前言
随着手app的发展逐渐强大,我们手机应用每天的生活也是非常的多。那我们怎么知道他的数据是怎么形成的,通过电脑端如何爬取。相信大家也有这样的问题。下面我将讲解这些操作流程。
一、操作流程
首先我们要有
- fidder4
- 夜神模拟器
- pycharm
- python3.0或以上版本
二、fidder4抓包
1.fidder配置
首先我们先下载fidder,
打开Fiddler,点击Tools => Options 打开配置选项,切换到第二个标签页HTTPS,先在这里打勾
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
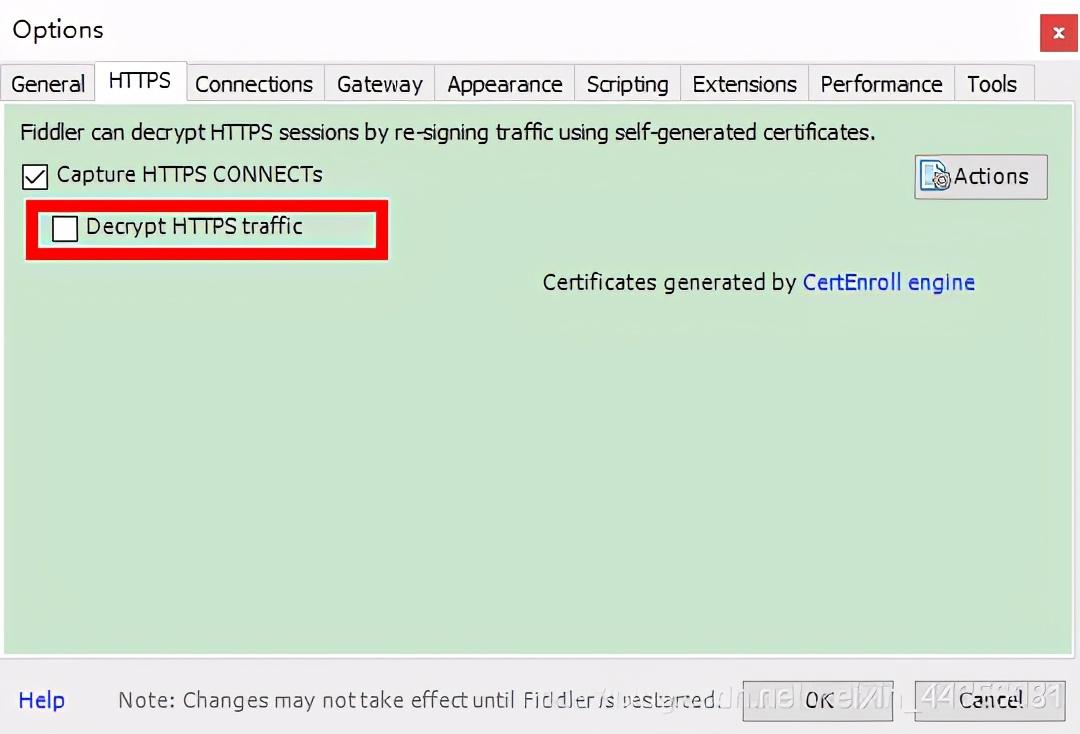
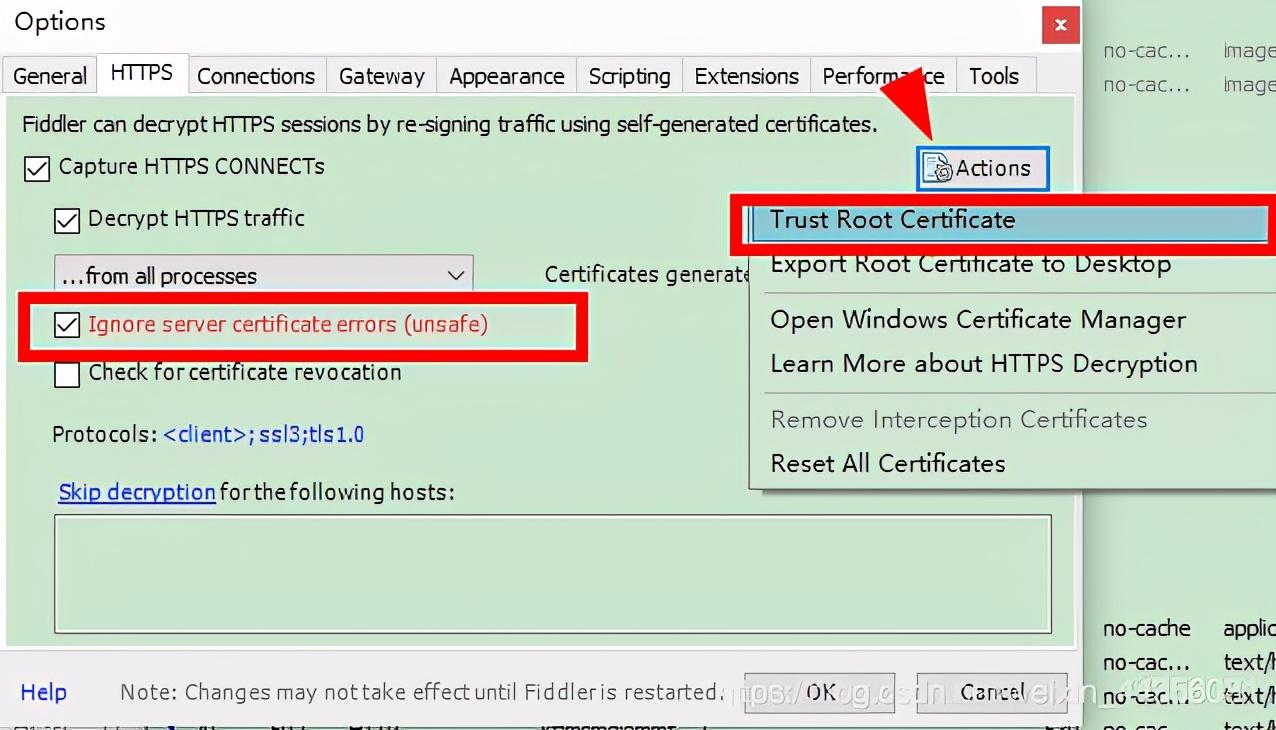
然后就是点下面如图所示的单选框,点击Actions,运行第一个Trust Root Certificate。后面会有一个框,记得点击确定。
