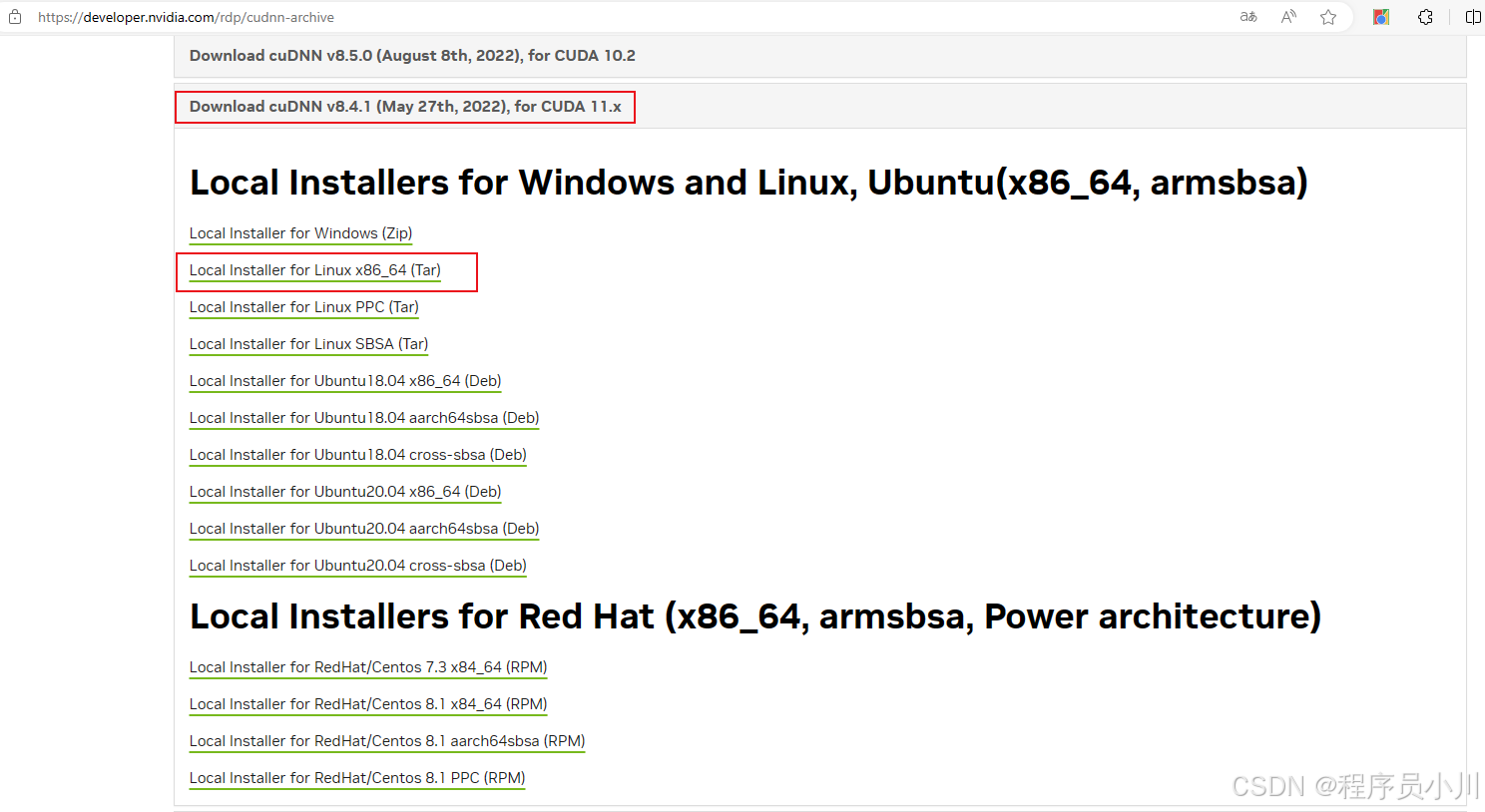
机器学习之非监督学习(一)K-means 聚类算法
- 0. 文章传送
- 1.非监督学习定义
- 2.非监督学习分类
- 2.1 聚类 Clustering
- 2.2 异常检测 Anomaly Detection
- 3.K-means聚类算法 K-means clustering
- 案例引入
- 算法步骤
- 算法优化
- 成本函数
- 初始化方法
- K的选择
- 代码实现
- 4.案例实战:图像压缩
0. 文章传送
机器学习之监督学习(一)线性回归、多项式回归、算法优化[巨详细笔记]
机器学习之监督学习(二)二元逻辑回归
机器学习之监督学习(三)神经网络基础
机器学习之实战篇——预测二手房房价(线性回归)
机器学习之实战篇——肿瘤良性/恶性分类器(二元逻辑回归)
机器学习之实战篇——MNIST手写数字0~9识别(全连接神经网络模型)
机器学习之监督学习(四)决策树和随机森林
1.非监督学习定义
非监督学习是一种机器学习方法,在这种方法中,模型在没有预先标记的数据的情况下进行训练。相较于监督学习(需要提供输入和对应的输出标签),非监督学习仅依赖输入数据自身的结构来发现数据内部的模式和关系。
2.非监督学习分类
2.1 聚类 Clustering
聚类的目标是将数据集划分成多个组(或簇),使得簇内的数据点彼此相似,而不同簇的数据点差异较大。常见的聚类算法有 K 均值聚类(K-Means)、层次聚类和 DBSCAN 等。
2.2 异常检测 Anomaly Detection
异常检测的目标是识别数据集中与大多数数据点显著不同的异常数据点。异常检测在网络安全、金融欺诈检测等领域有广泛应用。常见的方法有孤立森林(Isolation Forest)和基于密度的检测方法等。
3.K-means聚类算法 K-means clustering
案例引入
在购买衣物时,我们通常根据自己的身高和体重来选择合适尺码的衣服,常见的衣服衣服型号标法为小(S)、中(M)、大(L)。假设某衣服生产商收集了一些用户身高和体重的数据,如果要根据这些数据点划分三个类别,该如何实现最优划分呢?这便是典型的聚类问题,如下图所示,三个圈代表三种型号,将无标签的数据划分为三个类别。下面介绍处理聚类问题的K-means算法。

算法步骤
K-means聚类算法步骤如下:
- randomly generate cluster centroids 随机产生簇心
- assign each point to its closest centroid 将点分配到最近的簇中
- recompute the centroids 重新计算簇心 (簇内的中心点)
- repeat step2 and step3 重复步骤2和步骤3直至簇心不再移动(或点所处簇不再改变)

从上面的动图可以很直观地理解算法的思想,需要注意的是,起始点选择不同,聚类的结果也不同。
用数学语言表示如下:
m 个数据, n 个特征, m 个数据分别记为 x ( 1 ) 、 x ( 2 ) 、 . . . 、 x ( m ) ,每个数据为 n 维向量 m个数据,n个特征,m个数据分别记为x^{(1)}、x^{(2)}、...、x^{(m)},每个数据为n维向量 m个数据,n个特征,m个数据分别记为x(1)、x(2)、...、x(m),每个数据为n维向量
目标 : 将数据分为 K 部分 , 划分结果保存在 m × 1 列向量 c 中 目标:将数据分为K部分,划分结果保存在m\times1列向量c中 目标:将数据分为K部分,划分结果保存在m×1列向量c中
