![]()
熟悉使用Excel的同学应该都知道,在单个Excel表格里想要分商品计算总销售额,使用数据透视表也可以非常快速方便的获得结果。
但当有非常大量的Excel文件需要处理时,每一个Excel文件单独去做数据透视也会消耗大量的时间。
就算使用Power Query这样的工具进行多表合一,也会有同一个工作表太大导致电脑太卡和所有Excel文件格式必须一样这样的问题。
Python读取、处理Excel文件优势就在于处理大量文件也非常快速以及应付各种不同格式的文件和不同需求的灵活性。
今天,我们将学习解决这个问题的第一步:
读取单个月份Excel表格数据。
剩下的三步将在明天和后天的课程中进行学习,并最终解决阿珍的问题。在开始读取表格数据前, 我们需要先学习一下Excel表格的基本结构。

| 一个Excel表格文件,又叫做一个工作簿(Workbook)。 |
|
| 一个工作簿中包含一个或多个工作表(Worksheet)。 |
|
| 一个工作表由单元格(Cell)组成。Excel的数据存储在单元格中。 |
|
| 行号默认从数字1开始,并依次递增。 |
|
| 下面,我们通过观察Excel表格来思考一下,如何计算单个月份的销售额: |
|
| 表格中第I列为订单的总价。 |
|






根据这个思路,我们得出了整个计算单个月份“火龙果可乐”销售额的步骤:
1. 读取工作表:“销售订单数据”
2. 逐行读取订单数据
3. 把“火龙果可乐”的订单总价相加
这些步骤我们会在今明两天的课程中去实现。

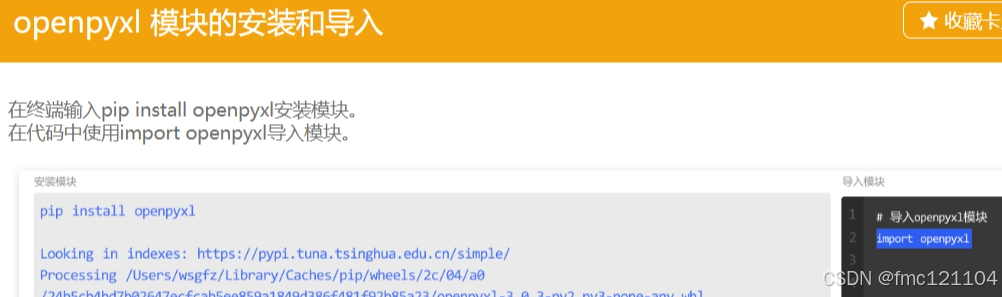
| 在终端中输入pip install openpyxl安装模块。 |
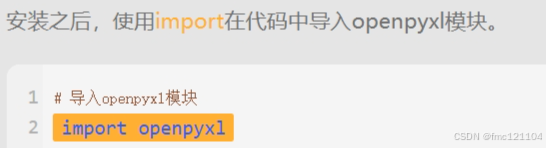
| 要使用Python对Excel表格进行读取,我们需要安装一个用于读取数据的工具 openpyxl 。openpyxl 是一个用于读、写Excel文件的开源模块。 |
|
|


| 读取当前运行目录里名为"2019年1月销售订单.xlsx"的工作簿并赋值给变量wb |
|
|

|
|