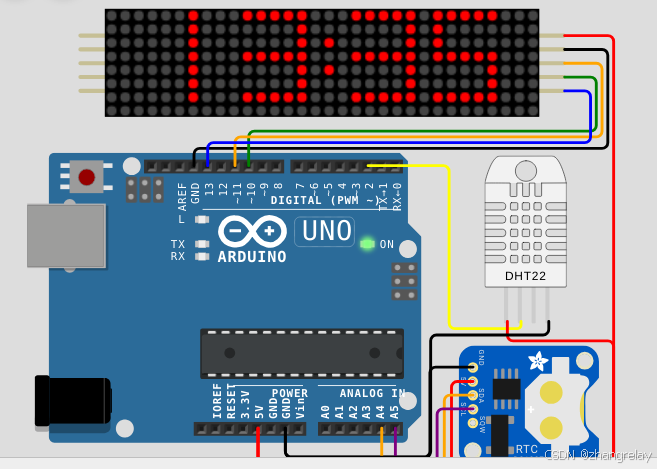
用 bert 生成句向量 用 lstm 或 bert 承接 bert 的输出,保证模型可以学习到内容的连续性。此时 lstm 输入形状为:pooled_output.unsqueeze(0)(1, num_sentence, vector_size) 词性标注 句法分析 命名实体识别 中文分词 远程监督 pip install torch-crf
from torchcrf import CRF
限制实体的类别到类别之间的转移关系模型的输出即发射矩阵 当模型足够好时,使用 crf 前后结果可能不大(几个百分点的提升)使用 crf 会多出大量的计算,如转移矩阵、篱笆墙解码的处理 CRF 核心逻辑 开始转移矩阵 结束转移矩阵 状态转移矩阵 篱笆墙解码 假设每组节点平均数量为 D,B 为 beamSize beam search 保存n 条最高概率的路径 仅计算高概率路径的转移概率 时间复杂度 n * D * B 维特比解码 保留从上一层全部节点,到当前层每个节点中,最高概率的一条路径 时间复杂度 n * D^2 暴力求解 除了暴力求解,都有可能错过最优解 发射矩阵 实体标签重叠问题 忽略较短的实体 使用 moe 思路,分别用对应类型的 label,构建和输出 fc 和 loss,最后把所有 loss 求和 用生成式模型处理 有时,可以用规则进行实体识别re.search(pattern, string)
re.match(pattern, string)
re.findall(pattern, string)
re.sub(pattern, string)
re.split(pattern, string)
输入与输出是等长的序列 对序列中的每个时间步做分类 需要对每个时间步都打上标签 本质上相当于每个节点都要做一次分类,做一次 loss