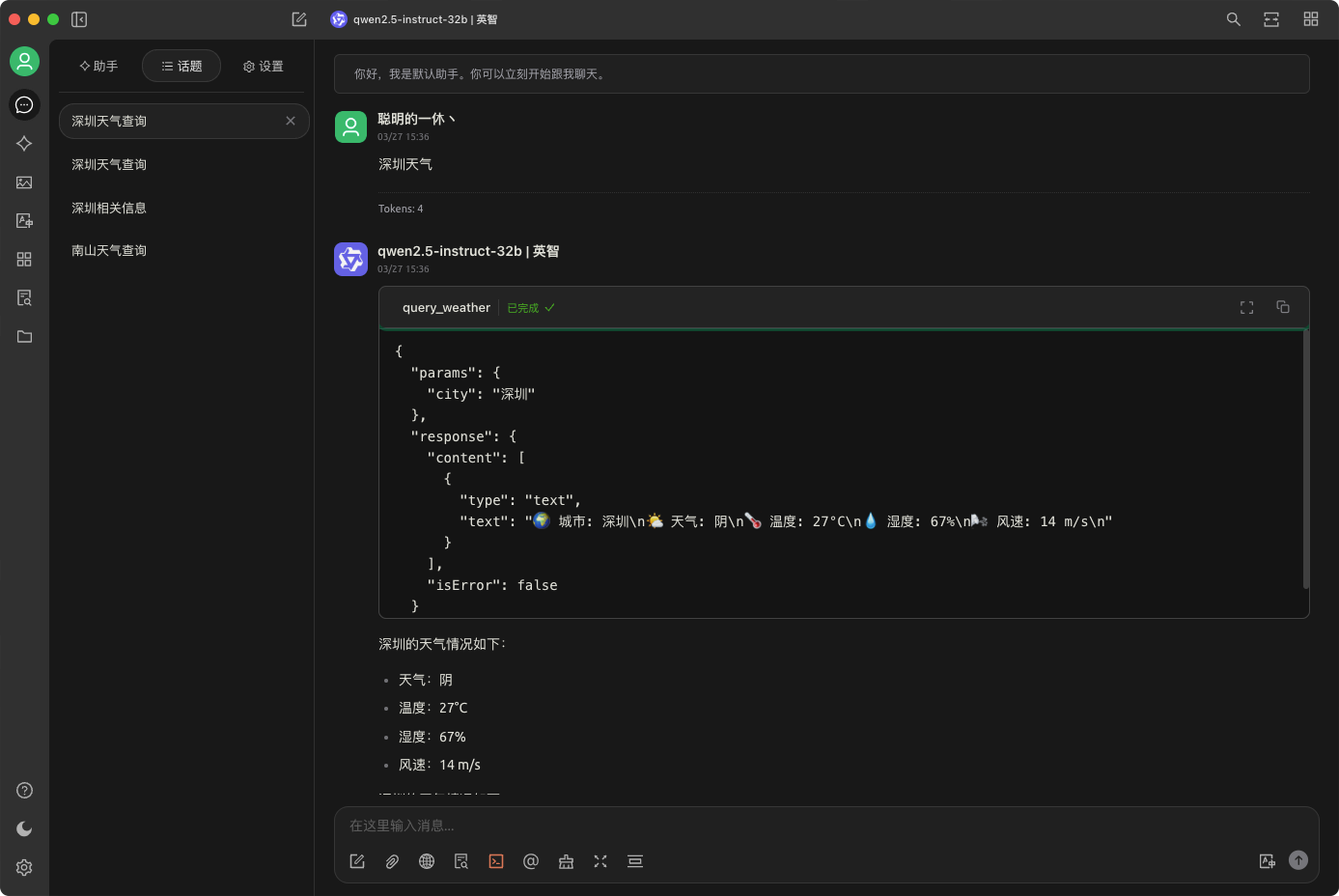
优化并发
- 一、并发基础与优化核心知识点
- 二、关键代码示例与测试
- 三、关键优化策略总结
- 四、性能测试方法论
- 多选题
- 设计题
- 答案与详解
- 多选题答案:
- 设计题答案示例
一、并发基础与优化核心知识点
- 线程 vs 异步任务
- 核心区别:
std::thread直接管理线程,std::async由运行时决定异步策略(可能用线程池)。 - 优化点:频繁创建线程开销大,优先用
std::async。
- 原子操作与内存序
- 原子类型:
std::atomic<T>确保操作不可分割。 - 内存序:
memory_order_relaxed(无同步)到memory_order_seq_cst(全序同步)。
- 锁的精细控制
- 锁类型:
std::mutex、std::recursive_mutex、std::shared_mutex。 - 优化技巧:缩短临界区、避免嵌套锁、用
std::lock_guard/std::unique_lock自动管理。
- 条件变量与生产者-消费者
- 使用模式:
wait()搭配谓词防止虚假唤醒,notify_one()/notify_all()通知。
- 无锁数据结构
- 适用场景:高并发计数器、队列等,减少锁竞争。
二、关键代码示例与测试
示例1:原子操作 vs 互斥锁的性能对比
#include <iostream>
#include <atomic>
#include <mutex>
#include <thread>
#include <vector>
#include <chrono>constexpr int kIncrements = 1'000'000;// 使用互斥锁的计数器
struct MutexCounter {int value = 0;std::mutex mtx;void increment() {std::lock_guard<std::mutex> lock(mtx);++value;}
};// 使用原子操作的计数器
struct AtomicCounter {std::atomic<int> value{0};void increment() {value.fetch_add(1, std::memory_order_relaxed);}
};template<typename Counter>
void test_performance(const std::string& name) {Counter counter;auto start = std::chrono::high_resolution_clock::now();std::vector<std::thread> threads;for (int i = 0; i < 4; ++i) {threads.emplace_back([&counter] {for (int j = 0; j < kIncrements; ++j) {counter.increment();}});}for (auto& t : threads) t.join();auto end = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();std::cout << name << " Result: " << counter.value << ", Time: " << duration << "ms\n";
}int main() {test_performance<MutexCounter>("Mutex Counter");test_performance<AtomicCounter>("Atomic Counter");return 0;
}
编译命令:
g++ -std=c++11 -O2 -pthread atomic_vs_mutex.cpp -o atomic_vs_mutex
输出示例:
Mutex Counter Result: 4000000, Time: 182ms
Atomic Counter Result: 4000000, Time: 32ms
结论:原子操作在高并发下性能显著优于互斥锁。
示例2:线程池实现(减少线程创建开销)
#include <iostream>
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <future>class ThreadPool {