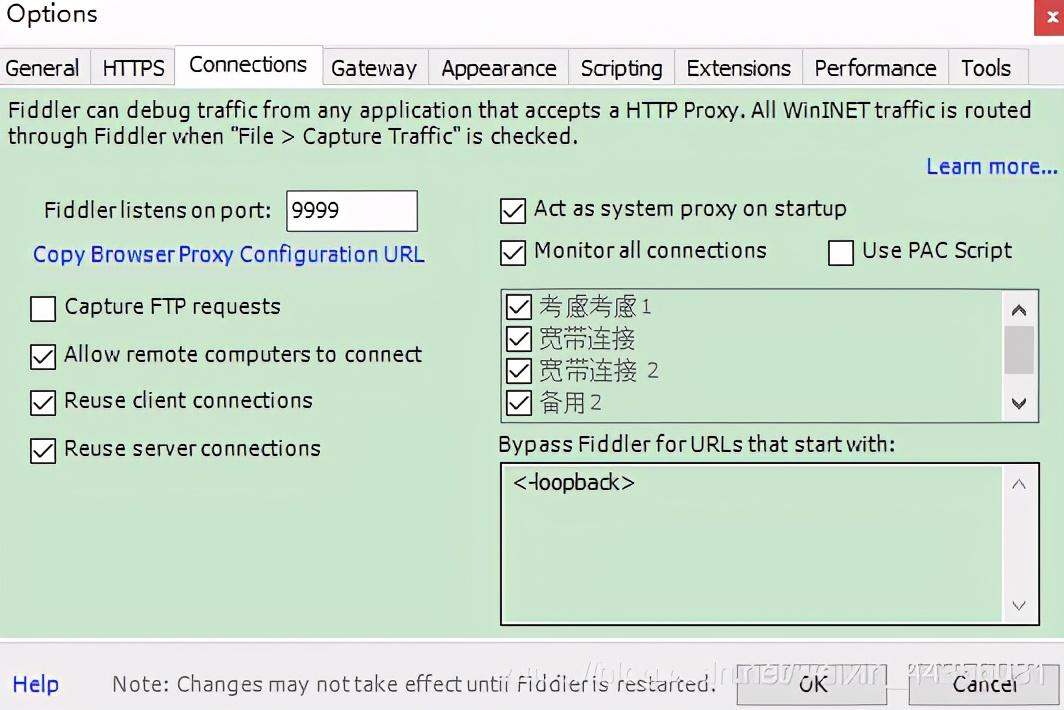
打开Fiddler,点击Tools => Options… 打开配置选项,切换到第三个标签页Connections,修改如图所示的地方,端口号可任意修改,这里使用我自定的9999,请记住自己设置的端口号,后面有需要使用的地方。
2.模拟器配置
我们为什么使用模拟器,因为由于Fidder抓包,要在局域网环境下,我们大部分电脑都是以宽带连接,所以我这里就以模拟器讲解抓包,后续我会更新一期fidder手机抓包。
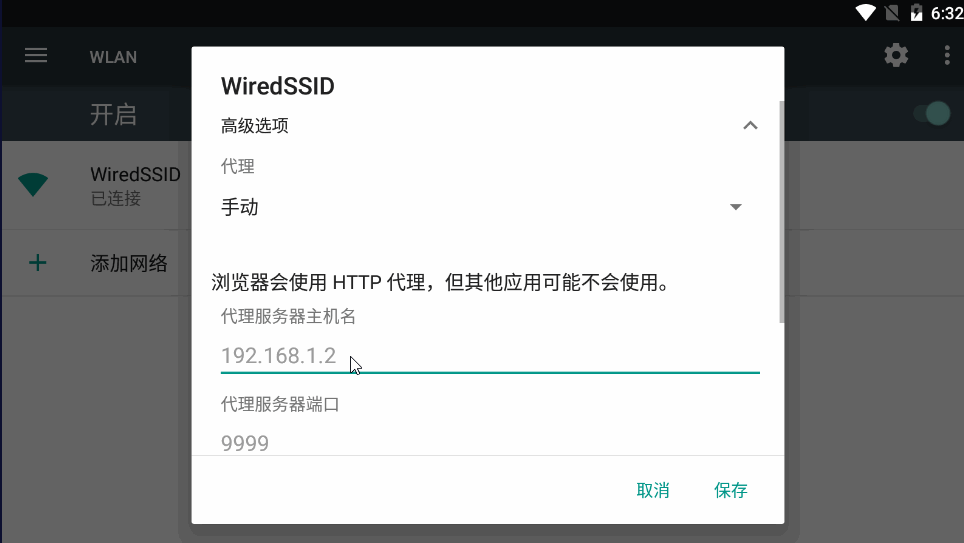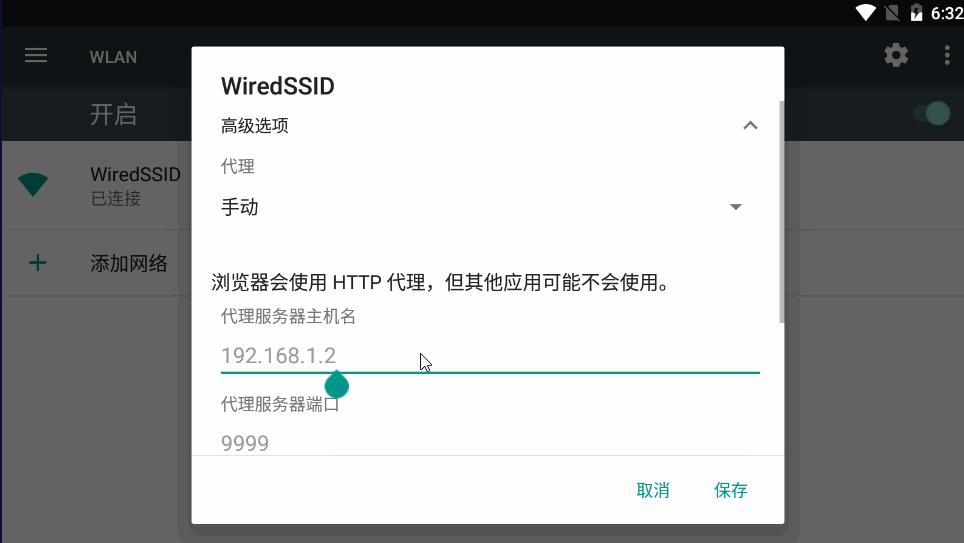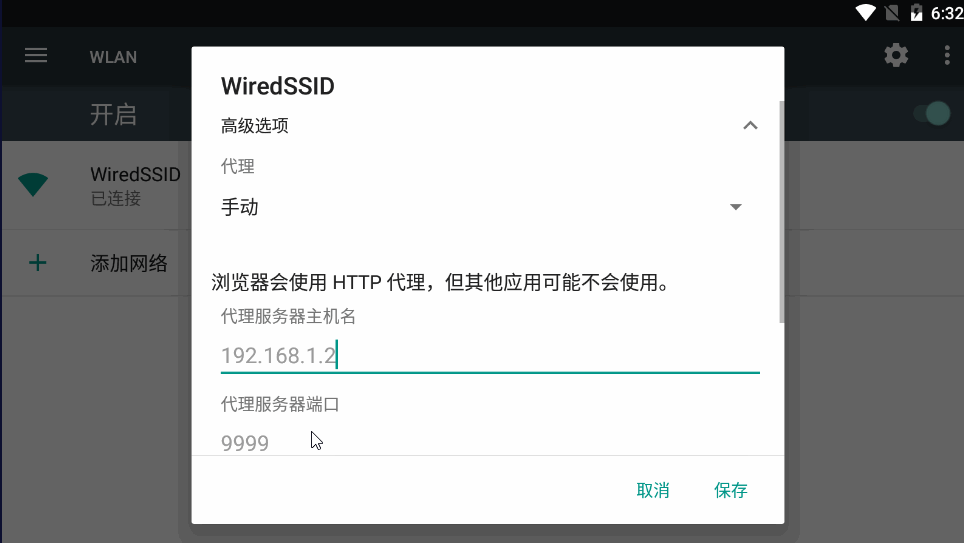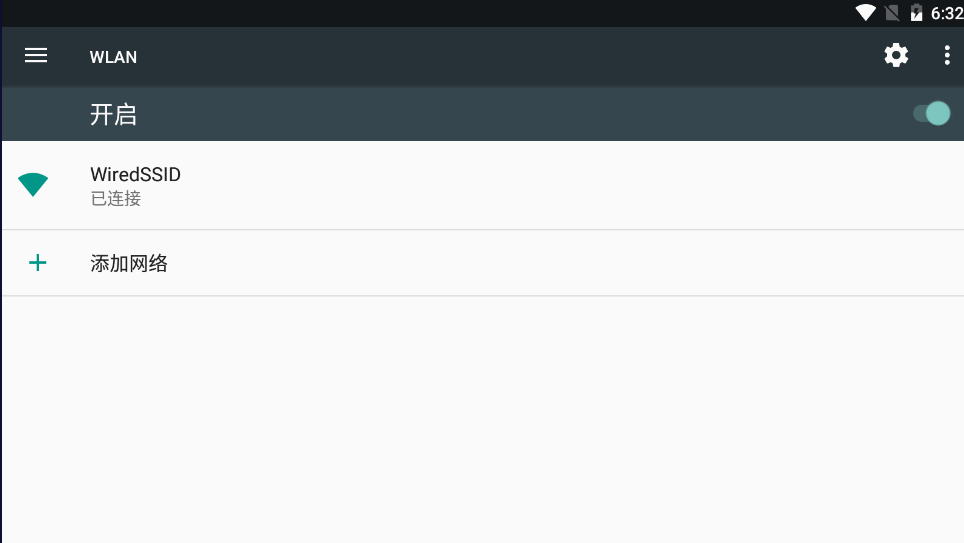
这里们先打模拟器,设置模拟器的代理。我们先查看自己的本机IP,通过cmd命令输入ipconfig即可查看本机的ip,我的本机IP是192.168.1.2

