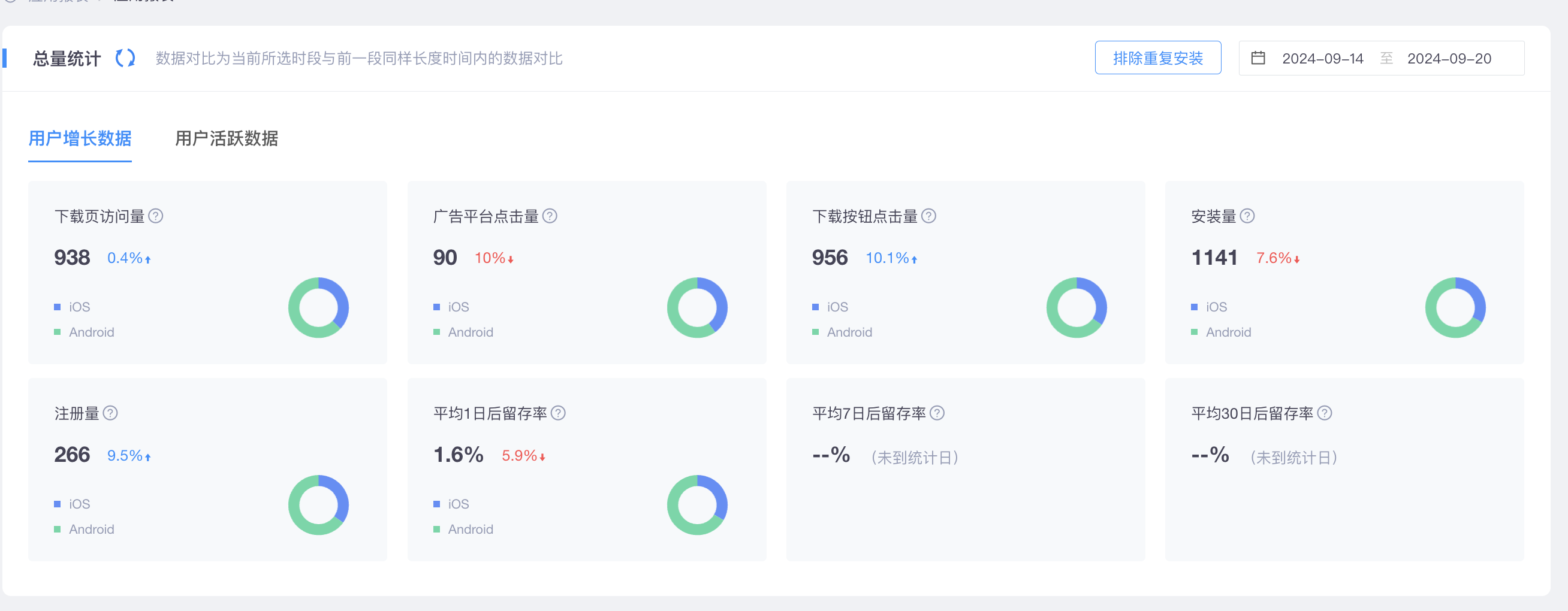
1. 最终一致性
1.1. 在一些应用领域,通常谈论的是银行和金融行业,最终一致性根本不合适
1.2. 事实上,最终一致性在银行业已经使用了很多年
-
1.2.1. 支票需要几天时间才能在你的账户上进行核对,而且你可以轻松地开出比账户余额多的支票
-
1.2.2. 当处理检查并建立一致性后,你才能看到一些后果
1.3. 在过去的好日子里,系统的所有数据项都有一个单一的真实来源,即数据库,不存在副本一致性的问题,因为根本没有副本
1.4. 为了保证每个节点的数据高可用,还需要对每个节点的内容进行复制,以消除单点故障
-
1.4.1. 当数据库节点和网络快速且可靠地工作时,用户不知道他们正在与分布式系统交互
-
1.4.2. 副本似乎是即时被更新的,同时用户请求的处理响应时间很短
- 1.4.2.1. 不一致的读取很少见
-
1.4.3. 出现故障意味着你的数据库副本保持不一致的时间可能比你的应用程序能容忍的时间更长
1.5. 不一致窗口
-
1.5.1. 最终一致系统中的不一致窗口是数据对象被更新并传播到所有副本所需的持续时间
-
1.5.2. 在领导者-追随者模式的系统中,领导者协调其他副本进行更新
-
1.5.3. 在无领导系统中,任何副本(或者是任何数据库节点——这取决于实现)都会协调更新
-
1.5.4. 当所有副本都具有相同的值时,不一致窗口结束
-
1.5.5. 影响不一致窗口持续时间的因素
-
1.5.5.1. 副本数目
1.5.5.1.1. 副本越多,需要协调的副本更新就越多
1.5.5.1.2. 只有当所有副本都相同时,不一致窗口才会关闭
1.5.5.1.3. 拥有的副本越多,不一致窗口受个别响应缓慢的副本影响而导致窗口延长的可能性就会增加
-
1.5.5.2. 运维环境
1.5.5.2.1. 任何瞬时操作故障,例如瞬时网络故障或数据包丢失,都会延长不一致窗口
1.5.5.2.2. 副本存在更新延迟的主要原因可能是节点上的大量读/写工作负载
1.5.5.2.2.1. 导致副本过载并产生额外的数据传播延迟
1.5.5.2.3. 数据库承受的负载越多,不一致窗口可能就越长
-
1.5.5.3. 副本之间的距离
1.5.5.3.1. 如果所有副本都在同一个局域网子网上,通信延迟可能是亚毫秒级的
1.5.5.3.2. 只要有一个副本跨越大陆或世界各地,不一致窗口的最小值都将是副本之间的往返时间
-
1.5.5.4. 所有这些问题都意味着你无法控制不一致窗口的持续时间
-
1.6. 读写一致性
-
1.6.1. 读写一致性是系统的一个属性,它确保如果客户端对数据进行持久更改,更新后的数据值由同一客户端的任何后续读取返回
-
1.6.2. 不一致窗口期间客户端有可能的情况
-
1.6.2.1. 发布对数据库数据对象键的更新
-
1.6.2.2. 对相同的数据库对象键发出后续读取操作,由于它访问的是一个副本,未保留最近的更新,导致访问到过时的数据
-
-
1.6.3. 采用领导者-追随者副本时,实现读写一致性很简单
-
