长话短说:
准备好深入研究:
- 矢量存储的复杂性以及如何利用 Qdrant 进行高效数据摄取。
- 掌握 Qdrant 中的集合管理以获得最佳性能。
- 释放上下文感知响应的相似性搜索的潜力。
- 精心设计复杂的 LangChain 工作流程以增强聊天机器人的功能。
- 将革命性的 Llama 3.1 模型与 Groq 的高速基础设施集成。
介绍
当我们探索创建尖端的多语言医疗保健聊天机器人时,踏上先进人工智能世界的变革之旅。在这份综合指南中,我们将利用 Qdrant、LangChain 和 OpenAI 的力量来构建打破语言障碍的复杂对话式 AI。
无论您是人工智能爱好者、经验丰富的开发人员还是介于两者之间,本教程都将为您提供创建人工智能应用程序的知识和技能,从而突破可能的界限。读完本文后,您将为构建能够适应各种用例的智能多语言系统奠定坚实的基础。
准备好挑战自己,扩展您的 AI 工具包,并加入塑造对话式 AI 未来的创新者行列。让我们开始这次激动人心的现代聊天机器人开发核心冒险吧!

图像通过代码与Prince
项目数据集
要创建多语言医疗保健聊天机器人,第一步是保护合适的数据集。该数据集应与医疗保健相关,以确保做出相关且准确的响应。在我的研究过程中,我发现了一个有用的在线数据集,我们可以将其用于该项目。
GitHub - Princekrampah/multilingual_healthcare_bot
通过在 GitHub 上创建帐户来为 Princekrampah/multilingual_healthcare_bot 开发做出贡献。
github.com
我执行了一些预处理来合并两个表: symptom_Description.csv和symptom_precaution.csv文件。合并这些表后,我清理了数据并将结果保存在名为cleaned_data.csv的文件中。所有文件都位于数据目录中,以便于访问。

图像通过代码与Prince
我不会详细介绍数据清理过程,因为它不是本文的重点。但是,您可以通过从提供的位置下载cleaned_data.csv文件来访问已清理的数据。
获取 API 密钥
成功下载所有数据后,我们还需要Qdrant和OpenAI的 API 密钥。
从OpenAI开始,您可以点击此处的链接来访问您的 API 密钥。
生成 OpenAI API 密钥后,您可以返回 VS-code 并打开.env文件并添加以下内容:
OPENAI_API_KEY=sk-xxxxxxxxxxxxx
转到Qdrant ,您首先需要创建一个 Qdrant 云帐户。您可以使用此链接执行此操作。一旦您在 Gmail 下拥有了帐户,我们就可以进入下一阶段。
注意:如果您不想使用免费提供的 Qdrant 云实例,您也可以在本地设置 Qdrant。这不是我将在本文中讨论的内容。欲了解更多信息,您可以阅读此处。
创建Qdrant云集群
一旦我们有了 API 密钥,我们就需要继续创建一个集群,正如它们在Qdrant Cloud中所调用的那样。登录帐户后,您应该会看到此仪表板。
图像通过代码与Prince
在屏幕最左侧的侧边栏上,单击“集群”按钮。
单击屏幕右上角的“创建”按钮,填写详细信息以创建集群

图像通过代码与Prince

图像由代码与Prince
完成后,您应该能够在仪表板中看到创建的集群。
图像通过代码与Prince
单击集群名称可重定向至集群仪表板。
到达那里后,您应该能够看到集群详细信息。

获取 Qdrant API 密钥
要获取 Qdrant API 密钥,您必须单击屏幕最左侧的“数据访问控制”按钮。
完成后,单击屏幕右上角的“创建”按钮。填写详细信息并创建您的 API 密钥。
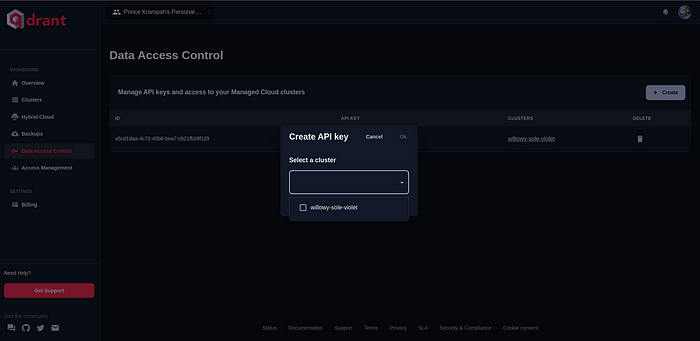
选择您要为其创建 API 密钥的集群,然后单击“确定”。
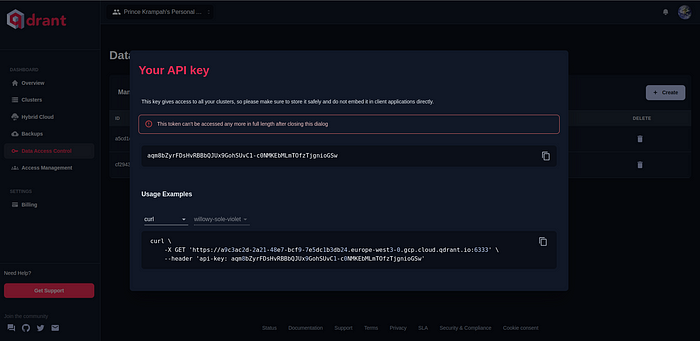
请勿在此模式之外单击,并轻轻复制第一个输入字段中显示的 API 密钥。
复制后,您可以返回 VS 代码,打开.env文件并将其添加到其中
OPENAI_API_KEY=sk-xxxx
