1 介绍
布隆过滤器(Bloom Filter)是 Redis 4.0 版本之后提供的新功能,我们一般将它当做插件加载到 Redis Service服务器中,给 Redis 提供强大的滤重功能。
它是一种概率性数据结构,可用于判断一个元素是否存在于一个集合中。相比较之 Set 集合的去重功能,布隆过滤器空间上能节省 90% +,不足之处是去重率大约在 99% 左右,那就是有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。它有如下优缺点:
-
优点:空间效率和查询时间都比一般的算法要好的多
-
缺点:有一定的误识别率和删除困难
2 应用场景说明
我们在遇到数据量大的时候,为了去重并避免大批量的重复计算,可以考虑使用 Bloom Filter 进行过滤。具体常用的经典场景如下:
-
解决大流量下缓存穿透的问题,参考笔者这篇《一次缓存雪崩的灾难复盘》。
-
过滤被屏蔽、拉黑、减少推荐的信息,一般你在浏览抖音或者百度App的时候,看到不喜欢的会设置减少推荐、屏蔽此类信息等,都可以采用这种原理设计。
-
各种名单过滤,使用布隆过滤器实现第一层的白名单或者黑名单过滤,可用于各种AB场景。
下面以缓存穿透为解决目标进行案例介绍。
3 案例分析
布隆过滤器的一个经典应用场景就是解决缓存穿透问题!
缓存穿透是指访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量井喷时会导致DB挂掉。
比如 我们查询用户的信息,程序会根据用户的编号去缓存中检索,如果找不到,再到数据库中搜索。如果你给了一个不存在的编号:XXXXXXXX,那么每次都比对不到,就透过缓存进入数据库。这样风险很大,如果因为某些原因导致大量不存在的编号被查询,甚至被恶意伪造编号进行大规模攻击,那将是灾难。
解决方案质疑就是在缓存之前在加一层 BloomFilter :
-
把存在的key记录在BloomFilter中,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在则说明数据库和缓存都没有,就直接返回,
-
存在再走查缓存 ,投入数据库去查询,这样减轻了数据库的压力。
3.1 巨量查询场景
下面以火车票订购和查询为案例进行说明,如果火车票被恶意攻击,模拟了一样结构的火车票订单编号,那很可能通过大量的请求穿透过缓存层把数据库打雪崩了,所以使用布隆过滤器为服务提供一层保障。具体的做法就是,我们在购买火车票成功的时候,把订单号的ID写入(异步或者消息队列的方式)到布隆过滤器中,保障后续的查询都在布隆过滤器中走一遍再进到缓存中去查询。
3.2 创建Bloom Filter
创建 Bloom Filter 的语法如下:
# BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
BF.RESERVE ticket_orders 0.01 1000000这边的命令是通过BF.RESERVE命令手动创建一个名字为 ticket_orders,错误率为 0.01 ,初始容量为 1000000 的布隆过滤器。这边需要注意的一些点是:
-
error_rate 越小,对碰撞的容忍度越小,需要的存储空间就越大。如果允许一定比例的不准确,对精确度要求不高的场景,error_rate 可以设的稍大一点。
-
capacity 设置的过大,会浪费存储空间,设置过小,准确度不高。所以评估的时候需要精准一点,既要避免浪费空间也要保证准确比例。
3.3 创建车票订单
# BF.ADD {key} {value ... }# 添加单个订单号
BF.ADD ticket_orders 1725681193-350000