这里打开模拟器的设置,找到我们WLAN用点击,我们看到我们的wifi,用鼠标点击时间长一点,它会出现设置的,下面我用视频给大家看一下
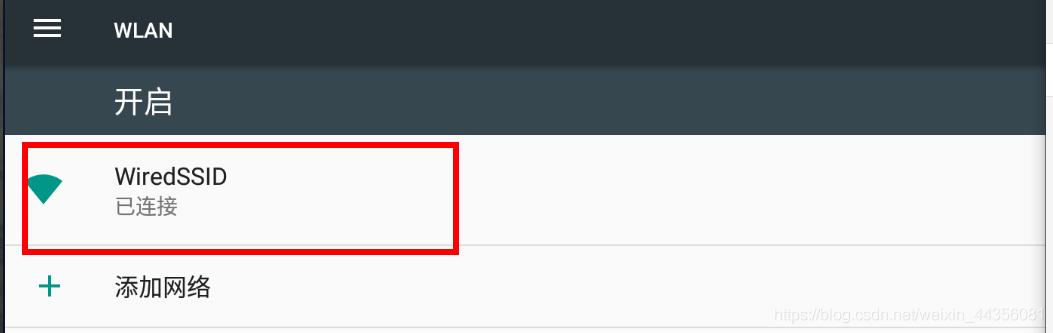
我们本机ip进行代理哦
3.模拟器证书安装
我们用模拟器打开浏览器,输入我们本机ip加端口,就是 192.168.1.2:9999
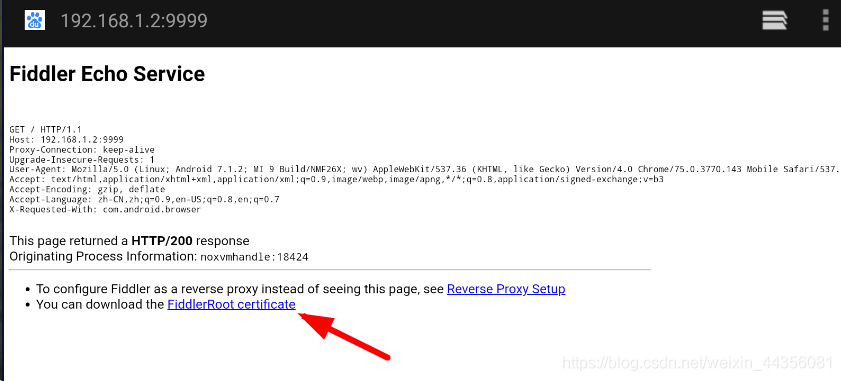
点击这个下载证书,下载完成后安装证书,命名随便命名。密码自己要记入。
上述如果都做成功了,应该就没什么问题了。
三、fidder4解析视频网站
这是我们模拟器里的app,app名字我会在下面评论发出。
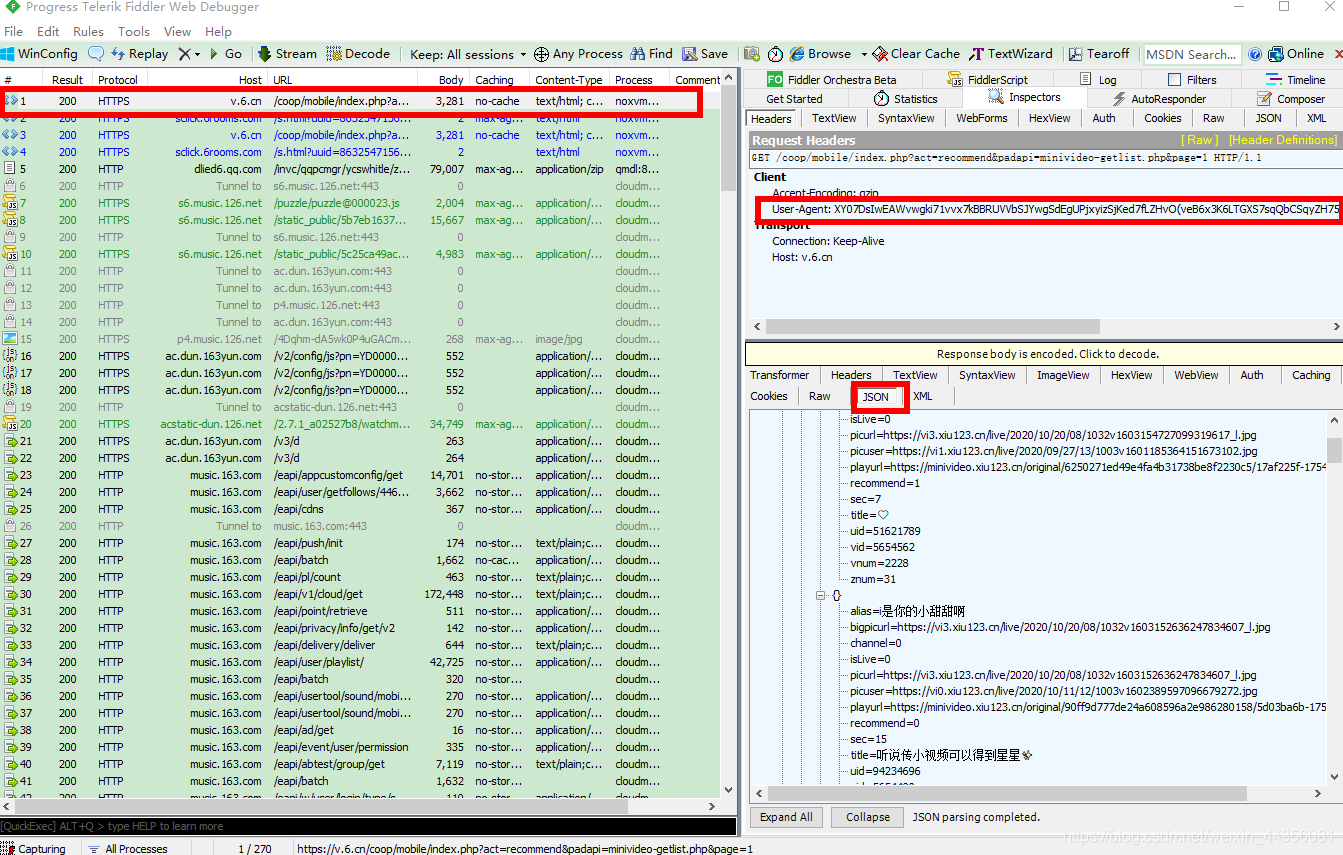
这里的所和上面的正好相对应,这里相信我们大家都找到了,
我们可以把fidder抓包到的数据在这里,这个是我们的数据网址