1.6.3.1. 对于要求读写一致性的用例,你只需确保后续读取由领导者副本处理
1.6.3.1.1. 可以保证读取的是最新的数据对象值
-
-
1.6.4. MongoDB的默认行为是通过访问主副本实现
-
1.6.5. 在Neo4j集群中,所有写入操作都由领导者处理,领导者异步更新只读的副本
- 1.6.5.1. 读取操作可能由副本处理
1.7. 最终一致数据库广泛应用于大型系统中
-
1.7.1. 在线博彩和游戏行业依赖于高可用性和低延迟
-
1.7.2. 写入Riak KV的数据自动写入跨全球分布式集群的多个副本,具有可调节一致性,以便用户访问靠近其物理位置的副本来提供高可用性和低延迟
1.8. 最终一致数据库已经成为可扩展分布式系统领域的一个既定部分
-
1.8.1. 简单的、可演化的数据模型通过自然分区和复制来实现可扩展性和可用性,为许多互联网规模的系统提供了出色的解决方案
-
1.8.2. 最终一致数据库难免为系统提供过时的数据
-
1.8.3. 大多数数据库都提供可调节一致性,允许系统设计人员平衡读取和写入的延迟,并权衡可用性和一致性以满足应用程序需求
-
1.8.4. 对数据库中不同副本的同一对象的并发写入会导致冲突
2. 可调节一致性
2.1. 许多最终一致的数据库允许你通过配置选项和API参数来定制数据库的最终一致行为,可以根据用例能容忍的副本最终一致性级别来权衡读写操作的性能
2.2. 可调节一致性基于要完成数据库请求必须访问的特定副本数
3. 读取和写入仲裁
3.1. 法定数仲裁是多数副本,即(N/2)+1
3.2. 对于三个副本,法定数仲裁意味着写入必须在两个副本上成功,而读取必须访问两个副本
3.3. 仲裁的直观表现是,始终在大多数副本中读取和写入,读取请求将看到数据库对象最新版本的值
3.4. 如果法定数的节点不可用,写入和读取将失败
3.5. 宽松仲裁(sloppy quorum)
-
3.5.1. 宽松仲裁第一次出现在Amazon的早期Dynamo论文的描述中,并在DynamoDB、Cassandra、Riak和Voldemort多个数据库中实现
-
3.5.2. 如果副本节点不可用而导致写入操作无法达到给定的法定数,则将更新临时存储在另一个可访问的节点上
4. 副本修复
4.1. 在分布式、自我复制数据库中,你希望每个副本都是一致的
4.2. 系统会随着时间的推移趋向于熵(无序)
- 4.2.1. 数据库需要采取积极措施来确保副本保持一致,这些措施统称为反熵修复
4.3. 主动修复
-
4.3.1. 在访问对象时应用程序的主动修复
-
4.3.2. 主动修复对于频繁读取的数据库对象有效
-
4.3.3. 主动副本修复也称为读取修复,是在响应数据库读取请求时发生的
-
4.3.4. 如果有任何值不一致,协调器将向副本发回最新值以更新过时的值
-
4.3.5. 读取修复的工作方式取决于数据库实现
4.4. 被动修复
-
4.4.1. 对于不常访问的对象(很可能是你的绝大多数数据),使用被动修复策略
-
4.4.2. 被动反熵修复通常是一个定期运行的进程,旨在修复不常访问的副本
