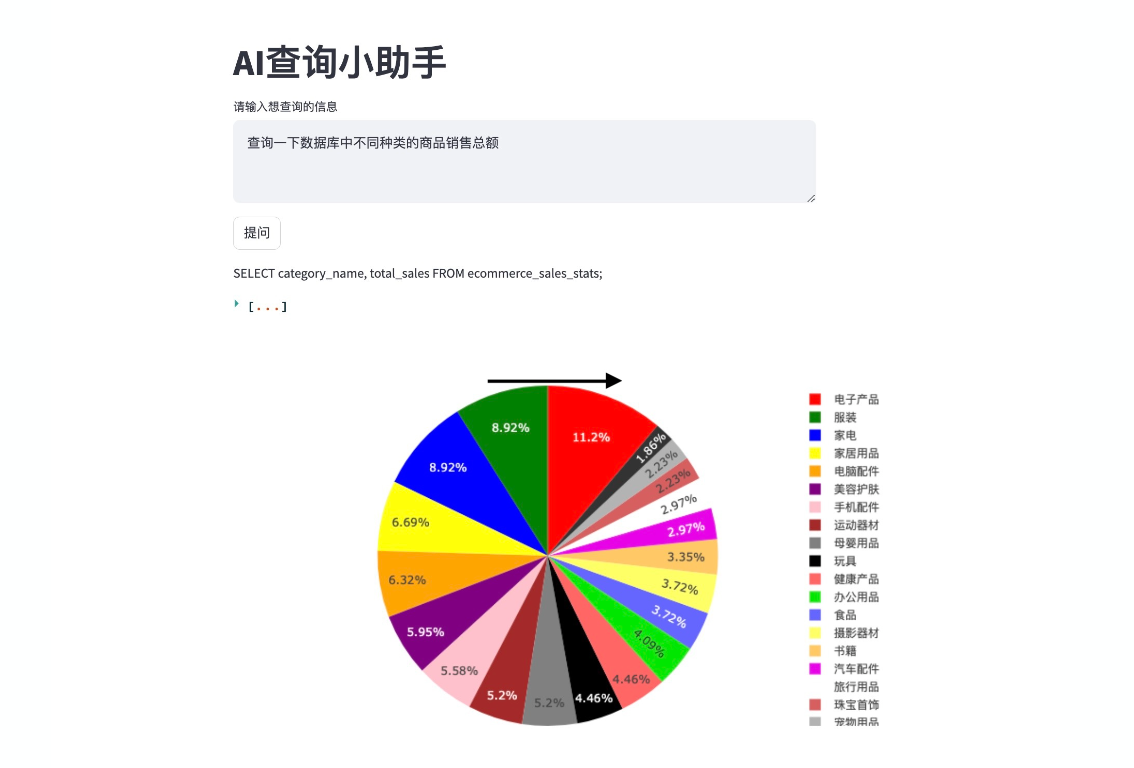
文章目录
- 一、经典神经语言模型(A Neural Probabilistic Language Model)
- 二、C&W模型 (Collobert and Weston, 2008)
- 2.1 文章背景
- 2.2 模型架构(词向量的表示)
- 2.2.1 Lookup-Table Layer(查找表)
- 2.2.2 TDNN layer(带窗口的时延神经网络)
- 2.3 使用深度神经网络处理多任务(词向量的训练)
- 2.4 实验结果
- 三、基于Hierarchical Softmax(层次 Softmax)的Word2Vec模型
- 3.1 模型介绍(Word2Vec与NNLM的联系)
- 3.2 基于层次 Softmax的CBOW模型(Continuous Bag-of-Words Model)
- 3.2.1 网络结构
- 3.2.2 Hierarchical Softmax机制 介绍
- 3.2.3 梯度计算
- 3.3 基于层次 Softmax的Skip-Gram模型
- 3.3.1 网络结构
- 3.3.2 梯度计算
- 四、基于Negative Sampling(负采样)的Word2Vec模型
- 4.1 基于负采样的CBOW模型
- 4.2 基于负采样的Skip-Gram模型
- 4.3 负采样算法
拓展内容:
Deep Learning in NLP (一)词向量和语言模型——licstar
静态词嵌入(Static Word Embedding)总结——長門有希
word2vec中的数学——peghoty
Deep Learning 实战之 word2vec——邓澍军、陆光明、夏龙
不可思议的Word2Vec——苏剑林
一、经典神经语言模型(A Neural Probabilistic Language Model)
A Neural Probabilistic Language Model
关于函数 f ( w t , w t − 1 , … , w t − n + 1 ) f(w_t,w_{t-1},\dots,w_{t-n+1}) f(wt,wt−1,…,wt−n+1)的解释:
- 函数 f ( w t , w t − 1 , … , w t − n + 1 ) = P ^ ( w t ∣ W 1 t − 1 ) f(w_t,w_{t-1},\dots,w_{t-n+1})=\hat P(w_t|W_{1}^{t-1}) f(wt,wt−1,…,wt−n+1)=P^(wt∣W1t−1)是模型的学习目标,表示用前 n − 1 n-1 n−1个词来预测 w t w_t wt
- 困惑度: 1 P ^ ( w t ∣ W 1 t − 1 ) \frac{1}{\hat P(w_t|W_{1}^{t-1})} P^(wt∣W1t−1)1的几何平均数也就是困惑度。
- 相关内容可见:深入理解语言模型的困惑度(perplexity)——武辰
- p e r p l e x i t y ( W ) = P ( w 1 , w 2 , … , w n ) − 1 N = 1 P ( w 1 , w 2 , … , w n ) N = ∏ i = 1 n 1 P ( w i ∣ w 1 , w 2 , … , w i − 1 ) N perplexity(W)=P(w_1,w_2,\dots,w_n)^{-\frac{1}{N}}=\sqrt[N]{\frac{1}{P(w_1,w_2,\dots,w_n)}}=\sqrt[N]{\prod_{i=1}^{n}\frac{1}{P(w_i|w_1,w_2,\dots,w_{i-1})}} perplexity(W)=P(w1,w2,…,wn)−N1=NP(w1,w2,…,wn)1=Ni=1∏nP(wi∣w1,w2,…,wi−1)1
- 函数的约束条件为:
- f ( w t , w t − 1 , … , w t − n + 1 ) > 0 f(w_t,w_{t-1},\dots,w_{t-n+1})>0 f(wt,wt−1,…,wt−n+1)>0
- ∑ i = 1 ∣ V ∣ f ( i , w t − 1 , … , w t − n + 1 ) = 1 \sum_{i=1}^{|V|}f(i,w_{t-1},\dots,w_{t-n+1})=1 ∑i=1∣V∣f(i,wt−1,…,wt−n+1)=1
关于函数 g ( i , C ( w t − 1 ) , … , C ( w t − n + 1 ) ) g(i,C(w_{t-1}),\dots,C(w_{t-n+1})) g(i,C(wt−1),…,C(wt−n+1))的解释:
- 矩阵 C C C是一个 ∣ V ∣ × m |V|\times m ∣V∣×m的随机初始化矩阵,实际上相当于一个查找表,将词表中的任意元素 i i i映射为向量 C ( i ) ∈ R m C(i)\in \mathbb{R}^{m} C(i)∈Rm,这个向量就是词表中每个词的 d i s t r i b u t e d f e a t u r e v e c t o r distributed\ feature\ vector distributed feature vector
- 此时的词向量只是帮助构造目标函数的辅助参数,它仅仅是这个过程中的副产品,却在众多下游任务中发挥了作用,因为它依靠distributed representation解决维度灾难
- 函数 g g g将上下文中单词的特征向量输入序列 ( C w t − 1 , … , C w t − n + 1 ) (C_{w_{t-1}}, \dots ,C_{w_{t-n+1}}) (Cwt−1,…,Cwt−n+1)映射为 V V V中单词的条件概率分布
- 函数 g g g的输出是一个向量,其中第 i i i个元素就是 P ^ ( w t = i ∣ W 1 t − 1 ) \hat P(w_t=i|W_{1}^{t-1}) P^(wt=i∣W1t−1),表示输出为第 i i i个单词的估计概率
- 函数 g g g可由前馈、循环或其他的参数化网络来实现,其中的参数称为 ω \omega ω

