Axure RP 9.0教程: 基于动态面板的元件跟随来实现【音量滑块】



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/41935.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
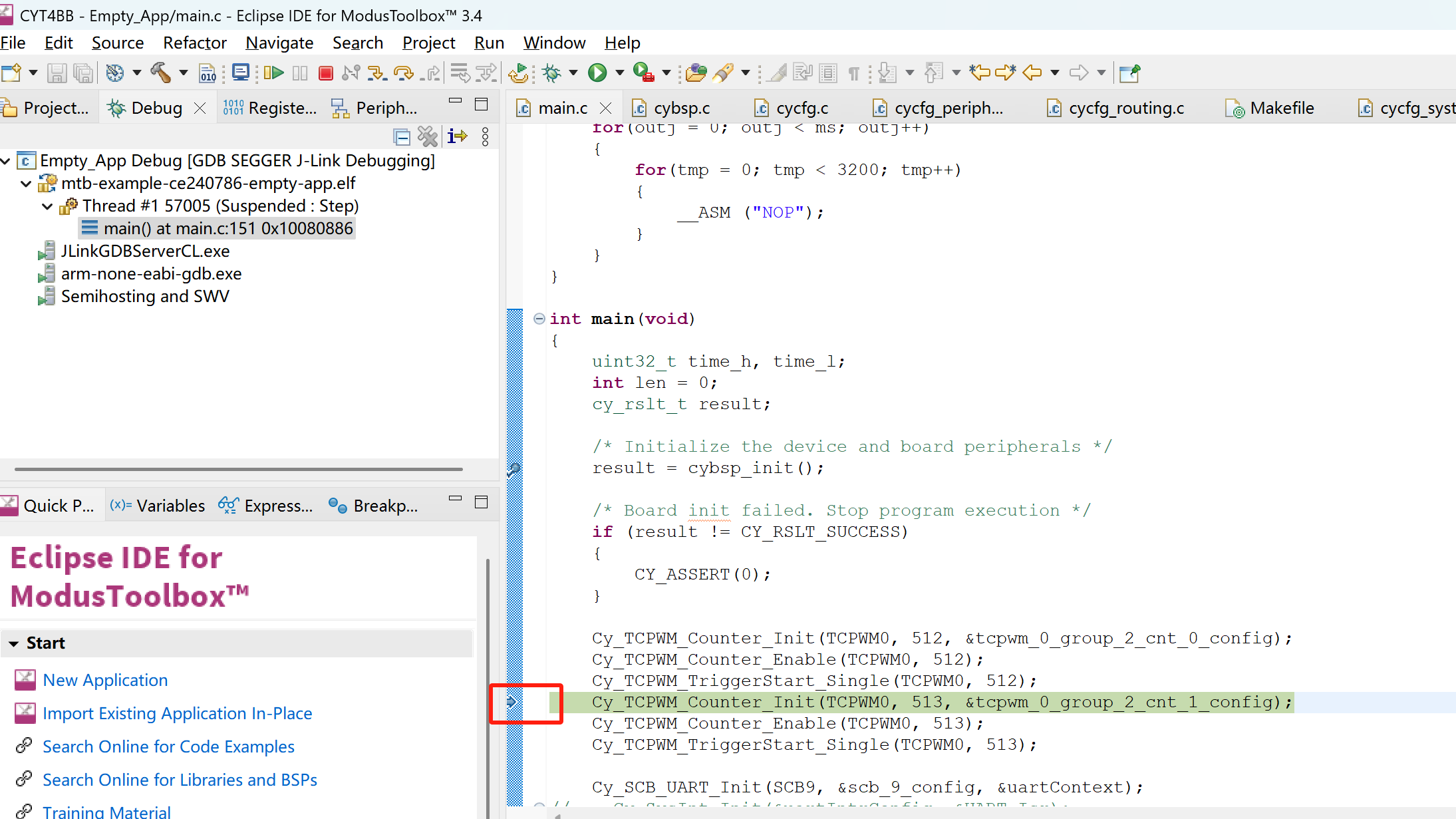
Eclipse IDE for ModusToolbox™ 3.4环境通过JLINK调试CYT4BB
使用JLINK在Eclipse IDE for ModusToolbox™ 3.4环境下调试CYT4BB,配置是难点。总结一下在IDE中配置JLINK调试中遇到的坑,以及如何一步一步解决遇到的问题。
1. JFLASH能够正常下载程序
首先要保证通过JFLASH(我使用的J-Flash V7.88c版本)能够通过JLIN…


