css属性列举


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/43259.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

python实现股票数据可视化
最近在做一个涉及到股票数据清洗及预测的项目,项目中需要用到可视化股票数据这一功能,这里我与大家分享一下股票数据可视化的一些基本方法。
股票数据获取
在经过多次尝试后,发现了一个

从 JDK 11 到 JDK 17:OpenRewrite 实战 Spring Boot 升级指南
一、为什么选择 OpenRewrite 升级?
在 Spring Boot 项目升级 JDK 的过程中,我们面临两个核心痛点:
语法兼容性问题(如废弃的 API、新的关键字)依赖版本冲突(特别是 Spring Boot 与 JDK 版本的匹配&#x…
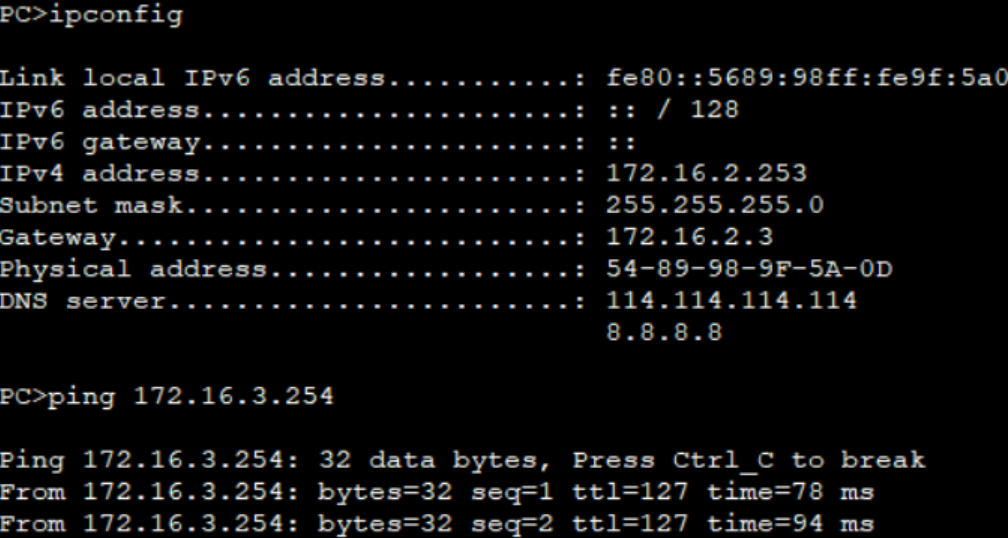
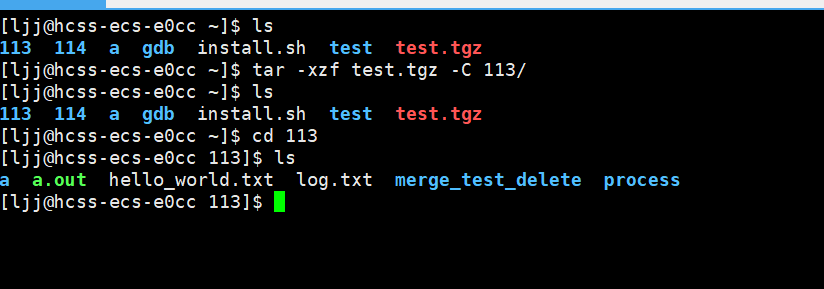
【Linux】了解基础指令(超详细)
目录 【whoami】指令【pwd】指令【mkdir】指令【touch】指令【ls】指令文件的扩展内容 【cd】指令相对路径和绝对路径(.和..存在的原因)绝对路径相对路径 【rm】指令【man】命令【less】指令echo指令重定向操作追加重定向 cat 指令输入重定向 管道操作(组合指令)查找三剑客find…

基于改进粒子群算法的多目标分布式电源选址定容规划(附带Matlab代码)
通过分析分布式电源对配电网的影响,以有功功率损耗、电压质量及分布式电源总容量为优化目标,基于模糊理论建立了分布式电源在配电网中选址定容的多目标优化模型,并提出了一种改进粒子群算法进行求解。在算例仿真中,基于IEEE-14标准…


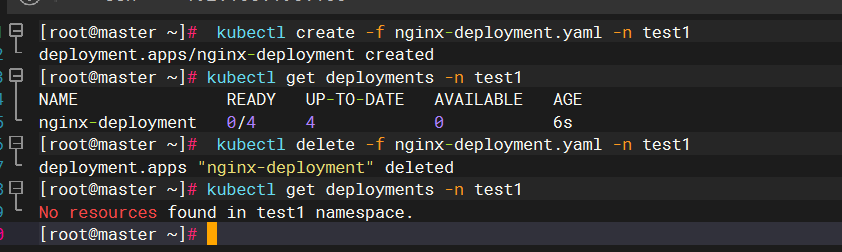
Kubernetes对象基础操作
基础操作 文章目录 基础操作一、创建Kubernetes对象1.使用指令式命令创建Deployment2.使用指令式对象配置创建Deployment3.使用声明式对象配置创建Deployment 二、操作对象的标签1.为对象添加标签2.修改对象的标签3.删除对象标签4.操作具有指定标签的对象 三、操作名称空间四、…