QDRANT_API_KEY=xxxxxx我们还需要刚刚创建的集群的 URL 或“端点” ;您可以通过单击侧栏上的“Clusters”按钮获取该 URL。
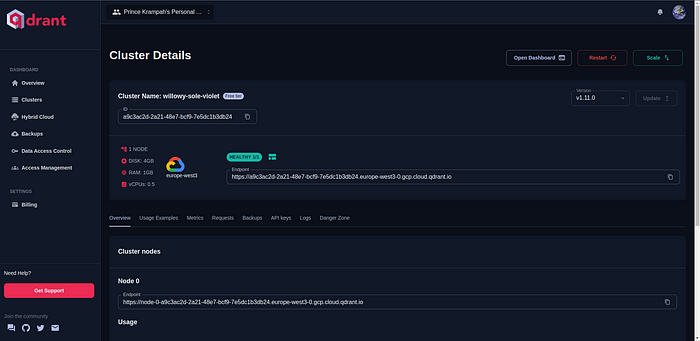
复制后,将其粘贴到.env文件中,如下所示:
OPENAI_API_KEY=sk-xxxxxxxxxxxxx
QDRANT_URL=https://xxxxxxxxxxxxxxxxxxxxxx
QDRANT_API_KEY=xxxxxxxOpenAI 嵌入模型
我们将使用 OpenAI 的文本嵌入模型来创建文本文档的矢量表示。为此,我们需要在我们将使用的.env文件中设置一些环境变量。
OPENAI_API_KEY=sk-xxxxxxxxxxxxx
QDRANT_URL=https://xxxxxxxxxxxxxxxxxxxxxx
QDRANT_API_KEY=xxxxxxx
QDRANT_VECTOR_DIMENSION=1536
EMBEDDING_MODEL="text-embedding-3-small"您可以在此处阅读有关 OpenAI 嵌入模型的更多信息: OpenAI 嵌入模型
数据摄取
这个非常重要的部分中,我们将深入探讨将数据引入 Qdrant Cloud 的过程,Qdrant Cloud 是一个功能强大的矢量数据库,将作为我们高级文档检索系统的基础。通过创建复杂的矢量索引,我们将解锁执行闪电般快速的相似性搜索的能力,使我们能够查明最相关的文档,以前所未有的准确性回答用户查询。
为了使这个系统栩栩如生,我们将利用 OpenAI 最先进的嵌入模型的力量。这些尖端模型将把我们的原始文本数据转换为丰富的多维向量表示,捕获每个文档的微妙语义。
读完本节后,您将拥有一个触手可及的强大矢量索引,准备好彻底改变您的信息检索和查询应答方法。
设置
索引对于查找相关文档以有效回答用户查询至关重要。我们将利用 OpenAI 强大的嵌入模型将数据转换为向量表示。
首先,让我们设置我们的环境。我们需要安装两个关键的 Python 库:用于矢量数据库的 Qdrant 和用于无缝集成的 LangChain-Qdrant。在data_ingestion.ipynb笔记本中,运行以下命令:
!pip install qdrant-client langchain-qdrant langchain-openai
作为参考,这是我的项目目录结构的视图:

此设置将为我们的向量索引和相似性搜索功能提供基础。
从CSV文件创建LangChain文档
使用 Pandas 读取 CSV 文件后,我们将把每一行数据转换为 LangChain 文档。
from langchain_core.documents import Document
import pandas as pd现在让我们使用 Pandas 读取清理后的数据:
df = pd.read_csv('../data/cleaned_data.csv')
df.head()
从这里,我们现在可以继续创建 LangChain 文档,以下是执行此操作的代码:
documents = []for index, row in df.iterrows():document = Document(page_content=row["prepared_text"],metadata={"Disease": row["Disease"]})documents.append(document)len(documents)
文档UUID
我们上面创建的文档列表中的每个文档都将具有唯一的标识。让我们继续创建它们:
from uuid import uuid4
uuids = [str(uuid4()) for _ in range(len(documents))]连接到 Qdrant 云
现在我们已经准备好了文档,我们需要能够嵌入它们并将它们存储在我们的矢量数据库中,在本例中为 Qdrant Cloud。为此,我们首先需要连接到我们刚刚创建的 Qdrant Cloud 实例。
为此,我们需要以下代码块:
from qdrant_client import QdrantClient
from dotenv import load_dotenv
import os%load_ext dotenv
%dotenvqdrant_client = QdrantClient(api_key=os.getenv("QDRANT_API_KEY"),url=os.getenv("QDRANT_URL")
)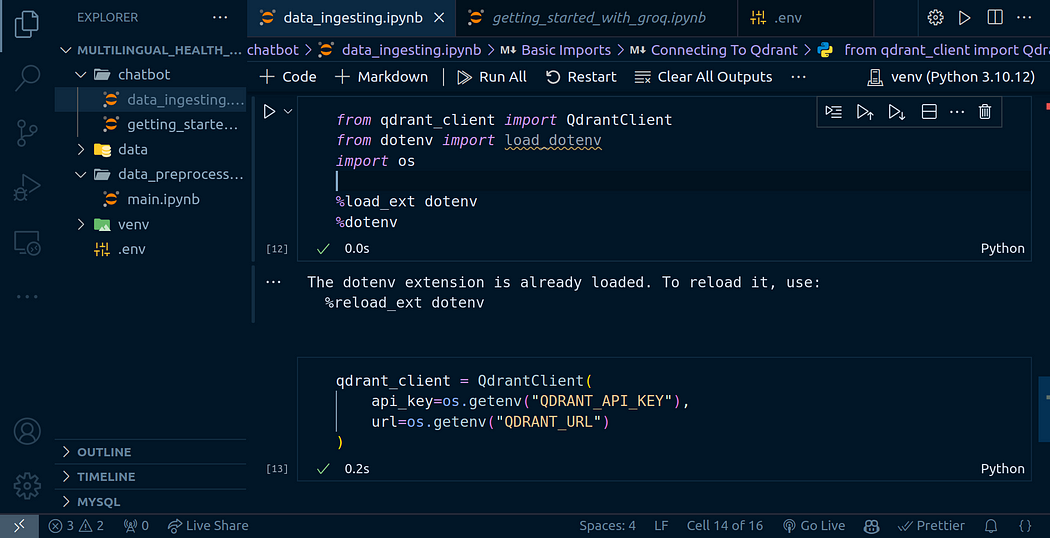
我们可以使用以下代码检查是否有任何现有集合:
qdrant_client.get_collections()
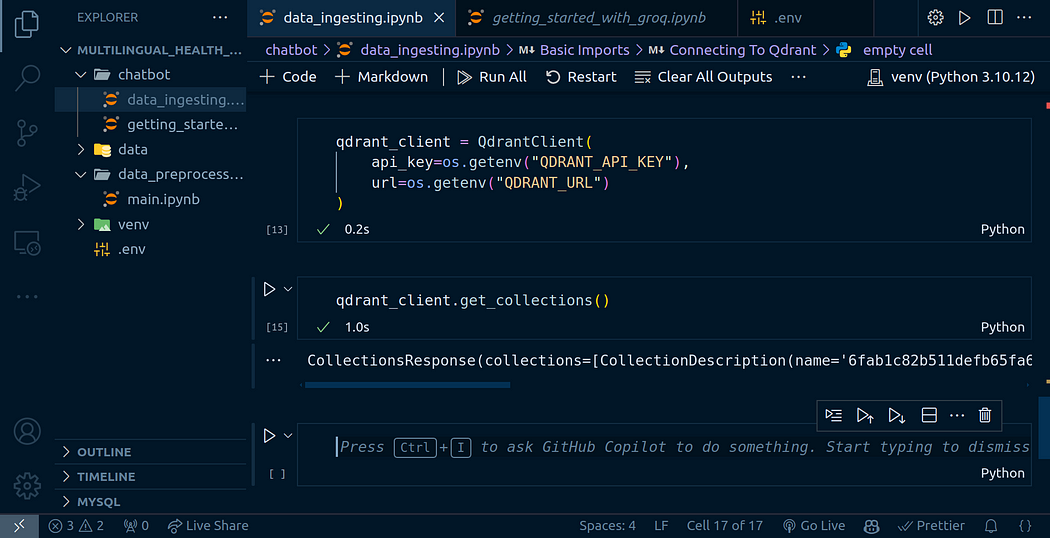
您可以从上图中看到,我已经有一些收藏品正在用于我在学校的一个项目。我们将为该项目创建一个新集合,如果您当前没有任何集合,请不要担心。
创建集合
要创建集合,我们需要以下代码块:
from qdrant_client.http.models import Distance, VectorParams
COLLECTION_NAME ="healthcare_collection"
现在,让我们使用上面的详细信息在 Qdrant 云上创建集合:
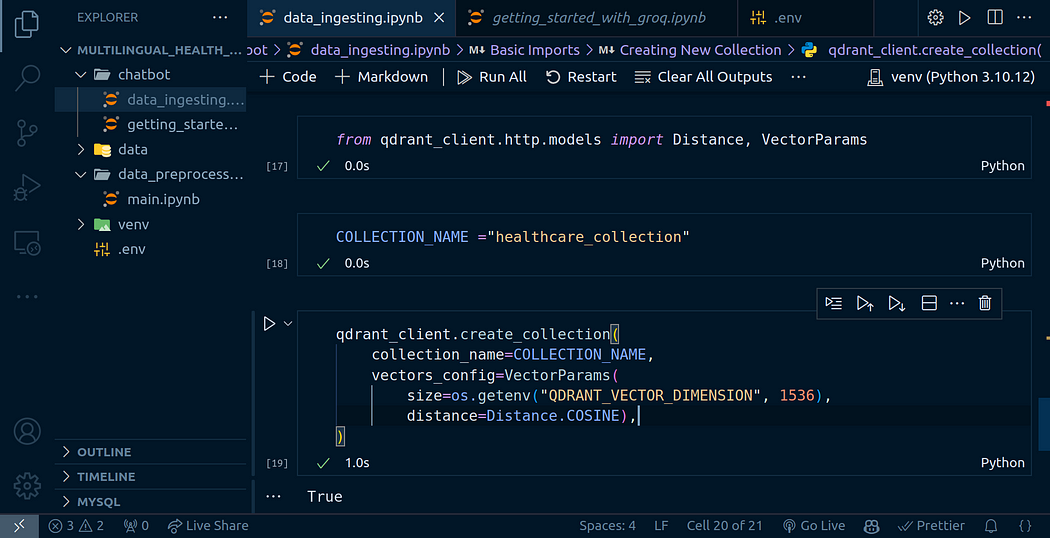
qdrant_client.create_collection(collection_name=COLLECTION_NAME,vectors_config=VectorParams(size=os.getenv("QDRANT_VECTOR_DIMENSION", 1536), distance=Distance.COSINE),
)
现在我们已经创建了集合,我们可以返回 Qdrant Cloud 仪表板并查看创建的“集合”。单击屏幕右上角的“打开仪表板”按钮。
这会将您重定向到一个页面并要求您提供身份验证详细信息;输入详细信息,您应该会看到如下所示的视图:
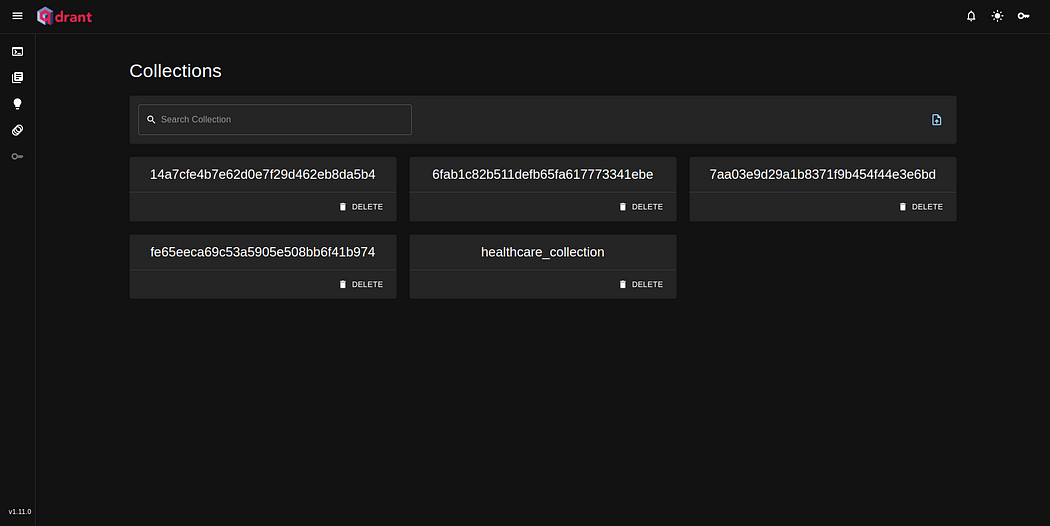
连接到矢量存储
现在让我们继续连接到这个集合。为此,我们将使用以下代码块。
首先,我们需要创建 OpenAI 嵌入模型实例。我们将使用text-embedding-3-small模型。
from langchain_qdrant import QdrantVectorStore
from langchain_openai import OpenAIEmbeddingsembedding_model = OpenAIEmbeddings(model=os.getenv("EMBEDDING_MODEL", default="text-embedding-3-small")
)from langchain_qdrant import RetrievalMode
QdrantVectorStore支持 3 种相似性搜索模式。它们可以在设置类时使用retrieval_mode参数进行配置。密集向量搜索(默认)
稀疏向量搜索
混合搜索
vector_store = QdrantVectorStore(client=qdrant_client,collection_name=COLLECTION_NAME,embedding=embedding_model,# retrieval_mode=RetrievalMode.DENSE
)如果您希望使用稀疏或混合搜索,则需要使用 SparseEmbeddings。
稀疏向量搜索
仅使用稀疏向量进行搜索,
retrieval_mode参数应设置为RetrievalMode.SPARSE。必须将使用任何稀疏嵌入提供程序的
SparseEmbeddings接口的实现作为sparse_embedding参数的值提供。
您可以在这里内容
在我们的例子中,我们将使用默认的DENSE检索模式。
插入记录/文档
现在,我们已准备好将最初创建的文档插入到 Qdrant Cloud Cluster 集合中。此过程称为“更新插入”。
