MySQL中NULL值是否会影响索引的使用
为何写这一篇文章
🐭🐭在面试的时候被问到NULL值是否会走索引的时候,感到有点不理解,于是事后就有了这篇文章
问题:
为name建立索引,name可以为空select * from user where name is null是否会使用索引?
生活会拷打每一个做事不认真的人😭
索引的结构
详细的可以参照我的上一篇文章深入浅出MySQL,里面有关于索引的详细介绍
在InnoDB引擎中,索引分为聚簇索引和二级索引,对于二级索引
,在这个场景下我们要考虑的就是是否会为NULL建立索引和如果列中存在NULL值,是否会走索引去查找这个NULL
访问方法
访问方法是MySQL来实际访问数据的执行方法大致分为:
- 全表扫描
- 使用索引扫
测试表
CREATE TABLE user ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) NOT NULL, `age` int(11) DEFAULT NULL, `sex` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8; INSERT INTO user (`id`, `name`, `age`, `sex`) VALUES ('1', 'Bob', '20', '男');
INSERT INTO user (`id`, `name`, `age`, `sex`) VALUES ('2', 'Jack', '20', '男');
INSERT INTO user (`id`, `name`, `age`, `sex`) VALUES ('3', 'Tony', '20', '男');
INSERT INTO user (`id`, `name`, `age`, `sex`) VALUES ('4', 'Alan', '20', '男'); CREATE UNIQUE INDEX indexName ON user(name(20));
# 为age建立索引
CREATE INDEX indexAge ON user(age);const
通过主键或者唯一二级索引列来定位一条记录的访问方法explain select * from user where id = 1;
解决如下:

通过type我们可以看见访问方法是const
ref
如果二级索引列不是唯一的,那么就使用二级索引的值去匹配,之后再回表
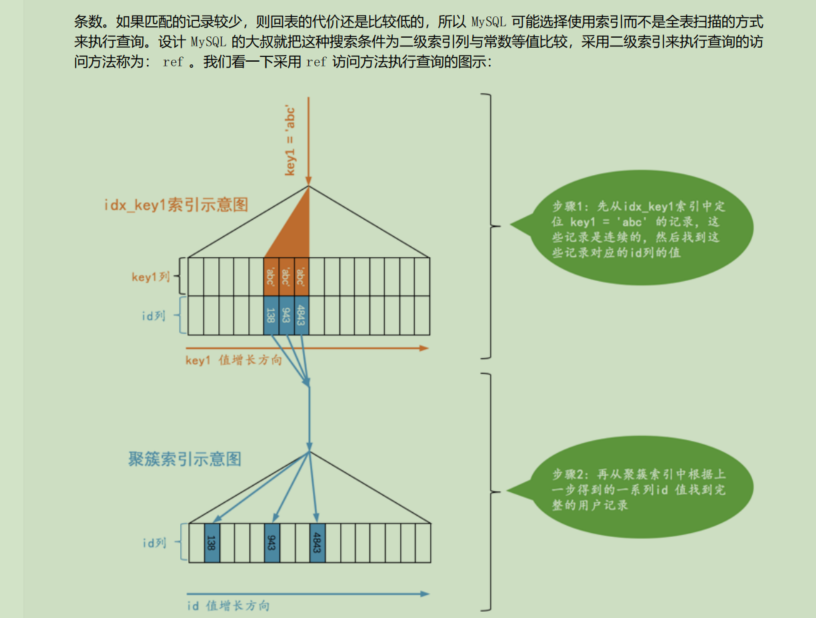
explain select * from user where age = 20;