S t e p 1 : 随机初始化 K 个簇心 μ 1 、 μ 2 、 . . . 、 μ K Step1:随机初始化K个簇心\mu_1、\mu_2、...、\mu_K Step1:随机初始化K个簇心μ1、μ2、...、μK
S t e p 2 : 重复 c ( i ) = arg min k ∣ ∣ x ( i ) − μ k ∣ ∣ Step2:重复 \quad c^{(i)}=\argmin_{k}||x^{(i)}-\mu{_k}|| Step2:重复c(i)=argmink∣∣x(i)−μk∣∣
S t e p 3 : μ k = a v e r a g e ( x ( i ) ) ∣ c ( i ) = k Step3: \mu_k=average(x^{(i)})|c^{(i)}=k Step3:μk=average(x(i))∣c(i)=k
S t e p 4 : 重复 S t e p 2 和 S t e p 3 Step4:重复Step2和Step3 Step4:重复Step2和Step3
注意:在训练过程中,可能出现某一簇(或多)内无点的情况,结果产生K-1(>1)簇。此时可以更改决策方案,或者如果希望目标结果必须产生K个簇,那么可以更改起始簇心位置再次进行聚类。
算法优化
成本函数
既然初始簇心选择不同会导致聚类结果不同,那么如何评估聚类效果并选择最优方案。设计优化函数,首先需要先定义成本函数:
J ( c ( 1 ) , . . . , c ( m ) , μ 1 、 . . . 、 μ K ) = 1 m ∑ i = 1 m ∣ ∣ x ( i ) − μ c ( i ) ∣ ∣ 2 J(c^{(1)},...,c^{(m)},\mu_{1}、...、\mu_{K})=\frac{1}{m}\sum_{i=1}^{m}||x^{(i)}-\mu_{c^{(i)}}||^2 J(c(1),...,c(m),μ1、...、μK)=m1∑i=1m∣∣x(i)−μc(i)∣∣2
由于聚类结果的具体表现是各个簇心的位置以及每个数据被归类情况,因此J包含了上面所示的m+K个参数。这里的成本函数是平均每个数据点到所处簇心距离的平方。再回过头看上面的算法步骤,我们发现算法实际上就是不断减少J的过程:
Step 2 : fix μ \mu μ,assign c c c to minimize J(固定簇心位置,分配每个数据点给最近的簇心,下降J)
Step 3 : fix c,shift μ \mu μ to minimize J(固定每个数据点所属簇,中心化簇心位置,下降J)
In theory : J keep going down and converge(理论上,J不断下降直至收敛)
有了成本函数,我们就可以采用蒙特卡罗思想,进行多次试验,不同初始化得到的最终结果存在差异,挑选cost最小的作为最优方案。
初始化方法
还有一个问题需要解决,如何随机初始化簇心?下面是几种随机初始化方法:
①随机选择数据点
方法:从数据集中随机选择 K 个数据点作为初始簇心。
优点:简单易行,快速实现。
缺点:可能会选择到极端点,导致不良结果。
② 分布式初始化
方法:将数据空间划分为 K 个区域,然后从每个区域中随机选择一个数据点作为簇心。
优点:可以确保簇心的初始位置分散,避免集中在某一部分数据上。
③ K-means++
方法:在选择每个新的簇心时,使得新簇心与已有簇心的距离尽可能远。具体步骤如下:
随机选择一个数据点作为第一个簇心。
对于每个数据点,计算其与已选择簇心的最小距离。
