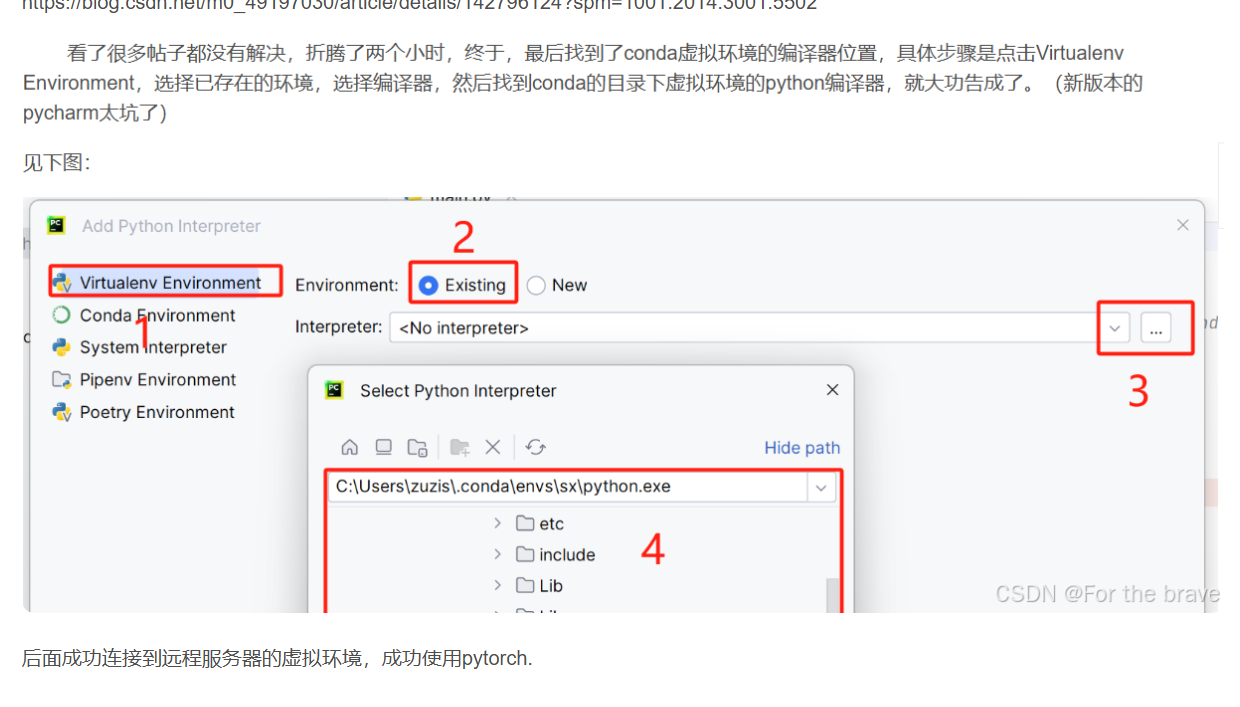
引言
============ 仅供学习研究,欢迎交流 ======================
抢票难,难于上青天!无论是演唱会、话剧还是体育赛事,大麦网的票总是秒光。作为一名技术爱好者,你是否想过用技术手段提高抢票成功率?本文将为你揭秘大麦手机端抢票的核心技术:BP、监测回流以及自动抢票脚本,手把手教你如何用技术手段轻松抢到心仪的票!

什么是BP?
BP(Bypass,绕过)是指通过技术手段绕过官方限制,直接与服务器交互,从而提高抢票效率。在大麦抢票中,BP通常用于:
绕过前端限制:跳过繁琐的前端验证,直接提交请求。
提高请求速度:通过多线程或异步请求,快速提交订单。
模拟真实用户:通过伪造请求头、Cookie等,伪装成真实用户,避免被风控拦截。
BP的核心技术
抓包分析:使用抓包工具(如Fiddler、Charles)分析大麦APP的请求流程。
模拟请求:通过Python的requests库或Node.js的axios库模拟HTTP请求。
多线程并发:利用多线程技术同时发送多个请求,提高抢票成功率。
什么是监测回流?
监测回流是指实时监控票务平台的退票、取消订单等行为,第一时间抢到这些“回流票”。回流票的来源包括:
用户退票:部分用户因各种原因退票,这些票会重新释放。
支付超时:用户未在规定时间内完成支付,订单会被取消。
系统释放:平台可能会在特定时间释放部分预留票。
监测回流的技术实现
定时轮询:通过脚本定时查询票务状态,发现回流票后立即下单。
WebSocket监听:如果平台支持WebSocket,可以实时监听票务状态变化。
异常处理:针对网络波动、请求失败等情况,设置重试机制。
如何自动进行抢票?
自动抢票的核心是编写脚本,模拟用户操作,实现从登录到下单的全流程自动化。以下是实现自动抢票的关键步骤:
环境准备
抓包工具:Fiddler、Charles等,用于分析大麦APP的请求接口。
编程语言:Python、Node.js等,用于编写抢票脚本。
代理IP:防止IP被封禁,建议使用动态代理IP。
抓包分析
登录接口:获取登录所需的参数(如token、Cookie)。
抢票接口:分析下单请求的URL、参数和请求头。
验证码处理:遇到验证码,可以使用OCR技术或第三方打码平台。
分享个人成熟且成功率高的方式
基于 Selenium 的自动化抢票脚本,支持在 Android 和 iOS 设备上运行。脚本用于在大某麦网上抢购门票并完成支付宝支付,支持日志记录和滑块验证。
- 软件安装
Termux:
在 Google Play 或 F-Droid 中搜索并安装 Termux。
Python:
在 Termux 中运行以下命令安装 Python:
bash
复制
pkg update
pkg install python
ChromeDriver:
下载与手机 Chrome 浏览器版本匹配的 ChromeDriver:ChromeDriver 下载页面。
将下载的 chromedriver 文件上传到 Termux 的 /data/data/com.termux/files/usr/bin/ 目录中。 - 文件放置
将 damai_ticket_script.py 和 config.ini 文件上传到 Termux 的主目录(~)中。
确保文件权限正确:
bash
复制
chmod +x ~/damai_ticket_script.py
config.ini文件
[DAMAI]
TICKET_URL = https://www.damai.cn/
USERNAME = your_username
PASSWORD = your_password[ALIPAY]
PHONE = your_phone_number
PASSWORD = your_alipay_password[CHROME]
DRIVER_PATH = /path/to/chromedriver
主流程的部分代码
damai_ticket_script.py
def breakpoint_before_booking(driver, booking_time):try:config = load_config()DAMAI_TICKET_URL = config.get("DAMAI", "TICKET_URL")# 提前加载抢票页面driver.get(DAMAI_TICKET_URL)WebDriverWait(driver, 10).until(EC.url_contains("damai.cn"))logging.info("Arrived at ticket booking page")# 暂停,等待抢票时间while datetime.now() < booking_time:time_left = (booking_time - datetime.now()).total_seconds()logging.info(f"Waiting for booking time. Time left: {time_left:.0f} seconds")time.sleep(1)logging.info("Booking time reached! Proceeding to book ticket.")return Trueexcept Exception as e:logging.error(f"Error during breakpoint: {e}")return False注意事项
合法合规:抢票脚本仅用于学习和技术研究,请勿用于非法用途。
道德约束:抢票成功后,请勿囤积或高价转卖,维护公平购票环境。
通过BP技术、监测回流和自动抢票脚本,你可以大幅提高抢票成功率。然而,技术只是手段,公平购票才是目的。希望本文能为你提供技术上的启发,同时也能引发对抢票现象的思考。