《Hadoop+Spark知识图谱体育赛事推荐系统》开题报告
一、研究背景及意义
随着互联网技术的迅猛发展和大数据时代的到来,体育赛事数据的数量呈爆炸式增长。用户面对海量的体育赛事信息,常常感到信息过载,难以快速找到感兴趣的赛事内容。如何高效地从海量数据中筛选出用户感兴趣的体育赛事,成为当前亟待解决的问题。传统的推荐系统由于计算量大、处理速度慢,难以应对大规模数据处理的挑战。Hadoop和Spark作为两种主流的大数据处理技术,因其高扩展性和高性能,被广泛应用于大数据处理领域。本研究旨在结合Hadoop和Spark两种技术,并引入知识图谱,构建一个高效的体育赛事推荐系统。该系统通过分析用户的兴趣和行为数据,结合多种推荐算法和知识图谱的语义关联,为用户提供个性化的体育赛事推荐服务,提高用户查找赛事的效率和满意度,同时也为赛事资源的优化配置提供有力支持。
二、研究目标
- 设计并实现一个基于Hadoop和Spark的分布式体育赛事推荐系统,该系统能够高效处理大规模赛事数据,并实时响应用户的推荐请求。
- 比较和选择最优的推荐算法,通过分析和比较多种推荐算法(如基于内容的推荐、协同过滤推荐、深度学习推荐等),找出最适合体育赛事推荐的算法或算法组合。
- 验证推荐系统的性能和准确性,通过实验验证所设计的推荐系统在推荐准确率、召回率、F1分数等指标上的表现,确保其在实际应用中的有效性和可靠性。
三、研究内容
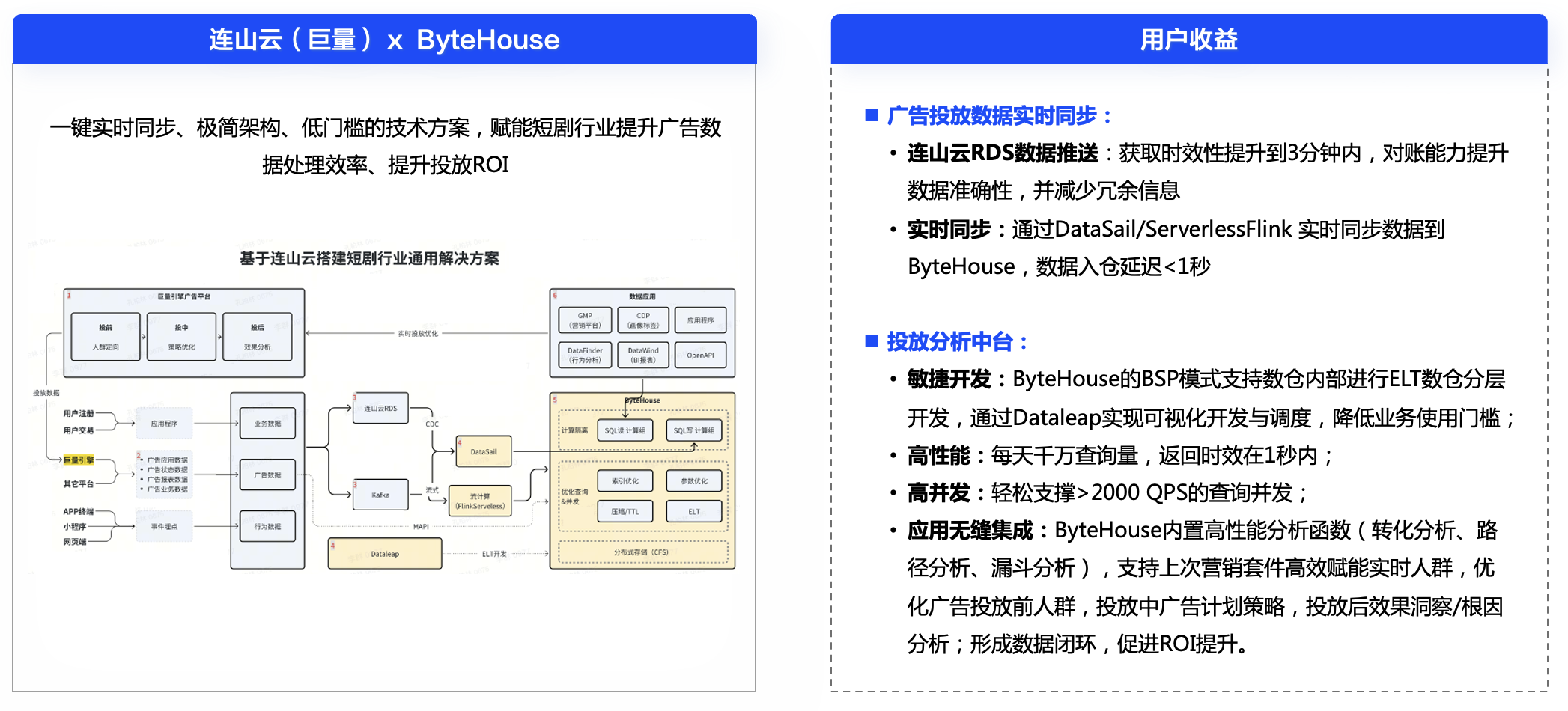
1. 系统架构设计
系统架构将包括数据预处理、数据存储、模型训练、推荐算法实现及用户交互等模块。
- 数据预处理:使用Hadoop进行数据的清洗、转换和存储。
- 数据存储:利用HDFS进行数据存储,并利用Hive进行数据仓库的建设。
- 模型训练:利用Spark进行高效的数据分析和模型训练。
- 推荐算法实现:结合基于内容的推荐、协同过滤推荐、深度学习推荐及知识图谱的语义推荐算法。
- 用户交互:设计用户友好的界面,提供赛事推荐和查询功能。
2. 关键技术实现
- 基于内容的推荐:通过分析赛事的内容特征(如球队、球员、比赛类型等)进行推荐。
- 协同过滤推荐:利用用户的历史行为数据,找到兴趣相似的用户群体进行推荐。
- 深度学习推荐:采用深度学习模型(如LSTM、CNN等)挖掘赛事数据中的潜在关系进行推荐。
- 知识图谱推荐:利用知识图谱中的语义关系,进行赛事之间的关联推荐。
3. 数据采集与处理
