针对夸夸闲聊数据集,利用UniLM模型进行模型训练及测试,更深入地了解预训练语言模型的使用方法,完成一个生成式闲聊机器人任务。
项目主要结构如下:
- data 存放数据的文件夹
- dirty_word.txt 敏感词数据
- douban_kuakua_qa.txt 原始语料 【数据量:大概20M的样子】==》用于增量训练
- sample.json 处理后的语料样例
- kuakua_robot_model 已训练好的模型路径
- config.json
- pytorch_model.bin
- vocab.txt
- pretrain_model UniLm预训练文件路径
- config.json
- pytorch_model.bin
- vocab.txt
- chatbot.py 模型推理文件
- configuration_unilm.py UniLm配置文件
- data_helper.py 数据预处理文件
- data_set.py 数据类文件
- modeling_unilm.py UniLm模型文件
- train.py 模型训练文件
- dirty_recognize.py 敏感词检测文件
增量训练的数据样例:
1 Q: 要去打球赛了求表扬
2 A: 真棒好好打乒乓球!
3 Q: 要去打球赛了求表扬
4 A: 是篮球哈哈哈
5 Q: 要去打球赛了求表扬
6 A: 篮板王就是你!
7 Q: 要去打球赛了求表扬
8 A: 加油别把鞋踢脏喽
9 Q: 要去打球赛了求表扬
10 A: 多买点儿币!
11 Q: 要去打球赛了求表扬
12 A: 已经脏了
13 Q: 要去打球赛了求表扬
14 A: 好滴
15 Q: 要去打球赛了求表扬
16 A: 这个配色是是真心不太合我的胃口,还有为什么白鞋要配黑袜子
17 Q: 要去打球赛了求表扬
18 A: 这不是表扬组吗hhh你咋来拆台
19 Q: 要去打球赛了求表扬
20 A: 我不是,我没有,别瞎说哈
21 Q: 要去打球赛了求表扬
22 A: 全场最帅(・ัω・ั),卡胃踩脚拇指戳肋骨无毒神掌天下无敌,然后需要代打嘛
23 Q: 要去打球赛了求表扬
24 A: 你走!
25 Q: 要去打球赛了求表扬
26 A: 8要!
27 Q: 要去打球赛了求表扬
28 A: 我不,我还想问问什么鞋码,多高多重,打什么位置的

注意:由于GitHub不方便放模型文件,因此data文件中douban_kuakua_qa.txt文件、kuakua_robot_model文件夹和pretrain_model文件夹中的模型bin文件,请从百度云盘中下载。【bert模型大小:400MB,用于增量训练的模型,应该是来自https://huggingface.co/bert-base-chinese/tree/main下载的原始bert文件】
