关联比赛: FashionAI全球挑战赛—服饰关键点定位
昨天是天池Fashion AI初赛Deadline, 成绩出来复赛都没能进,虽然结果很遗憾,但在比赛的过程中也接触到了不少的新东西,希望能在这里把我尝试过的方法都分享出来。作为对自己的总结,如果能让看到的人以后少踩点坑,那也算是一丢丢的贡献吧。
由于各种原因,真的着手在这个比赛的时间大概就一个星期,前后只提交了几次。失败也是对"各种原因"的一个惩罚吧。水平极其有限(不然就不是失败经历分享了),欢迎分享 : )。不多废话,下面进入正题。
# 比赛内容
我参加的是Fashion AI 服装关键点定位的比赛,目标就是通过算法找到图片中衣服的各个关键点。具体关键点如下图所示:

详细的赛制和数据可以在这里找到:[FashionAI全球挑战赛——服饰关键点定位](https://tianchi.aliyun.com/competition/introduction.htm?spm=5176.100066.0.0.6acdd780km5qMe&raceId=231648)。
# 算法
这年头碰上图像识别,深度学习基本是没跑了。虽然深度学习模型的可解释性基本没有,但效果就是杠杠的,用的时候嘴上说着不要不要,编辑器里面还是很诚实地 ```import keras```。如果有别的算法可以马上出效果(浮躁啊),我也想改,可惜暂时没有想到。