关于计算过程的介绍:
- 为了满足约束条件,此时使用 s o f t m a x softmax softmax输出层:
- P ^ ( w t ∣ W t − 1 , … , w t − n + 1 ) = e y w t ∑ i e y i \hat P(w_t|W_{t-1},\dots,w_{t-n+1})=\frac{e^{y_{w_t}}}{\sum_ie^{y_i}} P^(wt∣Wt−1,…,wt−n+1)=∑ieyieywt
- y i y_i yi为每个单词 i i i尚未标准化的对数概率 ⇒ y = b + W x + U t a n h ( d + H x ) \Rightarrow y=b+Wx+U tanh (d+Hx) ⇒y=b+Wx+Utanh(d+Hx)
- x x x结构为 ( n − 1 ) m × 1 (n-1)m\times 1 (n−1)m×1,为word features layer activation vector,根据矩阵 C C C的相应词向量连结而成: x = ( C ( w t − 1 ) ) , ( C ( w t − 2 ) ) , … , ( C ( w t − n + 1 ) ) x=(C(w_{t-1})),(C(w_{t-2})),\dots,(C(w_{t-n+1})) x=(C(wt−1)),(C(wt−2)),…,(C(wt−n+1))
- W W W结构为 ∣ V ∣ × ( n − 1 ) m |V| \times (n-1)m ∣V∣×(n−1)m,为单词特征到输出的权重,当不需要 x x x与输出的直接连接时可选择置为0;直连虽然不能提升模型效果,但是可以少一半的迭代次数。
- H H H结构为 h × ( n − 1 ) m h \times (n-1)m h×(n−1)m,为隐藏层;
- U U U结构为 ∣ V ∣ × h |V| \times h ∣V∣×h,为隐藏层到输出的权重;
- b b b结构为 ∣ V ∣ × 1 |V| \times 1 ∣V∣×1,隐藏层偏差值;
- d d d结构为 h × 1 h \times 1 h×1,输出偏差值;
- 相较于 n − g r a m n-gram n−gram模型,上述内容的计算瓶颈是softmax 层,因为计算 softmax 的计算复杂度与词汇库 V 中词的数量成正比,这也是后续的优化方向之一,Word2vec正是代表之一。
- 拓展内容:比较语言建模中近似softmax的几种方法——机器之心
二、C&W模型 (Collobert and Weston, 2008)
A unified architecture for natural language processing: deep neural networks with multitask learning
2.1 文章背景
当时的研究仅着眼于浅层次的子任务,大部分的系统无法用于构建适合深层语义任务的通用架构,它们的问题为:
- 它们在分类器层面上是浅层的,不能捕捉到数据中的复杂非线性关系,通常只能处理较为简单的任务;
- 为了让线性分类器工作得更好,需要大量的人工干预来设计特征,而这些特征往往是针对特定任务定制的,不具备通用性;
- 当系统尝试将针对不同任务学到的特征结合起来时,可能会引入错误,因为这些特征可能并不适用于新的任务环境
Collobert和Weston重新定义了一个通用的卷积网络架构,并将其应用于诸多知名的NLP子任务:
- Part-Of-Speech Tagging (POS)
- 词性标注(POS)的目标是为句子中的每个单词分配一个唯一的标签,以指示其句法角色,例如复数名词、副词等。
- Chunking
- 分块(也称为浅层解析)的目标是为句子中的片段分配句法成分标签,如名词短语(NP)或动词短语(VP)。
- 在分块中,每个单词被分配一个唯一的标签,通常编码为开始分块(例如B-NP)或内部分块标签(例如I-NP)。
- Named Entity Recognition (NER)
- 命名实体识别(NER)的目标是将句子中的原子元素标注为“PERSON”、“COMPANY”或“LOCATION”等类别。
- Semantic Role Labeling (SRL)
- 语义角色标注(SRL)目的是识别句子中谓词(通常是动词或形容词)与其论元(即句子中的其他成分,如名词短语)之间的语义关系。SRL通过为每个论元分配一个语义角色来揭示句子的深层意义,这些角色描述了论元在谓词所表示的动作或状态中的作用。
- 语义角色(Semantic Roles):语义角色描述了论元在谓词表达的事件中的角色。常见的语义角色包括:
- ARG0:通常指事件的主体或执行者。
- ARG1:通常指事件的直接对象或受事。
- ARG2:有时指事件的间接对象。
- ARGM:修饰词(Modifier),提供额外信息,如时间、地点、方式、原因等。
- 例如,在句子“John gave a book to Mary.”中,谓词是“gave”,其论元“John”可能被标注为ARG0(给予者),而“a book”被标注为ARG1(给予的对象),"Mary"被标注为ARG2(接收者)。
- Language Models
- 传统的语言模型通常用于估计序列中下一个词是特定词 w 的概率。这意味着,给定一个文本序列的前一部分,模型会计算下一个可能出现的词的概率分布。
- 这个文章使用了不同的设置,语言模型的任务不是传统地预测下一个词,而是判断一个给定的文本序列是否在自然界中存在。
- 通过将真实文本作为正例和生成伪造文本作为负例来训练模型,以使其能够预测给定序列在自然界中是否存在。
- Semantically Related Words
- 任务目标是预测两个词在语义上是否相关,这种关系可能包括同义词(synonyms)、上义词(hypernyms)、下义词(hyponyms)、整体词(holonyms)等。
- 这个任务的评价标准是使用WordNet数据库(http://wordnet.princeton.edu)作为基准真相(ground truth)来衡量预测的准确性。
作者认为这些任务中SRL是最复杂的,所以将这项任务的性能作为主要评价指标,其他任务用于辅助提升SRL的性能。
2.2 模型架构(词向量的表示)

2.2.1 Lookup-Table Layer(查找表)
第一层为 L o o k u p − T a b l e L a y e r Lookup-Table\ Layer Lookup−Table Layer,机制和第一节提到的矩阵 C C C类似,此时使用的是矩阵 W ∈ R d × ∣ D ∣ W \in \mathbb{R}^{d\times |D|} W∈Rd×∣D∣,将单词索引 i i i 直接映射为一个向量 W i ∈ R d W_{i} \in \mathbb{R}^{d} Wi∈Rd,每个单词对应查找表中的一列,在训练过程中可通过反向传播来更新这个矩阵的值,也就是更新单词的不同表达。需要注意的是:
- 预处理过程中,所有单词都被转换为小写,但原始单词的大小写信息仍然被认为是有价值的,因此研究者将其作为一个单独的特征包含在模型中。
- 将单词分解成多个元素(特征),例如词根、后缀、词性标签等,具体例子如下:
- 将单词分解为 K K K个特征,原始单词可被表示为元组 i = { i 1 , i 2 , … , i k } ∈ D 1 × ⋯ × D K i=\{i^1,i^2,\dots,i^k\}\in D^1 \times \dots \times D^K i={i1,i2,…,ik}∈D1×⋯×DK,其中每个元素分属于不同的字典
- 每个元素对应一个查找表: 对于单词分解后的每个元素,都使用一个单独的查找表将其映射到一个低维向量空间。每个查找表的作用就是将一个元素索引 i k i^k ik 映射为一个 d k d^k dk 维向量。
- 每个查找表的结构为 W k ∈ R d k × ∣ D k ∣ W^k \in \mathbb{R}^{d^k \times |D^k|} Wk∈Rdk×∣Dk∣,其中 d k d^k dk为用户指定的向量维度,表示低维向量的维度; ∣ D k ∣ |D^k| ∣Dk∣是第 k k k 个查找表中的元素数量。
- 原始单词嵌入到了一个维度为 d d d 的空间中,其中 d d d 是所有查找表维度 d k d^k dk 的总和:实际意义就是最终的词向量其实是由每个查找表对应的低维向量拼接而来 L T W 1 , … , W k ( i ) T = ( L T W 1 ( i 1 ) T , … , L T W K ( i K ) T ) LT_{W^1,\dots,W^k}(i)^T=(LT_{W^1}(i^1)^T,\dots,LT_{W^K}(i^K)^T) LTW1,…,Wk(i)T=(LTW1(i1)T,…,LTWK(iK)T)
- 多查找表的方法允许模型捕捉到词汇在不同上下文中的复杂语义信息,这在很多复杂的NLP任务中是非常有用的。
- 每个单词添加一个特征,也就是需要增加一个查找表,该特征编码了单词相对于选定的谓词的相对距离,对于句子中的第 i i i个单词,如果它的谓语位于 p o s p pos_p posp,对应的元素索引为: ( i − p o s p ) (i-pos_p) (i−posp),对应的向量映射为 L T d i s t p ( i − p o s p ) LT^{dist_p}(i-pos_p) LTdistp(i−posp)。
- 在SRL任务中,一个句子中的每个单词的分类标签依赖于句中的谓词(predicate),即执行某种动作或状态的词。因此,在神经网络(NN)架构中需要编码当前考虑的谓词。