| 文件名称 | 下载地址 | 提取码 |
|---|---|---|
| pretrain_model | 百度云 | 7h4a |
| kuakua_robot_model | 百度云 | j954 |
| data | 百度云 | 3sz3 |
由于敏感词表中包含大量敏感词,导致百度云的data链接会失效,因此将敏感词之间放到项目的data目录下。
环境配置
模型训练或推理所需环境,请参考requirements.txt文件。
数据处理
数据预处理需要运行data_helper.py文件,会在data文件夹中生成训练集和测试集文件。
命令如下:
python3 data_helper.py
注意:如果需要修改数据生成路径或名称,请修改data_helper.py文件147-150行,自行定义。
模型训练
模型训练需要运行train.py文件,会自动生成output_dir文件夹,存放每个epoch保存的模型文件。
命令如下:
python3 train.py --device 0 \--data_dir "data/" \--src_file "train.json" \--model_name_or_path "pretrain_model/" \--max_seq_length 256 \--train_batch_size 16 \--num_train_epochs 10
注意:当服务器资源不同或读者更换数据等时,可以在模型训练时修改响应参数,详细参数说明见代码或阅读书3.5.4小节。
模型训练示例如下:
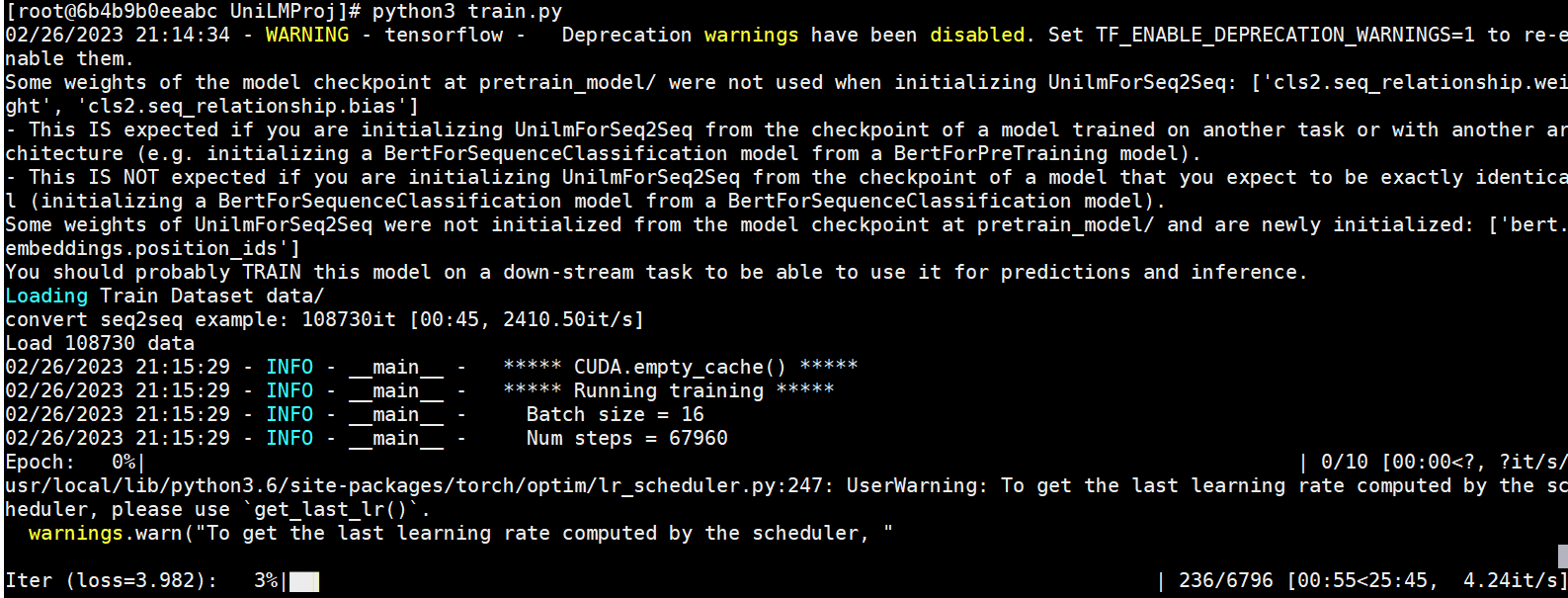
模型训练阶段损失值变化如下: 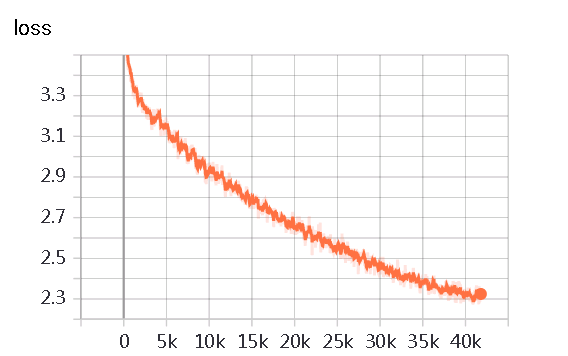
模型推理
模型训练需要运行chatbot.py文件,可以采用项目中以提供的模型,也可以采用自己训练后的模型。
命令如下:
python3 chatbot.py --device 0 --topk 3 --topp 0.95 --max_len 32
注意:如果修改模型路径,请修改–model_path参数。
模型推理示例如下: 
USER:工作不开心
CHAT-BOT:我也是,不过现在开始努力找工作啦!一起加油鸭~
USER:工作不开心
CHAT-BOT:那就祝福你,能找到喜欢的工作吧。
USER:工作不开心
CHAT-BOT:你也要加油鸭!
USER:工作不开心
CHAT-BOT:我也是,不过总有一天就会好起来的
样例2
USER:我分手了
CHAT-BOT:分手快乐,你会遇到更好的。
USER:我分手了
CHAT-BOT:旧的不去新的不来,你会遇见更好的
USER:我分手了
CHAT-BOT:分的好,下一个更乖
样例3
USER:好想去吃火锅,但是我在减肥
CHAT-BOT:你好棒!一定会瘦下来的!
