目录
一、什么是缓存
二、缓存更新策略
2.1. 缓存主动更新策略
2.1.1. Cache Aside模式(主流)
2.1.2. Read/Write Through模式
2.1.3. Write Behind模式
2.1.4. 总结
三、缓存穿透
四、缓存雪崩
五、缓存击穿
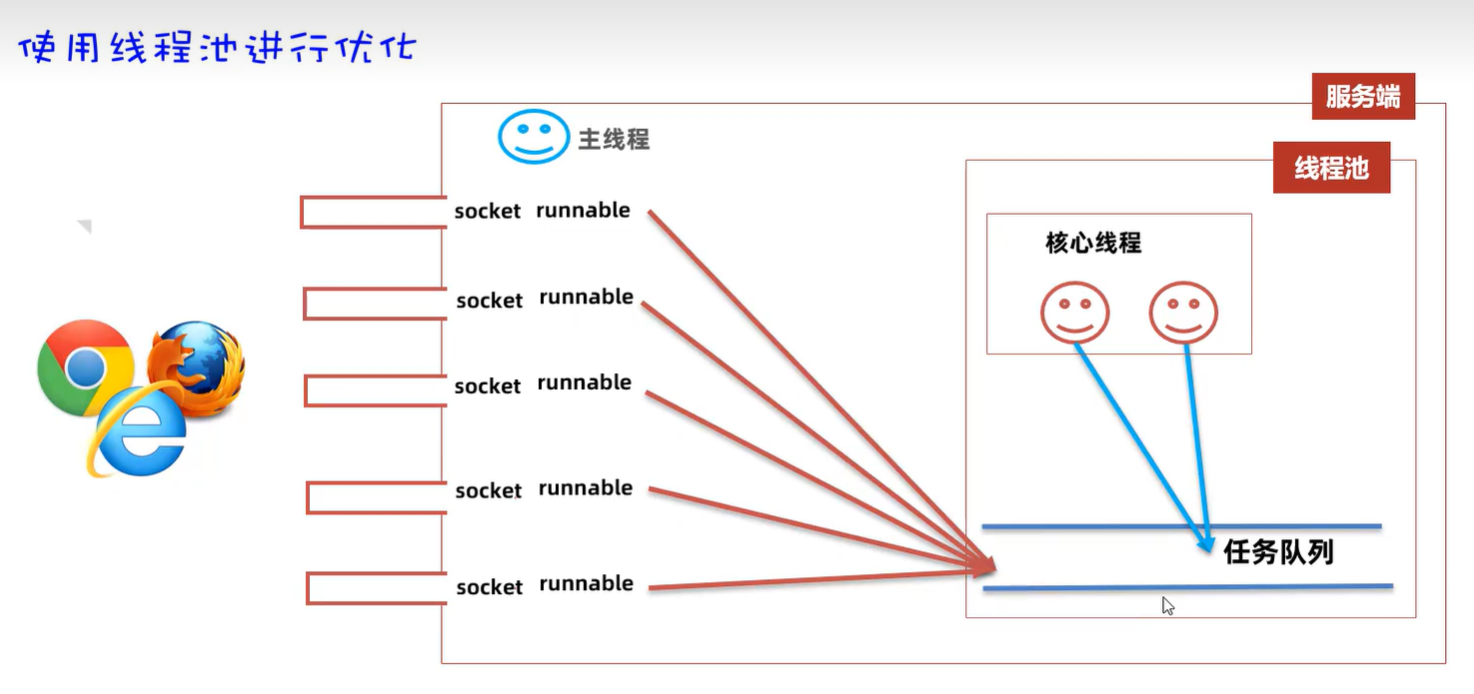
本文中的图片内容部分来源于黑马程序员教程案例
一、什么是缓存
缓存是一种用于临时存储数据的技术或机制,旨在提高数据访问速度和系统性能。 缓存通常位于计算机系统内部或附近,可以是硬件、软件或两者的结合体。例如,Web浏览器可以将最常访问的网页内容缓存在本地,以便下次访问时无需从远程服务器重新下载。
缓存的作用和原理在于利用程序局部性原理,将频繁访问的数据存储在高速存储器中,如SRAM或DRAM,以便快速访问。当硬件需要读取数据时,首先在缓存中查找,如果找到则直接执行,否则从内存中查找。由于缓存的运行速度比内存快得多,因此缓存的作用是帮助硬件更快地运行。
缓存可以根据不同的分类标准进行分类。例如,根据存储位置和用途的不同,可以分为CPU缓存、硬盘缓存、内存缓存等。CPU缓存包括L1、L2和L3缓存,硬盘缓存用于提高数据传输速度。此外,还有HTTP缓存、浏览器缓存等。
虽然缓存可以提高系统性能,但也会引入一定的数据一致性问题。因为缓存中的数据可能会与后端数据源(如数据库)存在不一致的情况,所以在使用缓存时需要考虑数据的更新和缓存的过期策略,以保证数据的一致性。
二、缓存更新策略

2.1. 缓存主动更新策略
指在更新数据库中的数据时,如何同步更新缓存中的数据,以保证数据的一致性。常见的缓存更新策略包括Cache Aside模式、Read/Write Through模式和Write Behind模式。