2.2.2 TDNN layer(带窗口的时延神经网络)
查找表可以将原始的句子映射为一个由 n n n个大小相同的向量组成的序列 x ( ⋅ ) x(\cdot) x(⋅):
( x 1 , x 2 , … , x n ) , ∀ t x t ∈ R d (x_1,x_2,\dots,x_n),\ \forall t\ x_t\in\mathbb{R}^d (x1,x2,…,xn), ∀t xt∈Rd
但当时普通的神经网络无法处理可变长度的序列输入,所以还需要将其处理为固定格式的内容。
一个简单的思路是只使用一个窗口,仅关注要标注的单词的周围,但这种思路足以用于POS任务,却不足以用于解决SRL任务,因为SRL中涉及到更远的单词,此时的解决思路是使用带窗口的TDNN。
TDNN通过一种在线方式浏览序列 x ( ⋅ ) x(\cdot) x(⋅):在时间 t ≥ 1 t\geq1 t≥1,读取序列中的第 t t t个单词。
经典的TDNN是对序列 x ( ⋅ ) x(\cdot) x(⋅)进行卷积操作,在时间 t t t的输出为:
O ( t ) = ∑ j = 1 − t n − t L j ⋅ x t + j O(t)=\sum_{j=1-t}^{n-t}L_{j}\cdot x_{t+j} O(t)=j=1−t∑n−tLj⋅xt+j
- j j j 是一个整数,它表示从当前时间点 t t t 开始的时间偏移量,每个时间偏移 j j j 对应一个特定的权重 L j ∈ R n × d L_j\in \mathbb{R}^{n\times d} Lj∈Rn×d, n n n为隐藏单元个数,这些权重参数将通过反向传播来训练。
- j j j 的范围为: − 1 ≤ j ≤ n -1 \leq j\leq n −1≤j≤n
通常,人们通过定义一个核宽度ksz来限制这种卷积,强制执行以下条件:
∀ ∣ j ∣ > ( k s z − 1 ) / 2 , L j = 0 \forall |j|>(ksz-1)/2,L_j=0 ∀∣j∣>(ksz−1)/2,Lj=0
传统的窗口方法在处理序列时,只考虑当前元素周围大小为ksz的窗口内的元素。而TDNN使用这两个式子,可以同时考虑句子中所有大小为ksz的单词窗口,从而捕捉更广泛的上下文信息。
TDNN层可以堆叠起来使用,这样可以在网络的较低层提取局部特征(例如,单词或短语的特征),在较高层提取更全局的特征(例如,句子或段落的特征)。这种方法在处理图像的卷积神经网络中也很常见,例如LeNet架构,它通过堆叠卷积层来逐步提取从局部到全局的特征。
2.3 使用深度神经网络处理多任务(词向量的训练)

训练过程如下:
- 任务选择: 从多个任务中选择一个进行训练。
- 样本选择: 从所选任务的训练数据集中随机选择一个样本。
- 梯度更新: 使用该样本更新神经网络的参数。参数更新采用梯度下降算法,目标是使模型的预测结果更接近真实标签。
- 循环: 重复步骤 1-3,直到所有任务都训练完毕。
语言模型训练方法是一种基于神经网络的无监督学习方法,可以有效地学习单词的语义信息,并提升其他自然语言处理任务的性能,此时并没有将训练一个理想的语言模型作为目标,而是使用语言模型训练得到的词嵌入作为其他 NLP 任务中词嵌入层的初始化参数,所以此时训练语言模型使用的损失函数也不同于一般训练语言模型的思路:
- 数据集:
使用整个维基百科网站作为训练数据集。将维基百科中的所有文本按照固定窗口大小 (ksz) 分割成多个句子片段,每个片段包含 ksz 个单词。 - 任务定义:
将语言模型训练成一个二分类器,目标是判断句子片段中的中间词是否与其上下文相关。- 正例: 维基百科中的真实句子片段。
- 负例: 将真实句子片段中的中间词替换成随机单词得到的句子片段。
- 损失函数: ∑ s ∈ S ∑ w ∈ D m a x ( 0 , 1 − f ( s ) + f ( s w ) ) \sum_{s\in S}\sum_{w \in D}max(0,1-f(s)+f(s^w)) s∈S∑w∈D∑max(0,1−f(s)+f(sw))
- S S S 是句子片段集合
- D D D 是单词字典
- f ( ⋅ ) f(·) f(⋅) 代表神经网络模型 (不包括 softmax 层)
- s w s^w sw是将句子片段 s s s 中的中间词替换成单词 w w w 得到的句子片段
- 该损失函数的目标是使真实句子片段的分数高于随机替换中间词的“假句子”的分数。 具体来说,对于每个真实句子片段 s s s ,都会找到所有可能的“假句子” s w s^w sw (将中间词替换成字典中的任意单词 w w w),并计算真实句子片段 s s s 和“假句子” s w s^w sw 之间的分数差。如果真实句子片段 s s s 的分数低于“假句子” s w s^w sw 的分数,则将分数差加到损失函数中。
2.4 实验结果

将语言模型与 SRL 任务联合训练,可以显著提高 SRL 任务的性能。论文中最好的模型在 PropBank 数据集上实现了 14.30% 的每词错误率,优于之前基于神经网络和基于句法分析树的 SRL 方法。
三、基于Hierarchical Softmax(层次 Softmax)的Word2Vec模型
参考:
word2vec中的数学——peghoty
Deep Learning 实战之 word2vec——邓澍军、陆光明、夏龙
不可思议的Word2Vec——苏剑林
3.1 模型介绍(Word2Vec与NNLM的联系)
下图来源:Efficient Estimation of Word Representations in Vector Space

下图来源:word2vec中的数学——peghoty

第一张图介绍了Word2Vec的原始结构,大致分为了三层:
- 输入层
- 映射层
- 输出层
重新回顾一下NNLM的计算:
- P ^ ( w t ∣ W t − 1 , … , w t − n + 1 ) = e y w t ∑ i e y i \hat P(w_t|W_{t-1},\dots,w_{t-n+1})=\frac{e^{y_{w_t}}}{\sum_ie^{y_i}} P^(wt∣Wt−1,…,wt−n+1)=∑ieyieywt
- y = b + W x + U t a n h ( d + H x ) y=b+Wx+U tanh (d+Hx) y=b+Wx+Utanh(d+Hx)
NNLM的计算量集中在隐藏层和softmax归一化运算,仅从结构上出发,可以看到Word2Vec去掉了隐藏层;其实除此以外,Word2Vec在softmax归一化运算上也进行了优化,有两个提速手段,分别是层次Softmax和负样本采样:
- 层次Softmax是对Softmax的简化,直接将预测概率的效率从 O ( ∣ V ∣ ) O(|V|) O(∣V∣)降为 O ( log 2 ∣ V ∣ ) O(\log_2|V|) O(log2∣V∣),但相对来说,精度会比原生的Softmax略差;
- 负样本采样则采用了相反的思路,它把原来的输入和输出联合起来当作输入,然后做一个二分类来打分
3.2 基于层次 Softmax的CBOW模型(Continuous Bag-of-Words Model)
基于神经网络的语言模型的目标函数通常为如下对数似然函数:
L = ∑ w ∈ c log p ( w ∣ C o n t e x t ( w ) ) \mathcal{L}=\sum_{w\in c}\log p(w|Context(w)) L=w∈c∑logp(w∣Context(w))
其中的关键就是条件概率函数的构造,NNLM使用的是 P ^ ( w t ∣ W t − 1 , … , w t − n + 1 ) = e y w t ∑ i e y i \hat P(w_t|W_{t-1},\dots,w_{t-n+1})=\frac{e^{y_{w_t}}}{\sum_ie^{y_i}} P^(wt∣Wt−1,…,wt−n+1)=∑ieyieywt,而此处使用的是层次 Softmax。
3.2.1 网络结构
以样本 ( C o n t e x t ( w ) , w ) (Context(w),w) (Context(w),w)为例(假设 C o n t e x t ( w ) Context(w) Context(w)由 w w w 前后各 c c c 个词构成):
- 输入层: 包含 C o n t e x t ( w ) Context(w) Context(w)中 2 c 2c 2c 个词的词向量,词向量长度为 m m m;
- 投影层: 将输入层的 2 c 2c 2c个词向量做求和累加: X w = ∑ i = 1 2 c v ( C o n t e x t ( w ) i ) ∈ R m X_w=\sum_{i=1}^{2c}v(Context(w)_i)\in \mathbb{R}^m Xw=∑i=12cv(Context(w)i)∈Rm
- 输出层: 输出层对应的是一个二叉树,以语料中出现过的词为叶子结点,以各词在语料中的词频作为权值构造的Huffman树。它的作用依然是一个分类器,通过一系列的二分类决策来执行多分类任务,即预测给定上下文中的中心单词。