wgcloud怎么实现服务器或者主机的远程关机、重启操作吗
可以,WGCLOUD的指令下发模块可以实现远程关机和重启
使用指令下发模块,重启主机,远程关机,重启agent程序- WGCLOUD

深度解析Spring Boot可执行JAR的构建与启动机制
一、Spring Boot应用打包架构演进
1.1 传统JAR包与Fat JAR对比
传统Java应用的JAR包在依赖管理上存在明显短板,依赖项需要单独配置classpath。Spring Boot创新的Fat JAR(又称Uber JAR)解决方案通过spring-boot-maven-plugin插件实现了"…

deepseek(2)——deepseek 关键技术
1 Multi-Head Latent Attention (MLA) MLA的核心在于通过低秩联合压缩来减少注意力键(keys)和值(values)在推理过程中的缓存,从而提高推理效率: c t K V W D K V h t c_t^{KV} W^{DKV}h_t ctKVWDKVht…

突破反爬困境:SDK架构设计,为什么选择独立服务模式(四)
声明 本文所讨论的内容及技术均纯属学术交流与技术研究目的,旨在探讨和总结互联网数据流动、前后端技术架构及安全防御中的技术演进。文中提及的各类技术手段和策略均仅供技术人员在合法与合规的前提下进行研究、学习与防御测试之用。 作者不支持亦不鼓励任何未经授…

自然语言处理,能否成为人工智能与人类语言完美交互的答案?
自然语言处理(NLP)作为人工智能关键领域,正深刻改变着人机交互模式。其发展历经从早期基于规则与统计,到如今借深度学习实现飞跃的历程。NLP 涵盖分词、词性标注、语义理解等多元基础任务,运用传统机器学习与前沿深度学…

蓝桥杯备考:八皇后问题
八皇后的意思是,每行只能有一个,每个对角线只能有一个,每一列只能有一个,我们可以dfs遍历每种情况,每行填一个,通过对角线和列的限制来进行剪枝
话不多说,我们来实现一下代码 #include <ios…

HDR(HDR10/ HLG),SDR
以下是HDR(HDR10/HLG)和SDR的详细解释: 1. SDR(Standard Dynamic Range,标准动态范围)
• 定义:SDR是传统的动态范围标准,主要用于8位色深的视频显示,动态范围较窄&…

【MySQL】验证账户权限
在用户进行验证之后,MySQL将提出以下问题验证账户权限:
1.谁是当前用户?
2.该用户有何权限?
管理权限比如:shutdown、replication slave、load data infile。数据权限比如:select、insert、update、dele…

通过TIM+DMA Burst 实现STM32输出变频且不同脉冲数量的PWM波形
Burst介绍:
DMA控制器可以生成单次传输或增量突发传输,传输的节拍数为4、8或16。
为了确保数据一致性,构成突发传输的每组传输都是不可分割的:AHB传输被锁定,AHB总线矩阵的仲裁器在突发传输序列期间不会撤销DMA主设备…