USER:好像去吃火锅,但是我在减肥
CHAT-BOT:吃火锅是为了能更好的减肥,你真棒!我自己没有gpu,训练了一天,运行的流程如下:
D:\book\ChatGPTBook``-``main\UniLMProj 的目录``2023``-``09``-``25` `17``:``54` `<``DIR``> .``2023``-``09``-``25` `17``:``22` `<``DIR``> ..``2023``-``09``-``25` `17``:``22` `5``,``530` `chatbot.py``2023``-``09``-``25` `17``:``22` `2``,``153` `configuration_unilm.py``2023``-``09``-``25` `21``:``04` `<``DIR``> data``2023``-``09``-``25` `17``:``22` `4``,``375` `data_helper.py``2023``-``09``-``25` `17``:``22` `9``,``173` `data_set.py``2023``-``09``-``25` `17``:``22` `1``,``304` `dirty_recognize.py``2023``-``09``-``25` `17``:``22` `<``DIR``> images``2023``-``09``-``25` `17``:``22` `<``DIR``> kuakua_robot_model``2023``-``09``-``25` `17``:``22` `13``,``452` `modeling_unilm.py``2023``-``09``-``25` `17``:``22` `<``DIR``> pretrain_model``2023``-``09``-``25` `17``:``22` `4``,``199` `README.md``2023``-``09``-``25` `17``:``22` `88` `requirements.txt``2023``-``09``-``25` `17``:``22` `8``,``337` `train.py``2023``-``09``-``25` `17``:``22` `1``,``861` `trie.py``2023``-``09``-``25` `17``:``54` `<``DIR``> __pycache__`` ``10` `个文件 ``50``,``472` `字节`` ``7` `个目录 ``175``,``152``,``689``,``152` `可用字节` `D:\book\ChatGPTBook``-``main\UniLMProj>python data_helper.py``total number of data: ``121687` `D:\book\ChatGPTBook``-``main\UniLMProj>``dir` `data`` ``驱动器 D 中的卷是 Data`` ``卷的序列号是 CA99``-``555E` ` ``D:\book\ChatGPTBook``-``main\UniLMProj\data 的目录` `2023``-``09``-``25` `21``:``06` `<``DIR``> .``2023``-``09``-``25` `17``:``54` `<``DIR``> ..``2023``-``09``-``25` `17``:``22` `245``,``546` `dirty_words.txt``2023``-``09``-``25` `17``:``56` `21``,``620``,``763` `douban_kuakua_qa.txt``2023``-``09``-``25` `17``:``22` `446` `sample.json``2023``-``09``-``25` `21``:``06` `14``,``272``,``447` `train.json`` ``4` `个文件 ``36``,``139``,``202` `字节`` ``2` `个目录 ``175``,``138``,``414``,``592` `可用字节` `D:\book\ChatGPTBook``-``main\UniLMProj>python train.py``Traceback (most recent call last):`` ``File` `"D:\book\ChatGPTBook-main\UniLMProj\train.py"``, line ``18``, ``in` `<module>`` ``import` `torch``ModuleNotFoundError: No module named ``'torch'` `D:\book\ChatGPTBook``-``main\UniLMProj>pip install torch`` ` `D:\book\ChatGPTBook``-``main\UniLMProj>pip install torch`` ` `D:\book\ChatGPTBook``-``main\UniLMProj>``D:\book\ChatGPTBook``-``main\UniLMProj>python train.py``Traceback (most recent call last):`` ``File` `"D:\book\ChatGPTBook-main\UniLMProj\train.py"``, line ``20``, ``in` `<module>`` ``from` `transformers ``import` `BertTokenizer``ModuleNotFoundError: No module named ``'transformers'` `D:\book\ChatGPTBook``-``main\UniLMProj>pip install transformers`` ` `D:\book\ChatGPTBook``-``main\UniLMProj>python train.py``Traceback (most recent call last):`` ``File` `"D:\book\ChatGPTBook-main\UniLMProj\train.py"``, line ``170``, ``in` `<module>`` ``main()`` ``File` `"D:\book\ChatGPTBook-main\UniLMProj\train.py"``, line ``86``, ``in` `main`` ``model ``=` `UnilmForSeq2Seq.from_pretrained(args.model_name_or_path, config``=``config)`` ``^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^`` ``File` `"C:\Python311\Lib\site-packages\transformers\modeling_utils.py"``, line ``2740``, ``in` `from_pretrained`` ``raise` `EnvironmentError(``OSError: Error no ``file` `named pytorch_model.``bin``, tf_model.h5, model.ckpt.index ``or` `flax_model.msgpack found ``in` `directory pretrain_model``/``.