文章目录
- 一.什么是MySQL 读写分离
- 二.读写分离的几种实现方式(手动控制)
- 1.基于Spring下的AbstractRoutingDataSource
- 1.yml
- 2.Controller
- 3.Service实现
- 4.Mapper层
- 5.定义多数据源
- 6.继承Spring的抽象路由数据源抽象类,重写相关逻辑
- 7. 自定义注解@WR,用于指定当前操作使用哪个库
- 8. 切面逻辑
- 9.源码简单分析
- 10. 开始测试
- 2.基于Mybatis的SqlSessionFactory
- 1.yml
- 2.Controller
- 3.Service实现
- 4.Mapper层
- 5.配置类
- 1. 指定哪些Mapper接口使用读数据源:
- 2. 指定哪些Mapper接口使用写数据源
- 6. 开始测试
- 3.基于baomidou动态数据源实现读写分离(最简单)
- 1. maven依赖
- 2.yml
- 3.Controller
- 4.Service
- 5.Mapper层
- 6.开始测试
- 三.小结
一.什么是MySQL 读写分离
我记得实习的第一家公司做个一个项目就用过mysql多数据源的读写分离方案(4年前了…依稀记得也是在mapper层面来分离的),但那时候是我同事弄的,完全不懂怎么实现的,觉得他好厉害。从此成了心里的一道坎,很久之前就了解了,一直想着要写篇博客记录下,ok,那赶紧开始吧~
先了解下概念什么是读写分离、优势、实现方式、注意事项、和使用场景。如果项目里面有用到数据库集群,开始有性能方面问题,结合业务场景及综合衡量下去考虑是否适用数据库读写分离方案。
以下解释来自chatgpt,我觉得说的挺好的。
MySQL 读写分离是一种数据库优化策略,通过将数据库的读操作和写操作分开,分别交由不同的数据库实例处理,以提高系统的性能和扩展性。具体来说,读写分离通常涉及一个主数据库(Master)和一个或多个从数据库(Slave),它们通过复制机制保持数据的一致性。
以下是读写分离的核心概念:
- 主从复制(Master-Slave Replication)
- 主库(Master):负责处理所有的写操作(INSERT、UPDATE、DELETE 等),也可以处理读操作。
- 从库(Slave):主要用于处理读操作(SELECT),不会直接接收写操作。从库通过复制机制从主库同步数据,确保数据一致性。
- 读写分离的优势
- 提高读性能:由于从库处理读操作,可以通过增加从库实例来扩展系统的读性能,减轻主库的负担。
减少主库压力:写操作集中在主库,从库处理大部分的读操作,主库的压力减少,有助于提高写操作的响应速度。
容错性:在某些情况下,从库可以用作备份,如果主库出现故障,可以临时将从库提升为主库以保持服务的可用性。
- 实现方式
读写分离可以通过多种方式实现,包括:
- 手动分离:应用程序通过逻辑代码,手动决定读请求发送到从库,写请求发送到主库。
- 代理层(中间件):使用数据库中间件(如 MySQL Proxy、MaxScale、MyCat等),在应用和数据库之间自动实现读写分离和负载均衡。
- 连接池支持:某些数据库连接池(如 Druid、HikariCP)可以自动支持主从库的读写分离。
- 注意事项
- 数据一致性问题:由于复制存在延迟,从库上的数据可能会比主库滞后。如果应用程序对实时数据一致性要求较高,需谨慎处理。
- 负载均衡:要合理分配读请求到不同的从库,避免单个从库成为瓶颈。
- 主库故障恢复:需要设计可靠的故障转移机制,确保主库出现问题时,从库能够及时接管。
- 使用场景
读写分离适用于读操作远多于写操作的场景,例如电商平台、社交媒体网站等。在这些场景中,读请求往往占大多数,通过读写分离可以有效提升系统的扩展性和性能。
二.读写分离的几种实现方式(手动控制)
这里只介绍手动分离读写库:应用程序通过逻辑代码,手动决定读请求发送到从库,写请求发送到主库的几种实现方式。
1.基于Spring下的AbstractRoutingDataSource
根据大家平常开发习惯,我还是从controller层开始吧。
1.yml
我的yml配置如下:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedatasource1:url: jdbc:mysql://127.0.0.1:3306/tl_mall_master?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverdatasource2:url: jdbc:mysql://127.0.0.1:3306/tl_mall_slave?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver
2.Controller
@RestController
@RequestMapping("friend")
@Slf4j
public class FriendController {@Autowiredprivate FriendService friendService;@GetMapping(value = "select")public List<Friend> select(){return friendService.list();}@GetMapping(value = "insert")public String in(){Friend friend = new Friend();friend.setName("jinbiao666");friendService.save(friend);return "主库插入成功";}