对于比赛数据,有几点基础的条件可以直接获得:
- 每一张图片只对应一件衣物,所以不需要考虑多件衣服的情况。只要单纯地做识别就好了。
- 处理对象是图片不是视频,只要把预测结果上交就行,所以不需要太担心模型运算复杂度,也就是不需要把精力放在 real time recognition 上面。
- 衣服跟人不一样,不像人手,衣服的衣袖可长可短,夏天来了还可以没有。这相对于一般的 pose estimation 增加了一定的难度。
总的来说,在形状上衣服跟人还是很相像的,所以我把突破口放在了 pose estimation 的一类算法上,反正这类算法本质上也就是给图片圈重点。希望能在比赛结果出来后看到更好的突破口,不然看到自己是输在没时间调参洗数据那也是很郁闷的事情。
数据分5类,分别是 blouse, outwear, dress, skirt, trousers。 我对每一类都训练一个单独的模型,也就是说有5个独立的模型。
## Deeppose
根据上面第一条,我们不需要考虑多人的情况。那最简单粗暴的方法就是对所有关键点x, y坐标进行regression。再怎么不济也会有个结果,对吧?于是我一开始直接上了14年Google大神弄出来的deeppose模型。主要思想就是给每张图片定义一个bounding box,这个bounding box可以是一个绕着衣服的框框,也可以是整张图片。然后计算每个关键点根这个bounding box的相对位置,最后用bounding box的长和宽对这些相对位置进行 normalization。得出来的结果就是模型训练的目标。这是应该是最粗暴的regression模型了。
然而现实却是很骨感的,我分别尝试了以下几个模型作为基模型来构建 deeppose:
- 一个简单的4层卷积模型
- VGG16
- VGG19
- Resnet 50
所有这些模型训练后都成了一个鬼样,那就是模型的输出固定不变。也就是说,无论我扔什么图片进去作为输入,输出的结果都是一样的。境遇有点像这位同学[[Tensorflow] Human Pose estimation by Deep Learning ](https://hypjudy.github.io/2017/05/04/pose-estimation/)。我看了一下模型中间层的权重和输出,发现上述模型训练后的第一层卷积的输出都是0,也就是说网络在梯度下降的洗礼后都会不约而同地卡在同一个 local minimum 里面。