` `D:\book\ChatGPTBook``-``main\UniLMProj>python train.py``Loading Train Dataset data``/``convert seq2seq example: ``108730it` `[``00``:``29``, ``3741.34it``/``s]``Load ``108730` `data``C:\Python311\Lib\site``-``packages\transformers\optimization.py:``411``: FutureWarning: This implementation of AdamW ``is` `deprecated ``and` `will be removed ``in` `a future version. Use the PyTorch implementation torch.optim.AdamW instead, ``or` `set` ``no_deprecation_warning``=``True```to disable this warning`` ``warnings.warn(``09``/``25``/``2023` `21``:``45``:``57` `-` `INFO ``-` `__main__ ``-` `*``*``*``*``*` `CUDA.empty_cache() ``*``*``*``*``*``09``/``25``/``2023` `21``:``45``:``57` `-` `INFO ``-` `__main__ ``-` `*``*``*``*``*` `Running training ``*``*``*``*``*``09``/``25``/``2023` `21``:``45``:``57` `-` `INFO ``-` `__main__ ``-` `Batch size ``=` `16``09``/``25``/``2023` `21``:``45``:``57` `-` `INFO ``-` `__main__ ``-` `Num steps ``=` `67960``Epoch: ``0``%``| | ``0``/``10` `[``00``:``00``<?, ?it``/``s]C:\Python311\Lib\site``-``packages\torch\optim\lr_scheduler.py:``265``: UserWarning: To get the last learning rate computed by the scheduler, please use `get_last_lr()`.`` ``warnings.warn(``"To get the last learning rate computed by the scheduler, "``Iter` `(loss``=``3.279``): ``100``%``|████████████████████████████████████████████████████████| ``6796``/``6796` `[``25``:``32``:``28``<``00``:``00``, ``13.53s``/``it]``09``/``26``/``2023` `23``:``18``:``26` `-` `INFO ``-` `__main__ ``-` `*``*` `*``*` `*` `Saving fine``-``tuned model ``and` `optimizer ``*``*` `*``*` `*` `32``:``28``<``00``:``00``, ``9.24s``/``it]``Epoch: ``10``%``|██████▌ | ``1``/``10` `[``25``:``32``:``29``<``229``:``52``:``22``, ``91949.11s``/``it]``Iter` `(loss``=``3.525``): ``31``%``|████████████████▎ | ``2096``/``6796` `[``10``:``55``:``33``<``16``:``16``:``17``, ``12.46s``/``it]
训练了一天,最后的聊天效果:
D:\book\ChatGPTBook``-``main\UniLMProj>python chatbot.py ``-``-``topk ``3` `-``-``topp ``0.95` `-``-``max_len ``32` `-``-``model_name_or_path output_dir\checkpoint``-``6796``\``cpu``Chitchat Robot Starting``user:你好啊``chat``-``bot:这么可爱的人真的很有缘分呢,你是最棒了!``user:终于训练好了一个大模型机器人了``chat``-``bot:好厉害!我也想学,但是还是没有做到``user:哈哈哈``chat``-``bot:你真的很可爱!我也是,但不想被表扬。``user:大模型是什么呢?``chat``-``bot:我们一起努力吧!``user:你是谁?``chat``-``bot:我是你!``user:你逗我呢``chat``-``bot:你也是个可爱的小可爱,我们一起夸
我们来分析下模型源码:
import` `copy``import` `math``import` `logging``import` `torch``from` `torch ``import` `nn``import` `torch.nn.functional as F``from` `torch.nn.modules.loss ``import` `_Loss``from` `transformers.modeling_utils ``import` `PreTrainedModel``from` `configuration_unilm ``import` `UnilmConfig``from` `transformers.models.bert.modeling_bert ``import` `load_tf_weights_in_bert, BertPooler, BertIntermediate, BertOutput, \`` ``BertSelfOutput, BertOnlyMLMHead, BertEmbeddings` `logger ``=` `logging.getLogger(__name__)` `BertLayerNorm ``=` `torch.nn.LayerNorm` `class` `BertSelfAttention(nn.Module):`` ``def` `__init__(``self``, config):`` ``super``(BertSelfAttention, ``self``).__init__()`` ``if` `config.hidden_size ``%` `config.num_attention_heads !``=` `0``:`` ``raise` `ValueError(`` ``"The hidden size (%d) is not a multiple of the number of attention "`` ``"heads (%d)"` `%` `(config.hidden_size, config.num_attention_heads))`` ``self``.num_attention_heads ``=` `config.num_attention_heads`` ``self``.attention_head_size ``=` `int``(`` ``config.hidden_size ``/` `config.num_attention_heads)`` ``self``.all_head_size ``=` `self``.num_attention_heads ``*` `self``.attention_head_size` ` ``self``.query ``=` `nn.Linear(config.hidden_size, ``self``.all_head_size)`` ``self``.key ``=` `nn.Linear(config.hidden_size, ``self``.all_head_size)`` ``self``.value ``=` `nn.Linear(config.hidden_size, ``self``.all_head_size)` ` ``self``.dropout ``=` `nn.Dropout(config.attention_probs_dropout_prob)` ` ``def` `transpose_for_scores(``self``, x):`` ``sz ``=` `x.size()[:``-``1``] ``+` `(``self``.num_attention_heads,`` ``self``.attention_head_size)`` ``x ``=` `x.view(``*``sz)`` ``return` `x.permute(``0``, ``2``, ``1``, ``3``)` ` ``def` `forward(``self``, hidden_states, attention_mask, history_states``=``None``):`` ``if` `history_states ``is` `None``:`` ``mixed_query_layer ``=` `self``.query(hidden_states)`` ``mixed_key_layer ``=` `self``.key(hidden_states)`` ``mixed_value_layer ``=` `self``.value(hidden_states)`` ``else``:`` ``x_states ``=` `torch.cat((history_states, hidden_states), dim``=``1``)`` ``mixed_query_layer ``=` `self``.query(hidden_states)`` ``mixed_key_layer ``=` `self``.key(x_states)`` ``mixed_value_layer ``=` `self``.value(x_states)` ` ``query_layer ``=` `self``.transpose_for_scores(mixed_query_layer)`` ``key_layer ``=` `self``.transpose_for_scores(mixed_key_layer)`` ``value_layer ``=` `self``.transpose_for_scores(mixed_value_layer)` ` ``attention_scores ``=` `torch.matmul(`` ``query_layer ``/` `math.sqrt(``self``.attention_head_size), key_layer.transpose(``-``1``, ``-``2``))`` ``attention_scores ``=` `attention_scores ``+` `attention_mask` ` ``attention_probs ``=` `nn.Softmax(dim``=``-``1``)(attention_scores)` ` ``attention_probs ``=` `self``.dropout(attention_probs)` ` ``context_layer ``=` `torch.matmul(attention_probs, value_layer)`` ``context_layer ``=` `context_layer.permute(``0``, ``2``, ``1``, ``3``).contiguous()`` ``new_context_layer_shape ``=` `context_layer.size()[`` ``:``-``2``] ``+` `(``self``.all_head_size,)`` ``context_layer ``=` `context_layer.view(``*``new_context_layer_shape)`` ``return` `context_layer` `class` `BertAttention(nn.Module):`` ``def` `__init__(``self``, config):`` ``super``(BertAttention, ``self``).__init__()`` ``self``.``self` `=` `BertSelfAttention(config)`` ``self``.output ``=` `BertSelfOutput(config)` ` ``def` `forward(``self``, input_tensor, attention_mask, history_states``=``None``):`` ``self_output ``=` `self``.``self``(`` ``input_tensor, attention_mask, history_states``=``history_states)`` ``attention_output ``=` `self``.output(self_output, input_tensor)`` ``return` `attention_output` `class` `BertLayer(nn.Module):`` ``def` `__init__(``self``, config):`` ``super``(BertLayer, ``self``).__init__()`` ``self``.attention ``=` `BertAttention(config)`` ``self``.intermediate ``=` `BertIntermediate(config)`` ``self``.output ``=` `BertOutput(config)` ` ``def` `forward(``self``, hidden_states, attention_mask, history_states``=``None``):`` ``attention_output ``=` `self``.attention(`` ``hidden_states, attention_mask, history_states``=``history_states)`` ``intermediate_output ``=` `self``.intermediate(attention_output)`` ``layer_output ``=` `self``.output(intermediate_output, attention_output)`` ``return` `layer_output` `class` `BertEncoder(nn.Module):`` ``def` `__init__(``self``, config):`` ``super``(BertEncoder, ``self``).__init__()`` ``layer ``=` `BertLayer(config)`` ``self``.layer ``=` `nn.ModuleList([copy.deepcopy(layer)`` ``for` `_ ``in` `range``(config.num_hidden_layers)])` ` ``def` `forward(``self``, hidden_states, attention_mask, output_all_encoded_layers``=``True``, prev_embedding``=``None``,`` ``prev_encoded_layers``=``None``):`` ``assert` `(prev_embedding ``is` `None``) ``=``=` `(prev_encoded_layers ``is` `None``)` ` ``all_encoder_layers ``=` `[]`` ``if` `(prev_embedding ``is` `not` `None``) ``and` `(prev_encoded_layers ``is` `not` `None``):`` ``history_states ``=` `prev_embedding`` ``for` `i, layer_module ``in` `enumerate``(``self``.layer):`` ``hidden_states ``=` `layer_module(`` ``hidden_states, attention_mask, history_states``=``history_states)`` ``if` `output_all_encoded_layers:`` ``all_encoder_layers.append(hidden_states)`` ``if` `prev_encoded_layers ``is` `not` `None``:`` ``history_states ``=` `prev_encoded_layers[i]`` ``else``:`` ``for` `layer_module ``in` `self``.layer:`` ``hidden_states ``=` `layer_module(`` ``hidden_states, attention_mask)`` ``if` `output_all_encoded_layers:`` ``all_encoder_layers.append(hidden_states)`` ``if` `not` `output_all_encoded_layers:`` ``all_encoder_layers.append(hidden_states)`` ``return` `all_encoder_layers` `class` `UnilmPreTrainedModel(PreTrainedModel):`` ``config_class ``=` `UnilmConfig`` ``load_tf_weights ``=` `load_tf_weights_in_bert`` ``base_model_prefix ``=` `"unilm"` ` ``def` `_init_weights(``self``, module):`` ``if` `isinstance``(module, (nn.Linear, nn.Embedding)):`` ``module.weight.data.normal_(mean``=``0.0``, std``=``self``.config.initializer_range)`` ``elif` `isinstance``(module, BertLayerNorm):`` ``module.bias.data.zero_()`` ``module.weight.data.fill_(``1.0``)`` ``if` `isinstance``(module, nn.Linear) ``and` `module.bias ``is` `not` `None``:`` ``module.bias.data.zero_()` `class` `UnilmModel(UnilmPreTrainedModel):`` ``def` `__init__(``self``, config):`` ``super``(UnilmModel, ``self``).