GaussDB数据库表设计与性能优化实践
GaussDB分布式数据库表设计与性能优化实践
引言
在金融、电信、物联网等大数据场景下,GaussDB作为华为推出的高性能分布式数据库,凭借其创新的架构设计和智能优化能力,已成为企业核心业务系统的重要选择。本文深入探讨GaussDB分布式架构下的…

npm install 卡在创建项目:sill idealTree buildDeps
参考:
https://blog.csdn.net/PengXing_Huang/article/details/136460133 或者再执行
npm install -g cnpm --registryhttps://registry.npm.taobao.org
或者换梯子
【MySQL】从零开始:掌握MySQL数据库的核心概念(五)
由于我的无知,我对生存方式只有一个非常普通的信条:不许后悔。 前言 这是我自己学习mysql数据库的第五篇博客总结。后期我会继续把mysql数据库学习笔记开源至博客上。 上一期笔记是关于mysql数据库的增删查改,没看的同学可以过去看看…

抖音矩阵系统源码开发与部署技巧!短视频矩阵源码搭建部署
在短视频蓬勃发展的时代,短视频矩阵已成为内容创作者和企业扩大影响力、提升传播效果的重要策略。而一个高效、易用的前端系统对于短视频矩阵的成功运营至关重要。本文将深入探讨短视频矩阵前端源码搭建的技术细节,为开发者提供全面的技术指导。
一、技…

ESP32S3 WIFI 实现TCP服务器和静态IP
一、 TCP服务器代码
代码由station_example_main的官方例程修改
/* WiFi station ExampleThis example code is in the Public Domain (or CC0 licensed, at your option.)Unless required by applicable law or agreed to in writing, thissoftware is distributed on an &q…

物质与空:边界中的确定性,虚无中的无限可能——跨学科视角下的存在本质探析
一、哲学框架:二元性与超越性
1. 物质的边界性:有限世界的确定性法则 在人类认知的起点,物质以"非0即1"的绝对姿态显现。一块石头、一滴水、乃至微观粒子,都以明确的边界定义自身存在。这种确定性映射着: 亚…

linux常用指令(10)
那么我们就继续来学习linux指令的使用,来了解搜索查找类的相关指令,话不多说,来看.
搜索查找类
1.find指令
find将从指定目录向下遍历其各个子目录,将满足条件的条件或目录显示在终端
基本语法 find[搜索范围][项项]
选项说明
-name<查询方式> 按照指定的文件名查找…

AWTK-WEB 快速入门(6) - JS WebSocket 应用程序
WebSocket 可以实现双向通信,适合实时通信场景。本文介绍一下使用 Javacript 语言开发 AWTK-WEB 应用程序,并用 WebSocket 与服务器通讯。 用 AWTK Designer 新建一个应用程序
先安装 AWTK Designer:
https://awtk.zlg.cn/web/index.html
…

机器学习——集成学习框架(GBDT、XGBoost、LightGBM、CatBoost)、调参方法
一、集成学习框架 对训练样本较少的结构化数据领域,Boosting算法仍然是常用项 XGBoost、CatBoost和LightGBM都是以决策树为基础的集成学习框架 三个学习框架的发展是:XGBoost是在GBDT的基础上优化而来,CatBoost和LightGBM是在XGBoost的基础上…
推荐文章
- 挖数据平台对接DeepSeek推出一键云端部署功能:API接口驱动金融、汽车等行业智能化升级
- # [Unity]【游戏开发】 脚本生命周期与常见事件方法
- (四)Dart 常量:`final` 和 `const` 修饰符
- .NET Core跨域
- [C]基础8.详解操作符
- [C++] 智能指针 进阶
- [VSCode]彻底卸载和重装,并搭建Java开发环境
- [石榴翻译] 维吾尔语音识别 + TTS语音合成
- [特殊字符] C语言中打开和关闭文件的两种方法:标准库 VS 系统调用
- 《2核2G阿里云神操作!Ubuntu+Ollama低成本部署Deepseek模型实战》
- 《C#上位机开发从门外到门内》3-5:基于FastAPI的Web上位机系统
- 《DeepSeek MoE架构下,动态专家路由优化全解析》