如图使用的是ref方法
二级索引列值为NULL时:
二级索引列对NULL值的数量时不限制的,所以key is NULL最多使用的是ref,而不是const
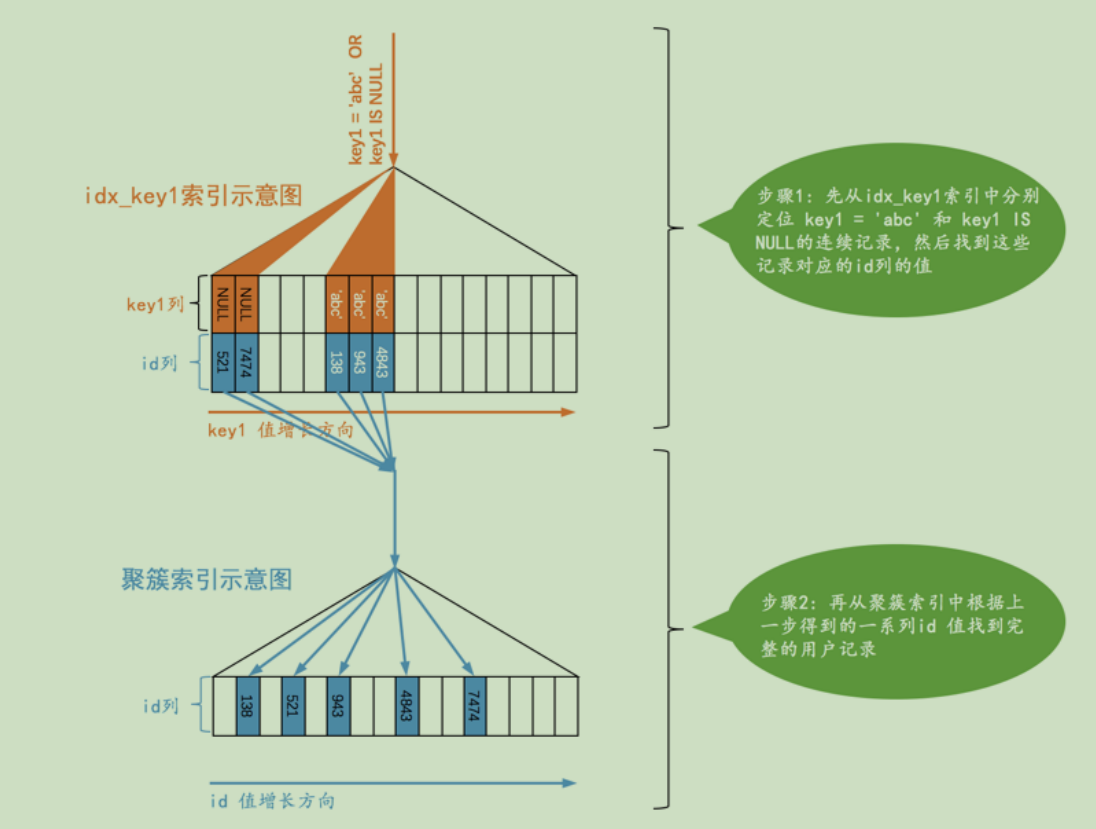
ref_or_null
有时候我们需要找出二级索引等于常数和为NULL的记录一同找出explain select * from user where age = 20 or age is null ;

执行的流程:
如图,NULL是放在每一层中最左侧的,并且是连在一起的
range
使用索引进行范围访问,可以是聚簇索引,也可以是二级索引。explain select * from user where age > 11 and age <= 20;

index
遍历二级索引记录的执行方式,常常出现在查询列和条件都包含在索引中,不需要回表,所以直接遍历即可
all
全表扫描
NULL在二级索引中的位置
通过查询资料,发现如果索引列允许NULL值,那么NULL在二级索引中是被当作最小值放在树的每一层的最左侧的,也就是NULL值会被当成索引列的数据使用的,所以NULL值匹配是可能会走索引的
- 如果在索引列上使用IS NULL或IS NOT NULL,MySQL通常会走索引
explain select * from user where age is null; explain select * from user where age is not null; - 符合索引,如果签到列不为NULL,后续的列也是可以走索引的