vector_store.add_documents(documents=documents, ids=uuids)
add_documents方法将使用我们在创建向量存储集合时指定的 OpenAI 模型来创建嵌入。它还将使用我们最初创建的uuids唯一地标识每个文档。
这就是我们将数据更新插入到集群集合中所需的全部内容。
查询向量库
现在我们已经将数据嵌入到 Qdrant 云集合中并建立了索引,现在我们可以通过提出一些问题并查看返回的数据来继续对其执行一些查询。
query = "What is malaria?"
results = vector_store.similarity_search(query, k=2
)在这里,我指定要执行相似性搜索并返回与我的查询最接近的k 个文档。 k是一个变量,您可以为它设置任何值。只要记住它应该有意义;不要指定像 1000 这样荒谬的值。
默认情况下,您的文档将存储在以下有效负载结构中;例如:
print(results)
print(results[0].metadata)
print(results[0].page_content)for res in results:print(f"* {res.page_content} [{res.metadata}]")*疾病:疟疾描述:由疟原虫科原生动物寄生虫引起的传染病,可通过按蚊叮咬或通过受污染的针头或输血传播。恶性疟疾是最致命的类型。立即行动:咨询最近的医院 医疗建议:避免油腻食物 饮食指导:避免非蔬菜食品 长期管理:防止蚊子 [{'疾病': '疟疾', '_id': '1497e650–06e7–458c-a542– 9f8815e7303f', '_collection_name': 'healthcare_collection'}] *
疾病:登革热描述:由黄病毒(黄病毒属登革热病毒种)引起的一种急性传染病,通过伊蚊传播,特征为头痛、严重关节痛和皮疹。 — 也称为断骨热、登革热。立即行动:喝木瓜叶汁 医疗建议:避免油腻辛辣食物 饮食指导:远离蚊子 长期管理:保持水分 [{'疾病': '登革热', '_id': '8320500c-c4d2–4143–9263– 83fbd5e4170b', '_collection_name': 'healthcare_collection'}]
您可以看到我们拥有可以用来回答用户问题的正确数据。
我们还可以应用元数据过滤,您可以通过阅读此处找到更多信息
完成此部分后,我们就可以继续构建多语言聊天机器人。
构建多语言人工智能:构建我们最初的多语言聊天机器人框架
对于我们最初的设计,这就是我一直在考虑实现的。我现在只想大声思考。在这里,看看这张图:
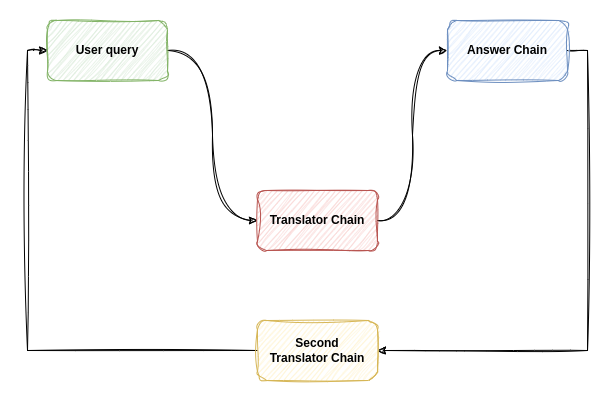
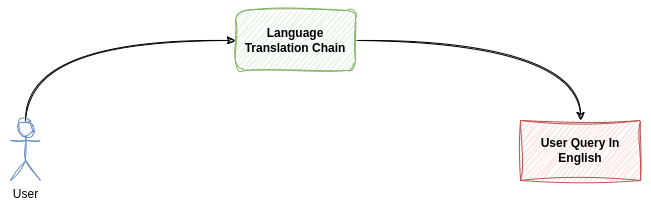
- 用户查询:这是用户用其首选语言输入问题或请求的起点。
- 翻译器链:用户的查询首先发送到该组件,该组件将输入从用户的语言翻译为聊天机器人的主要语言(可能是英语)。
- 答案链:翻译后,查询将由答案链处理。该组件负责理解问题并以聊天机器人的主要语言生成适当的响应。
- 第二个翻译链:来自答案链的响应随后被发送到最后一个组件,该组件将答案翻译回用户的原始语言。
该过程形成一个完整的循环:
- 它从用户使用其语言的查询开始
- 将其翻译为机器人的主要语言
- 处理并回答查询
- 将答案翻译回用户的语言
- 将翻译后的响应返回给用户
这种架构允许聊天机器人维护单一核心语言来处理和回答查询,同时为用户提供多语言界面。它将语言翻译任务与核心问答功能有效地分开,使系统更加模块化,并且更容易维护或更新其他语言。
我们需要翻译器的原因是,嵌入是从英语文本生成的,用户可以使用任何选择的语言。那么,我们如何确保我们能够创建与我们从英语文本中创建的嵌入具有相似含义的嵌入呢?这就是为什么我们需要适当的翻译层。希望这对您有意义。
让我们继续实现这个架构。
获取 Groq API 密钥的访问权限
要开始使用 Llama-3.1,我们需要首先创建一个 Groq 帐户并访问 Groq API 密钥。
什么是 Groq?