-
4.4.3. 构建Merkle树是一种CPU和内存密集型操作,该操作要么按需启动(由管理工具启动),要么定期安排
5. 冲突处理
5.1. 在无领导系统中,写入操作可以由任何副本处理
5.2. 最后写入者胜出
-
5.2.1. 决定最终值的一种方法是使用时间戳
-
5.2.2. 为更新请求生成一个时间戳,数据库确保并发写入发生时,具有最新时间戳的更新成为最终版本
-
5.2.3. 机器上的时钟会漂移
-
5.2.3.1. 更新请求由两个或多个独立进程在不同副本上的同一数据对象执行
-
5.2.3.2. 这些更新必须被视为同时的或并发的
-
5.2.3.3. 附加到更新请求的时间戳只是施加了任意顺序来解决冲突罢了
-
-
5.2.4. 使用最后写入者胜出策略来解决冲突,数据丢失是不可避免的
-
5.2.5. 在数据库中安全地使用纯粹的最后写入者胜出策略的唯一方法是确保所有写入都使用唯一键存储数据对象,并且对象在后续操作中是不可变的
- 5.2.5.1. 对数据库中数据的任何更改都需要读取现有数据对象,并使用新键将新内容写入数据库
5.3. 版本向量
-
5.3.1. 每个唯一的数据库对象都与版本号一起存储
-
5.3.2. 如果写入的版本号与数据库对象版本不匹配,则发生冲突,数据库必须采取补救措施以确保数据不丢失
-
5.3.3. 管理版本向量是数据库的责任
- 5.3.3.1. 数据库客户端只需要提供带有更新的最新版本,并在冲突发生时进行处理
-
5.3.4. 逻辑时钟
-
5.3.4.1. CPU测量的物理时间在分布式系统中不是可靠的时间来源
-
5.3.4.2. Leslie Lamport在他的开创性论文中首次提到了逻辑时钟
5.3.4.2.1. 这项工作的本质是happens-before关系的定义
5.3.4.2.2. 如果一个进程发生操作a(例如,一个数据库请求),并在它完成后发生操作b,则a happens-before b。这由a→b表示
5.3.4.2.3. 如果一个进程向另一个进程发送消息m,则发送发生在接收之前,即发送happens-before接收
5.3.4.2.4. 如果两个独立的进程执行操作a→b和c→d,则无法定义{a,b}和{c,d}之间的顺序
5.3.4.2.5. 关系happens-before是可传递的,如果a→b和b→c,则a→c
-
5.3.4.3. 系统可以使用逻辑时钟捕获happens-before关系,使用简单的计数器和算法达成
5.3.4.3.1. 每个进程都有一个本地时钟,进程启动时将其初始化为零
-
5.3.4.4. Lamport时钟定义了部分事件之间的顺序,然而它无法辨别没有因果关系的并发请求
5.3.4.4.1. 它不能用于检测数据库冲突
5.3.4.4.1.1. 这便是版本向量的使用场景了
-
-
5.3.5. Redis、Cosmos DB和Riak等数据库正在利用研究社区的最新成果来支持名为CRDT(无冲突数据副本类型)的数据类型集合
- 5.3.5.1. CRDT的一个简单示例是一个可用于维护社交媒体网站上用户的关注者数量的计数器