public:ThreadPool(size_t num_threads) : stop(false) {for (size_t i = 0; i < num_threads; ++i) {workers.emplace_back([this] {while (true) {std::function<void()> task;{std::unique_lock<std::mutex> lock(queue_mutex);condition.wait(lock, [this] { return stop || !tasks.empty(); });if (stop && tasks.empty()) return;task = std::move(tasks.front());tasks.pop();}task();}});}}template<class F, class... Args>auto enqueue(F&& f, Args&&... args) -> std::future<decltype(f(args...))> {using return_type = decltype(f(args...));auto task = std::make_shared<std::packaged_task<return_type()>>(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);tasks.emplace([task] { (*task)(); });}condition.notify_one();return res;}~ThreadPool() {{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for (std::thread& worker : workers)worker.join();}private:std::vector<std::thread> workers;std::queue<std::function<void()>> tasks;std::mutex queue_mutex;std::condition_variable condition;bool stop;
};int main() {ThreadPool pool(4);std::vector<std::future<int>> results;for (int i = 0; i < 8; ++i) {results.emplace_back(pool.enqueue([i] {std::cout << "Task " << i << " executed\n";return i * i;}));}for (auto& result : results)std::cout << "Result: " << result.get() << std::endl;return 0;
}
编译命令:
g++ -std=c++11 -O2 -pthread thread_pool.cpp -o thread_pool
输出示例:
Task Result: Task 3Task 1Task 20 executedexecuted
Task 5 executed
Task 40 executed
Task 7Task 6 executedexecutedexecutedexecutedResult: 1
Result: 4
Result: 9
Result: 16
Result: 25
Result: 36
Result: 49
结论:线程池复用线程,减少频繁创建销毁的开销。
示例3:使用无锁队列提升并发
#include <iostream>
#include <atomic>
#include <thread>template<typename T>
class LockFreeQueue {
public:struct Node {T data;Node* next;Node(const T& data) : data(data), next(nullptr) {}};LockFreeQueue() : head(new Node(T())), tail(head.load()) {}void push(const T& data) {Node* newNode = new Node(data);Node* prevTail = tail.exchange(newNode);prevTail->next = newNode;}bool pop(T& result) {Node* oldHead = head.load();if (oldHead == tail.load()) return false;head.store(oldHead->next);result = oldHead->next->data;delete oldHead;return true;}private:std::atomic<Node*> head;std::atomic<Node*> tail;