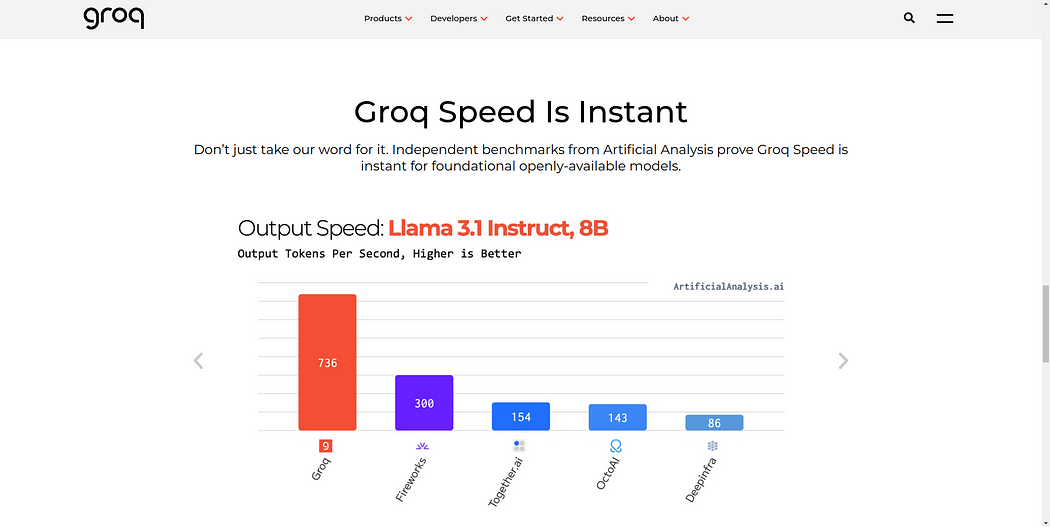
Groq 是一家成立于 2016 年的创新型人工智能公司,专注于高速人工智能推理解决方案。他们的突破性语言处理单元 (LPU) 技术专为人工智能推理和语言处理而设计,提供前所未有的速度、经济性和能源效率。与传统 GPU 不同,Groq 的 LPU 代表了 AI 硬件架构的根本性转变。通过在云和本地环境中进行快速人工智能推理来提供即时智能,Groq 正在推动跨行业的下一波人工智能创新和生产力浪潮。
如果您不想使用 Groq,另一个选择是在本地下载 Llama-3.1 并从那里运行它。我没有足够的计算能力来演示这个,所以我们将坚持使用 Groq API。
您可以前往他们的官方网站并创建一个帐户。创建帐户后,前往 GroqCloud 仪表板并在 API 密钥部分下生成 API 密钥。

- 将以下内容添加到您的
.env文件中。
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#836c28">GROQ_API_KEY</span>=your_groq_api_key</span></span>将your_actual_api_key_here替换为您复制的 API 密钥。
- 保存文件。
重要提示:
- 请勿在 API 密钥周围使用引号。
- 确保等号前后没有空格。
- 确保此文件的安全,切勿将其提交到 Git 等版本控制系统。将
.env添加到您的.gitignore文件中,以防止意外共享您的 API 密钥。 - 在您的代码中,您将使用
python-dotenv之类的库来加载此环境变量。
请记住,保证 API 密钥的安全至关重要。切勿公开共享它或将其直接包含在您的代码中。
Groq LangChain 集成
LangChain 是一个强大的 Python LLM编排框架,可以与 Groq 无缝集成,以释放非凡的功能。对于那些刚接触 LangChain 的人,我创建了全面的资源,包括介绍性文章和YouTube 视频教程。
要探索 Groq-LangChain 集成,只需导航至 GroqCloud 文档下的“LangChain 集成”部分,该部分将引导您访问官方 LangChain 文档以获取详细的实施说明。
您可以使用此处的链接直接访问 LangChain Groq 集成文档页面。
LangChain-Grop集成包的安装
我们首先需要创建一个新的笔记本来覆盖 LangChain Groq 集成。我创建了一个名为chatbot的新文件夹,在该文件夹内我有一个名为 getting_started_with_groq.ipynb 。这是我的新目录的树结构:
要安装 LangChain-Groq 集成包,请使用官方文档中提到的此命令。
!pip install -qU langchain-groq python-dotenv
我们还需要安装python-dotenv包来帮助我们读取.env文件中的环境变量。还记得我们在那里存储了什么值吗?
加载环境变量
从上面的段落中,我们讨论了 Groq API 密钥。我们将其存储在安全的位置。我们如何将其读入我们的代码中?
