义)参数的新函数(下面都会演示)。同时,使用std::bind函数还可以实现参数顺序调整等操作。

(1)用途与使用方法
可以将bind函数看作是一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对
象来“适应”原对象的参数列表。
调用 bind 的一般形式:auto newCallable = bind(callable,arg_list);
其中,newCallable 本身是一个可调用对象,arg_list是一个逗号分隔的参数列表(在模板中就是可变参数模板),对应给定的 callable 的参数。当我们调用newCallable时,newCallable会调用callable,并传给它 arg_list 中的参数。
参数列表 arg_list 中的参数会用 _1、_2、_3、_4....、_n 这种参数表示,这些参数,表示 newCallable 的参数,它们占据了传递给 newCallable 的参数的“位置”。这种参数叫做 placeholders ,
placeholders 是一个命名空间,表示一种序号,主要是配合 bind 使用,例如 _1 就表示函数调用newCallable 的第一个实参, _2 就表示函数调用 newCallable 的第二个实参

bind 的用途一:调整参数顺序
下面代码,相同的函数调用,结果不同,就是因为 bind 修改了函数调用参数的顺序
// bind
struct Sub
{int operator()(const int& x, const int& y) {return (x - y) ;}
};using placeholders::_1;
using placeholders::_2;
using placeholders::_3;int main() {// 因为bind返回可调用对象,直接用 auto 接收即可// 1、调整参数顺序auto sub1 = bind(Sub(), _1, _2); // 第一个参数 Sub() 就是可调用对象,其他参数为函数调用sub1的第一个第二个参数cout << sub1(10, 20) << '\n';auto sub2 = bind(Sub(), _2, _1);cout << sub2(10, 20) << '\n';return 0;
}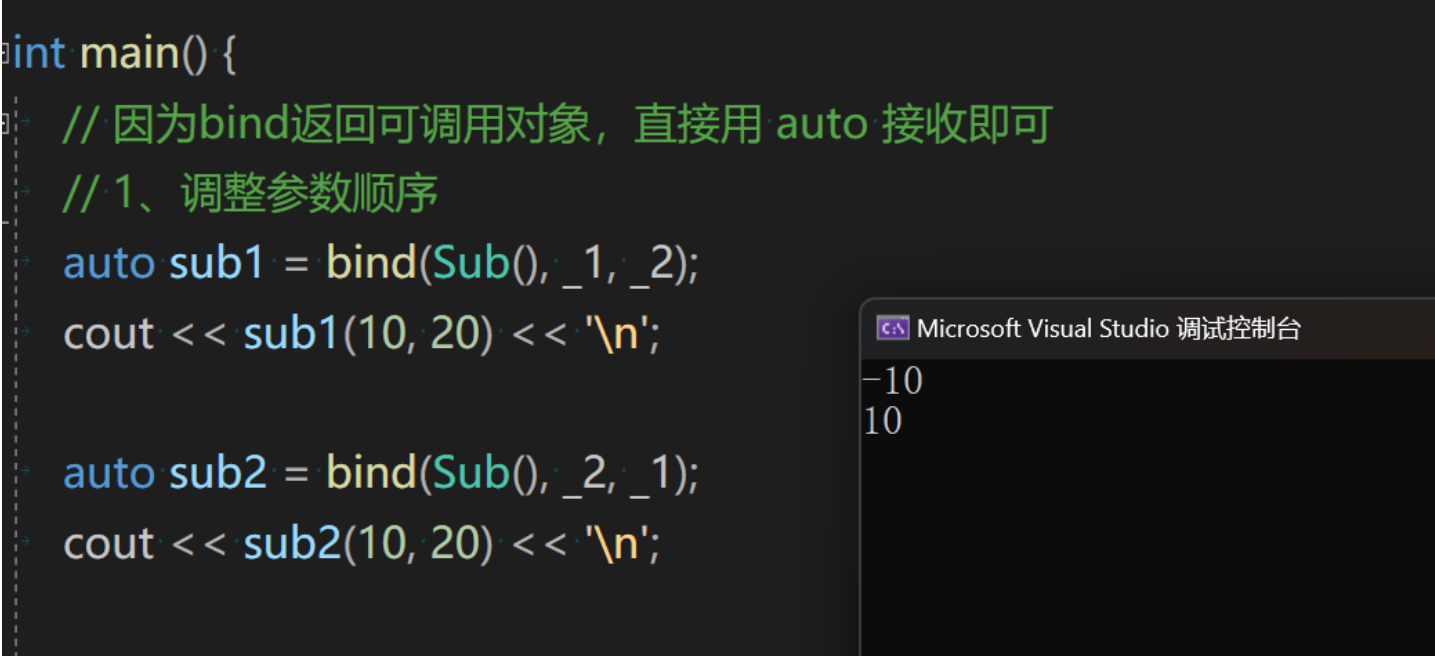
_1 代表第一个实参, _2 代表第二个实参,调用 仿函数 Sub 时传递参数的顺序就是 bind 中 _1 和 _2 的顺序,因此可以调整顺序
相当于 placeholder 的 _1 直接绑定 函数调用sub中第一个参数, _2 直接绑定 函数调用sub中第二个参数,因此 sub2 中将 _1 和 _2 交换位置就表示两个传值(10, 20)交换位置