根据这些距离的平方(即 D(x)^2)进行概率选择,选择下一个簇心。
重复步骤 2 和 3 直到选择到 K 个簇心。
优点:能显著提高聚类效果,通常收敛速度更快,得到的结果更稳定。
注: 关于概率选择,可以使用numpy.random中的choice函数,示例:
next_center = np.random.choice(X, p=probabilities)
K的选择
有时候我们并不能提前根据数据点的分布确定聚类的类别数量K,或者对K的选择没有什么思路,以下是关于K的一些选择策略和解释:
肘部法 elbow method :
方法:通过绘制K-J曲线,选择合适的K(下降变化速率发生突变的临界K值)
弊端:不适用于平滑下降的曲线

除了上面的技术方法,考虑实际业务需求和可解释性也非常重要。例如:
- 市场需求:根据市场调研和客户反馈,了解消费者对不同型号的需求。这可以帮助你决定是否需要更多的细分(即更多的聚类)或者更简单的分类(即更少的聚类)。
- 生产和库存管理:更多的型号意味着更复杂的生产和库存管理。评估你的生产能力和库存管理能力,确定是否能有效管理更多的型号。
- 可解释性:更多的聚类可能导致更难解释每个型号的特点,特别是对销售和市场团队而言。确保每个聚类(型号)都能被清晰地描述和定位。
代码实现
K-means算法每个步骤函数以及最后整合的完整如下,
import numpy as np
import matplotlib.pyplot as plt# 计算每个数据点所归属的簇
def find_closest_centroids(X, centroids):K = centroids.shape[0]m = X.shape[0]idx = np.zeros(m, dtype=int)for i in range(m):idx[i] = np.argmin(np.sum((X[i] - centroids) ** 2, axis=1))return idx# 根据当前分类情况计算新的簇心
def compute_centroids(X, idx, K):m, n = X.shapecentroids = np.zeros((K, n))for k in range(K):cond = (idx == k)if cond.any():X_k = X[cond]centroids[k] = np.mean(X_k, axis=0)else: # 如果没有点被分配到这个簇,则随机选择一个点作为新的簇心centroids[k] = X[np.random.choice(X.shape[0])]return centroids# 随机初始化簇心
def kMeans_init_centroids(X, K):randidx = np.random.permutation(X.shape[0])centroids = X[randidx[:K]]return centroids# 成本函数
def KMeans_compute_cost(X, centroids, idx):m = X.shape[0]cost = 0for i in range(m):K_idx = idx[i]X_centroid = centroids[K_idx]cost += np.sum((X_centroid - X[i]) ** 2)return cost / m# 运行 K-means 聚类算法