要将环境变量读入我们的代码中,我们需要使用此命令,在我们正在处理的同一笔记本中创建一个新单元并运行此代码块:
from dotenv import load_dotenv%load_ext dotenv
%dotenv
使用Llama-3.1 70B型号
现在我们已经奠定了基础,是时候利用尖端Llama-3.1 模型的力量了! 🚀
让我们深入了解旅程中令人兴奋的部分。在您当前的笔记本中,创建一个新单元并执行以下代码片段以实现 Llama-3.1:
from langchain_groq import ChatGroqllm = ChatGroq(model="llama-3.1-70b-versatile",temperature=0,max_tokens=None,timeout=None,max_retries=2,
)为了测试一下,我将使用 LangChain 官方文档中的这段代码:
messages = [("system","You are a helpful assistant that translates English to French. Translate the user sentence.",),("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg
图
构建语言翻译链
我们的医疗保健都是多语言聊天机器人,这意味着它可以理解多种语言。因此,我们需要一个将用户输入转换为一种通用语言(在本例中为英语)的链。
图片胜过他们所说的一千个字,所以这就是我想做的。
但为什么我们要把用户输入翻译成英语呢?原因是,我们的嵌入是根据英语文本语料库创建的。
首先,安装以下依赖项和软件包:
!pip install langchain langchain-community
完成此操作后,引入以下导入:
from langchain.prompts import (ChatPromptTemplate,HumanMessagePromptTemplate,PromptTemplate,SystemMessagePromptTemplate,
)
from pydantic import BaseModel
from langchain_core.output_parsers import JsonOutputParser创建语言翻译解析器
为了提高翻译链的性能,我们正在深入研究结构化输出的世界。当我们可以精确地协调时,为什么要满足于混乱呢?让我们创建一个解析器,充当 AI 的个人造型师,确保每个输出都经过精心设计,以准确呈现我们想要的字段和数据类型。
看吧,这些代码将把我们原始的人工智能思考转化为结构化的黄金:
class TranslationParser(BaseModel):source_language: strtarget_language: strtarget_text: strtranslation_parser = JsonOutputParser(pydantic_object=TranslationParser)这个强大的解析器是您实现以下目标的关键:
- 一致、干净的数据结构
- 易于操作的输出以进行进一步处理
- 增强人类和机器的可读性
通过实现这个解析器,我们不仅仅是翻译——我们还将信息雕刻成最完美的形式。准备好见证结构化人工智能输出的美丽吧!
我们的翻译链管道的快速工程
即时工程是为 Llama-3.1 等 AI 模型制作精确指令以生成最佳输出的艺术和科学。这是人工智能开发中的一项关键技能,涉及精心设计文本提示来指导模型的响应。通过微调这些提示,开发人员可以显着提高人工智能生成内容的准确性、相关性和实用性。
在我们的项目中,我们利用即时工程来优化我们的翻译链,确保结构化输出,并根据我们的特定需求定制 Llama-3.1 的响应。掌握这项技术使我们能够释放人工智能的全部潜力,将强大的语言模型转变为用于复杂语言任务的微调工具。
首先,创建一个新单元并运行以下代码块:
language_translation = """
You are a highly skilled assistant specializing in language translation.
Your task is to accurately translate the given text into English while
preserving the original meaning, tone, and context. Please translate the user's sentence to English.User's sentence: {user_sentence}Your final output should be in the following format: {format_instructions}
"""language_translation_prompt = SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=["user_sentence", "format_instructions"],template=language_translation,partial_variables={"format_instructions": translation_parser.get_format_instructions()},)
)human_prompt = HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=["user_sentence"], template="Translate this text to English. Text: {user_sentence}")
)messages = [language_translation_prompt, human_prompt]translation_chain_promt = ChatPromptTemplate(messages=messages,input_variables=["user_sentence"]
)将它们放在一起构建链:
first_layer_translation_chain = translation_chain_promt | llm | translation_parser
测试我们的翻译链:
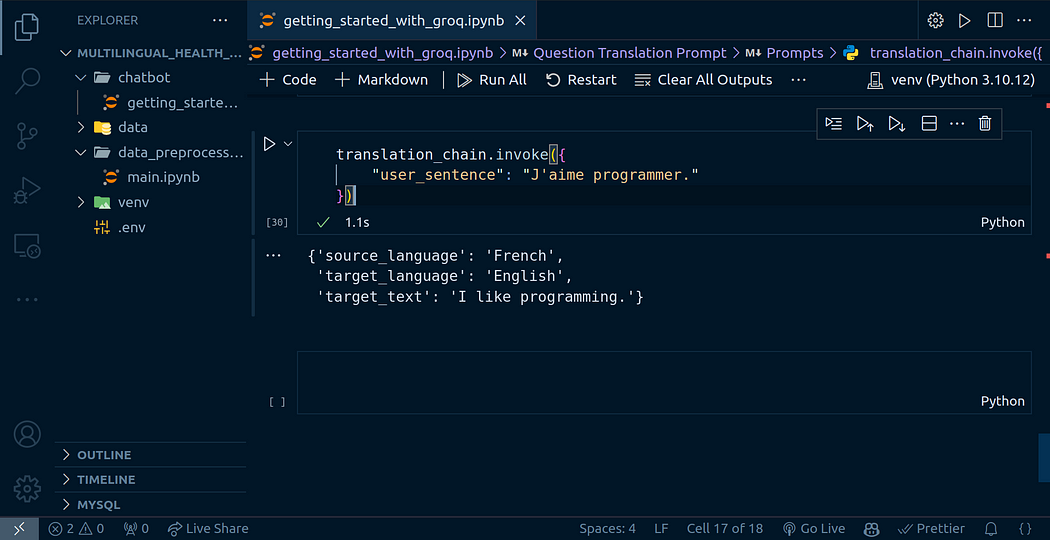
first_layer_translation_chain.invoke({"user_sentence": "J'aime programmer."
})
一旦我们翻译好了,我们就能回答各种语言的问题了!
信息检索
现在,让我们继续实现信息检索层。该层将接收LLM支持的任何语言的翻译后的用户查询,并执行相似性搜索,以给出可用于回答用户问题的最相似的文档、最相关的文档。
def information_retriever(question: str) -> str:"""Search and retrieve information from the Qdrant vector store."""# Filter the search results based on the product nameunstructured_data_results = vector_store.similarity_search(query=query,k=3)return unstructured_data_resultsinformation_retriever("What is malaria?")