};int main() {LockFreeQueue<int> queue;// 生产者线程std::thread producer([&] {for (int i = 0; i < 10; ++i) {queue.push(i);std::this_thread::sleep_for(std::chrono::milliseconds(10));}});// 消费者线程std::thread consumer([&] {int value;while (true) {if (queue.pop(value)) {std::cout << "Consumed: " << value << std::endl;if (value == 9) break;}}});producer.join();consumer.join();return 0;
}
编译命令:
g++ -std=c++11 -O2 -pthread lockfree_queue.cpp -o lockfree_queue
输出示例:
Consumed: 0
Consumed: 1
Consumed: 2
Consumed: 3
Consumed: 4
Consumed: 5
Consumed: 6
Consumed: 7
Consumed: 8
Consumed: 9
结论:无锁队列减少锁争用,适合高并发场景。
三、关键优化策略总结
-
减少锁竞争:
- 缩小临界区范围。
- 使用读写锁(
std::shared_mutex)区分读写操作。
-
利用原子操作:
- 简单计数器优先用
std::atomic。 - 适当选择内存序(如
memory_order_relaxed)。
- 简单计数器优先用
-
异步与线程池:
- 避免频繁创建线程,使用
std::async或自定义线程池。
- 避免频繁创建线程,使用
-
无锁数据结构:
- 在CAS(Compare-And-Swap)安全时使用,但需注意ABA问题。
-
缓存友好设计:
- 避免false sharing(用
alignas对齐或填充字节)。
- 避免false sharing(用
四、性能测试方法论
-
基准测试:
- 使用
std::chrono精确测量代码段耗时。 - 对比不同实现的吞吐量(如ops/sec)。
- 使用
-
压力测试:
- 模拟高并发场景,观察资源竞争情况。
-
工具辅助:
- Valgrind检测内存问题。
- perf分析CPU缓存命中率。
多选题
-
下列哪些情况可能导致数据竞争?
A. 多个线程同时读取同一变量
B. 一个线程写,另一个线程读同一变量
C. 使用互斥量保护共享变量
D. 使用原子变量操作 -
关于
std::async和std::thread的选择,正确的说法是?
A.std::async默认启动策略是延迟执行
B.std::thread更适合需要直接控制线程生命周期的场景
C.std::async会自动管理线程池
D.std::thread无法返回计算结果 -
以下哪些操作可能引发死锁?
A. 在持有锁时调用外部未知代码
B. 对多个互斥量使用固定顺序加锁
C. 递归互斥量(std::recursive_mutex)的嵌套加锁
D. 未及时释放条件变量关联的锁 -
关于原子操作的内存顺序,正确的说法是?
A.memory_order_relaxed不保证操作顺序
B.memory_order_seq_cst会降低性能但保证全局顺序
C.memory_order_acquire仅保证读操作的可见性
D. 原子操作必须与volatile关键字结合使用 -
优化同步的合理手段包括:
A. 将大临界区拆分为多个小临界区
B. 使用无锁数据结构替代互斥量
C. 通过std::future传递计算结果
D. 在单核系统上使用忙等待(busy-wait) -
关于条件变量的正确使用方式:
A. 必须在循环中检查谓词
B.notify_one()比notify_all()更高效
C. 可以脱离互斥量单独使用
D. 虚假唤醒(spurious wakeup)是必须处理的 -
以下哪些是"锁护送"(Lock Convoy)的表现?
