目录
前言:
进程终止在干什么
进程终止的3种情况
进程如何终止
前言:
由上文的地址空间的学习,我们已经知道了进程不是单纯的等于PCB + 自己的代码和数据,进程实际上是等于PCB + mm_struct(地址空间) + 页表 + 自己的代码和数据。在地址空间那里我们结合写时拷贝重新理解了进程具有独立性,也理解了为什么fork函数会返回所谓的两个值,那么今天的话题是进程控制,我们拿fork举例,为什么fork返回给父进程的是子进程的pid,而子进程返回的值的0呢?
这是因为子进程退出的时候,可以将自己的代码和数据退出了,但是自己的PCB还需要维护一段时间,因为父进程需要知道对应的退出信息,退出信息都是维护在PCB里面的,就像是A交给B办一件事,B干的怎么样,A总得知道吧?这个“干的怎么样”,就是B的退出信息。
那么对于进程终止这块内容,本文的介绍方式是:先想清楚进程终止是在干什么,然后理解进程终止的3种情况,最后理解进程如何终止。
进程终止在干什么
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include<sys/types.h>int main()
{pid_t id = fork();if(id == 0){printf("I am a child process,I will die\n");}else{sleep(10);printf("I am a father process,I wait\n");}return 0;
}

我们使用如上的代码,观察了一下僵尸进程的现象,子进程结束之后,父进程休眠10秒,这个过程,子进程已经结束了,但是父进程没有回收它,所以子进程短暂的变成了僵尸进程。
这里提问,进程创建的时候,是自己的代码和数据先过去还是PCB那些数据结构先过去呢?
结合上大学的时候,是你的数据先过去还是人先过去来思考哦~
那么当你毕业了,你的数据是否瞬间就没有了呢?你的人当然是先走了,但是数据总得维护一段时间吧?进程这里同理,当进程终止的时候,进程的代码和数据所占据的空间是被释放了,但是,进程的PCB是需要被维护一段时间的,因为要记录退出信息,此时有一个对应的状态就是zombie,即僵尸进程。
所以进程终止的时候,第一个要干的事就是对应的代码和数据占据的空间先释放掉,然后是进程对应的PCB被维护起来,整个进程的状态变成僵尸,等待回收,对应的退出信息记录在PCB里面,此时进程终止的操作也就完成了,剩下的是等待父进程来回收即可。
进程终止的3种情况
进程终止的3种情况,分别是代码正常,结果正确,代码不正常,结果不正确,以及代码执行的时候,出现了异常,提前退出了,这是3种情况,介绍的时候即围绕这三种情况进行讲解。
思考一个问题:为什么C语言阶段我们写main函数默认要返回的是0呢?为什么不是1?不是100呢?
int main()
{return 1;
}
int main()
{return 0;
}
int main()
{return 100;
}
这三种代码我们放在VS跑都是没有问题的,那么是不是代表main函数的返回值我们可以随便返回呢?
当然不是,在C语言阶段我们只是在语言层面知道了可以返回值而已,但是返回给的谁的我们是不知道的。在Linux阶段,我们通过了解退出码这个知识点,就会知道main的返回值怎么回事。
相信大部分人都知道error,错误码,当我们程序报错的时候,会返回错误码,我们可以打印出来看看:
#include<string.h>int main()
{for(int errcode = 0; errcode <= 255; errcode++){printf("%d: %s\n", errcode, strerror(errcode));}return 0;
}


从133开始,就没有错误码了,所以是unknown,那么第一个错误码,也就是0,表示的意思是success,也就是成功,程序成功运行的时候并且结果正确,返回的错误码是0,也就代表了成功。
现在是知道了错误码,那么我们可以通过命令echo $? 来看到对应的错误码:

看这个2,是不是很熟悉?就是我们刚才的No such file or directory,对于错误码,系统有自己的一套规范,但是错误码是可以自己自定义的,也就是说,我们可以拥有自己的一套错误码的体系:
比如:
int main()
{for(int errcode = 0; errcode <= 255; errcode++){printf("%d: %s\n", errcode, strerror(errcode));}return 100;
}

我们自己规定返回的是100,那么退出码就是100,因为echo是内建命令,直接获取到的父进程的资源,那么bash创建的子进程main,再获取到了退出码为100,这就是退出码。
退出码唯一的一个稍微规范的是0为success,!0为失败,但是失败的具体原因是我们自己规定的,而不是错误码那样,系统已经规定好了。
但是echo $?只能获取最近的一个进程的退出码:

得到结论:退出码可以默认,也可以自定义。
进程如果正常运行,结果是否正确,都只需要一个退出码即可,父进程就可以知道这个进程的情况是什么样的。
进程如果是异常终止的呢?
比如我们写了一个死循环,进程自己停下来不了,我们使用kill发送9号信息码,进程被杀死,就会:


此时,我们看到对应的错误码是137,可是错误码还有意义吗?实际上没有,因为进程异常终止的本质,就是OS给了进程信号,比如:
int main()
{int* p = NULL;*p = 0;return 0;
}
这段代码是一定会报错的:
此时报错,
专业点讲叫做段错误。
本质上就是发生了异常,此时进程收到了OS给的信号,并终止:

kill11号命令,SIGSEGV,就是上面的缩写:
int main()
{while(1){printf("Hello Linux,pid is %d\n",getpid());sleep(1);}return 0;
}
此时我们使用11号信号终止进程,就会报段错误,实际上就是进程收到了OS的信号。
也就是说,如果进程异常终止了,退出码是没有用的,退出码只有在程序正常运行的时候有用,进程如果是异常终止,我们想要知道进程为什么异常,就应该查看信号码了,怎么查看,我们在进程等待章节提及。

源码中,进程退出的时候,对于exit_code exit_signal就需要维护,即对应上面的三种情况。
进程如何终止
进程如何终止的呢?难道是程序运行结束就终止了吗?
不完全是,如果程序是:
int main()
{return 0;
}如果是main函数运行到了return 0 ,此时进程代表终止,但是如果是其他函数碰到了return 0,只能说是函数结束,这是第一种情况。
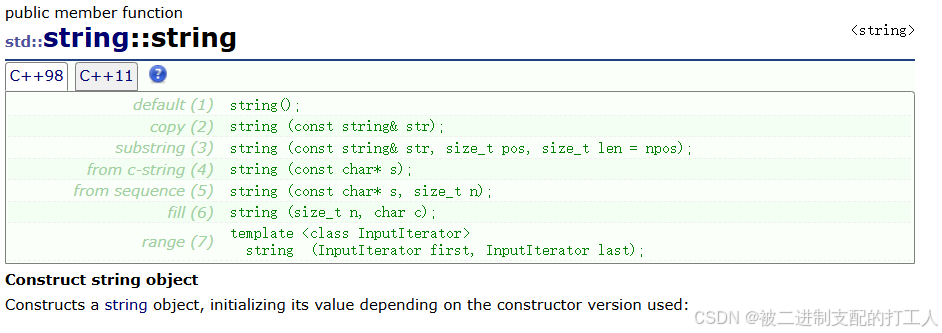
进程终止的第二种情况是exit,我们可以使用两个函数,exit _exit:
int main()
{printf("hello 111\n"); sleep(2);//_exit(3);
}这段代码和缓冲区有关,大家应该知道怎么回事,今天我们这样写:
int main()
{printf("hello 111"); sleep(2);exit(3);
}
可以看到对应的退出码是3,和return效果好像是一样的,因为进程终止,所以会强制刷新缓冲区,即不是先打印,是先休眠的。
此时我们使用系统接口_exit,刚才的exit我们在C语言阶段就使用过,这是库函数,使用_exit呢?

欸?运行了之后为什么什么也没有?

可是对应的退出码也有。
这里,第一个点是exit _exit运行到了都会直接进程终止,并且退出码是exit _exit里面的num,第二点,缓冲区的刷新,_exit调用了没有打印,代表缓冲区没有刷新,我们之前有一个图:
C库函数在系统调用的上方,系统调用在OS的上面,也就是说,exit刷新的缓冲区一定不在OS里面,因为它没有权限,_exit才有资格接触OS,这就说明刷新的缓冲区是在C库函数的上面,得出结论,目前我们说的缓冲区,并不是内核缓冲区!
这是两种进程终止所引发的缓冲区的一个知识点,进程终止我们可以使用return 也可以使用exit,也可以使用_exit,区别就是缓冲区的刷新,但是对于PCB里面的exit_code exit_signal都是要维护的,无非就是缓冲区的刷新而已。
进程终止的更多小点会放在进程等待,即下篇文章哦~
感谢阅读!




![[Linux]僵尸进程,孤儿进程,环境变量](https://i-blog.csdnimg.cn/direct/f352ebe0c5214ba68728660e02f5fb89.png)