(integer) 1# 添加多个订单号
BF.MADD ticket_orders 1725681193-350000 1725681197-270001 1725681350-510007
1) (integer) 1
2) (integer) 1
3) (integer) 1以上的语句是将已经订好的车票订单号存储到Bloom Filter中,包括一次存储单个和一次存储多个。
火车票订单同步到 Bloom Filter 的步骤如下:
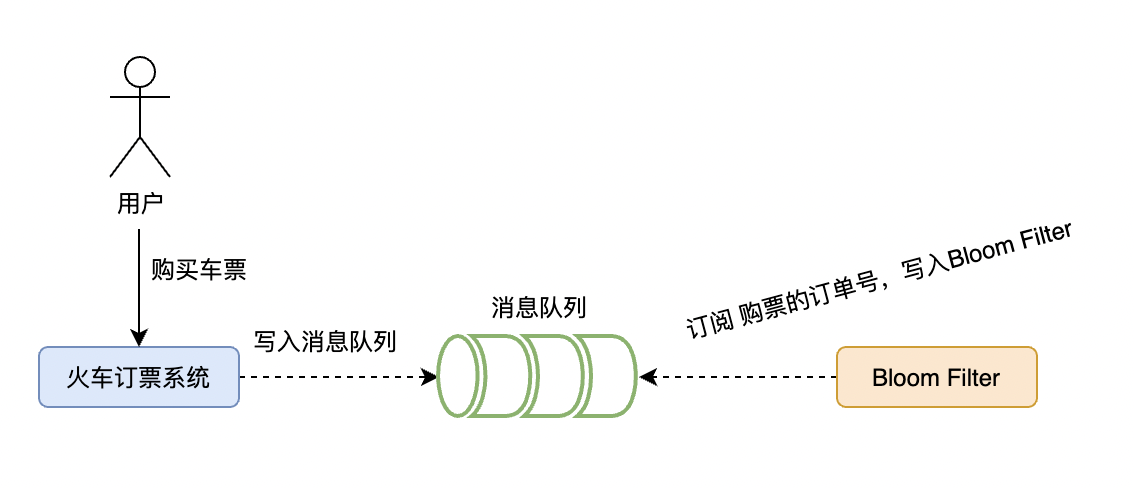
3.4 判断火车票订单Id是否存在
# BF.EXISTS {key} {value} ,存在的话返回 1,不存在返回 0
BF.EXISTS ticket_orders 1725681193-350000
(integer) 1# 批量判断多个值是否存在于布隆过滤器,语句如下:
BF.MEXISTS ticket_orders 1725681193-350000 1725681197-270001 1725681350-510007
1) (integer) 0
2) (integer) 1
3) (integer) 0BF.EXISTS 判断一个元素是否存在于 Bloom Filter中,返回值 = 1 表示存在,返回值 = 0 表示不存在。可以一次性判断单个元素,或者一次性判断多个元素。
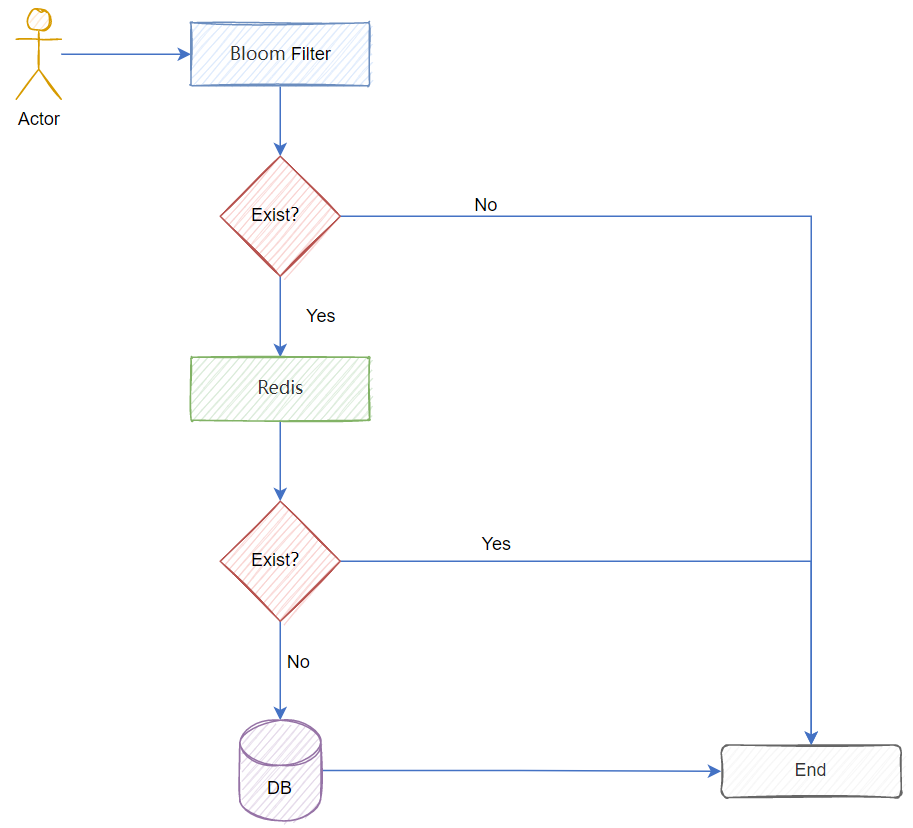
综上,我们通过几个指令就能实现布隆过滤器的建设,避免缓存穿透的情况发生。如果你要查询缓存信息,必须先到Bloom Filter中先跑一次,不存在的直接过滤掉,这样就不会因为无效的key把缓存打穿。
4 程序实现说明
可以在 Golang 中使用 go-redis/redis 库来封装布隆过滤器功能。你需要先确保你的 Redis 服务器已经安装了 RedisBloom 模块,因为 Redis 本身并不直接支持布隆过滤器。一旦 RedisBloom 安装并配置好,你就可以在 Go 代码中通过 go-redis/redis 库来调用相关的 RedisBloom 命令。
package bloomfilter import ( "context" "fmt" "github.com/go-redis/redis/v8"
) // BloomFilter 封装了与布隆过滤器相关的操作
type BloomFilter struct { rdb *redis.Client name string
} // NewBloomFilter 创建一个新的布隆过滤器实例
func NewBloomFilter(rdb *redis.Client, name string) *BloomFilter { return &BloomFilter{ rdb: rdb, name: name, }
} // Add 将元素添加到布隆过滤器中
func (bf *BloomFilter) Add(ctx context.Context, item string, capacity int64, errorRate float64) error { // 注意:RedisBloom 的 BF.ADD 命令通常不需要显式设置容量和错误率, // 因为这些是在创建布隆过滤器时设置的。这里我们简化为只添加元素。 // 如果需要动态调整这些参数,你可能需要重新创建布隆过滤器。 // 但为了示例,我们假设这些参数在创建布隆过滤器时已经设置好了。 _, err := bf.rdb.Do(ctx, "BF.ADD", bf.name, item).Result() return err
