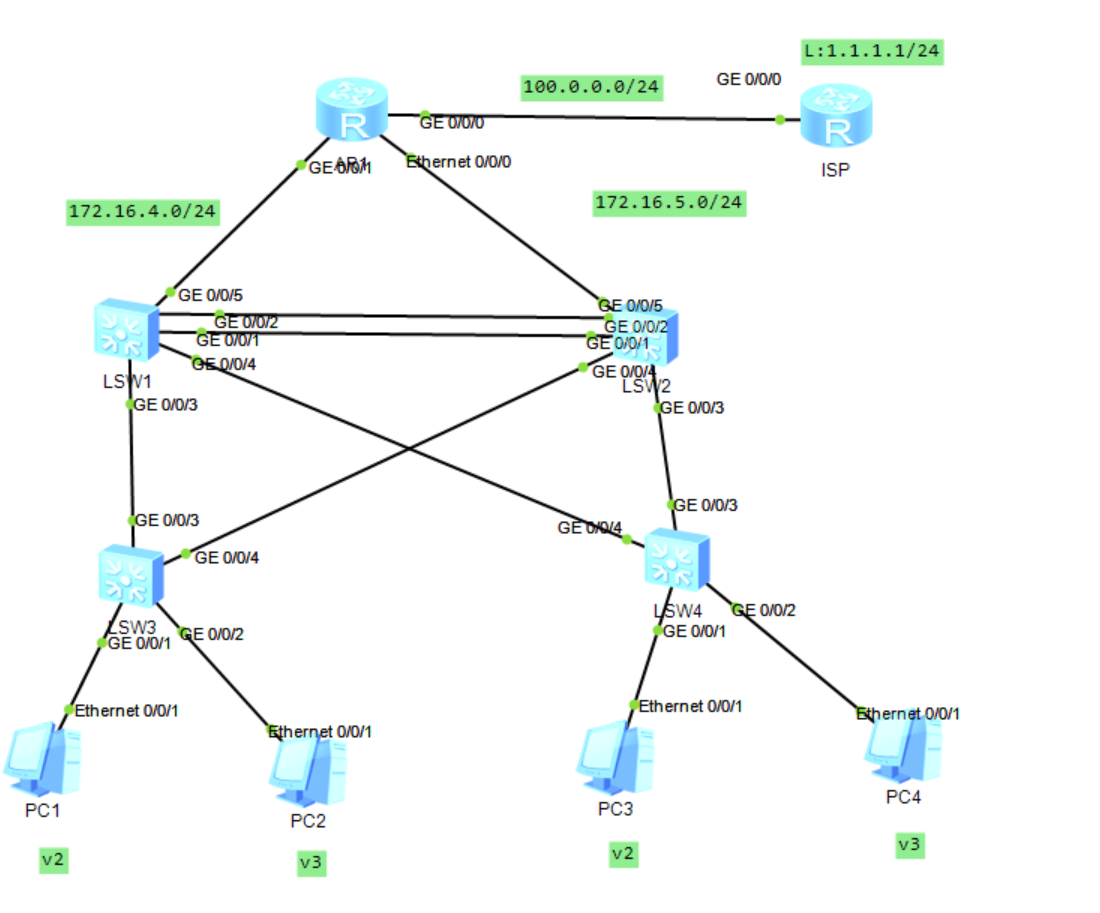
一、实验拓扑
二、实验要求
内网IP地址使用172.16.0.0/16分配。
SW1和SW2之间互为备份。
VRRP/STP/VLAN/Eth-trunk均使用。
所有PC通过DHCP获取IP地址。
ISP只能配置IP地址。
所有电脑可以正常访问ISP路由器。
三、实验步骤
基于172.16.0.0/16进行划分
172.16.2.0/24:VLAN 2
172.16.3.0/24:VLAN 3
172.16.4.0/24:R1和SW1
172.16.5.0/24:R1和SW2
100.0.0.0/24:公网地址,R1和ISP
1.配置聚合链路和vlan