__init__(config)`` ``self``.embeddings ``=` `BertEmbeddings(config)`` ``self``.encoder ``=` `BertEncoder(config)`` ``self``.pooler ``=` `BertPooler(config)`` ``self``.init_weights()` ` ``def` `get_extended_attention_mask(``self``, input_ids, token_type_ids, attention_mask):`` ``if` `attention_mask ``is` `None``:`` ``attention_mask ``=` `torch.ones_like(input_ids)`` ``if` `token_type_ids ``is` `None``:`` ``token_type_ids ``=` `torch.zeros_like(input_ids)` ` ``if` `attention_mask.dim() ``=``=` `2``:`` ``extended_attention_mask ``=` `attention_mask.unsqueeze(``1``).unsqueeze(``2``)`` ``elif` `attention_mask.dim() ``=``=` `3``:`` ``extended_attention_mask ``=` `attention_mask.unsqueeze(``1``)`` ``else``:`` ``raise` `NotImplementedError`` ``extended_attention_mask ``=` `extended_attention_mask.to(`` ``dtype``=``next``(``self``.parameters()).dtype) ``# fp16 compatibility`` ``extended_attention_mask ``=` `(``1.0` `-` `extended_attention_mask) ``*` `-``10000.0`` ``return` `extended_attention_mask` ` ``def` `forward(``self``, input_ids, token_type_ids``=``None``, attention_mask``=``None``, output_all_encoded_layers``=``True``):`` ``extended_attention_mask ``=` `self``.get_extended_attention_mask(`` ``input_ids, token_type_ids, attention_mask)` ` ``embedding_output ``=` `self``.embeddings(`` ``input_ids, token_type_ids)`` ``encoded_layers ``=` `self``.encoder(embedding_output, extended_attention_mask,`` ``output_all_encoded_layers``=``output_all_encoded_layers)`` ``sequence_output ``=` `encoded_layers[``-``1``]`` ``pooled_output ``=` `self``.pooler(sequence_output)`` ``if` `not` `output_all_encoded_layers:`` ``encoded_layers ``=` `encoded_layers[``-``1``]`` ``return` `encoded_layers, pooled_output` `class` `LabelSmoothingLoss(_Loss):`` ``def` `__init__(``self``, label_smoothing``=``0``, tgt_vocab_size``=``0``, ignore_index``=``0``, size_average``=``None``, ``reduce``=``None``,`` ``reduction``=``'mean'``):`` ``assert` `0.0` `< label_smoothing <``=` `1.0`` ``self``.ignore_index ``=` `ignore_index`` ``super``(LabelSmoothingLoss, ``self``).__init__(`` ``size_average``=``size_average, ``reduce``=``reduce``, reduction``=``reduction)` ` ``assert` `label_smoothing > ``0`` ``assert` `tgt_vocab_size > ``0` ` ``smoothing_value ``=` `label_smoothing ``/` `(tgt_vocab_size ``-` `2``)`` ``one_hot ``=` `torch.full((tgt_vocab_size,), smoothing_value)`` ``one_hot[``self``.ignore_index] ``=` `0`` ``self``.register_buffer(``'one_hot'``, one_hot.unsqueeze(``0``))`` ``self``.confidence ``=` `1.0` `-` `label_smoothing`` ``self``.tgt_vocab_size ``=` `tgt_vocab_size` ` ``def` `forward(``self``, output, target):`` ``assert` `self``.tgt_vocab_size ``=``=` `output.size(``2``)`` ``batch_size, num_pos ``=` `target.size(``0``), target.size(``1``)`` ``output ``=` `output.view(``-``1``, ``self``.tgt_vocab_size)`` ``target ``=` `target.view(``-``1``)`` ``model_prob ``=` `self``.one_hot.repeat(target.size(``0``), ``1``)`` ``model_prob.scatter_(``1``, target.unsqueeze(``1``), ``self``.confidence)`` ``model_prob.masked_fill_((target ``=``=` `self``.ignore_index).unsqueeze(``1``), ``0``)` ` ``return` `F.kl_div(output, model_prob.type_as(output), reduction``=``'none'``).view(batch_size, num_pos, ``-``1``).``sum``(``2``)` `class` `UnilmForSeq2Seq(UnilmPreTrainedModel):`` ``"""UniLM模型进行Seq2Seq的训练模型类"""` ` ``def` `__init__(``self``, config):`` ``"""模型初始化函数,定义模型训练所需的各个模块"""`` ``super``(UnilmForSeq2Seq, ``self``).__init__(config)`` ``self``.bert ``=` `UnilmModel(config)`` ``self``.