使用Selenium等Python爬虫工具采集体育赛事数据,存储到CSV文件或MySQL数据库中,并上传到HDFS分布式文件系统上。利用Hive进行数据仓库建模,并进行初步的数据处理和分析。
4. 实验验证与结果分析
设计实验方案,收集用户行为数据和赛事数据,进行系统测试和验证。评估系统的推荐准确率、召回率、F1分数等关键指标,确保系统性能达到预期目标。
四、研究计划
第一阶段(1-2个月):文献综述和需求分析
- 查阅相关文献,了解当前体育赛事推荐系统的研究现状和发展趋势,为系统设计提供理论基础和参考。
- 确定研究方案和技术选型,完成开题报告。
第二阶段(3-4个月):系统设计和实现
- 根据需求分析和技术选型,设计系统架构和模块划分。
- 完成代码编写和调试工作,实现系统的各个功能模块。
第三阶段(5-6个月):实验验证和结果分析
- 设计实验方案,收集用户行为数据和赛事数据。
- 进行系统测试和验证,评估系统的推荐准确率、召回率、F1分数等关键指标。
- 撰写实验报告,总结实验结果。
第四阶段(7-8个月):论文撰写和总结
- 整理研究成果,撰写毕业论文。
- 进行答辩准备,完成答辩工作。
五、预期成果和创新点
预期成果
- 设计和实现一个基于Hadoop和Spark的分布式体育赛事推荐系统,提高推荐系统的性能和用户体验。
- 通过实验验证所设计的推荐系统的性能和准确性,为后续相关研究提供参考。
- 为体育赛事机构和用户提供一种高效、实用的赛事推荐方法,提高赛事资源的利用效率和用户满意度。
创新点
- 结合Hadoop和Spark两种大数据处理技术:设计并实现一个分布式、可扩展的体育赛事推荐系统,提高系统的处理能力和响应速度。
- 引入知识图谱技术:通过语义关联提高推荐的准确性和个性化程度。
- 多种推荐算法的比较与选择:通过实验验证多种推荐算法在体育赛事推荐中的效果,选择最适合的算法或算法组合。
六、参考文献
由于篇幅限制,此处仅列出部分参考文献的示例,详细文献列表将在后续研究中进一步完善。
- 磨春妗, 黎飞, 谢燕芳, 程登, 张森. 一种泊车服务推荐系统的设计[J]. 现代工业经济和信息化, 2022年03期.
- 李方园. 基于个性化需求的图书馆书籍智能推荐系统的设计与实现研究[J]. 信息记录材料, 2020年12期.
- 孔令圆, 彭琰, 郑汀华, 马华. 面向个性化学习的慕课资源推荐系统开发[J]. 计算机时代, 2021年07期.