}
3.Service实现
@Service
public class FriendImplService implements FriendService {@AutowiredFriendMapper friendMapper;@Override@WR("R") // 库2public List<Friend> list() {return friendMapper.list();}@Override@WR("W") // 库1public void save(Friend friend) {friendMapper.save(friend);}
}
4.Mapper层
public interface FriendMapper {@Select("SELECT * FROM friend")List<Friend> list();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void save(Friend friend);
}
5.定义多数据源
@Configuration
public class DataSourceConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource1")public DataSource dataSource1() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource2")public DataSource dataSource2() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}
}
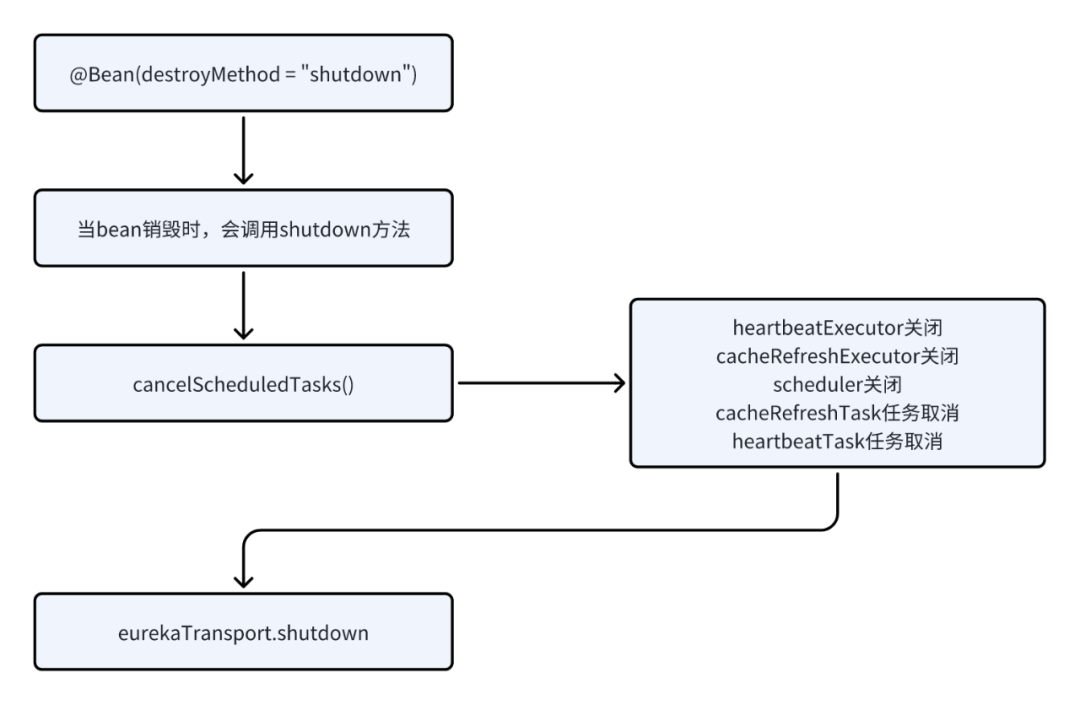
6.继承Spring的抽象路由数据源抽象类,重写相关逻辑
- 继承 org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource抽象类。
- 重写determineCurrentLookupKey方法,设置当前db操作应使用的数据源key
- 重写afterPropertiesSet方法,设置多数据源和默认数据源。
@Component
@Primary
public class DynamicDataSource extends AbstractRoutingDataSource {/*** 通过ThreadLocal设置当前线程所使用的数据源key*/public static ThreadLocal<String> name = new ThreadLocal<>();// 写@AutowiredDataSource dataSource1;// 读@AutowiredDataSource dataSource2;// 返回当前数据源标识,根据返回的key决定最终使用的数据源@Overrideprotected Object determineCurrentLookupKey() {return name.get();}/*** InitializingBean 是 Spring 框架中的一个接口,用于在 Bean 初始化完成后执行特定的操作。它定义了一个方法 afterPropertiesSet(),当 Bean 的属性设置完成后会被调用。* Spring 容器会在实例化该 Bean 并设置完属性后,自动调用 afterPropertiesSet() 方法来执行一些初始化操作*/@Overridepublic void afterPropertiesSet() {// 为targetDataSources初始化所有数据源Map<Object, Object> targetDataSources=new HashMap<>();targetDataSources.put("W",dataSource1);targetDataSources.put("R",dataSource2);super.setTargetDataSources(targetDataSources);// 为defaultTargetDataSource 设置默认的数据源super.setDefaultTargetDataSource(dataSource1);super.afterPropertiesSet();}
}
7. 自定义注解@WR,用于指定当前操作使用哪个库
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface WR {String value() default "W";
}
8. 切面逻辑
@Component
@Aspect
public class DynamicDataSourceAspect implements Ordered {// 前置@Before("within(com.tuling.dynamic.datasource.service.impl.*) && @annotation(wr)")public void before(JoinPoint point, WR wr){// 设置数据源key为注解值(determineCurrentLookupKey()方法里面会去取这个key)DynamicDataSource.name.set(wr.value());}@Overridepublic int getOrder() {return 0;}
}
9.源码简单分析
简单看下AbstractRoutingDataSource里面的determineTargetDataSource决定目标数据源方法。