3.2.2 Hierarchical Softmax机制 介绍
记号说明:
- p w p^w pw:从根节点出发到达 w w w对应的叶子结点的路径;
- l w l^w lw:路径 p w p^w pw中包含结点的个数;
- p 1 w , p 2 w , … , p l w w p_{1}^{w},p_{2}^{w},\dots,p_{l_w}^{w} p1w,p2w,…,plww:路径 p w p^w pw中的 l w l^w lw个结点,其中 p 1 w p_{1}^{w} p1w表示根结点, p l w w p_{l_w}^{w} plww表示 w w w 对应的叶子结点;
- d 2 w , d 3 w , … , d l w w ∈ { 0 , 1 } d_{2}^{w},d_{3}^{w},\dots,d_{l_w}^{w}\in \{0,1\} d2w,d3w,…,dlww∈{0,1}:词 w w w 对应的 H u f f m a n Huffman Huffman 编码,由 l w − 1 l_w-1 lw−1 位编码构成(根节点不包含编码), d j w d_j^w djw 表示路径 p w p^w pw 中第 j j j 个结点对应的编码;
- θ 1 w , θ 2 w , … , θ l w − 1 w ∈ R m \theta_{1}^{w},\theta_{2}^{w},\dots,\theta_{l_w-1}^{w}\in \mathbb{R}^m θ1w,θ2w,…,θlw−1w∈Rm:路径 p w p^w pw 中非叶子结点对应的向量, θ j w \theta_j^w θjw 表示路径 p w p^w pw 中第 j j j 个非叶子结点对应的向量。

在结合图片了解记号后,我们还需要解决一个问题:如何利用这样的 H u f f m a n Huffman Huffman 树处理多分类问题,也就是如何利用它来定义 p ( w ∣ C o n t e x t ( w ) ) p(w|Context(w)) p(w∣Context(w))。
之前提过,Huffman树的作用依然是一个分类器,通过一系列的二分类决策来执行多分类任务,以上图为例,如果要从根节点到达“足球”,需要经过4次分支(每条红色的边对应一个分支),每一次分支相当于进行了一次二分类。
s i g m o i d sigmoid sigmoid 函数可以将数据映射到0~1之间,这一特性使得很适合利用它的输出来直接表示二分类问题中某一类的概率,对于任意样本 X = ( x 1 , x 2 , … , x n ) T X=(x_1,x_2,\dots,x_n)^{T} X=(x1,x2,…,xn)T,可将二分类问题的假设函数写作:
h θ ( X ) = σ ( θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n ) h_{\theta}(X)=\sigma(\theta_0+\theta_1x_1+\theta_2x_2+\dots+\theta_nx_n) hθ(X)=σ(θ0+θ1x1+θ2x2+⋯+θnxn)
其中 Θ \Theta Θ为待定参数,为了符号上的简化,引入 x 0 = 1 x_0=1 x0=1,将 X X X拓展为 X = ( x 0 , x 1 , x 2 , … , x n ) T X=(x_0,x_1,x_2,\dots,x_n)^{T} X=(x0,x1,x2,…,xn)T,于是可将假设函数简写为:
h θ ( X ) = σ ( Θ T X ) = 1 1 + e − ( Θ T X ) h_\theta(X)=\sigma(\Theta^TX)=\frac{1}{1+e^{-(\Theta^TX)}} hθ(X)=σ(ΘTX)=1+e−(ΘTX)1
取阈值为0.5,则二分类的判别公式为:
y ( X ) = { 1 h θ ( X ) ≥ 0.5 0 h θ ( X ) < 0.5 y(X)=\begin{cases} 1 & h_\theta(X)\geq0.5 \\ 0 & h_\theta(X)<0.5 \end{cases} y(X)={10hθ(X)≥0.5hθ(X)<0.5
特别说明一下,sigmoid函数导函数具有以下形式: σ ′ ( x ) = σ ( x ) [ 1 − σ ( x ) ] \sigma'(x)=\sigma(x)[1-\sigma(x)] σ′(x)=σ(x)[1−σ(x)],借助这一性质和链式法则,可以进一步推导得到以下式子,这些式子将在梯度计算中使用:
{ log σ ( x ) ′ = 1 − σ ( x ) log ( 1 − σ ( x ) ) ′ = − σ ( x ) \begin{cases} \ \ \ \ \log\sigma(x)'&=1-\sigma(x)\\ \log(1-\sigma(x))'&=-\sigma(x) \end{cases} { logσ(x)′log(1−σ(x))′=1−σ(x)=−σ(x)
根据上述对二分类的解释,结合上图可以发现非叶子结点对应的向量 θ i w \theta_i^w θiw就是充当了二分类公式中 Θ \Theta Θ的角色,所以可以总结出在一个非叶子结点处,被归为负类的概率为:
σ ( X w T θ ) = 1 1 + e − ( X T Θ ) \sigma(X_w^T\theta)=\frac{1}{1+e^{-(X^T\Theta)}} σ(XwTθ)=1+e−(XTΘ)1
我们也可以将其整理后写作:
p ( d j w ∣ X w , θ j − 1 w ) = [ σ ( X w T θ j − 1 w ) ] 1 − d j w ⋅ [ 1 − σ ( X w T θ j − 1 w ) ] d j w p(d_j^w|X_w,\theta_{j-1}^w)=[\sigma(X_w^T\theta_{j-1}^w)]^{1-d_j^w}\cdot [1-\sigma(X_w^T\theta_{j-1}^w)]^{d_j^w} p(djw∣Xw,θj−1w)=[σ(XwTθj−1w)]1−djw⋅[1−σ(XwTθj−1w)]djw
根据上述内容,我们就知道了此时这样的 H u f f m a n Huffman Huffman 树来定义 p ( w ∣ C o n t e x t ( w ) ) p(w|Context(w)) p(w∣Context(w)),我们可以用它的路径概率来表示条件概率:
p ( w ∣ C o n t e x t ( w ) ) = ∏ j = 2 l w p ( d j w ∣ X w , θ j − 1 w ) p(w|Context(w))=\prod_{j=2}^{l^w}p(d_j^w|X_w,\theta_{j-1}^w) p(w∣Context(w))=j=2∏lwp(djw∣Xw,θj−1w)
从公式中可以看出,相较于经典NNLM中使用的Softmax概率计算,此时的概率计算只需沿着路径计算,计算复杂度从 O ( V ) O(V) O(V)变为了 O ( log V ) O(\log V) O(logV)。
3.2.3 梯度计算
结合下列式子,可以得到此时的目标函数:
{ p ( w ∣ C o n t e x t ( w ) ) = ∏ j = 2 l w p ( d j w ∣ X w , θ j − 1 w ) L = ∑ w ∈ c log p ( w ∣ C o n t e x t ( w ) ) \begin{cases} p(w|Context(w))&=\prod_{j=2}^{l^w}p(d_j^w|X_w,\theta_{j-1}^w)\\ \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \mathcal{L}&=\sum_{w\in c}\log p(w|Context(w)) \end{cases} ⎩ ⎨ ⎧p(w∣Context(w)) L=∏j=2lwp(djw∣Xw,θj−1w)=∑w∈clogp(w∣Context(w))