``cls` `=` `BertOnlyMLMHead(config)`` ``self``.mask_lm ``=` `nn.CrossEntropyLoss(reduction``=``'none'``)`` ``if` `hasattr``(config, ``'label_smoothing'``) ``and` `config.label_smoothing:`` ``self``.mask_lm_smoothed ``=` `LabelSmoothingLoss(config.label_smoothing, config.vocab_size, ignore_index``=``0``,`` ``reduction``=``'none'``)`` ``else``:`` ``self``.mask_lm_smoothed ``=` `None`` ``self``.init_weights()`` ``self``.tie_weights()` ` ``def` `tie_weights(``self``):`` ``"""权重加载,加载预训练模型的embeddings部分权重"""`` ``self``._tie_or_clone_weights(``self``.``cls``.predictions.decoder,`` ``self``.bert.embeddings.word_embeddings)` ` ``def` `forward(``self``, input_ids, token_type_ids``=``None``, attention_mask``=``None``, masked_lm_labels``=``None``, masked_pos``=``None``,`` ``masked_weights``=``None``):`` ``"""模型forward,向前传递函数"""`` ``# 获取Encoder部分的序列输出,维度[bs,seq_len,hidden_size]`` ``sequence_output, __ ``=` `self``.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers``=``False``)` ` ``def` `gather_seq_out_by_pos(seq, pos):`` ``return` `torch.gather(seq, ``1``, pos.unsqueeze(``2``).expand(``-``1``, ``-``1``, seq.size(``-``1``)))` ` ``def` `loss_mask_and_normalize(loss, mask):`` ``mask ``=` `mask.type_as(loss)`` ``loss ``=` `loss ``*` `mask`` ``denominator ``=` `torch.``sum``(mask) ``+` `1e``-``5`` ``return` `(loss ``/` `denominator).``sum``()` ` ``if` `masked_lm_labels ``is` `None``:`` ``if` `masked_pos ``is` `None``:`` ``prediction_scores ``=` `self``.``cls``(sequence_output)`` ``else``:`` ``sequence_output_masked ``=` `gather_seq_out_by_pos(sequence_output, masked_pos)`` ``prediction_scores ``=` `self``.``cls``(sequence_output_masked)`` ``return` `prediction_scores`` ``# 获取被掩码位置的向量`` ``sequence_output_masked ``=` `gather_seq_out_by_pos(sequence_output, masked_pos)`` ``prediction_scores_masked ``=` `self``.``cls``(sequence_output_masked)`` ``if` `self``.mask_lm_smoothed:`` ``masked_lm_loss ``=` `self``.mask_lm_smoothed(F.log_softmax(prediction_scores_masked.``float``(), dim``=``-``1``),`` ``masked_lm_labels)`` ``else``:`` ``masked_lm_loss ``=` `self``.mask_lm(prediction_scores_masked.transpose(``1``, ``2``).``float``(), masked_lm_labels)`` ``# 计算[Mask]标记的损失值`` ``masked_lm_loss ``=` `loss_mask_and_normalize(masked_lm_loss.``float``(), masked_weights)` ` ``return` `masked_lm_loss` `class` `UnilmForSeq2SeqDecodeSample(UnilmPreTrainedModel):`` ``"""UniLM模型进行Seq2Seq的模型解码类"""`` ``def` `__init__(``self``, config):`` ``"""模型初始化函数,定义模型训练所需的各个模块"""`` ``super``(UnilmForSeq2SeqDecodeSample, ``self``).__init__(config)`` ``self``.bert ``=` `UnilmModel(config)`` ``self``.``cls` `=` `BertOnlyMLMHead(config)`` ``self``.init_weights()`` ``self``.tie_weights()` ` ``def` `tie_weights(``self``):`` ``"""权重加载,加载预训练模型的embeddings部分权重"""`` ``self``._tie_or_clone_weights(``self``.``cls``.predictions.decoder, ``self``.bert.embeddings.word_embeddings)` ` ``def` `forward(``self``, input_ids, token_type_ids, attention_mask):`` ``# 获取Encoder部分的序列输出,维度[bs,seq_len,hidden_size]`` ``sequence_output, __ ``=` `self``.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers``=``False``)`` ``# 获取最优一个节点的输出`` ``last_hidden ``=` `sequence_output[:, ``-``1``:, :]`` ``# 将其映射到词表中,为后面解码提供内容`` ``prediction_scores ``=` `self``.``cls``(last_hidden)`` ``return` `prediction_scores
文件定义了一个基于UniLM(Unified Language Model)的Seq2Seq模型,主要用于序列生成任务。UniLM是一种预训练的语言模型,它在单一的语言模型架构下整合了双向和单向的语言模型。
文件中定义了以下几个主要的类:
\1. BertSelfAttention:这是一个自注意力机制的实现,用于计算输入序列中每个元素的注意力分数。
\2. BertAttention、BertLayer、BertEncoder:这些类是BERT模型的主要组成部分,用于处理输入序列并生成隐藏状态。
\3. UnilmPreTrainedModel:这是一个预训练模型的基类,定义了权重初始化和加载预训练权重的方法。
\4. UnilmModel:这是UniLM模型的主要实现,它包含了BERT的嵌入层、编码器和池化层。
\5. LabelSmoothingLoss:这是一个实现了标签平滑的损失函数,用于训练过程中减少模型对于标签的过拟合。
\6. UnilmForSeq2Seq:这是一个用于序列到序列任务的UniLM模型,它在UnilmModel的基础上添加了一个预测头,用于预测下一个词。
\7. UnilmForSeq2SeqDecodeSample:这是一个用于序列到序列任务的解码器,它使用UnilmModel生成的隐藏状态,通过预测头生成下一个词的预测。
总的来说,这个文件定义的模型结构主要用于处理序列到序列的任务,如机器翻译、文本摘要等。模型的最终目标是根据输入的序列生成一个新的序列。
【模型训练】