我尝试过迁移学,把前面的一些层给锁死,结果就是第一个没有锁死的层的输出还是会变成全零,一样的配方,一样的味道,一样的坑。如果你跟我一样,想到要不就不要对关键点进行 normalization 了,数字大一点说不定会好呢? 别想了,没用的。
## Convolutional pose machine
Regression 不行,那咱就来 classification 呗。于是我做了 Convolutional pose machine, 之间没有接触过,也是看完论文现学现卖。模型的输出是一张believe map,大小可以自定义。我设定是32x32,也尝试过64x64,但这个不是重点,误差的来源主要不在于这里。这个 believe map 需要通过 softmax 来生成。我一开始脑子有点抽,给每一个输出像素点作 sigmoid 输出,也就是说一开始我的模型输出层是一个32x32的 sigmoid 张量。 结果就是所有的 sigmoid 都输出0,掉进了local minimum。后来一拍脑门,才想到要用 softmax, 一个函数对应 $R^{32x32}$ 的输出张量,这样才能强制模型输出0之外的数。
那么按照套路来,我又尝试了上面 deeppose 里面用的几个基模型,这里分享各个模型对应的问题:
- **4层卷积**: 我也不知道它学了些什么,输出牛头不对马嘴。不过这也是意料之中,这个模型就是拿来debug的嘛。