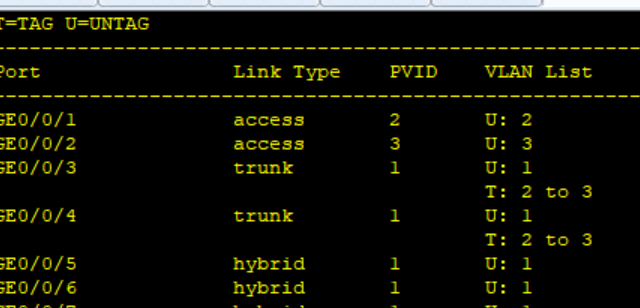
2.配置MSTP
[sw3]stp region-configuration
[sw3-mst-region]region-name aa
[sw3-mst-region]revision-level 1
[sw3-mst-region]instance 2 vlan 2
[sw3-mst-region]instance 3 vlan 3
[sw3-mst-region]active region-configuration[sw3-GigabitEthernet0/0/1]stp edged-port enable
[sw3-GigabitEthernet0/0/1]stp bpdu-filter enable
[sw3-GigabitEthernet0/0/2]stp edged-port enable
[sw3-GigabitEthernet0/0/2]stp bpdu-filter enable
sw4同上配置
[sw1]stp region-configuration
[sw1-mst-region]region-name aa
[sw1-mst-region]revision-level 1
[sw1-mst-region]instance 2 vlan 2
[sw1-mst-region]instance 3 vlan 3
[sw1-mst-region]active region-configuration
[sw1]stp instance 2 root primary
[sw1]stp instance 3 root secondary
sw2同sw1
配置结果


配置虚拟网关vlanif与链路vlanif:
# SW1上:
[sw1]int Vlanif 2
[sw1-Vlanif2]ip add 172.16.2.1 24
[sw1-Vlanif2]int vlanif 3
[sw1-Vlanif3]ip add 172.16.3.1 24
# SW2上:
[sw2]int Vlanif 2
[sw2-Vlanif2]ip add 172.16.2.2 24
[sw2-Vlanif2]int vlanif 3
[sw2-Vlanif3]ip add 172.16.3.2 24
# SW1上:
[sw1]vlan 4
[sw1-vlan4]int vlanif 4
[sw1-Vlanif4]ip add 172.16.4.1 24
[sw1-Vlanif4]int g0/0/5
[sw1-GigabitEthernet0/0/5]port link-type access
[sw1-GigabitEthernet0/0/5]port default vlan 4
[sw1]ip route-static 0.0.0.0 0 172.16.4.2 //配置缺省指向R1
# SW2上:
[sw2]vlan 5
[sw2-vlan5]int vlanif 5
[sw2-Vlanif5]ip add 172.16.5.1 24
[sw2-Vlanif5]int g0/0/5
[sw2-GigabitEthernet0/0/5]port link-type access
[sw2-GigabitEthernet0/0/5]port default vlan 5
[sw2]ip route-static 0.0.0.0 0 172.16.5.2


配置VRRP
# SW1上:
[sw1-Vlanif2]vrrp vrid 2 virtual-ip 172.16.2.3
[sw1-Vlanif2]vrrp vrid 2 priority 110
[sw1-Vlanif2]vrrp vrid 2 track interface Vlanif 4 reduced 20
[sw1-Vlanif2]vrrp vrid 2 preempt-mode timer delay 20
[sw1-Vlanif3]vrrp vrid 3 virtual-ip 172.16.3.3
# SW2上:
[sw2-Vlanif2]vrrp vrid 2 virtual-ip 172.16.2.3
[sw2-Vlanif3]vrrp vrid 3 virtual-ip 172.16.3.3
[sw2-Vlanif3]vrrp vrid 3 priority 110
[sw2-Vlanif3]vrrp vrid 3 track interface Vlanif 5 reduced 20
[sw2-Vlanif3]vrrp vrid 3 preempt-mode timer delay 20