这个训练代码使用的模型是UnilmForSeq2Seq,这是一个基于UniLM(Unified Language Model)的序列到序列模型。这个模型主要用于处理序列生成任务,如机器翻译、文本摘要等。在代码中,模型的加载过程如下:
config = UnilmConfig.from_pretrained(args.model_name_or_path)
tokenizer = BertTokenizer.from_pretrained(args.model_name_or_path, do_lower_case=args.do_lower_case)
model = UnilmForSeq2Seq.from_pretrained(args.model_name_or_path, config=config)
model.to(device)
这段代码首先从预训练模型的路径加载UniLM的配置和BERT的分词器,然后使用这些配置和分词器从预训练模型的路径加载UnilmForSeq2Seq模型,并将模型移动到指定的设备上(如果有GPU则使用GPU,否则使用CPU)。
class` `UnilmForSeq2Seq(UnilmPreTrainedModel):`` ``"""UniLM模型进行Seq2Seq的训练模型类"""` ` ``def` `__init__(``self``, config):`` ``"""模型初始化函数,定义模型训练所需的各个模块"""`` ``super``(UnilmForSeq2Seq, ``self``).__init__(config)`` ``self``.bert ``=` `UnilmModel(config)`` ``self``.``cls` `=` `BertOnlyMLMHead(config)`` ``self``.mask_lm ``=` `nn.CrossEntropyLoss(reduction``=``'none'``)`` ``if` `hasattr``(config, ``'label_smoothing'``) ``and` `config.label_smoothing:`` ``self``.mask_lm_smoothed ``=` `LabelSmoothingLoss(config.label_smoothing, config.vocab_size, ignore_index``=``0``,`` ``reduction``=``'none'``)`` ``else``:`` ``self``.mask_lm_smoothed ``=` `None`` ``self``.init_weights()`` ``self``.tie_weights()` ` ``def` `tie_weights(``self``):`` ``"""权重加载,加载预训练模型的embeddings部分权重"""`` ``self``._tie_or_clone_weights(``self``.``cls``.predictions.decoder,`` ``self``.bert.embeddings.word_embeddings)` ` ``def` `forward(``self``, input_ids, token_type_ids``=``None``, attention_mask``=``None``, masked_lm_labels``=``None``, masked_pos``=``None``,`` ``masked_weights``=``None``):`` ``"""模型forward,向前传递函数"""`` ``# 获取Encoder部分的序列输出,维度[bs,seq_len,hidden_size]`` ``sequence_output, __ ``=` `self``.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers``=``False``)` ` ``def` `gather_seq_out_by_pos(seq, pos):`` ``return` `torch.gather(seq, ``1``, pos.unsqueeze(``2``).expand(``-``1``, ``-``1``, seq.size(``-``1``)))` ` ``def` `loss_mask_and_normalize(loss, mask):`` ``mask ``=` `mask.type_as(loss)`` ``loss ``=` `loss ``*` `mask`` ``denominator ``=` `torch.``sum``(mask) ``+` `1e``-``5`` ``return` `(loss ``/` `denominator).``sum``()` ` ``if` `masked_lm_labels ``is` `None``:`` ``if` `masked_pos ``is` `None``:`` ``prediction_scores ``=` `self``.``cls``(sequence_output)`` ``else``:`` ``sequence_output_masked ``=` `gather_seq_out_by_pos(sequence_output, masked_pos)`` ``prediction_scores ``=` `self``.``cls``(sequence_output_masked)`` ``return` `prediction_scores`` ``# 获取被掩码位置的向量`` ``sequence_output_masked ``=` `gather_seq_out_by_pos(sequence_output, masked_pos)`` ``prediction_scores_masked ``=` `self``.``cls``(sequence_output_masked)`` ``if` `self``.mask_lm_smoothed:`` ``masked_lm_loss ``=` `self``.mask_lm_smoothed(F.log_softmax(prediction_scores_masked.``float``(), dim``=``-``1``),`` ``masked_lm_labels)`` ``else``:`` ``masked_lm_loss ``=` `self``.mask_lm(prediction_scores_masked.transpose(``1``, ``2``).``float``(), masked_lm_labels)`` ``# 计算[Mask]标记的损失值`` ``masked_lm_loss ``=` `loss_mask_and_normalize(masked_lm_loss.``float``(), masked_weights)` ` ``return` `masked_lm_loss
我们重点看看这个模型类:
UnilmForSeq2Seq是一个基于UniLM模型的序列到序列模型,主要用于处理序列生成任务,如机器翻译、文本摘要等。下面是UnilmForSeq2Seq模型的主要组成部分及其功能:
-
self.bert = UnilmModel(config):这是UniLM模型的主体部分,包括BERT的嵌入层、编码器和池化层。这部分用于处理输入序列并生成隐藏状态。
-
self.cls = BertOnlyMLMHead(config):这是一个预测头,用于预测下一个词。它接收UnilmModel生成的隐藏状态,并输出每个词的预测分数。
-
self.mask_lm = nn.CrossEntropyLoss(reduction=‘none’):这是一个交叉熵损失函数,用于计算预测和真实标签之间的损失。
-
self.mask_lm_smoothed = LabelSmoothingLoss(config.label_smoothing, config.vocab_size, ignore_index=0, reduction=‘none’):这是一个实现了标签平滑的损失函数,用于训练过程中减少模型对于标签的过拟合。
-
forward函数:这是模型的前向传播函数,它接收输入序列、注意力掩码和标签,然后通过UnilmModel和预测头计算预测分数,最后使用损失函数计算损失。
总的来说,UnilmForSeq2Seq模型的主要功能是根据输入的序列生成一个新的序列,并通过计算预测和真实标签之间的损失进行训练。
最后如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


![[Uninstall] 软件彻底卸载工具的下载及详细安装使用过程(附有下载文件)](https://i-blog.csdnimg.cn/direct/f6cfe95bd4cf4412b8bb780a72c0a4f8.png)