- **VGG16, VGG19**: 模型学到了点东西,不过预测结果跟ground true 也是离天隔丈远,第一次提交线上成绩 116%,可谓不堪入目。
- **Resnet 50**: 这是很过份的一个模型,整个 believe map 的置信度是一模一样的,模型把 1.0 平均分配到了 believe map 的每个像素点上。又掉进 local minimum 里面了,这是一个名副其实的坑,随便都能卡在里面。
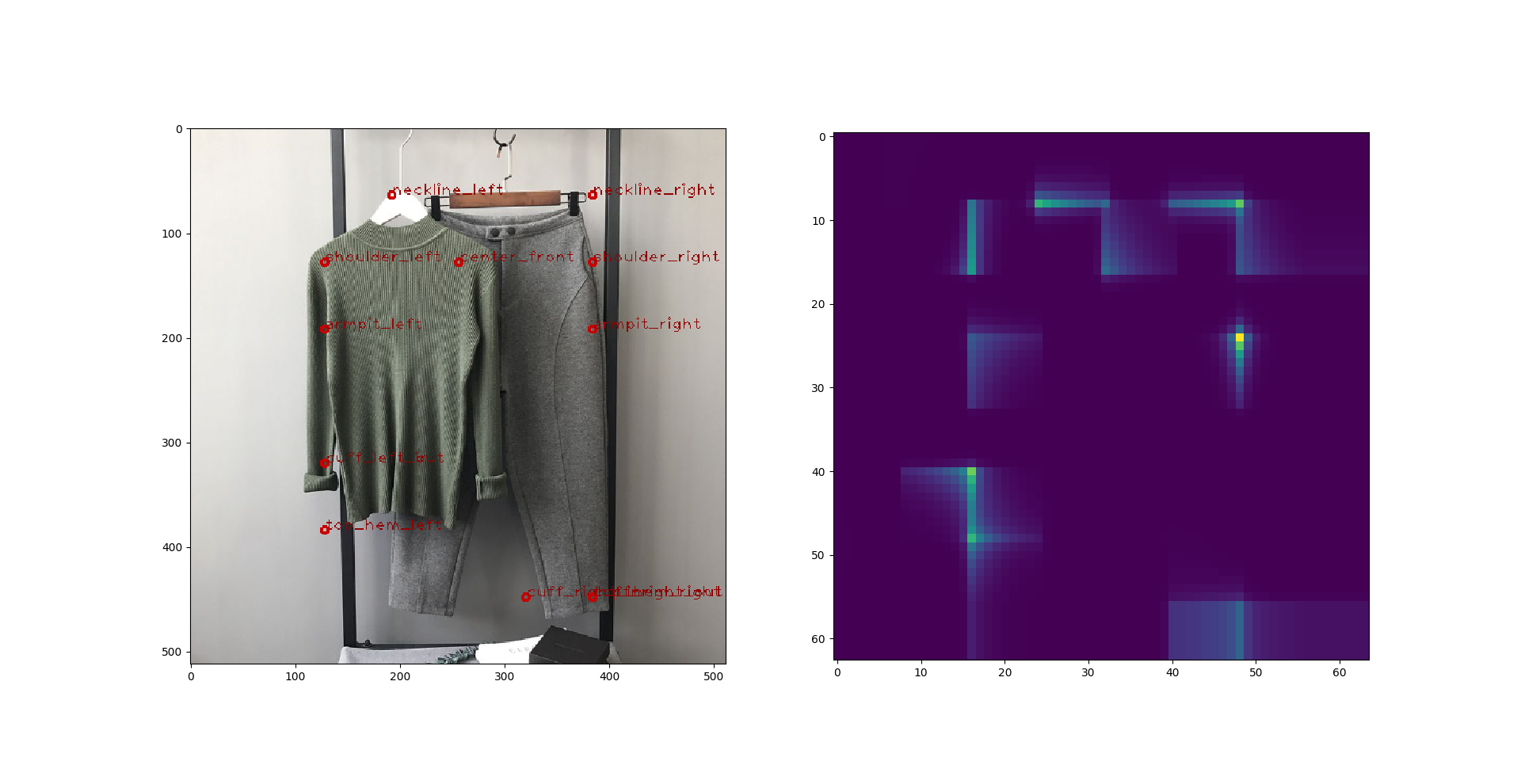
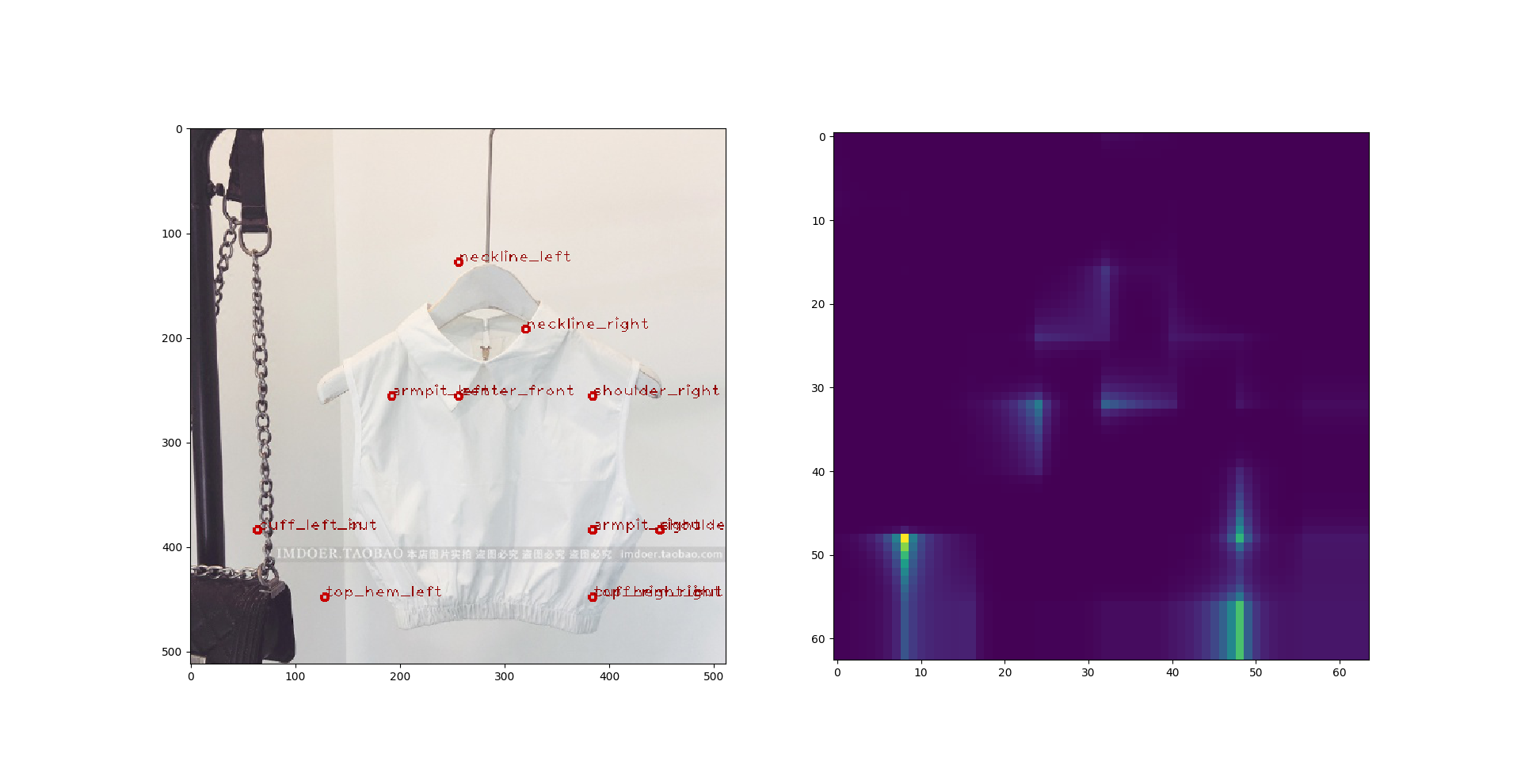
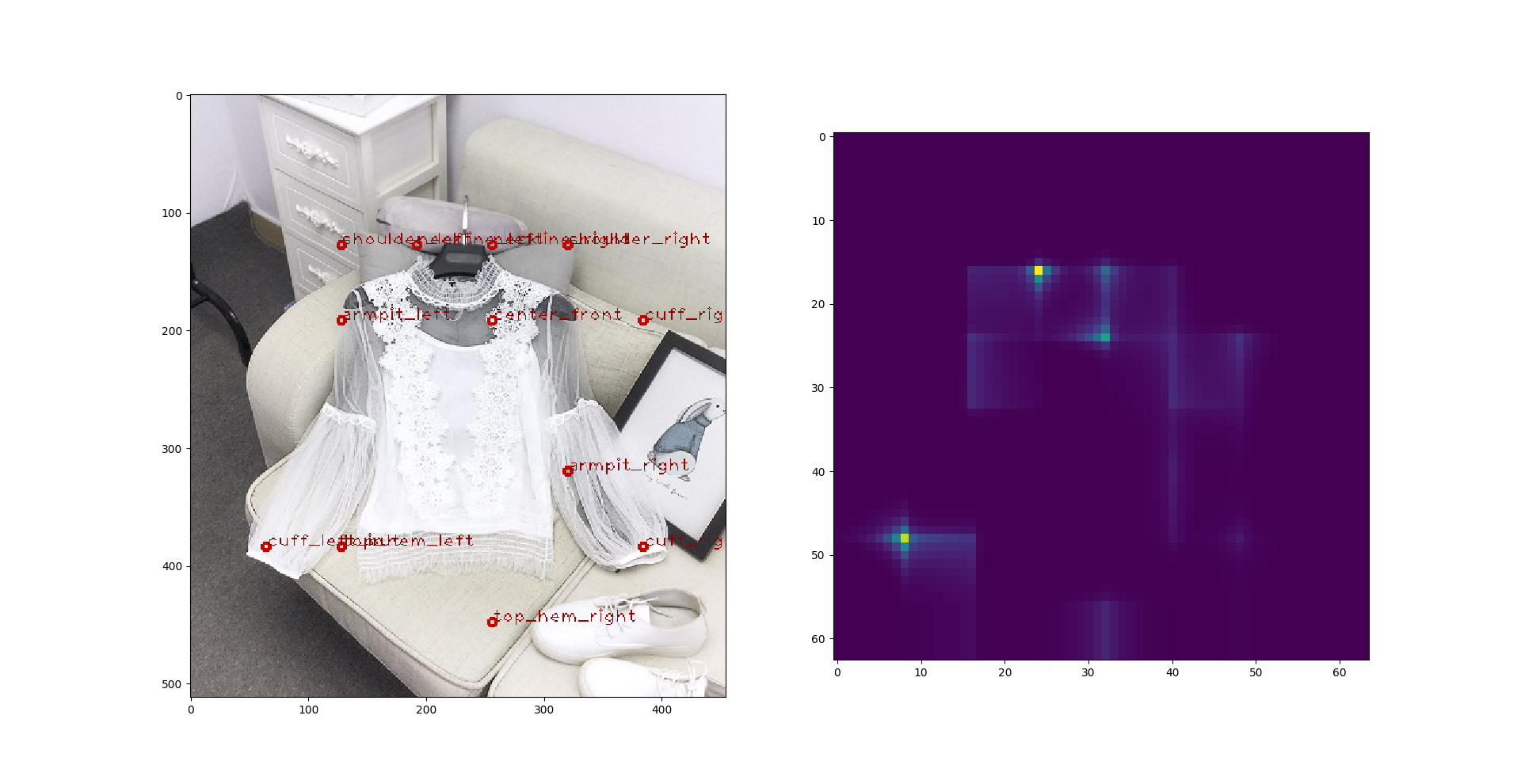
那这样子也不是个办法,于是我又尝试了 **DenseNet**。: 这回结果好了很多。我做了 DenseNet-169 和 DenseNet-201,两个效果差不多,又或者是我没有时间去调。这是上述尝试里面最好的结果了,进入复赛的同学们如果用了别的模型可以尝试一下DenseNet,下面随便找了两张预测图:
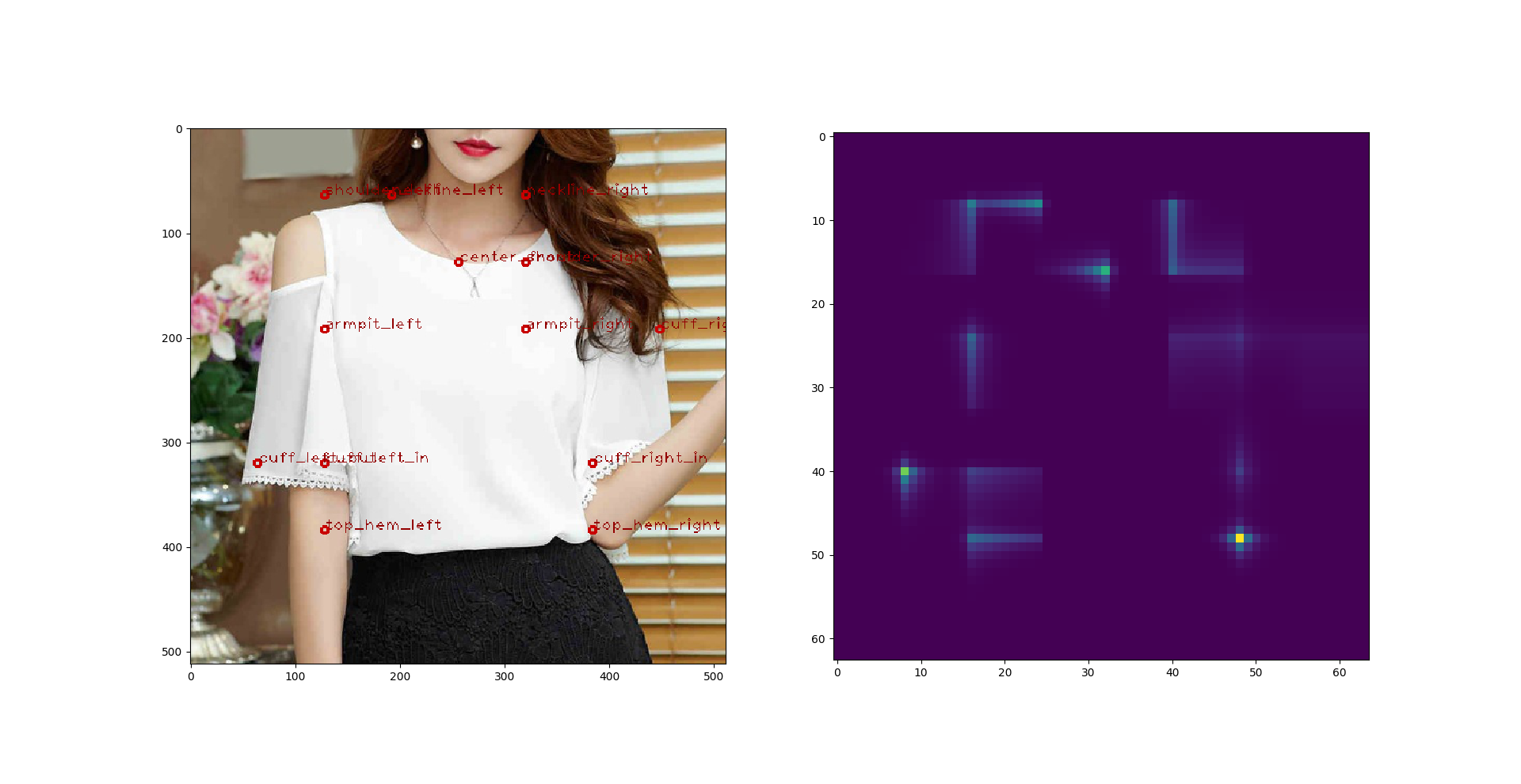
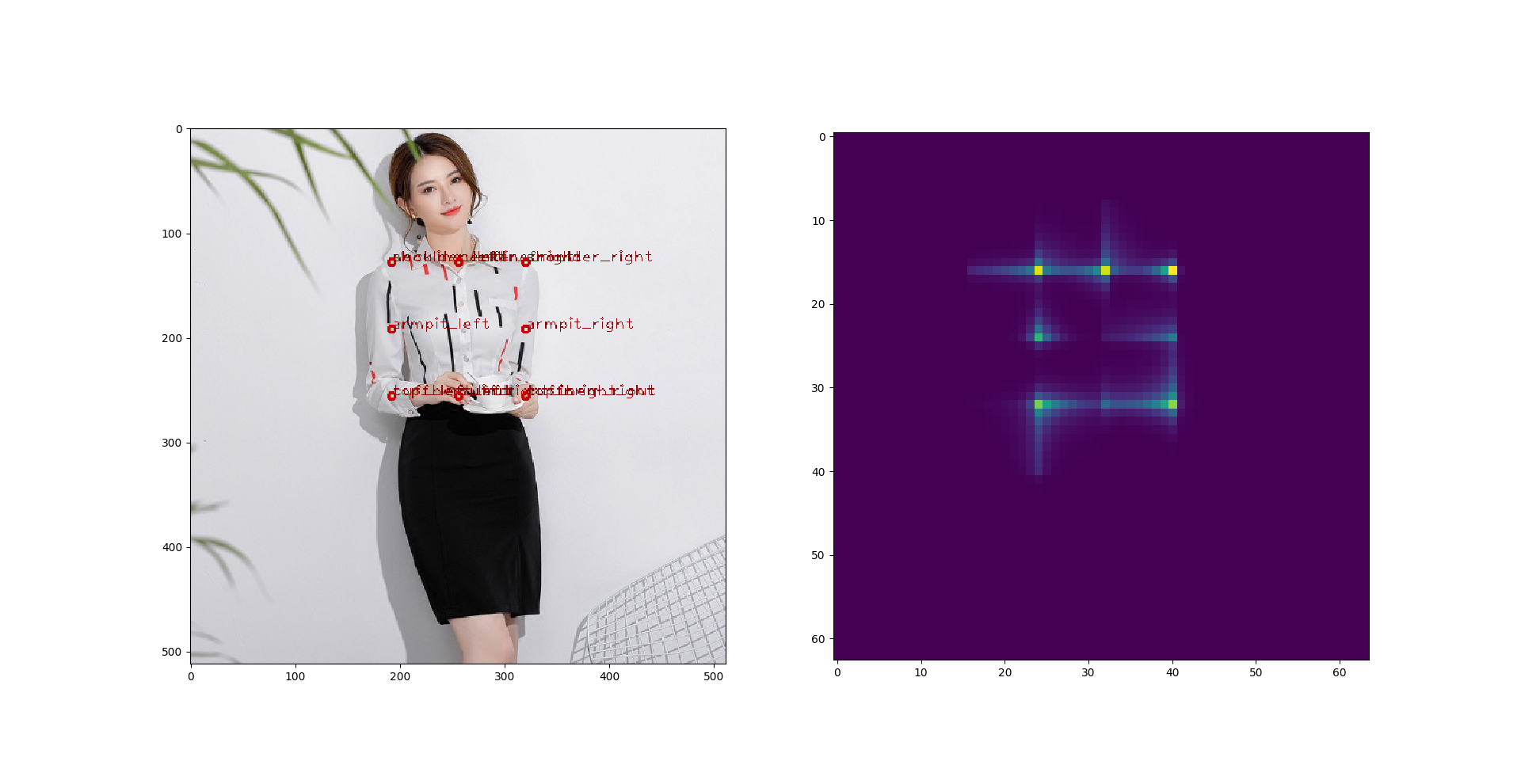