https://v.6.cn/coop/mobile/index.php?act=recommend&padapi=minivideo-getlist.php&page=1
我们通过模拟器视频往下滑,可以知道它是分页的,那样会有好多小姐姐视频哦,
https://v.6.cn/coop/mobile/index.php?act=recommend&padapi=minivideo-getlist.php&page=2
这里就是第二页的数据,这个时候就可以通过pycharm进行解析了。
pycharm编写app代码
import requests
import json
def Demo(page):url='https://v.6.cn/coop/mobile/index.php?act=recommend&padapi=minivideo-getlist.php&page={}'.format(page)header={'User-Agent':'XY0xDgIxDAS)wgtOthPHTn5AQUVFdXLOCRwSdEhX5PGQFmlHo6n22D)bw973lz13W2)XlZe8pKEpEEdBTgmU4ricT3kQENEI04ATJcbg2VsnEcvoVttmTXpq7r)sVToAdNLqmaxF1B6HFigkhXgO(f)rCw@@'}response = requests.get(url,headers=header,verify=False).json()data=response['content']['list'] #由于网站是json数据我们可以通过json解析,然后在进行数据的爬取for i in data:title =i['title'] #这里爬取的是视频标题playurl=i['playurl'] #这里是爬取是的视频的urlVideo(title,playurl)def Video(title,playurl):header = {'User-Agent': 'XY0xDgIxDAS)wgtOthPHTn5AQUVFdXLOCRwSdEhX5PGQFmlHo6n22D)bw973lz13W2)XlZe8pKEpEEdBTgmU4ricT3kQENEI04ATJcbg2VsnEcvoVttmTXpq7r)sVToAdNLqmaxF1B6HFigkhXgO(f)rCw@@'}response = requests.get(playurl,headers=header,verify=False)# 文件写入异常机制try:#由于写入可以会有点出错,我们要加一个异常处理机制,这样可以提高我们的程序性能。with open('VIdeo/{}.mp4'.format(title),'ab') as f:f.write(response.content)except Exception as e:print(e)for i in range(1,11):Demo(i)
总结
以上就是今天要讲的内容,本文简单的对fidder配置与模拟器的证书安装,通过fidder监视app传输的数据进行解析,我们知道此网址有分页功能 ,最后我们通过pycharm编写程序,这些操作看似繁锁,其实看懂了,就很简单。