A. 多个线程频繁争抢同一互斥量
B. 线程因锁竞争频繁切换上下文
C. 互斥量的持有时间极短
D. 使用读写锁(std::shared_mutex) -
减少共享数据竞争的方法包括:
A. 使用线程局部存储(TLS)
B. 复制数据到各线程独立处理
C. 通过消息队列传递数据
D. 增加互斥量的数量 -
关于
std::promise和std::future的正确说法是:
A.std::promise只能设置一次值
B.std::future的get()会阻塞直到结果就绪
C. 多个线程可以共享同一个std::future对象
D.std::async返回的std::future可能延迟执行 -
关于原子变量与互斥量的对比,正确的说法是:
A. 原子变量适用于简单数据类型
B. 互斥量能保护复杂操作序列
C. 原子变量的fetch_add是原子的
D. 互斥量比原子变量性能更好
设计题
- 实现一个线程安全的无锁(lock-free)队列
要求:
- 使用原子操作实现
push和pop - 处理ABA问题
- 提供测试代码验证并发操作正确性
- 设计一个生产者-消费者模型
要求:
- 使用
std::condition_variable和std::mutex - 队列长度限制为固定大小
- 支持多生产者和多消费者
- 提供测试代码模拟并发场景
- 实现基于
std::async的并行任务执行器
要求:
- 支持提交任意可调用对象
- 自动回收已完成的任务资源
- 限制最大并发线程数为CPU核心数
- 测试代码展示并行加速效果
- 优化高竞争场景下的计数器
要求:
- 使用线程局部存储(TLS)分散写操作
- 定期合并局部计数到全局变量
- 对比普通原子计数器与优化版本的性能差异
- 提供测试代码和性能统计输出
5 实现一个读写锁(Read-Write Lock)
要求:
- 支持多个读者或单个写者
- 避免写者饥饿(writer starvation)
- 基于
std::mutex和std::condition_variable实现 - 测试代码验证读写操作的互斥性
答案与详解
多选题答案:
-
B
解析:数据竞争的条件是至少一个线程写且无同步措施。A只有读不冲突,C/D有同步机制。 -
B, D
解析:std::async默认策略非延迟(C++11起为std::launch::async|deferred),B正确,D因std::thread无直接返回值机制正确。 -
A, C
解析:A可能导致回调中再次加锁;C递归锁允许同一线程重复加锁但需对应解锁次数,误用仍可能死锁。 -
A, B
解析:memory_order_relaxed无顺序保证,B正确,C中acquire保证后续读的可见性,D错误(原子操作无需volatile)。 -
A, B, C
解析:D在单核忙等待浪费CPU,其余均为有效优化手段。 -
A, B, D
解析:C错误,条件变量必须与互斥量配合使用。 -
A, B
解析:锁护送表现为频繁争抢导致线程切换,C短持有时间反而减少竞争,D无关。 -
A, B, C
解析:D增加锁数量可能加剧竞争,其余均为减少竞争的有效方法。 -
A, B, D
解析:C错误,std::future不可多线程同时调用get()。 -
A, B, C
解析:D错误,互斥量在低竞争时性能可能更差。
设计题答案示例
- 无锁队列实现(部分代码)
#include <atomic>
#include <memory>template<typename T>
class LockFreeQueue {
private:struct Node {std::shared_ptr<T> data;std::atomic<Node*> next;Node() : next(nullptr) {}};std::atomic<Node*> head;std::atomic<Node*> tail;public:LockFreeQueue() : head(new Node), tail(head.load()) {}void push(T value) {Node* new_node = new Node;new_node->data = std::make_shared<T>(std::move(value));Node* old_tail = tail.load();while (!old_tail->next.compare_exchange_weak(nullptr, new_node)) {old_tail = tail.load();}tail.compare_exchange_weak(old_tail, new_node);}std::shared_ptr<T> pop() {Node* old_head = head.load();while (old_head != tail.load()) {if (head.compare_exchange_weak(old_head, old_head->next)) {std::shared_ptr<T> res = old_head->next->data;delete old_head;return res;}}return nullptr;}
};// 测试代码
int main() {LockFreeQueue<int> queue;queue.push(42);auto val = queue.pop();if (val && *val == 42) {std::cout << "Test passed!\n";}return 0;
}
- 生产者-消费者模型
#include <queue>
#include <mutex>
#include <condition_variable>
#include <thread>
#include <iostream>template<typename T>
class SafeQueue {
private:std::queue<T> queue;std::mutex mtx;std::condition_variable cv;size_t max_size;public:SafeQueue(size_t size) : max_size(size) {}void push(T item) {std::unique_lock<std::mutex> lock(mtx);cv.wait(lock, [this] { return queue.size() < max_size; });queue.push(std::move(item));cv.notify_all();}T pop() {std::unique_lock<std::mutex> lock(mtx);cv.wait(lock, [this] { return !queue.empty(); });T val = std::move(queue.front());queue.pop();cv.notify_all();return val;}
};// 测试代码
int main() {SafeQueue<int> q(10);std::thread producer([&q] {for (int i = 0; i < 10; ++i) {q.push(i);}});std::thread consumer([&q] {for (int i = 0; i < 10; ++i) {int val = q.pop();std::cout << "Got: " << val << '\n';}});producer.join();consumer.join();return 0;
}
其他设计题目的答案, 稍后补充