1、集合类图

1)ArrayList与LinkedList 区别

LinkedList 实现了双向队列的接口,对于数据的插入速度较快,只需要修改前后的指向即可;ArrayList对于特定位置插入数据,需要移动特定位置后面的数据,有额外开销
public class Test {public static void main(String[] args) {List<String> list = new ArrayList<String>();list.add("a");list.add("b");list.add("c");list.add(1,"d");//相对LinkedList插入速度较慢System.out.println(list);System.out.println(list.get(1));//直接通过数据下标index获取数据,查询速度相对LinkedList较快List<String> linkedList = new LinkedList<>();linkedList.add("a");linkedList.add("b");linkedList.add("c");linkedList.add(2,"d");//相对ArrayList插入速度较快System.out.println(linkedList.get(1));//需要遍历整个队列,查询速度相对ArrayList较慢System.out.println(linkedList);}
}2)Set 存储的元素不重复,元素重复的标准如下:
i:先判断集合元素的hashCode是否在集合里面存在,不存在认为是不重复的,直接插入进集合,插入集合的位置按照hash出来散列值排序 ii:如果集合元素的hashCode在集合里面存在,需要再判断集合元素的内容是否一致(存在hash冲突,即不同的元素hash后产生相同的hashCode),调用equals方法,如果内容不一致,可以插入 iii:调用equals方法,如果内容一致,说明是重复,则不插入集合
import lombok.AllArgsConstructor;
import lombok.Data;import java.util.Objects;@Data
@AllArgsConstructor
public class Student {private String num;//学号private String name;private int age;@Overridepublic int hashCode() {return num.hashCode();//用学号计算hashCode}@Overridepublic boolean equals(Object o) { //学号、姓名、年龄完全一致才认为是相同学生if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(num, student.num) && Objects.equals(name, student.name);}@Overridepublic String toString() {return this.hashCode() + "-Student{" +"num='" + num + '\'' +", name='" + name + '\'' +", age=" + age +'}';}
}import java.util.*;public class Test {public static void main(String[] args) {Set<Student> set = new HashSet<Student>();/*** set集合里面内容不可重复,判断重复的标准是:* 1)先判断集合元素的hashCode是否在集合里面存在,不存在认为是不重复的,直接插入进集合,插入集合的位置按照hash出来散列值排序* 2)如果集合元素的hashCode在集合里面存在,需要再判断集合元素的内容是否一致(存在hash冲突,即不同的元素hash后产生相同的hashCode),* 调用equals方法,如果内容不一致,可以插入* 3)调用equals方法,如果内容一致,说明是重复,则不插入集合*/Student s1 = new Student("1", "张三", 18);//hashCode:49Student s2 = new Student("2", "李四", 19);//hashCode:50set.add(s1);set.add(s2);System.out.println(set);//[49-Student{num='1', name='张三', age=18}, 