def run_kMeans(X, K, max_iters=10, test_times=50):m, n = X.shapemin_cost = float('inf')best_idx = np.zeros(m)best_centroids = np.zeros((K, n))for j in range(test_times):print(f'K-Means test {j}/{test_times - 1}:')initial_centroids = kMeans_init_centroids(X, K)centroids = initial_centroidsfor i in range(max_iters):print(f'K-Means iteration {i}/{max_iters - 1}', end=', ')idx = find_closest_centroids(X, centroids)centroids = compute_centroids(X, idx, K)cost = KMeans_compute_cost(X, centroids, idx)if cost < min_cost:min_cost = costbest_idx = idxbest_centroids = centroidsprint(f'cost: {cost}, min_cost: {min_cost}')return best_centroids, best_idx为了验证代码正确性和性能,随机在平面内三个点附近生成一系列点,构成试验数据集,并运行聚类算法最后可视化
# 生成数据集
def generate_data():np.random.seed(42)cluster1 = np.random.randn(100, 2) + np.array([1, 1])cluster2 = np.random.randn(100, 2) + np.array([5, 5])cluster3 = np.random.randn(100, 2) + np.array([9, 1])return np.vstack((cluster1, cluster2, cluster3))# 可视化数据和聚类结果
def visualize(X, centroids, idx):plt.figure(figsize=(8, 6))K = centroids.shape[0]# 绘制数据点for k in range(K):plt.scatter(X[idx == k, 0], X[idx == k, 1], label=f'Cluster {k + 1}')# 绘制簇心plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='red', marker='X', label='Centroids')plt.title('K-means Clustering')plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.legend()plt.show()# 主函数
if __name__ == "__main__":# 生成数据集X = generate_data()# 设置簇的数量K = 3max_iters = 10test_times = 50# 运行 K-means 聚类best_centroids, best_idx = run_kMeans(X, K, max_iters, test_times)# 可视化结果visualize(X, best_centroids, best_idx)
实验结果:可以看到聚类效果很好,三个簇心几乎与数据集构建的三个起始点重合。