} // Exists 检查元素是否可能存在于布隆过滤器中
func (bf *BloomFilter) Exists(ctx context.Context, item string) (bool, error) { result, err := bf.rdb.Do(ctx, "BF.EXISTS", bf.name, item).Int() if err != nil { return false, err } // BF.EXISTS 返回 1 表示可能存在,0 表示一定不存在 return result == 1, nil
} // 注意:在实际应用中,你可能还需要封装更多操作,比如删除布隆过滤器(虽然布隆过滤器通常不支持删除单个元素)
// 或者调整布隆过滤器的容量和错误率(这通常意味着需要重新创建布隆过滤器)。 func main() { rdb := redis.NewClient(&redis.Options{ Addr: "localhost:6379", // Redis 地址 Password: "", // 密码(如果有的话) DB: 0, // 使用的数据库 }) bf := NewBloomFilter(rdb, "myBloomFilter") ctx := context.Background() // 添加元素 err := bf.Add(ctx, "item1", 100000, 0.01) // 注意:BF.ADD 命令通常不需要 capacity 和 errorRate if err != nil { panic(err) } // 检查元素是否存在 exists, err := bf.Exists(ctx, "item1") if err != nil { panic(err) } fmt.Println("Exists:", exists) exists, err = bf.Exists(ctx, "item2") if err != nil { panic(err) } fmt.Println("Exists:", exists)
} // 注意:上面的 Add 方法中的 capacity 和 errorRate 参数在 BF.ADD 命令中并不直接使用,
// 因为 RedisBloom 的 BF.ADD 命令主要用于添加元素到已存在的布隆过滤器中。
// 容量和错误率通常在创建布隆过滤器时通过 BF.RESERVE 命令设置。重要提示:
-
在上面的代码中,
Add方法的capacity和errorRate参数并未直接用于BF.ADD命令,因为BF.ADD只是用于向已存在的布隆过滤器中添加元素。如果你需要设置布隆过滤器的容量和错误率,你应该在创建布隆过滤器时使用BF.RESERVE命令。
-
布隆过滤器不支持传统意义上的“删除”操作,因为一旦一个位被设置为 1,它就不能再被设置为 0(除非重新创建布隆过滤器)。
-
在实际部署之前,请确保你的 Redis 服务器已经安装了 RedisBloom 模块,并且
go-redis/redis库与你的 Redis 服务器版本兼容。
5 总结
本篇介绍了布隆过滤器的几种实现场景。并以火车票订单信息查询为案例进行说明,如何使用布隆过滤器避免缓存穿透,避免被恶意攻击。
文章转载自:Hello-Brand
原文链接:https://www.cnblogs.com/wzh2010/p/18030915
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构