50-Student{num='2', name='李四', age=19}]Student s4 = new Student("1", "赵六", 18);//hashCode:49,此时集合中已经存在hashCode=49的元素boolean add = set.add(s4);//true hashCode与s1一致,但是内容与s1不同,可以插入System.out.println(set);//[49-Student{num='1', name='张三', age=18}, 49-Student{num='1', name='赵六', age=18}, 50-Student{num='2', name='李四', age=19}]Student s5 = new Student("1", "张三", 18);//hashCode:49,内容与s1完全一致,插入不成功add = set.add(s5);System.out.println(add);//false}
}3)TreeSet 实现了SortedSet 接口,存放的元素可以按照自定义的顺序排序,示例如下:按照学生年龄升序排序
import java.util.*;public class Test {public static void main(String[] args) {Set<Student> set = new TreeSet<>((s1,s2) -> {return s1.getAge() - s2.getAge();//定义排序的集合,按照学生年龄升序排序});Student s1 = new Student("1", "张三", 20);Student s2 = new Student("2", "李四", 25);Student s3 = new Student("3", "李四", 18);set.add(s1);set.add(s2);set.add(s3);//[51-Student{num='3', name='李四', age=18}, 49-Student{num='1', name='张三', age=20}, 50-Student{num='2', name='李四', age=25}]System.out.println(set);}
}2、映射类图:
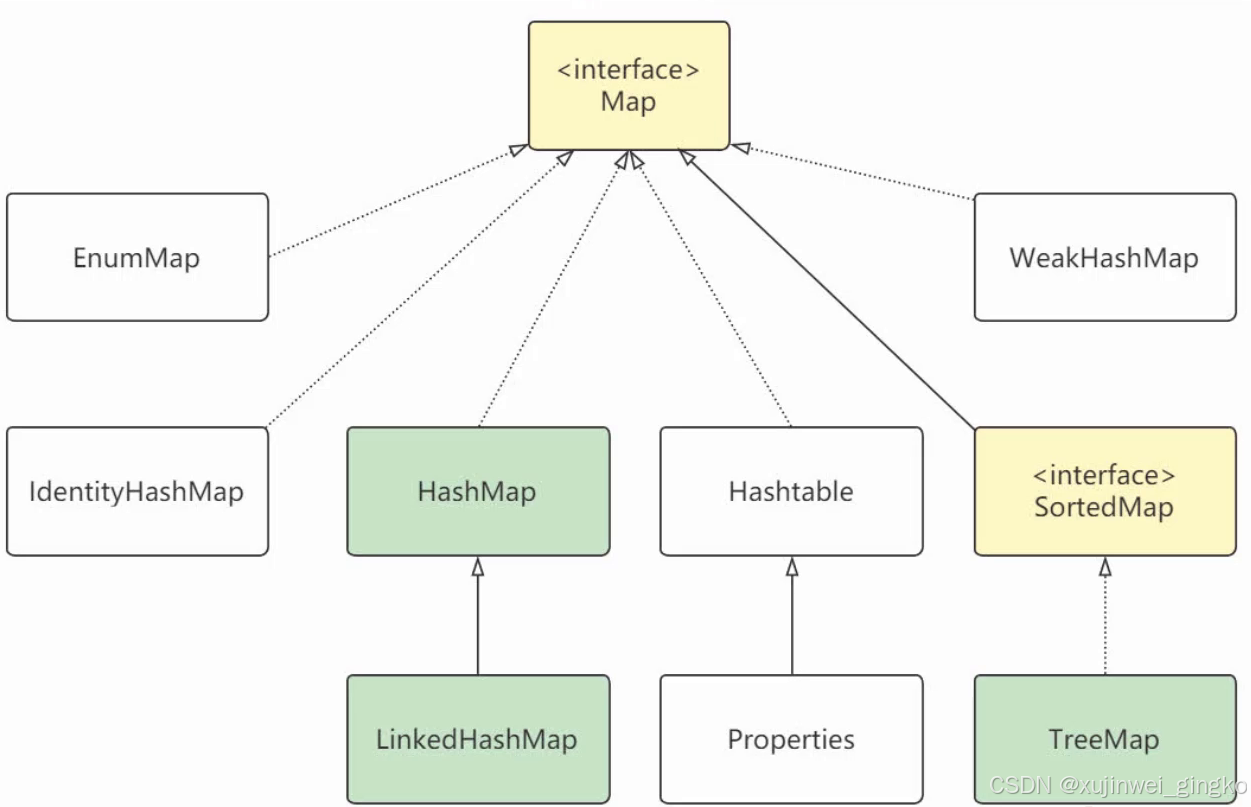
1)HashMap、LinkedHashMap、TreeMap 区别
HashMap: 按照key hash后的值大小顺序存放元素;
LinkedHashMap:有链表特性,按照映射插入顺序存放元素
TreeMap:按照key的自然顺序或自定义排序key进行存放元素
示例代码如下:
import java.util.*;public class Test {public static void main(String[] args) {Map<String,Object> map = new HashMap<>();map.put("name","张三");map.put("age","18");map.put("num","001");//按照key-hash后的值大小顺序放入映射中System.out.println(map);//{num=001, name=张三, age=18}Map<String,Object> linkedMap = new LinkedHashMap<>();linkedMap.put("name","张三");linkedMap.put("age","18");linkedMap.put("num","001");//LinkedHashMap,有链表特性,可以保证插入的顺序就是映射的顺序System.out.println(linkedMap);//{name=张三, age=18, num=001}Map<String,String> treeMap = new TreeMap<String,String>((s1,s2) -> {return s2.compareTo(s1);//自定义排序,按照字符串降序排列});treeMap.put("A1","A1");treeMap.put("A2","A2");treeMap.put("B1","B1");System.out.println(treeMap);//{B1=B1, A2=A2, A1=A1}//遍历treeMap.forEach((key,value) -> {System.out.println(key + ":" + value);});}
}