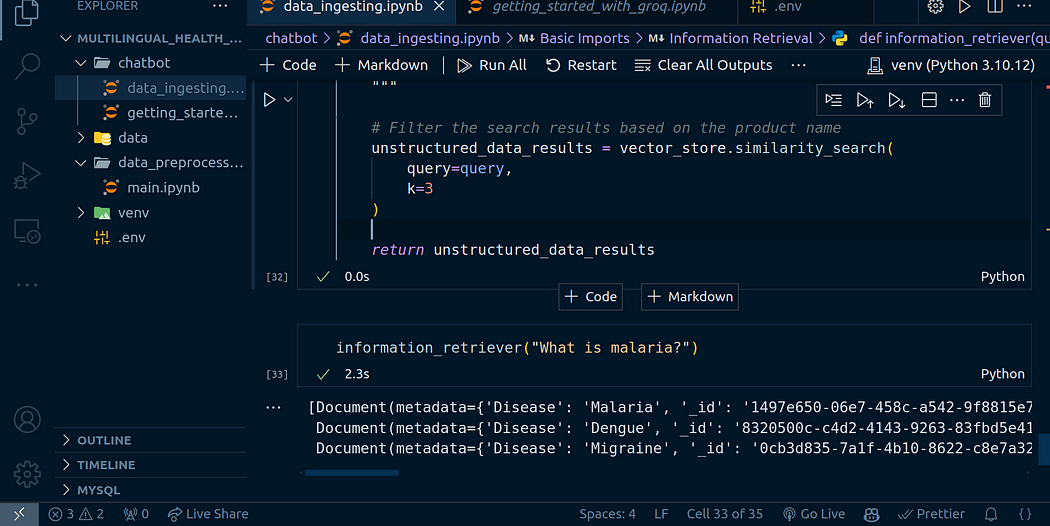
聊天机器人
检索最相关的文档,这将从 Qdrant 矢量数据库检索到的信息返回给我们。
有了这些信息,我们需要创建一个功能,可以将检索到的信息传递给聊天机器人,以使用检索到的信息作为上下文以正确的方式回答我们的问题。
为此,将使用LangChain表达式语言来构建LLM链。
from langchain_core.runnables import (RunnableParallel,RunnablePassthrough,
)bot_chat_template = """
You are an AI healthcare chatbot with extensive knowledge of medical conditions and diseases. Your task is to provide accurate, concise answers to user questions based solely on the given context.Context:
{context}Question:
{question}Instructions:
- Respond using natural language, ensuring your answer is clear and to the point.
- After your answer, explicitly state the context used without modification of the information. You are only to modify the datatype.
- If no context is provided, simply reply with: "No context was provided."Answer:
Context Used:
"""from pydantic import Field, BaseModel
from typing import List, Union
from langchain.prompts import ChatPromptTemplate
from langchain_groq import ChatGroqclass ResponseFormat(BaseModel):"""Identifying information about Products."""answer: str = Field(...,description="Your response to the user query.")sources: List[Union[str| Document]] = Field(...,description="The sources, contexts used to generate the response.")llm = ChatGroq(model="llama-3.1-70b-versatile",temperature=0,max_tokens=None,timeout=None,max_retries=2,
)bot_chat_prompt = ChatPromptTemplate.from_template(bot_chat_template)chat_chain = (RunnableParallel({"context": information_retriever,"question": RunnablePassthrough(),})| bot_chat_prompt| llm.with_structured_output(ResponseFormat)
) response = chat_chain.invoke("What is malaria?")
response.answer
机器人响应:
“疟疾是一种由疟原虫家族的原生动物寄生虫引起的传染病,可以通过按蚊叮咬或通过受污染的针头或输血传播。恶性疟疾是最致命的类型。
我们还可以通过以下方式检索生成答案的来源:
response.sources
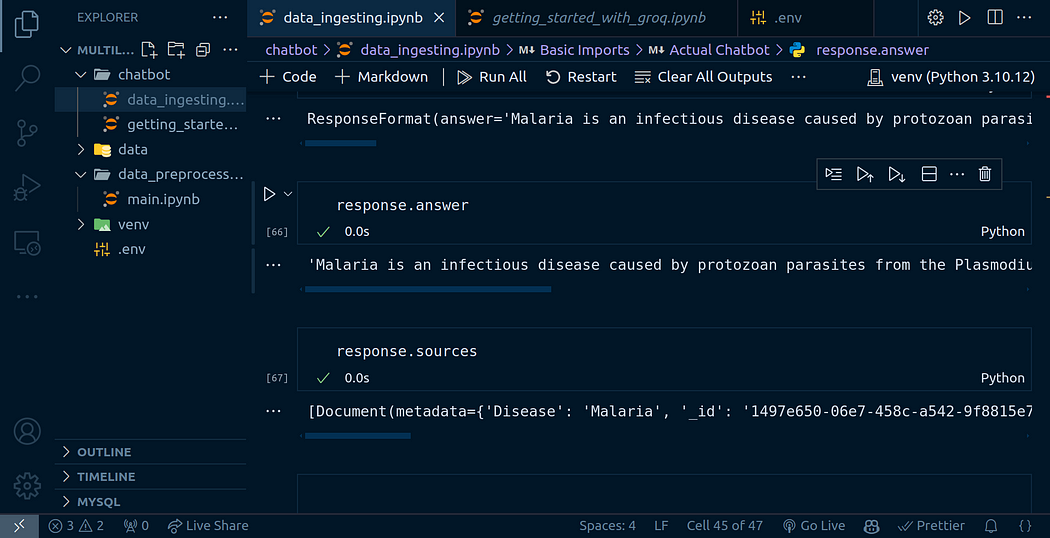
构建第二层翻译器
最后,我们必须将生成的答案翻译回用户查询的原始语言。
second_layer_language_translation = """
You are a highly skilled assistant specializing in language translation.