在R1配置DHCP:开启服务 添加地址池 在接口分发
[r1]ip route-static 172.16.2.0 24 172.16.4.1
[r1]ip route-static 172.16.3.0 24 172.16.4.1
[r1]ip route-static 172.16.2.0 24 172.16.5.1
[r1]ip route-static 172.16.3.0 24 172.16.5.1
配置静态路由后要在sw1、sw2开启DHCP中继
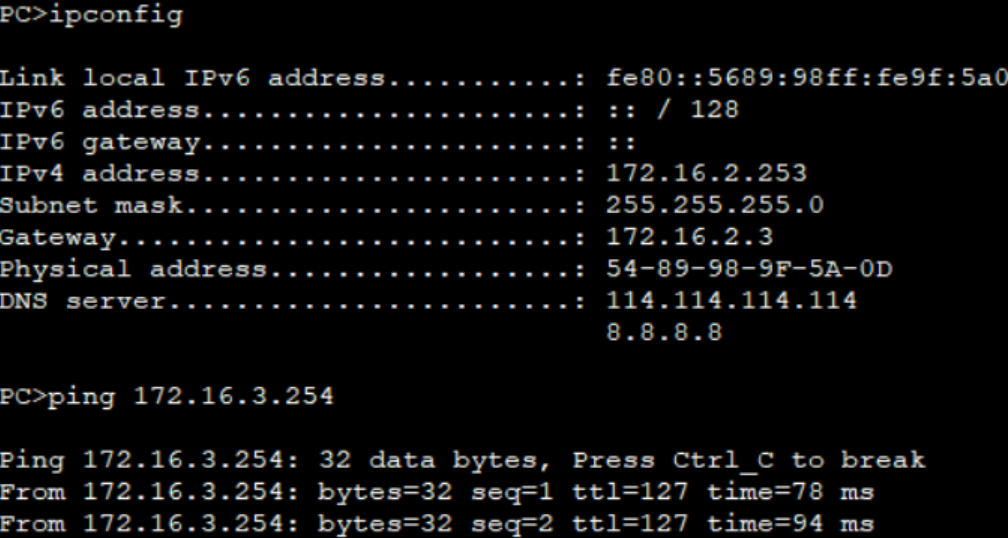
随后查看pc1 和pc3IP


配置公网IP 在ISP配置环回接口 在R1是设置acl通过easy-ip的方式实现公私分离
[r1]int g0/0/0
[r1-GigabitEthernet0/0/0]ip add 100.0.0.1 24
[r1]ip route-static 0.0.0.0 0 100.0.0.2
# ISP上:
[ISP]int g0/0/0
[ISP-GigabitEthernet0/0/0]ip add 100.0.0.2 24
[ISP-GigabitEthernet0/0/0]int l0
[ISP-LoopBack0]ip add 1.1.1.1 24
[r1]acl 2000
[r1-acl-basic-2000]rule permit source 172.16.2.0 0.0.0.255
[r1-acl-basic-2000]rule permit source 172.16.3.0 0.0.0.255
[r1-acl-basic-2000]rule permit source 172.16.4.0 0.0.0.255
[r1-acl-basic-2000]rule permit source 172.16.5.0 0.0.0.255
[r1-acl-basic-2000]int g0/0/0
[r1-GigabitEthernet0/0/0]nat outbound 2000
测试
PC1

pc2

pc3

pc4

pc2 ping pc4




![【数据结构】[特殊字符] 并查集优化全解:从链式退化到近O(1)的性能飞跃 | 路径压缩与合并策略深度实战](https://i-blog.csdnimg.cn/direct/81f95b97a06c4f66be7895afedcb590d.jpeg#pic_center)
![[python]基于yolov12实现热力图可视化支持图像视频和摄像头检测](https://i-blog.csdnimg.cn/direct/44dc4c20e5dd47d6b961f2a74c040389.png#pic_center)