10. 开始测试
-
给master写库的friend表清空,写入写库

-
写库写入成功

-
给slave读库的friend表插入一条数据rise,仅查询到读库的内容,成功实现读写分离。

2.基于Mybatis的SqlSessionFactory
一样还是从yml开始吧,目录结果清晰些。
1.yml
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedatasource1:url: jdbc:mysql://127.0.0.1:3306/tl_mall_master?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverdatasource2:url: jdbc:mysql://127.0.0.1:3306/tl_mall_slave?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver
server:port: 8080
2.Controller
@RestController
@RequestMapping("friend")
@Slf4j
public class FriendController {@Autowiredprivate FriendService friendService;@GetMapping(value = "select")public List<Friend> select(){return friendService.select();}@GetMapping(value = "insert")public void insert(){Friend friend = new Friend();friend.setName("jinbiao666");friendService.insert(friend);}
}
3.Service实现
/**** 读数据源配置:* 1. 指定扫描的mapper接口包(从库)* 2. 指定使用sqlSessionFactory是哪个(从库)*/
@Service
public class FriendImplService implements FriendService {@Autowiredprivate RFriendMapper rFriendMapper;@Autowiredprivate WFriendMapper wFriendMapper;// 读-- 读库@Overridepublic List<Friend> select() {return rFriendMapper.select();}// 保存-- 写库@Overridepublic void insert(Friend friend) {wFriendMapper.insert(friend);}}
4.Mapper层
在mapper层做的读写区分。
public interface RFriendMapper {@Select("SELECT * FROM friend")List<Friend> select();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void save(Friend friend);
}
public interface WFriendMapper {@Select("SELECT * FROM friend")List<Friend> list();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void insert(Friend friend);
}
5.配置类
1. 指定哪些Mapper接口使用读数据源:
- 通过@MapperScan注解扫对应的mapper接口,然后设置数据源为从数据源构造一个SqlSessionFactory 对象。
- 事务管理器用作事务回滚,暂不测试事务回滚了,都是可成功的.
/**** 写数据源配置:* 1. 指定扫描的mapper接口包(主库)* 2. 指定使用sqlSessionFactory是哪个(主库)*/
@Configuration
@MapperScan(basePackages = "com.tuling.datasource.dynamic.mybatis.mapper.r", sqlSessionFactoryRef="rSqlSessionFactory")
public class RMyBatisConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource2")public DataSource dataSource2() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}@Bean@Primarypublic SqlSessionFactory rSqlSessionFactory() throws Exception {final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();// 指定主库sessionFactory.setDataSource(dataSource2());// 指定主库对应的mapper.xml文件/*sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/r/*.xml"));*/return sessionFactory.getObject();}@Beanpublic DataSourceTransactionManager rTransactionManager(){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource2());return dataSourceTransactionManager;}@Beanpublic TransactionTemplate rTransactionTemplate(){return new TransactionTemplate(rTransactionManager());}
}
2. 指定哪些Mapper接口使用写数据源
@Configuration
@MapperScan(basePackages = "com.tuling.datasource.dynamic.mybatis.mapper.w", sqlSessionFactoryRef="wSqlSessionFactory")
public class WMyBatisConfig {@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource1")public DataSource dataSource1() {// 底层会自动拿到spring.datasource中的配置, 创建一个DruidDataSourcereturn DruidDataSourceBuilder.create().build();}@Bean@Primarypublic SqlSessionFactory wSqlSessionFactory() throws Exception {final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();// 指定主库sessionFactory.setDataSource(dataSource1());// 指定主库对应的mapper.xml文件/*sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/order/*.xml"));*/return sessionFactory.getObject();}@Bean@Primarypublic DataSourceTransactionManager wTransactionManager(){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource1());return dataSourceTransactionManager;}@Beanpublic TransactionTemplate wTransactionTemplate(){return new TransactionTemplate(wTransactionManager());}
}
6. 开始测试
1.写写库,成功,之前只有1条现在2条。ok,基于Mybatis在mapper层面的读写分离也成功了