## Faster RCNN
那么上面的训练结果都不行,时间也不剩下多少了,清洗数据是不可能了。于是就考虑要不要先通过物体识别,把要打点的衣物从图片中框选出来,降低图片的复杂度,再做关键点预测,也许关键点预测的模型训练起来就会简单很多。像下面几张图,图片里面东西多了,模型的路子也就开始野了:
于是我又尝试了通过 faster rcnn 做 object localization,希望把每张图片里面的衣服抽出来。这里我实在没时间打代码了,毕竟用Python写出来的bug不是那么好应付的。于是我用了[keras-retinanet](https://github.com/delftrobotics/keras-retinanet)。在这里感谢一下。可能是我没有充足的时间去训练了,localization的结果其实不算差,只是对关键点识别的影响不好。这里举几个问题例子,我暂时称关键点预测的模型为 **预测模型** ,以便跟 rcnn 区分:
大致流程:
[Images] -> Faster RCNN -> [Cropped Images] -> Convolutional Pose Machine -> [Key-points]
- 框选出来的图片可能会把某个关键点扔到框框外面。
- 如果框选的不好,那还不如用原图。因为框选的不好关键点会丢失,一个丢失的关键点会让你的预测模型错误预测其它所有的关键点。
- 抽取出来的图片精度不够,例如我可能希望它抽取上衣,它很可能把裙子也弄进来了,等于没抽取。
- 增加了复杂度。这样子训练就是两个阶段了。对于训练预测模型,你先要通过标准答案里面的关键点对训练样本进行物体抽取,然后再拿抽取结果凑成样本集训练预测模型。而在inference阶段,你要先通过 rcnn 对测试样本进行抽取再进行预测。注意,这两种抽取的结果是不会一样的, 一个通过标准答案里面的 key-points, 另外一个通过 rcnn, 除非你的 rcnn 能训练到100的准确率。也就是说,你的预测模型在训练阶段和预测阶段面对的两个数据集并非独立同分布,起码不可能做到同分布。

关键点丢失
# 数据预处理和清洗
我做了以下的数据预处理:
- Standardization
- 旋转
- 跳跃 (移动)
- 放大缩小
- 高斯模糊
- 高斯噪点
- 改变对比度
- 增加训练错误样本的采样率
在过程中有一些小细节:
凡是有不可见点的图片都不要,训练过程中发现那些图片纯粹添堵。
要小心预处理后关键点跑到图片外面,注意添加检测或者限制。
查看更多内容,欢迎访问天池技术圈官方地址:tair性能挑战赛攻略心得-Zzzzz-CSDN博客