⇒ L = ∑ w ∈ c log ∏ j = 2 l w p ( d j w ∣ X w , θ j − 1 w ) ⇒ L = ∑ w ∈ c ∑ j = 2 l w { ( 1 − d j w ) ⋅ log [ σ ( X w T θ j − 1 w ) ] + d j w ⋅ log [ 1 − σ ( X w T θ j − 1 w ) ] } \begin{aligned} \Rightarrow \mathcal{L} &=\sum_{w\in c}\log \prod_{j=2}^{l^w}p(d_j^w|X_w,\theta_{j-1}^w) \\\Rightarrow \mathcal{L} &=\sum_{w\in c}\sum_{j=2}^{l^w}\{ (1-d_j^w)\cdot \log[\sigma(X_w^T\theta_{j-1}^w)]+d_j^w\cdot \log[1-\sigma(X_w^T\theta_{j-1}^w)]\} \end{aligned} ⇒L⇒L=w∈c∑logj=2∏lwp(djw∣Xw,θj−1w)=w∈c∑j=2∑lw{(1−djw)⋅log[σ(XwTθj−1w)]+djw⋅log[1−σ(XwTθj−1w)]}
为了方便梯度推导,将上式中的 双重求和符号 下 花括号 的内容简记为 L ( w , j ) \mathcal{L}(w,j) L(w,j),即:
L ( w , j ) = ( 1 − d j w ) ⋅ log [ σ ( X w T θ j − 1 w ) ] + d j w ⋅ log [ 1 − σ ( X w T θ j − 1 w ) ] \mathcal{L}(w,j)=(1-d_j^w)\cdot \log[\sigma(X_w^T\theta_{j-1}^w)]+d_j^w\cdot \log[1-\sigma(X_w^T\theta_{j-1}^w)] L(w,j)=(1−djw)⋅log[σ(XwTθj−1w)]+djw⋅log[1−σ(XwTθj−1w)]
此时使用的是似然函数,所以目标是使得这个函数最大化,观察式子可知其中包含的参数为:
- w w w
- X w X_w Xw
- θ j − 1 w , j = 2 , … , l w \theta_{j-1}^w,j=2,\dots,l^w θj−1w,j=2,…,lw
每取出一个样本 ( C o n t e x t ( w ) , w ) (Context(w),w) (Context(w),w)后,就会对这些参数进行更新,接下来展示各个参数的梯度计算。
L ( w , j ) \mathcal{L}(w,j) L(w,j) 关于 θ j − 1 w \theta_{j-1}^w θj−1w 的梯度计算:
∂ L ( w , j ) ∂ θ j − 1 w = ∂ ∂ θ j − 1 w { ( 1 − d j w ) ⋅ log [ σ ( X w T θ j − 1 w ) ] + d j w ⋅ log [ 1 − σ ( X w T θ j − 1 w ) ] } = ( 1 − d j w ) [ 1 − σ ( X w T θ j − 1 w ) ] X w − d j w σ ( X w T θ j − 1 w ) X w ( 3.2.2 )已提及 s i g m o i d 函数求导特性 = { ( 1 − d j w ) [ 1 − σ ( X w T θ j − 1 w ) ] − d j w σ ( X w T θ j − 1 w ) } X w = [ 1 − d j w − σ ( X w T θ j − 1 w ) ] X w \begin{aligned} \frac{\partial \mathcal{L}(w,j)}{\partial \theta_{j-1}^w}&=\frac{\partial }{\partial \theta_{j-1}^w}\{ (1-d_j^w)\cdot \log[\sigma(X_w^T\theta_{j-1}^w)]+d_j^w\cdot \log[1-\sigma(X_w^T\theta_{j-1}^w)]\}\\ &=(1-d_j^w)[1-\sigma(X_w^T\theta_{j-1}^w)]X_w-d_j^w\sigma(X_w^T\theta_{j-1}^w)X_w\textcolor{blue}{(3.2.2)已提及sigmoid函数求导特性}\\ &=\{(1-d_j^w)[1-\sigma(X_w^T\theta_{j-1}^w)]-d_j^w\sigma(X_w^T\theta_{j-1}^w)\}X_w\\ &=[1-d_j^w-\sigma(X_w^T\theta_{j-1}^w)]X_w \end{aligned} ∂θj−1w∂L(w,j)=∂θj−1w∂{(1−djw)⋅log[σ(XwTθj−1w)]+djw⋅log[1−σ(XwTθj−1w)]}=(1−djw)[1−σ(XwTθj−1w)]Xw−djwσ(XwTθj−1w)Xw(3.2.2)已提及sigmoid函数求导特性={(1−djw)[1−σ(XwTθj−1w)]−djwσ(XwTθj−1w)}Xw=[1−djw−σ(XwTθj−1w)]Xw
如果使用 η \eta η表示学习率,此时 θ j − 1 w \theta_{j-1}^w θj−1w的更新公式可写为
θ j − 1 w : = θ j − 1 w + η [ 1 − d j w − σ ( X w T θ j − 1 w ) ] X w \theta_{j-1}^w:=\theta_{j-1}^w+\eta[1-d_j^w-\sigma(X_w^T\theta_{j-1}^w)]X_w θj−1w:=θj−1w+η[1−djw−σ(XwTθj−1w)]Xw
L ( w , j ) \mathcal{L}(w,j) L(w,j) 关于 X w X_w Xw 的梯度计算:
通过观察目标函数的式子,可以看到 X w X_w Xw与 θ j − 1 w \theta_{j-1}^w θj−1w总是以 X w T θ j − 1 w X_w^T\theta_{j-1}^w XwTθj−1w的形式相伴出现,所以我们可以参考之前的推导思路,直接做一个简单的替换:
∂ L ( w , j ) ∂ X w = [ 1 − d j w − σ ( X w T θ j − 1 w ) ] θ j − 1 w \frac{\partial \mathcal{L}(w,j)}{\partial X_w}=[1-d_j^w-\sigma(X_w^T\theta_{j-1}^w)]\theta_{j-1}^w ∂Xw∂L(w,j)=[1−djw−σ(XwTθj−1w)]θj−1w
考虑路径上的非叶子结点,得到梯度总和;但此时出现了一个问题: X w X_w Xw是上下文词向量的累加,如何使用梯度来更新上下文中的每个词向量。
如果 w ~ ∈ C o n t e x t ( w ) \tilde w \in Context(w) w~∈Context(w),相应词向量为 v ( w ~ ) v(\tilde w) v(w~),有两种实现的思路:
{ v ( w ~ ) : = v ( w ~ ) + η ∑ j = 2 l w ∂ L ( w , j ) ∂ X w v ( w ~ ) : = v ( w ~ ) + η ∣ c o n t e x t ( w ) ∣ ∑ j = 2 l w ∂ L ( w , j ) ∂ X w \begin{cases} v(\tilde w):=v(\tilde w)+\eta\sum_{j=2}^{l^w}\frac{\partial \mathcal{L}(w,j)}{\partial X_w} \\ \\ v(\tilde w):=v(\tilde w)+\frac{\eta}{|context(w)|}\sum_{j=2}^{l^w}\frac{\partial \mathcal{L}(w,j)}{\partial X_w} \end{cases} ⎩ ⎨ ⎧v(w~):=v(w~)+η∑j=2lw∂Xw∂L(w,j)v(w~):=v(w~)+∣context(w)∣η∑j=2lw∂Xw∂L(w,j)
两种思路的区别仅在第二种考虑的是平均梯度,但源码中使用的是第一种思路(值得讨论)
梯度更新伪代码展示:

3.3 基于层次 Softmax的Skip-Gram模型
3.3.1 网络结构
以样本 ( w , C o n t e x t ( w ) ) (w,Context(w)) (w,Context(w))为例(:
- 输入层: 只包含当前样本的中心词 w w w的词向量 v ( w ) ∈ R m v(w)\in \mathbb{R}^m v(w)∈Rm;
- 投影层: 仅是为了方便和上图结构进行对比,此处实际仅是恒等变换;
- 输出层: 输出层同样对应的是一个二叉树,以语料中出现过的词为叶子结点,以各词在语料中的词频作为权值构造的Huffman树。

对于Skip-Gram模型,根据当前的中心词 w w w,预测其上下文 C o n t e n t ( x ) Content(x) Content(x),需要注意的是此时它是每次独立预测一个上下文词,相当于词袋,预测所得的上下文词之间是不含顺序信息的,可定义为:
p ( C o n t e x t ( w ) ∣ w ) = ∏ u ∈ C o n t e x t ( w ) p ( u ∣ w ) p(Context(w)|w)=\prod_{u\in Context(w)} p(u|w) p(Context(w)∣w)=u∈Context(w)∏p(u∣w)
3.3.2 梯度计算
根据上述的层次Softmax思想,可得:
{ p ( u ∣ w ) = ∏ j = 2 l u p ( d j u ∣ v ( w ) , θ j − 1 u ) p ( d j u ∣ v ( w ) , θ j − 1 u ) = [ σ ( v ( x ) T θ j − 1 u ) ] 1 − d j u ⋅ [ 1 − σ ( v ( x ) T θ j − 1 u ) ] d j u \begin{cases} \ \ \ \ \ \ \ p(u|w)&=\prod_{j=2}^{l^u}p(d_j^u|v(w),\theta_{j-1}^{u})\\ \\ p(d_j^u|v(w),\theta_{j-1}^{u})&=[\sigma(v(x)^T\theta_{j-1}^{u})]^{1-d_j^u}\cdot[1-\sigma(v(x)^T\theta_{j-1}^{u})]^{d_j^u} \end{cases} ⎩ ⎨ ⎧ p(u∣w)p(dju∣v(w),θj−1u)=∏j=2lup(dju∣v(w),θj−1u)=[σ(v(x)Tθj−1u)]1−dju⋅[1−σ(v(x)Tθj−1u)]dju
将上述式子回代到目标函数 L = ∑ w ∈ c log p ( C o n t e x t ( w ) ∣ w ) \mathcal{L}=\sum_{w\in c}\log p(Context(w)|w) L=∑w∈clogp(Context(w)∣w)中,得到:
L = ∑ w ∈ c log ∏ u ∈ C o n t e x t ( w ) p ( u ∣ w ) = ∑ w ∈ c log ∏ u ∈ C o n t e x t ( w ) ∏ j = 2 l u p ( d j u ∣ v ( w ) , θ j − 1 u ) = ∑ w ∈ c log ∏ u ∈ C o n t e x t ( w ) ∏ j = 2 l u { [ σ ( v ( x ) T θ j − 1 u ) ] 1 − d j u ⋅ [ 1 − σ ( v ( x ) T θ j − 1 u ) ] d j u } = ∑ w ∈ c ∑ u ∈ C o n t e x t ( w ) ∑ j = 2 l u { ( 1 − d j u ) ⋅ log [ σ ( v ( x ) T θ j − 1 u ) ] + d j u ⋅ log [ 1 − σ ( v ( w ) T θ j − 1 u ) ] } \begin{aligned} \mathcal{L}&=\sum_{w\in c}\log \prod_{u\in Context(w)} p(u|w)\\ &=\sum_{w\in c}\log \prod_{u\in Context(w)}\prod_{j=2}^{l^u}p(d_j^u|v(w),\theta_{j-1}^{u})\\ &=\sum_{w\in c}\log \prod_{u\in Context(w)}\prod_{j=2}^{l^u}\{[\sigma(v(x)^T\theta_{j-1}^{u})]^{1-d_j^u}\cdot[1-\sigma(v(x)^T\theta_{j-1}^{u})]^{d_j^u}\}\\ &=\sum_{w\in c}\sum_{u\in Context(w)}\sum_{j=2}^{l^u}\{ (1-d_j^u)\cdot \log[\sigma(v(x)^T\theta_{j-1}^u)]+d_j^u\cdot \log[1-\sigma(v(w)^T\theta_{j-1}^u)]\} \end{aligned} L=w∈c∑logu∈Context(w)∏p(u∣w)=w∈c∑logu∈Context(w)∏j=2∏lup(dju∣v(w),θj−1u)=w∈c∑logu∈Context(w)∏j=2∏lu{[σ(v(x)Tθj−1u)]1−dju⋅[1−σ(v(x)Tθj−1u)]dju}=w∈c∑u∈Context(w)∑j=2∑lu{(1−dju)⋅log[σ(v(x)Tθj−1u)]+dju⋅log[1−σ(v(w)Tθj−1u)]}
为了方便梯度推导,将上式中的 三重求和符号 下 花括号 的内容简记为 L ( w , u , j ) \mathcal{L}(w,u,j) L(w,u,j),即:
L ( w , u , j ) = ( 1 − d j u ) ⋅ log [ σ ( v ( x ) T θ j − 1 u ) ] + d j u ⋅ log [ 1 − σ ( v ( w ) T θ j − 1 u ) ] \mathcal{L}(w,u,j)=(1-d_j^u)\cdot \log[\sigma(v(x)^T\theta_{j-1}^u)]+d_j^u\cdot \log[1-\sigma(v(w)^T\theta_{j-1}^u)] L(w,u,j)=(1−dju)⋅log[σ(v(x)Tθj−1u)]+dju⋅log[1−σ(v(w)Tθj−1u)]
L ( w , u , j ) \mathcal{L}(w,u,j) L(w,u,j) 关于 θ j − 1 u \theta_{j-1}^u θj−1u 的梯度计算:
∂ L ( w , u , j ) ∂ θ j − 1 u = ∂ ∂ θ j − 1 u { ( 1 − d j u ) ⋅ log [ σ ( v ( x ) T θ j − 1 u ) ] + d j u ⋅ log [ 1 − σ ( v ( w ) T θ j − 1 u ) ] } = [ 1 − d j u − σ ( v ( w ) T θ j − 1 u ) ] v ( x ) ( 推导类似,不赘述 ) \begin{aligned} \frac{\partial \mathcal{L}(w,u,j)}{\partial \theta_{j-1}^u}&=\frac{\partial }{\partial \theta_{j-1}^u}\{ (1-d_j^u)\cdot \log[\sigma(v(x)^T\theta_{j-1}^u)]+d_j^u\cdot \log[1-\sigma(v(w)^T\theta_{j-1}^u)]\}\\ &=[1-d_j^u-\sigma(v(w)^T\theta_{j-1}^u)]v(x)\ \ \textcolor{blue}{(推导类似,不赘述)} \end{aligned} ∂θj−1u∂L(w,u,j)=∂θj−1u∂{(1−dju)⋅log[σ(v(x)Tθj−1u)]+dju⋅log[1−σ(v(w)Tθj−1u)]}=[1−dju−σ(v(w)Tθj−1u)]v(x) (推导类似,不赘述)
如果使用 η \eta η表示学习率,此时 θ j − 1 u \theta_{j-1}^u θj−1u的更新公式可写为
θ j − 1 u : = θ j − 1 u + η [ 1 − d j u − σ ( v ( w ) T θ j − 1 u ) ] v ( w ) \theta_{j-1}^u:=\theta_{j-1}^u+\eta[1-d_j^u-\sigma(v(w)^T\theta_{j-1}^u)]v(w) θj−1u:=θj−1u+η[1−dju−σ(v(w)Tθj−1u)]v(w)
L ( w , u , j ) \mathcal{L}(w,u,j) L(w,u,j) 关于 v ( w ) v(w) v(w) 的梯度计算:
操作同上,使用对称性可得:
∂ L ( w , u , j ) ∂ v ( w ) = [ 1 − d j u − σ ( v ( w ) T θ j − 1 u ) ] θ j − 1 u \frac{\partial \mathcal{L}(w,u,j)}{\partial v(w)}=[1-d_j^u-\sigma(v(w)^T\theta_{j-1}^u)]\theta_{j-1}^u ∂v(w)∂L(w,u,j)=[1−dju−σ(v(w)Tθj−1u)]θj−1u
v ( w ) v(w) v(w)的更新公式就可以写作:
v ( w ) : = v ( w ) + η ∑ u ∈ C o n t e x t ( w ) ∑ j = 2 l u ∂ L ( w , u , j ) ∂ v ( w ) v(w):=v(w)+\eta\sum_{u\in Context(w)}\sum_{j=2}^{l^u}\frac{\partial \mathcal{L}(w,u,j)}{\partial v(w)} v(w):=v(w)+ηu∈Context(w)∑j=2∑lu∂v(w)∂L(w,u,j)
根据上述公式的梯度更新伪代码展示:

在Word2Vec源码中,采取的策略并非是遍历完 C o n t e x t ( w ) Context(w) Context(w)之后才更新 v ( w ) v(w) v(w),而是处理每一个 u u u之后就更新一下 v ( w ) v(w) v(w),也就是改动上述伪代码中两处:

四、基于Negative Sampling(负采样)的Word2Vec模型
4.1 基于负采样的CBOW模型
在 C B O W CBOW CBOW 模型中,已知上下文 C o n t e x t ( w ) Context(w) Context(w),预测 w w w,我们称需要预测的 w w w为正样本,词典中其他的单词就是负样本,暂不讨论负样本的选取要求和性质,假定已经选好了一个关于 C o n t e x t ( w ) Context(w) Context(w)的负样本子集 N E G ( w ) ≠ ∅ NEG(w)\neq \emptyset NEG(w)=∅。
对 ∀ w ~ ∈ D \forall \tilde w\in D ∀w~∈D,定义:
L w ( w ~ ) = { 1 w ~ = w 0 w ~ ≠ w L^w(\tilde w)= \begin{cases} 1&\tilde w=w\\ 0&\tilde w\neq w \end{cases} Lw(w~)={10w~=ww~=w
以 L w ( w ~ ) L^w(\tilde w) Lw(w~)作为词 w ~ \tilde w w~的标签,当其为正样本时取1,为负样本时取0。
仍然以 X w X_w Xw表示上下文词向量之和;以 θ u ∈ R m \theta^u\in \mathbb{R}^m θu∈Rm表示词 u u u的一个辅助向量(待训练的参数),此时我们可得表达式:
p ( u ∣ C o n t e x t ( w ) ) = [ σ ( X w T θ u ) ] L w ( u ) ⋅ [ 1 − σ ( X w T θ u ) ] 1 − L w ( u ) p(u|Context(w))=[\sigma(X_w^T\theta^u)]^{L^w(u)}\cdot[1-\sigma(X_w^T\theta^u)]^{1-L^w(u)} p(u∣Context(w))=[σ(XwTθu)]Lw(u)⋅[1−σ(XwTθu)]1−Lw(u)
此时我们需要借助另外一个函数来表示在包含负样本时,根据 C o n t e x t ( w ) Context(w) Context(w)正确预测 w w w的概率:
g ( w ) = ∏ u ∈ { w } ∪ N E G ( w ) p ( u ∣ C o n t e x t ( w ) ) = σ ( X w T θ w ) ∏ u ∈ N E G ( w ) [ 1 − σ ( X w T θ u ) ] g(w)=\prod_{u\in \{w\}\cup NEG(w)}p(u|Context(w))=\sigma(X_w^T\theta^w) \prod_{u\in NEG(w)}[1-\sigma(X_w^T\theta^u)] g(w)=u∈{w}∪NEG(w)∏p(u∣Context(w))=σ(XwTθw)u∈NEG(w)∏[1−σ(XwTθu)]
结合上述公式,最大化 g ( w ) g(w) g(w)就是我们在处理 C o n t e x t ( w ) Context(w) Context(w)时的目标,具体来说就是:
- 最大化 σ ( X w T θ w ) \sigma(X_w^T\theta^w) σ(XwTθw)
- 最小化 ∏ u ∈ N E G ( w ) [ 1 − σ ( X w T θ u ) ] \prod_{u\in NEG(w)}[1-\sigma(X_w^T\theta^u)] ∏u∈NEG(w)[1−σ(XwTθu)]
- 增加正样本概率的同时降低负样本的概率
考虑到语料库 C C C,我们此时可以得到目标函数:
L = ∑ w ∈ c log g ( w ) = ∑ w ∈ c log ∏ u ∈ { w } ∪ N E G ( w ) { [ σ ( X w T θ u ) ] L w ( u ) ⋅ [ 1 − σ ( X w T θ u ) ] 1 − L w ( u ) } = ∑ w ∈ c ∑ u ∈ { w } ∪ N E G ( w ) { L w ( u ) ⋅ log [ σ ( X w T θ u ) ] + [ 1 − L w ( u ) ] ⋅ log [ 1 − σ ( X w T θ u ) ] } \begin{aligned} \mathcal{L} &=\sum_{w\in c}\log g(w)\\ &=\sum_{w\in c}\log \prod_{u\in \{w\}\cup NEG(w)}\big\{ [\sigma(X_w^T\theta^u)]^{L^w(u)}\cdot[1-\sigma(X_w^T\theta^u)]^{1-L^w(u)}\big\}\\ &=\sum_{w\in c} \sum_{u\in \{w\}\cup NEG(w)}\{ L^w(u)\cdot \log[\sigma(X_w^T\theta^u)]+[1-L^w(u)]\cdot \log[1-\sigma(X_w^T\theta^u)]\} \end{aligned} L=w∈c∑logg(w)=w∈c∑logu∈{w}∪NEG(w)∏{[σ(XwTθu)]Lw(u)⋅[1−σ(XwTθu)]1−Lw(u)}=w∈c∑u∈{w}∪NEG(w)∑{Lw(u)⋅log[σ(XwTθu)]+[1−Lw(u)]⋅log[1−σ(XwTθu)]}
为了方便梯度推导,将上式中的 双重求和符号 下 花括号 的内容简记为 L ( w , u ) \mathcal{L}(w,u) L(w,u),即:
L ( w , u ) = L w ( u ) ⋅ log [ σ ( X w T θ u ) ] + [ 1 − L w ( u ) ] ⋅ log [ 1 − σ ( X w T θ u ) ] \mathcal{L}(w,u)=L^w(u)\cdot \log[\sigma(X_w^T\theta^u)]+[1-L^w(u)]\cdot \log[1-\sigma(X_w^T\theta^u)] L(w,u)=Lw(u)⋅log[σ(XwTθu)]+[1−Lw(u)]⋅log[1−σ(XwTθu)]
L ( w , u ) \mathcal{L}(w,u) L(w,u) 关于 θ u \theta^u θu 的梯度计算:
∂ L ( w , u ) ∂ θ u = ∂ ∂ θ u { L w ( u ) ⋅ log [ σ ( X w T θ u ) ] + [ 1 − L w ( u ) ] ⋅ log [ 1 − σ ( X w T θ u ) ] } = [ L w ( u ) − σ ( X w T θ u ) ] X w \begin{aligned} \frac{\partial \mathcal{L}(w,u)}{\partial \theta^u}&=\frac{\partial }{\partial \theta^u}\{ L^w(u)\cdot \log[\sigma(X_w^T\theta^u)]+[1-L^w(u)]\cdot \log[1-\sigma(X_w^T\theta^u)]\}\\ &=[L^w(u)-\sigma(X_w^T\theta^u)]X_w \end{aligned} ∂θu∂L(w,u)=∂θu∂{Lw(u)⋅log[σ(XwTθu)]+[1−Lw(u)]⋅log[1−σ(XwTθu)]}=[Lw(u)−σ(XwTθu)]Xw
如果使用 η \eta η表示学习率,此时 θ u \theta^u θu的更新公式可写为
θ u : = θ u + η [ L w ( u ) − σ ( X w T θ u ) ] X w \theta^u:=\theta^u+\eta[L^w(u)-\sigma(X_w^T\theta^u)]X_w θu:=θu+η[Lw(u)−σ(XwTθu)]Xw
L ( w , j ) \mathcal{L}(w,j) L(w,j) 关于 X w X_w Xw 的梯度计算:
操作同上,使用对称性可得::
∂ L ( w , u ) ∂ X w = [ L w ( u ) − σ ( X w T θ u ) ] θ u \frac{\partial \mathcal{L}(w,u)}{\partial X_w}=[L^w(u)-\sigma(X_w^T\theta^u)]\theta^u ∂Xw∂L(w,u)=[Lw(u)−σ(XwTθu)]θu
此时相应更新公式为:
v ( w ~ ) : = v ( w ~ ) + η ∑ u ∈ { w } ∪ N E G ( w ) ∂ L ( w , u ) ∂ X w , w ~ ∈ C o n t e x t ( w ) v(\tilde w):=v(\tilde w)+\eta\sum_{u\in \{w\}\cup NEG(w)}\frac{\partial \mathcal{L}(w,u)}{\partial X_w}, \tilde w \in Context(w) v(w~):=v(w~)+ηu∈{w}∪NEG(w)∑∂Xw∂L(w,u),w~∈Context(w)
梯度更新伪代码展示:

4.2 基于负采样的Skip-Gram模型
在包含负样本时,根据 w w w正确预测 C o n t e x t ( w ) Context(w) Context(w)的概率:
g ( w ) = ∏ w ~ ∈ C o n t e x t ( w ) ∏ u ∈ { w } ∪ N E G w ~ ( w ) p ( u ∣ w ~ ) = ∏ w ~ ∈ C o n t e x t ( w ) ∏ u ∈ { w } ∪ N E G w ~ ( w ) { [ σ ( v ( w ~ ) T θ u ) ] L w ( u ) ⋅ [ 1 − σ ( v ( w ~ ) T θ u ) ] 1 − L w ( u ) } \begin{aligned} g(w)&=\prod_{\tilde w\in Context(w)} \prod_{u\in \{w\}\cup NEG^{\tilde w}(w)}p(u|\tilde w)\\ &=\prod_{\tilde w\in Context(w)} \prod_{u\in \{w\}\cup NEG^{\tilde w}(w)}\{[\sigma(v(\tilde w)^T\theta^u)]^{L^w(u)}\cdot[1-\sigma(v(\tilde w)^T\theta^u)]^{1-L^w(u)}\} \end{aligned} g(w)=w~∈Context(w)∏u∈{w}∪NEGw~(w)∏p(u∣w~)=w~∈Context(w)∏u∈{w}∪NEGw~(w)∏{[σ(v(w~)Tθu)]Lw(u)⋅[1−σ(v(w~)Tθu)]1−Lw(u)}
需要说明的是,其中 N E G w ~ ( w ) NEG^{\tilde w}(w) NEGw~(w)表示的是处理词 w ~ \tilde w w~时生成的负样本子集。
考虑到语料库 C C C,我们此时可以得到目标函数:
L = ∑ w ∈ c log g ( w ) = ∑ w ∈ c log ∏ w ~ ∈ C o n t e x t ( w ) ∏ u ∈ { w } ∪ N E G w ~ ( w ) { [ σ ( v ( w ~ ) T θ u ) ] L w ( u ) ⋅ [ 1 − σ ( v ( w ~ ) T θ u ) ] 1 − L w ( u ) } = ∑ w ∈ c ∑ w ~ ∈ C o n t e x t ( w ) ∑ u ∈ { w } ∪ N E G w ~ ( w ) { L w ( u ) ⋅ log [ σ ( v ( w ~ ) T θ u ) ] + [ 1 − L w ( u ) ] ⋅ log [ 1 − σ ( v ( w ~ ) T θ u ) ] } \begin{aligned} \mathcal{L} &=\sum_{w\in c}\log g(w)\\ &=\sum_{w\in c}\log \prod_{\tilde w\in Context(w)} \prod_{u\in \{w\}\cup NEG^{\tilde w}(w)} \big\{[\sigma(v(\tilde w)^T\theta^u)]^{L^w(u)}\cdot[1-\sigma(v(\tilde w)^T\theta^u)]^{1-L^w(u)}\big\}\\ &=\sum_{w\in c} \sum_{\tilde w\in Context(w)} \sum_{u\in \{w\}\cup NEG^{\tilde w}(w)}\{ L^w(u)\cdot \log[\sigma(v(\tilde w)^T\theta^u)]+[1-L^w(u)]\cdot \log[1-\sigma(v(\tilde w)^T\theta^u)]\} \end{aligned} L=w∈c∑logg(w)=w∈c∑logw~∈Context(w)∏u∈{w}∪NEGw~(w)∏{[σ(v(w~)Tθu)]Lw(u)⋅[1−σ(v(w~)Tθu)]1−Lw(u)}=w∈c∑w~∈Context(w)∑u∈{w}∪NEGw~(w)∑{Lw(u)⋅log[σ(v(w~)Tθu)]+[1−Lw(u)]⋅log[1−σ(v(w~)Tθu)]}
为了方便梯度推导,将上式中的 三重求和符号 下 花括号 的内容简记为 L ( w , w ~ , u ) \mathcal{L}(w,\tilde w,u) L(w,w~,u),即:
L ( w , w ~ , u ) = L w ( u ) ⋅ log [ σ ( v ( w ~ ) T θ u ) ] + [ 1 − L w ( u ) ] ⋅ log [ 1 − σ ( v ( w ~ ) T θ u ) ] \mathcal{L}(w,\tilde w,u)=L^w(u)\cdot \log[\sigma(v(\tilde w)^T\theta^u)]+[1-L^w(u)]\cdot \log[1-\sigma(v(\tilde w)^T\theta^u)] L(w,w~,u)=Lw(u)⋅log[σ(v(w~)Tθu)]+[1−Lw(u)]⋅log[1−σ(v(w~)Tθu)]
L ( w , w ~ , u ) \mathcal{L}(w,\tilde w,u) L(w,w~,u) 关于 θ u \theta^u θu 的梯度计算:
∂ L ( w , w ~ , u ) ∂ θ u = ∂ ∂ θ u { ( L w ( u ) ⋅ log [ σ ( v ( w ~ ) T θ u ) ] + [ 1 − L w ( u ) ] ⋅ log [ 1 − σ ( v ( w ~ ) T θ u ) ] } = [ L w ( u ) − σ ( v ( w ~ ) T θ u ) ] v ( w ~ ) \begin{aligned} \frac{\partial\mathcal{L}(w,\tilde w,u)}{\partial \theta^u}&=\frac{\partial }{\partial \theta^u}\{ (L^w(u)\cdot \log[\sigma(v(\tilde w)^T\theta^u)]+[1-L^w(u)]\cdot \log[1-\sigma(v(\tilde w)^T\theta^u)]\}\\ &=[L^w(u)-\sigma(v(\tilde w)^T\theta^u)]v(\tilde w) \end{aligned} ∂θu∂L(w,w~,u)=∂θu∂{(Lw(u)⋅log[σ(v(w~)Tθu)]+[1−Lw(u)]⋅log[1−σ(v(w~)Tθu)]}=[Lw(u)−σ(v(w~)Tθu)]v(w~)
如果使用 η \eta η表示学习率,此时 θ u \theta^u θu的更新公式可写为
θ u : = θ u + η [ L w ( u ) − σ ( v ( w ~ ) T θ u ) ] v ( w ~ ) \theta^u:=\theta^u+\eta[L^w(u)-\sigma(v(\tilde w)^T\theta^u)]v(\tilde w) θu:=θu+η[Lw(u)−σ(v(w~)Tθu)]v(w~)
L ( w , w ~ , u ) \mathcal{L}(w,\tilde w,u) L(w,w~,u) 关于 v ( w ~ ) v(\tilde w) v(w~) 的梯度计算:
操作同上,使用对称性可得:
∂ L ( w , w ~ , u ) ∂ v ( w ~ ) = [ L w ( u ) − σ ( v ( w ~ ) T θ u ) ] θ u \frac{\partial \mathcal{L}(w,\tilde w,u)}{\partial v(\tilde w)}=[L^w(u)-\sigma(v(\tilde w)^T\theta^u)]\theta^u ∂v(w~)∂L(w,w~,u)=[Lw(u)−σ(v(w~)Tθu)]θu
v ( w ~ ) v(\tilde w) v(w~)的更新公式就可以写作:
v ( w ~ ) : = v ( w ~ ) + η ∑ u ∈ { w } ∪ N E G w ~ ( w ) ∂ L ( w , w ~ , u ) ∂ v ( w ~ ) v(\tilde w):=v(\tilde w)+\eta\sum_{u\in \{w\}\cup NEG^{\tilde w}(w)}\frac{\partial \mathcal{L}(w,\tilde w,u)}{\partial v(\tilde w)} v(w~):=v(w~)+ηu∈{w}∪NEGw~(w)∑∂v(w~)∂L(w,w~,u)
根据上述公式的梯度更新伪代码展示:

4.3 负采样算法
在了解了如何使用负采样进行概率计算后,我们还需要了解如何实现负采样,以及实现过程中需要注意哪些细节。
词典 D \mathcal{D} D的不同单词在语料 C \mathcal{C} C有着不同的词频,也就导致采样过程中,被选为负样本的概率存在差异,其本质就是一个带权采样问题,相关描述如下:
设词典 D \mathcal{D} D中的每一个词对应一个线段 l ( w ) l(w) l(w),长度为:
l e n ( w ) = c o u n t e r ( w ) ∑ u ∈ D c o u n t e r ( u ) len(w)=\frac{counter(w)}{\sum_{u\in \mathcal{D}}counter(u)} len(w)=∑u∈Dcounter(u)counter(w)
其中 c o u n t e r ( w ) counter(w) counter(w)表示该词在语料中的出现次数,如果将这些线段首尾相连接在一起,就形成了一个长度为1的线段,此时便可以直观看出不同单词的词频差异。
但在Word2Vec中,设置单词权值时用的是下列式子:
l e n ( w ) = [ c o u n t e r ( w ) ] 3 4 ∑ u ∈ D [ c o u n t e r ( u ) ] 3 4 len(w)=\frac{[counter(w)]^{\frac{3}{4}}}{\sum_{u\in \mathcal{D}}[counter(u)]^{\frac{3}{4}}} len(w)=∑u∈D[counter(u)]43[counter(w)]43
这是为了给低频词更多的学习机会,这样低频词在负采样中的出现概率会相对提高。

参数说明:
- l 0 = 0 , l k = ∑ j = 1 k l e n ( w j ) , k = 1 , 2 , … , N l_0=0,l_k=\sum_{j=1}^{k}len(w_j),k=1,2,\dots,N l0=0,lk=∑j=1klen(wj),k=1,2,…,N;以 { l j } j = 0 N \{l_j\}_{j=0}^N {lj}j=0N为剖分节点,可得到区间 [ 0 , 1 ] [0,1] [0,1]上的一个非等距剖分;
- 根据 { l j } j = 0 N \{l_j\}_{j=0}^N {lj}j=0N可得到 N N N个剖分区间,可表示为: I i = ( l i − 1 , l i ] , i = 1 , 2 , … , N I_i=(l_{i-1},l_i],i=1,2,\dots,N Ii=(li−1,li],i=1,2,…,N
- 如果使用等距剖分,剖分节点为 { m j } j = 0 M \{m_j\}_{j=0}^M {mj}j=0M,其中 M > > N M>>N M>>N;
如果将内部剖分节点 { m j } j = 1 M − 1 \{m_j\}_{j=1}^{M-1} {mj}j=1M−1投影到非等距剖分上,就可以借助这种映射实现采样,需要说明的是,负采样过程中需要避免正例,如果遇见正样本直接跳过即可。