2.1.1. Cache Aside模式(主流)
Cache Aside模式是最常用的缓存更新策略,其中又分为两种:
1. 先删除缓存,再操作数据库
2. 先操作数据库,再删除缓存(主流),其操作步骤如下:
- 先更新数据库中的数据。
- 然后删除缓存中的数据,或者让缓存失效。
- 当下次查询时,如果缓存失效,则重新从数据库中读取数据并更新缓存。
注:由于操作缓存和数据库的话存在线程安全性问题,相较于先删除缓存再操作数据库而言,先操作数据库再删除缓存对于产生线程安全性的概率较低,因为写缓存的速度比更新数据库要快很多:线程1在查询缓存未命中后继续查询数据库时,线程2进来更新数据库,绝大部分情况下线程2更新数据库期间,线程1已经完成了缓存的写入。

2.1.2. Read/Write Through模式
Read/Write Through模式将缓存和数据库整合为一个服务,由服务来维护一致性。操作步骤如下:
- 查询操作直接从缓存中读取数据。
- 如果缓存中不存在数据,则直接从数据库中读取并返回给用户,同时将数据写入缓存。
2.1.3. Write Behind模式
Write Behind模式由其他线程异步地将缓存数据持久化到数据库,保证最终一致性。操作步骤如下:
- 更新操作只更新缓存。
- 由其他线程异步地将缓存数据写入数据库。
2.1.4. 总结
不同策略的优缺点
Cache Aside模式的优点是简单易实现,但存在数据不一致的风险。Read/Write Through模式的优点是数据一致性高,但性能较低。Write Behind模式的优点是最终一致性,但需要额外的线程管理。
不同场景下的适用性
Cache Aside模式适用于读多写少的场景,简单高效。Read/Write Through模式适用于对数据一致性要求高的场景。Write Behind模式适用于写操作较少,可以容忍最终一致性的场景。
缓存更新策略的最佳实践方案
1. 低一致性需求:使用Redis自带的内存淘汰机制
2. 高一致性需求:主动更新,并以超时剔除作为兜底方案
读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,设定超时时间

写操作:
- 先写数据库,然后再删除缓存
- 要确保数据库与缓存操作的原子性

整个写操作的逻辑,我们要确保事务性,如在单体的Spring的JavaWeb项目业务代码的Service实现层添加@Transactional注解,分布式的项目中可以通过TTC模式来控制,当比如删除Redis缓存出现异常,直接回滚数据库的写操作。
三、缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会到数据库。
常见的解决方案有两种:
1. 缓存空对象:
- 优点:实现简单,维护方便
- 缺点:额外的内存消耗以及可能造成短期的不一致
2. 布隆过滤器
- 优点:内存占用较少,没有多余key
- 缺点:实现复杂、存在误判可能
3. 参数校验过滤不合法请求
通过对用户输入的参数进行校验,例如检查ID的格式是否合法,如果不合法则直接拒绝请求。这种方法可以过滤掉一部分恶意伪造的用户请求,减少对数据库的压力。
4. 使用分布式锁
在缓存未命中时,通过分布式锁控制只有一个请求去查询数据库,其他请求等待锁释放。这样可以防止多个请求同时查询数据库,减轻数据库的压力。
5. 服务降级和限流
在面对大量的恶意请求时,可以通过服务降级或限流的方式来保护后端服务。限流可以限制到达数据库的请求数量,避免数据库压力过大。

四、缓存雪崩
缓存雪崩是指由于缓存中大量数据同时失效或缓存服务器故障,导致大量请求直接打到数据库上,引发数据库压力激增,可能导致整个系统崩溃的现象。 缓存雪崩通常由于缓存的过期策略不当或缓存服务器故障导致。例如,如果大量的缓存数据设置为在同一时间点过期,或者缓存服务器出现问题无法提供服务,所有的请求将直接访问后端存储系统,导致后端系统瞬时承受巨大的负载压力

解决方案:
- 给不同的key的TTL失效时间设置随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
五、缓存击穿
缓存击穿是指当一个缓存中的热点数据过期或被删除后,大量并发请求同时到达,导致这些请求直接穿透缓存访问数据库,从而增加数据库的负载。 这种情况通常发生在热点数据过期或删除的瞬间,导致短时间内大量请求无法通过缓存获取数据,直接访问数据库,造成数据库负载急剧增加。
缓存击穿的具体场景包括:
- 热点数据过期:当缓存中的热点数据过期时,大量请求会同时查询后端数据库,导致数据库负载增加。
- 第一次请求:对于一个之前从未被请求过的数据,当它第一次被请求时,缓存中没有该数据,导致请求穿透到后端存储。
解决缓存击穿的方法包括:
- 设置热点数据永不过期:将热点数据的缓存过期时间设置为较长的时间,甚至是永不过期。这种方法可以避免缓存击穿,但可能导致数据不够及时和准确。
- 使用互斥锁:在数据失效时,通过设置互斥锁来保护数据库访问过程。如果某个请求已经获取到了锁,其他请求需要等待,直到获取到锁为止。这种方法可以避免大量并发请求同时访问数据库,但可能导致并发性能下降和请求等待时间增加

注意:这两种方案没有孰优孰劣,在实际项目中,我们要针对业务场景和需求,权衡自身是更注重可用性还是一致性来做选择。