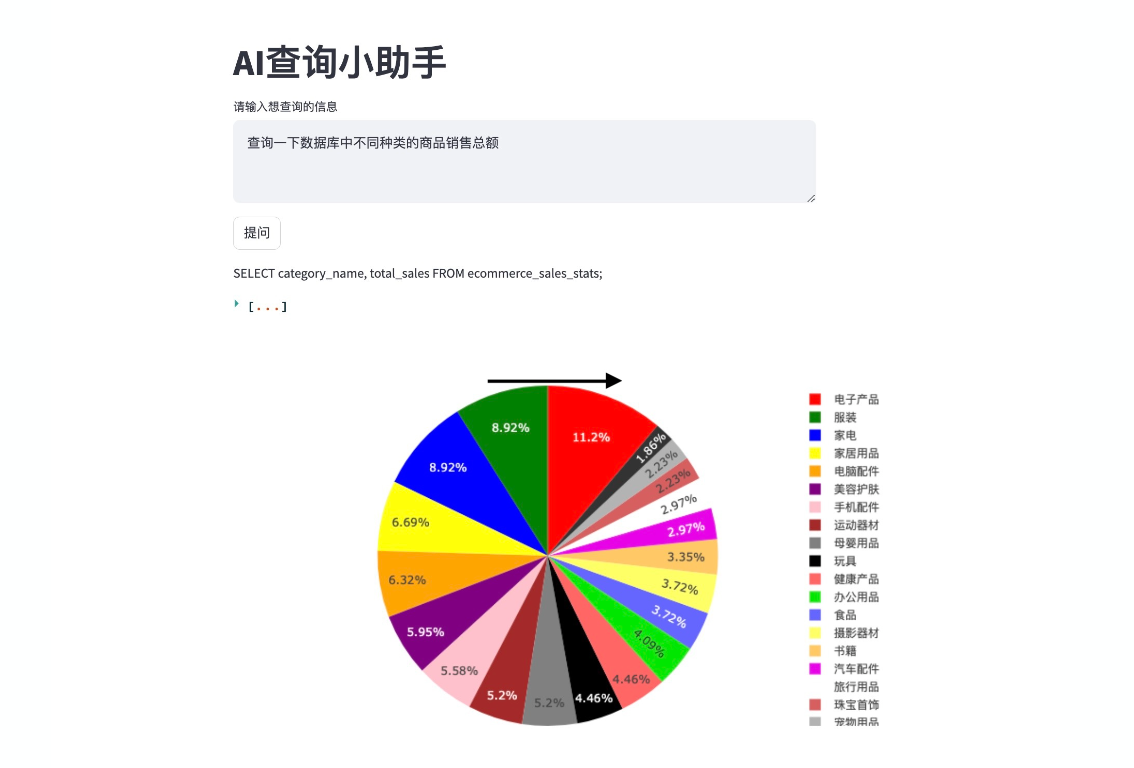
摘要
焦点调制网络(简称FocalNets),其中自注意力(SA)完全由焦点调制模块取代,用于在视觉中建模标记交互。焦点调制包括三个组件:(i)焦点情境化,通过一堆深度卷积层实现,从短到长范围编码视觉上下文,(ii)门控聚合,选择性地将上下文聚集到每个查询标记的调制器中,以及(iii)逐元素仿射变换,将调制器注入查询中。广泛的实验表明,FocalNets表现出卓越的可解释性,并且在图像分类、目标检测和分割任务上,以类似的计算成本优于SoTA SA的对应模型(例如Swin和Focal Transformers)。具体来说,具有微小和基础规模的FocalNets可以在ImageNet-1K上分别达到82.3%和83.9%的top-1准确率。在ImageNet-22K上以224²分辨率进行预训练后,微调时分别在224²和384²分辨率下获得86.5%和87.3%的top-1准确率。
焦点调制网络(FocalNet)调制自动且逐渐聚焦于诱导识别类别的目标区域,如下图所示:

FocalModulation介绍
自注意力(SA)和我们提出的焦点调制。给定查询token和目标token ,SA 首先执行查询-键交互以计算注意力分数,然后进行查询-值聚合以从其他token中捕捉上下文。相比之下,焦点调制首先将不同粒度级别的空间上下文编码为调制器,然后根据查询token自适应地注入到查询token中。显然,SA需要大量的交互和聚合操作,而焦点调制颠倒了它们的顺序,使两者都变得轻量化。如下图所示:

焦点调制计算公式如下:

其中 q(⋅) 是一个查询投影函数,m(⋅) 是上下文聚合函数,其输出称为调制器。焦点调制具有以下有利特性:
平移不变性:由于 q(⋅) 和 m(⋅) 始终以查询令牌 i 为中心,且不使用位置嵌入,调制对输入特征图 X 的平移不变。
显式输入依赖:通过在目标位置 i 周围聚合局部特征来计算调制 m(⋅),因此我们的焦点调制显式依赖于输入。
空间和通道特异性:目标位置 i 作为 m(⋅) 的指针使得调制在空间上是特异的,元素级乘法使得调制在通道上是特异的。
解耦特征粒度:q(⋅) 保留了个别令牌的最精细信息&