2.读读库

其他场景比如写库失败回滚都是可以的,因为我们给DataSourceTransactionManager注入了写库的数据源。这里不展示了。
3.基于baomidou动态数据源实现读写分离(最简单)
1. maven依赖
<dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.5.0</version></dependency>
2.yml
一主两从
spring:datasource:dynamic:#设置默认的数据源或者数据源组,默认值即为masterprimary: master#严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源strict: falsedatasource:master:url: jdbc:mysql://127.0.0.1:3306/tl_mall_master?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverslave_1:url: jdbc:mysql://127.0.0.1:3306/tl_mall_slave?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverslave_2:url: jdbc:mysql://127.0.0.1:3306/tl_mall_user?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123456initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver
server:port: 8080
3.Controller
@RestController
@RequestMapping("frend")
@Slf4j
public class FriendController {@Autowiredprivate FriendService friendService;@GetMapping(value = "select")public List<Friend> select(){return friendService.select();}@GetMapping(value = "insert")public void insert(){Friend friend = new Friend();friend.setName("jinbiao666");friendService.insert(friend);}
}
4.Service
@Service
public class FriendImplService implements FriendService {@AutowiredFriendMapper friendMapper;@Override@DS("slave2") // 从库2public List<Friend> select() {return friendMapper.select();}@Override@DS("master") // 主库//@DS("#session.userID") 基于session里面的用户id取数据源,sass化,数据源动态根据用户选择。@DSTransactional //开启事务操作public void insert(Friend friend) {friendMapper.insert(friend);}
}
5.Mapper层
public interface FriendMapper {@Select("SELECT * FROM friend")List<Friend> select();@Insert("INSERT INTO friend(`name`) VALUES (#{name})")void insert(Friend friend);
}
6.开始测试
使用是不是超级简单,省去了很多自己注入的步骤,如使用@DS注解选择数据源、@DSTransactional注解回滚对应的数据源事务等等都由baomidou帮我们实现了。
- 写写库,成功,之前只有2条现在3条。ok,基于baomidou动态数据源实现读写分离也成功了

- 读slave_2(tl_mall_user),可以看到数据库3条数据:

接口测试:查询从库slave_2,没问题, 事务回滚暂不在这里做测试了,替大家测过了的,没问题~

三.小结
- 经过上面3种方式介绍,多数据源读写分离是不是很简单。
- 不过上面都是对单数据源写入操作的,可以使用@Transactional或者@DSTransactional帮我们回滚单数据源的事务。
- 如果涉及到多数据源的写入需要统一提交回滚怎么实现呢?小伙伴们不妨也思考一下这个问题,这其实就是相当于是分布式事务的回滚了。