bind 的用途二:调整参数个数
struct Sub
{int operator()(const int& x, const int& y) {return (x - y) ;}
};int SubX(int a, int b, int c)
{return (a - b - c);
}using placeholders::_1;
using placeholders::_2;
using placeholders::_3;int main() {// 2、调整参数个数// 固定一个参数 100,函数调用只需传一个参数 10// 通过 _1(代表第一个函数调用参数)的顺序,来操作auto sub3 = bind(Sub(), 100, _1); // 把Sub的第一个参数 x 绑死cout << sub3(10) << '\n';auto sub4 = bind(Sub(), _1, 100); // 把Sub的第二个参数 y 绑死cout << sub4(10) << '\n';// 分别绑死第123个参数(我们这里调用的是函数:可调用对象可以是函数指针、仿函数、lambda)auto sub5 = bind(SubX, 100, _1, _2);cout << sub5(5, 1) << endl;auto sub6 = bind(SubX, _1, 100, _2);cout << sub6(5, 1) << endl;auto sub7 = bind(SubX, _1, _2, 100);cout << sub7(5, 1) << endl;cout << "\n\n\n\n\n";return 0;
}(2)bind 的应用(结合 function 讲解 “计算年利息”)
using placeholders::_1;
using placeholders::_2;
using placeholders::_3;int main() {bind一般用于,绑死一些固定参数前面学习的 function 包装类成员函数,需要传this指针或该类对象作为参数,这个是固定的参数因此,可以使用 bind ,将该参数绑定给 function//function<double(double, double)> f7 = bind(&Cal::add, Cal(), _1, _2);//cout << f7(1.1, 1.1) << endl;// bind 的应用:专门用于绑定一些固定的参数,用户只需输入变量,不用理会定量,便利性和可读性大大提升// 计算年利息:利息=本金×年数×年利率auto f8 = [](const double& rate, const int& year, const int& amount)->double {return amount * year * rate;};// f_3_1p5:表示 3 年 1.5%利率function<double(double)> f_3_1p5 = bind(f8, 0.015, 3, _1);function<double(double)> f_5_2p5 = bind(f8, 0.025, 5, _1);function<double(double)> f_10_3p5 = bind(f8, 0.035, 10, _1);cout << "3年期,1.5%的年利率的可得利息: " << f_3_1p5(10000) << '\n';cout << "5年期,2.5%的年利率的可得利息: " << f_5_2p5(10000) << '\n';cout << "10年期,3.5%的年利率的可得利息: " << f_10_3p5(10000) << '\n';cout << "\n\n\n\n\n";return 0;
}