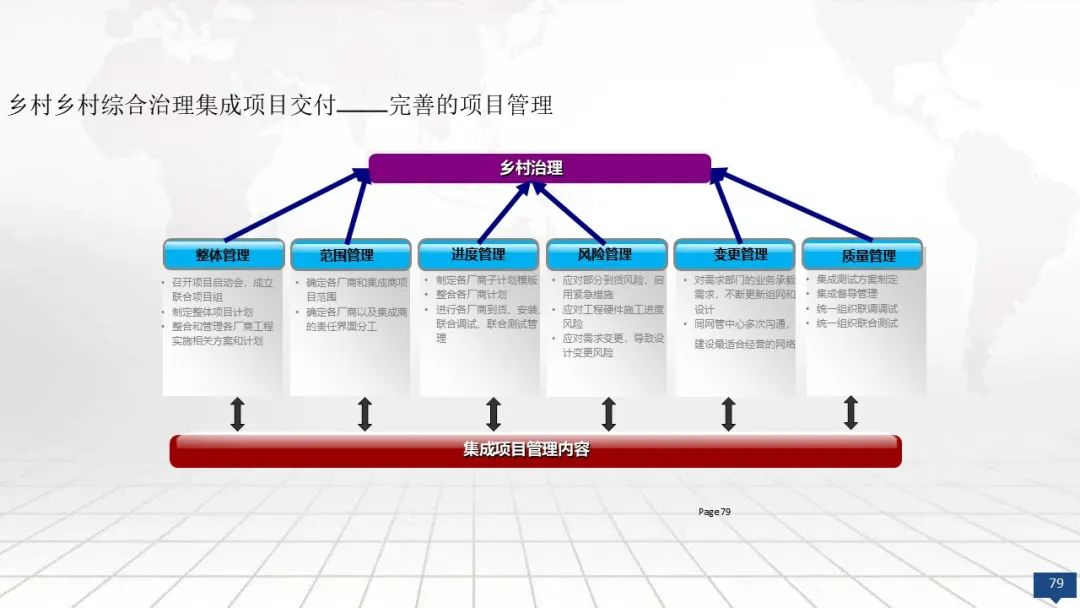
0. 来源
概念比较全,可以作为目录,前置知识讲得好,其他一般。
01.内容简介_哔哩哔哩_bilibili01.内容简介是集成学习:XGBoost, lightGBM的第1集视频,该合集共计19集,视频收藏或关注UP主,及时了解更多相关视频内容。![]() https://www.bilibili.com/video/BV1Ca4y1t7DS?p=1有数学原理与例子,有自己的理解和模型特点总结,可惜更新的少:
https://www.bilibili.com/video/BV1Ca4y1t7DS?p=1有数学原理与例子,有自己的理解和模型特点总结,可惜更新的少:
【决策树、随机森林】附源码!!超级简单,同济大佬手把手带你学决策树,快速搞定你的难题!—决策树算法|随机森林|决策树模型|机器学习算法|人工智能_哔哩哔哩_bilibili【决策树、随机森林】附源码!!超级简单,同济大佬手把手带你学决策树,快速搞定你的难题!—决策树算法|随机森林|决策树模型|机器学习算法|人工智能共计23条视频,包括:第一章:决策树原理 1-决策树算法概述、2-熵的作用、3-信息增益原理等,UP主更多精彩视频,请关注UP账号。![]() https://www.bilibili.com/video/BV1xS4y1w7GJ?GBDT算法——理论与sklearn代码实现 - 知乎 (zhihu.com)
https://www.bilibili.com/video/BV1xS4y1w7GJ?GBDT算法——理论与sklearn代码实现 - 知乎 (zhihu.com)
GradientBoostingClassifier — scikit-learn 1.5.1 documentation
1. 预备知识
1.1 信息熵

可以看出,事件发生的概率越为平均时,集合越不纯时,不确定性越大,最高为1。

条件熵:条件概率。
具体计算过程可以看视频,用图示来表示的话,类似于:

用信息熵构建可以得到分类决策树。
1.2 Gini指数

Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为个类时,基尼指数为0。

1.3 回归树

1.4 预剪枝和后剪枝
决策树的预剪枝与后剪枝-CSDN博客
预剪枝使得很多分支没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间。但是,有些分支虽当前不能提升泛化性。甚至可能导致泛化性暂时降低,但在其基础上进行后续划分却有可能导致显著提高,因此预剪枝的这种贪心本质,给决策树带来了欠拟合的风险。
后剪枝通常比预剪枝保留更多的分支,其欠拟合风险很小,因此后剪枝的泛化性能往往由于预剪枝决策树。但后剪枝过程是从底往上裁剪,因此其训练时间开销比前剪枝要大。
2. bagging:随机森林

bootstrap aggregating(自举汇聚法)

随机森林
优势:1.消除了决策树容易过拟合的缺点2.减小了预测的方差,预测值不会因训练数据的小变化而剧烈变化
3. Boosting方法
boosting:adaboost、GBDT、XGBoost、LightGBM



3.1 Adaboost
Adaboost可以看作是加法模型(串行调整弱分类器的权重)、损失函数为指数损失函数、学习算法为前向分布算法时的二分类学习方法。

3.2 GBDT



不同问题的提升树在于损失函数的不同,分类用指数损失函数,回归用平方误差损失。
GBDT算法——理论与sklearn代码实现 - 知乎 (zhihu.com)

用泰勒公式来理解梯度下降的原因是为了下一篇文章讨论XGBoost做准备,因为在GBDT中只对损失函数进行了一阶泰勒展开,只用到了一阶导数信息,而XGBoost对损失函数进行二阶泰勒展开,同时用到了一阶导数信息和二阶导数信息。



3.3 XGBoost
从这里开始变得复杂了起来……
深入理解XGBoost,优缺点分析,原理推导及工程实现-CSDN博客![]() https://blog.csdn.net/Datawhale/article/details/103725122
https://blog.csdn.net/Datawhale/article/details/103725122
3.4 lightGBM
LightGBM算法详解(教你一文掌握LightGBM所有知识点)-CSDN博客![]() https://blog.csdn.net/GFDGFHSDS/article/details/104779767
https://blog.csdn.net/GFDGFHSDS/article/details/104779767