命悬生死线:当游戏遭遇DDoS围剿,如何用AI破局?
文章作者:腾讯宙斯盾DDoS防护团队 一、血色战场:DDoS攻击游戏产业的致命瞬间 全球黑色星期五 这是一场波及全球的“黑色星期五”,起初无人察觉,包括小林。 他刚下班到家就迫不及待打开电脑,准备体验期待已久的《黑神话…
![【数据结构】[特殊字符] 并查集优化全解:从链式退化到近O(1)的性能飞跃 | 路径压缩与合并策略深度实战](https://i-blog.csdnimg.cn/direct/81f95b97a06c4f66be7895afedcb590d.jpeg#pic_center)
【数据结构】[特殊字符] 并查集优化全解:从链式退化到近O(1)的性能飞跃 | 路径压缩与合并策略深度实战
并查集的优化 导读一、合并优化1.1 基本原理1.2 按大小合并1.3 按秩合并1.4 两种合并的区别**1.4.1 核心目标****1.4.2 数据存储****1.4.3 合并逻辑****1.4.4 树高控制****1.4.5 适用场景****1.4.6 路径压缩兼容性****1.4.7 极端案例对比****1.4.8 小结**二、查找优化2.1 路径压…
![[python]基于yolov12实现热力图可视化支持图像视频和摄像头检测](https://i-blog.csdnimg.cn/direct/44dc4c20e5dd47d6b961f2a74c040389.png#pic_center)
[python]基于yolov12实现热力图可视化支持图像视频和摄像头检测
YOLOv12 Grad-CAM 可视化工具
本工具基于YOLOv12模型,结合Grad-CAM技术实现目标检测的可视化分析,支持图像、视频和实时摄像头处理。
注意
该项目使用的是yolov12-1.0模型进行测试通过,不是使用turbo模型,且由于yolov12-1.0由于…

进程Kill杀死后GPU显存没有释放仍然被占用,怎么杀死僵尸进程
参考链接:
https://blog.csdn.net/qq_37591986/article/details/131118109
使用下面的命令:
fuser -v /dev/nvidia0 | awk {print $0} | xargs kill -9一般来说他会杀掉整个用户的所有进程。

基于飞腾/龙芯+盛科CTC7132全国产交换机解决方案
产品介绍
盛科CTC7132,内置ARM-Cortex A53 主频1.2GHz;支持24个千兆电口,24个万兆光口(850nm多模),1个千兆管理网口,1个管理串口;支持1个百兆健康管理网口:用于设备端口状态、电压、…

Tesseract OCR技术初探(Python调用)
一、Tesseract OCR技术解析
1.1 核心架构与发展历程
Tesseract是由HP实验室于1985年研发的光学字符识别引擎,2005年由Google开源并持续维护至今。其核心技术经历了三个阶段演进:
传统模式(v3.x):基于特征匹配算法&a…

自动语音识别(ASR)技术详解
语音识别(Automatic Speech Recognition, ASR)是人工智能和自然语言处理领域的重要技术,旨在将人类的语音信号转换为对应的文本。近年来,深度学习的突破推动语音识别系统从实验室走入日常生活,为智能助手、实时翻译、医…

Cursor 汉化教程
# 问题
想把 cursor 改成中文
我这里是汉化过的 # 【第一种方法】安装插件 然后重启 # 【第二种方法】Ctrl Shift P 打开配置项 然后搜索输入 Configure Display Language 点一下 切换到 zh-cn 重启 cursor 即可 重启后就好了~

用 pytorch 从零开始创建大语言模型(三):编码注意力机制
从零开始创建大语言模型(Python/pytorch )(三):编码注意力机制 3 编码注意力机制3.1 建模长序列的问题3.2 使用注意力机制捕捉数据依赖关系3.3 通过自注意力关注输入的不同部分3.3.1 一个没有可训练权重的简化自注意力…

Linux之基础知识
目录
一、环境准备
1.1、常规登录
1.2、免密登录
二、Linux基本指令
2.1、ls命令
2.2、pwd命令
2.3、cd命令
2.4、touch命令
2.5、mkdir命令
2.6、rmdir和rm命令
2.7man命令
2.8、cp命令
2.9、mv命令
2.10、cat命令
2.11、echo命令
2.11.1、Ctrl r 快捷键
2…

Java学习------源码解析之StringBuilder
1. 介绍 String中还有两个常用的类,StringBuffer和StringBuilder。这两个类都是专门为频繁进行拼接字符串而准备的。最先出现的是StringBuffer,之后到jdk1.5的时候才有了StringBuilder。
2. StringBuilder解析 从这张继承结构图可以看出:
S…

数据化管理(一)---什么是数据化管理
目录 一、什么是数据化管理1.1 “聪明”的销售人员1.2 数据化管理的概念1.3 数据化管理的意义1.4 数据化管理的四个层次1.4.1 业务指导管理1.4.2 营运指导管理1.4.3 经营策略管理1.4.4 战略规划管理 1.5 数据化管理流程图1.5.1 分析需求1.5.2 收集数据1.5.3 整理数据1.5.4 分析…
推荐文章
- Python 3.11 69 个内置函数(完整版)
- .Net Core微服务入门全纪录(四)——Ocelot-API网关(上)
- .NET周刊【1月第4期 2025-01-26】
- [25] cuda 应用之 nppi 实现图像色彩调整
- [LevelDB]关于LevelDB存储架构到底怎么设计的?
- [Linux]在vim中批量注释与批量取消注释
- [Xilinx]工具篇_Vivado自动编译
- [创业之路-243]:《华为双向指挥系统》-1-组织再造-企业不同组织形式下的指挥线的种类?
- [多线程]基于阻塞队列(Blocking Queue)的生产消费者模型的实现
- [权限提升] Windows 提权 维持 — 系统错误配置提权 - Trusted Service Paths 提权
- [原创](Modern C++)现代C++的关键性概念: 流格式化
- 《Python基础教程》第16章笔记:测试基础