Your task is to accurately translate the given text into the specified target language while
preserving the original meaning, tone, and context.User's sentence: {sentence}
Souce Language: English
Target Language: {target_language}Your final output should be in the following format: {format_instructions}
"""second_language_translation_prompt = SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=["sentence", "target_language", "format_instructions"],template=second_layer_language_translation,partial_variables={"format_instructions": translation_parser.get_format_instructions()},)
)human_prompt = HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=["user_sentence"], template="Translate this text to the specified language. Text: {user_sentence}")
)messages = [second_language_translation_prompt, human_prompt]second_layer_translation_chain_promt = ChatPromptTemplate(messages=messages,input_variables=["user_sentence"]
)second_layer_translation_chain = second_layer_translation_chain_promt | llm | translation_parser
response = second_layer_translation_chain.invoke({"sentence": response.answer,"target_language": "French"
})response{'source_language': '英语',
'target_language': '法语',
'target_text': '疟疾是一种由疟原虫科原生动物寄生虫引起的传染病,可通过按蚊叮咬或通过受污染的针头或输血传播。恶性疟疾是最致命的类型。'}
把它们放在一起
带你回到我们最初的多语言聊天机器人设计,看看它:
我们已经成功构建了应用程序的所有子模块。我们剩下要做的就是把它们放在一起。我创建了一个可以用来实现此目的的函数:
def multilingual_chatbot(question: str) -> dict:"""Multilingual chatbot that answers user questions in multiple languages."""# Translate the user question to Englishtranslated_question = first_layer_translation_chain.invoke({"user_sentence": question})# Retrieve information based on the user questionresponse = chat_chain.invoke(translated_question.get("target_text"))# Translate the response to the specified target languagetranslated_response = second_layer_translation_chain.invoke({"sentence": response.answer,"target_language": translated_question.get("source_language")})return {"question": translated_question, "response": translated_response, "sources": response.sources}我要用斯瓦希里语(一种主要来自东非的语言)向多语言健康聊天机器人询问一个问题:
ml_response = multilingual_chatbot("Malaria ni nini?")
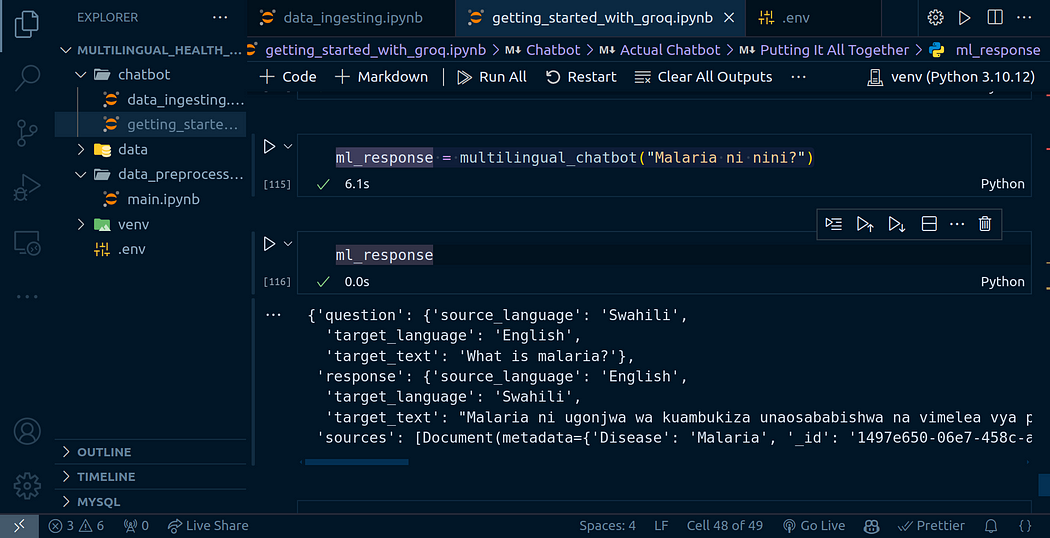
{'question': {'source_language': '斯瓦希里语',
'target_language': '英语',
'target_text': '什么是疟疾?'},
'response': {'source_language': '英语',
'target_language': '斯瓦希里语',
'target_text':“疟疾是一种由疟原虫科原生动物寄生虫引起的传染病,可通过按蚊叮咬、注射或血液传播。恶性疟疾是最致命的类型。”},
'sources': [Document(metadata={'Disease': '疟疾', '_id': '1497e650–06e7–458c-a542–9f8815e7303f', '_collection_name': 'healthcare_collection'}, page_content='疾病:疟疾描述:由疟原虫科原生动物寄生虫引起的传染病,可通过按蚊叮咬或受污染的针头或输血传播,是最致命的类型。 立即采取措施:咨询最近的医院 医疗建议:避免使用油性疟疾。 food 饮食指导:避免非素食食品 长期管理:驱蚊')]}
机器人的答案是孤立的:
“疟疾是一种由疟原虫家族的原生动物寄生虫引起的传染病,可通过按蚊叮咬、注射或血液传播。恶性疟疾是最致命的类型。”
结论
恭喜您完成这次旅程!您现在已经掌握了使用 Qdrant、LangChain 和 OpenAI 构建尖端多语言聊天机器人的艺术。您新发现的技能包括:
- 将数据提取到 Qdrant 强大的矢量存储中。
- 创建和管理 Qdrant 集合。
- 执行精确的相似性搜索。
- 打造复杂的 LangChain 工作流程。
- 利用 Groq 闪电般快速的基础设施来发挥 Llama-3.1 的潜力。
这个坚实的基础为无数创新项目奠定了基础。您学到的工具和技术不仅仅是理论上的,它们是现实世界中可以改变行业的人工智能应用程序的构建模块。
当您站在这个激动人心的十字路口时,我渴望听到您现在有能力将其变为现实的突破性想法。你的下一个大项目是什么?分享您的愿景,让我们探索这些强大的技术如何将您的概念变成现实。
请记住,人工智能创新之旅仍在继续。不断尝试,不断学习,最重要的是,不断构建。人工智能的未来掌握在你的手中——接下来你会创造什么?