关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
在众多开源项目中脱颖而出,OpenAssistant 有两把刷子。
转自《机器之心》
事实证明,将大型语言模型 (LLM) 与人类偏好保持一致可以显著提高可用性,这类模型往往会被快速采用,如 ChatGPT 所证明的那样。监督微调 (SFT) 和基于人类反馈的强化学习 (RLHF) 等对齐技术大大减少了有效利用 LLM 功能所需的技能和领域知识,从而提高了它们在各个领域的可访问性和实用性。
然而,像 RLHF 这样最先进的对齐技术依赖于高质量的人工反馈数据,这些数据的创建成本很高,而且通常仍然是专有的。
为了使大规模对齐研究民主化,来自 LAION AI 等机构(Stable diffusion 使用的开源数据就是该机构提供的。)的研究者收集了大量基于文本的输入和反馈,创建了一个专门训练语言模型或其他 AI 应用的多样化和独特数据集 OpenAssistant Conversations。
该数据集是一个由人工生成、人工注释的助理式对话语料库,覆盖了广泛的主题和写作风格,由 161443 条消息组成,分布在 66497 个会话树中,使用 35 种不同的语言。该语料库是全球众包工作的产物,涉及超过 13500 名志愿者。对于任何希望创建 SOTA 指令模型的开发者而言,它都是一个非常宝贵的工具。并且任何人都可以免费访问整个数据集。
此外,为了证明 OpenAssistant Conversations 数据集的有效性,该研究还提出了一个基于聊天的助手 OpenAssistant,其可以理解任务、与第三方系统交互、动态检索信息。可以说这是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。
结果显示,OpenAssistant 的回复比 GPT-3.5-turbo (ChatGPT) 更受欢迎。

论文地址:https://drive.google.com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
项目地址:https://github.com/LAION-AI/Open-Assistant
数据集地址:https://huggingface.co/datasets/OpenAssistant/oasst1
体验地址:https://open-assistant.io/chat
网友表示:做得好,超越 OpenAI(抱歉是 Closed AI)。

研究介绍
OpenAssistant Conversations 的基本数据结构是会话树 (Conversation Tree, CT),其中的节点表示会话中的消息。
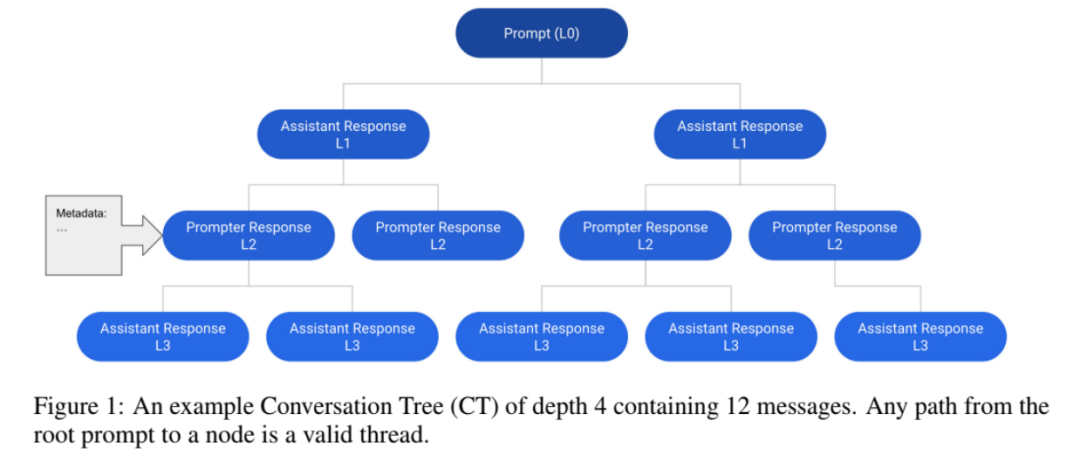
OpenAssistant Conversations 数据是使用 web-app 界面收集的,包括 5 个步骤:提示、标记提示、将回复消息添加为提示器或助手、标记回复以及对助理回复进行排名。

下图为 OpenAssistant Conversations 数据集语言分布,主要以英语和西班牙语为主:

实验结果
指令微调
为了评估和证明 OpenAssistant Conversations 数据集的有效性,研究者专注于基于 Pythia 和 LLaMA 的微调语言模型。其中 Pythia 是一个具有宽松开源许可的 SOTA 语言模型,而 LLaMA 是一个具有定制非商业许可的强大语言模型。
对此,研究者发布了一系列微调语言模型,包括指令微调的 Pythia-12B、LLaMA-13B 和 LLaMA-30B,这是他们迄今最大的模型。研究者将分析重心放在了具有开源属性的 Pythia-12B 模型上,使得它可以被广泛访问并适用于各种应用程序。
为了评估 Pythia-12B 的性能,研究者展开了一项用户偏好研究,将其输出与 OpenAI 的 gpt-3.5-turbo 模型进行比较。目前已经有 7,042 项比较,结果发现 Pythia-12B 对 gpt-3.5-turbo 的胜率为 48.3%,表明经过微调的 Pythia 模型是非常具有竞争力的大语言模型。
偏好建模
除了指令微调模型之外,研究者还发布了基于 Pythia-1.4B 和 Pythia-12B 的经过训练的奖励模型。利用在真实世界数据上训练的奖励模型可以为用户输入带来更准确和自适应的响应,这对于开发高效且对用户友好的 AI 助手至关重要。
研究者还计划发布经过人类反馈强化学习(RLHF)训练的 LLaMA-30B,这种方法可以显著提升模型性能和适应性。不过,基于 RLHF 方法的模型开发与训练正在进行中,需要进一步努力确保成功地整合进来。
有毒信息
研究者采取基于 Detoxify 的毒性检测方法来获得六个不同类别的自动评级,分别是有毒、色情、威胁、侮辱、攻击性、露骨言论。使用自动毒性评级,研究者系统地评估了人工指定毒性标签(如仇恨言论、不恰当和色情)的级别。并且基于 115,153 条消息样本,他们计算了自动与人工注释毒性标签之间的相关性,如下图 5 所示。

与 GPT-3.5(ChatGPT)的比较
我们来看几组 OpenAssistant 与 GPT-3.5 的生成结果比较。比如「单词 barn 的词源 / 起源是什么?」可以看到,OpenAssistant 解释地更详细、全面。

再比如输入「你现在是一个普通的人类。请介绍一下你自己并告诉我一些你的日常生活。」OpenAssistant 代入了普通人类的角色,GPT-3.5 显然没有,还是以 AI 语言模型自居。

最后输入「如何创建一个成功的 YouTube 频道,从开发一个利基市场到创建内容以建立一个社区并货币化频道?」OpenAssistant 的回答相对而言更有条理性。

体验下来,中文不太行
目前的 Open Assistant 基于「OA_SFT_Llama_30B」模型,最大新 token 的数量为 1024,支持了英文、中文、日语等数十种语言。

先让它做一下自我介绍。

然而在中文对话体验中发现,有时输入中文,但输出的仍是英文。比如「用中文写一首关于春天的诗歌」。

除了有时无法输出中文之外,中文百科知识方面也表现不佳。比如「介绍一下李白和杜甫」。

再比如「鲁智深是红楼梦中的角色,你觉得对吗」,人名和出处都搞错了。

另外在中英互译方面也不太好使。
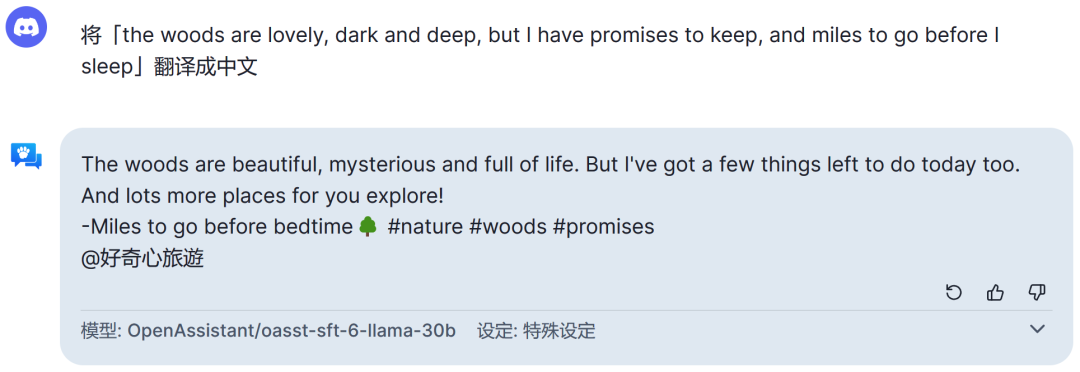

更不用提数学问题了,比如经典的鸡兔同笼问题。

这可能是因为在中文等其他语言的适配性上没有进行优化,希望未来可以改进。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606