一、说明
K-最近邻 (KNN) 算法是一种流行的监督机器学习算法,用于分类和回归任务。它是非参数惰性学习算法的一个典型例子。KNN 被认为是一种惰性学习算法,因为它在训练阶段不对底层数据分布做出任何假设,也不从训练数据中学习特定模型。相反,它是一种“惰性”或“延迟”学习,它只是记住训练数据集。
二、KNN算法
KNN 也是一种非参数算法,因为它没有在训练过程中确定的固定数量的参数。KNN 中的参数数量会随着训练数据的大小而增长,因为每个数据点都会成为一个参数。这与线性回归或神经网络等参数模型不同,这些模型无论训练数据大小如何,都有固定数量的参数。
在 KNN 中,根据 k 个最接近匹配的训练样本中的多数标签,将一个标签(表示为 x_i)分配给一个实例。这种方法允许 KNN 通过比较实例与其相邻数据点之间的相似性来进行预测。
在 K 最近邻 (KNN) 算法中,通过使用距离度量搜索其最近邻居来定位数据点。然后,该算法根据多数类或其 k 个最近邻居的平均值对输出进行分类或预测。例如,在 k=5 的分类问题中,当向算法呈现新的数据点时,将考虑训练集中距离新点最近的五个数据点(由欧几里得距离等距离度量确定)。新点的类标签是根据其五个邻居中的多数类分配的。在回归问题中,算法不是分配类标签,而是通过取其 k 个最近邻居的平均值来预测输出值。图 9-4 说明了 KNN 算法的工作原理。
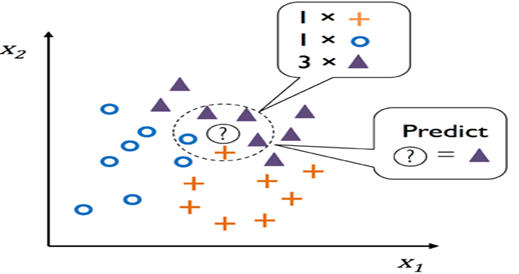
图 1.“KNN”算法的工作原理
新数据点用问号表示其未知的标签或值。如前所述,该算法利用 k 个最接近的训练样本中的多数标签对新数据点的输出进行分类或预测。
在 KNN 中,超参数 k 的选择至关重要,因为它决定了用于预测的邻居数量。k 值越小,决策边界就越复杂,这可能会增加过度拟合训练数据的风险。另一方面,k 值越大,决策边界就越平滑,但可能会导致欠拟合,即模型过度简化数据点之间的关系。
确定 k 的最佳值通常取决于手头的具体问题,可以通过实验或交叉验证来完成。选择合适的 k 值以在未知数据上实现令人满意的性能,在模型复杂性和泛化之间取得平衡至关重要。
图2显示了选择k值的效果。
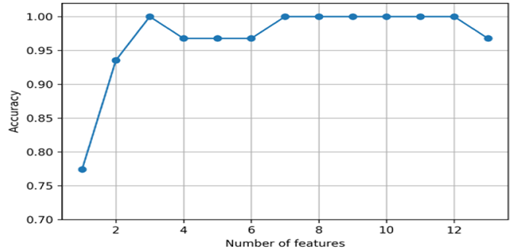
图 2. 不同 k 值的选择
图2中,横轴表示特征个数或者说数字k,横轴也表示模型的准确率。
在本教程中,我们将从头开始探索在 Python 中实现 K-最近邻 (KNN) 算法。KNN 是一种用于分类和回归任务的基本机器学习算法。通过从头开始构建 KNN,我们将更深入地了解其内部工作原理,并学习如何将其应用于现实世界的数据集。
让我们深入研究如何逐步实现 KNN 算法!
三、KNN算法的Python实现
3.1 步骤 1:导入库
我们首先导入必要的库。我们将使用 NumPy 进行数值计算、使用 Matplotlib 进行数据可视化、使用 mlxtend 绘制决策区域,并使用 scikit-learn 生成合成数据并将其拆分为训练集和测试集。
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split3.2 第 2 步:定义 KNN 类
该类KNN是我们 K-最近邻 (KNN) 算法实现的核心组件。在这个类中,我们封装了实例化、训练和利用 KNN 模型进行预测所需的所有基本功能。该类中的关键方法包括:
__init__:使用默认值初始化 KNN 分类器k,表示预测期间要考虑的邻居数量。fit:将模型与提供的训练数据进行拟合,存储训练特征(X_train)和相应的标签(y_train)。euclidean_distance:计算两个数据点之间的欧几里得距离,这是确定实例之间相似性的关键指标。predict:获取一组输入数据点并返回基于 k 个最近邻的预测标签数组。_predictpredict:通过识别 k 个最近邻并应用多数投票方案来计算单个数据点的预测所使用的内部方法。
通过将这些功能封装在KNN类中,我们创建了 KNN 算法的模块化和可重用实现,使其更易于理解、维护和扩展。这是 KNN 类:
class KNNClassification:def __init__(self, k=3):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef euclidean_distance(self, x1, x2):return np.sqrt(np.sum((x1 - x2)**2))def predict(self, X):y_pred = [self._predict(x) for x in X]return np.array(y_pred)def _predict(self, x):distances = [self.euclidean_distance(x, x_train) for x_train in self.X_train]k_indices = np.argsort(distances)[:self.k]k_nearest_labels = [self.y_train[i] for i in k_indices]most_common = max(set(k_nearest_labels), key=k_nearest_labels.count)return most_commondef plot_data(X, y):# (o==circle, for train) and (s==square for test)plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, s=100, cmap='jet', marker='o')plt.scatter(x_test[:, 0], x_test[:, 1], c=y_test, s=100, cmap='jet', marker='s')plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.title('Generated Data')plt.show()这部分代码是主要执行部分,我们在其中实例化 KNN 算法,在合成数据上对其进行训练,可视化决策边界,评估其性能,并绘制训练和测试数据点以及预测标签。
class KNN:def __init__(self, k=3):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef euclidean_distance(self, x1, x2):return np.sqrt(np.sum((x1 - x2)**2))def predict(self, X):y_pred = [self._predict(x) for x in X]return np.array(y_pred)def _predict(self, x):distances = [self.euclidean_distance(x, x_train) for x_train in self.X_train]k_indices = np.argsort(distances)[:self.k]k_nearest_labels = [self.y_train[i] for i in k_indices]most_common = max(set(k_nearest_labels), key=k_nearest_labels.count)return most_commondef plot_data(X, y):plt.scatter(X[:, 0], X[:, 1], c=y, s=100, cmap='jet', marker='o')plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.title('Generated Data')plt.show()if __name__ == "__main__":# Generate synthetic data using scikit-learn's make_classification functionX, y = make_classification(n_samples=20, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1, class_sep=1., random_state=23)plot_data(X, y)# Split data into training and testing setsx_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=19)knn = KNN(k=3)knn.fit(x_train, y_train)plot_decision_regions(X, y, clf=knn, legend=2)plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.title('KNN Decision Boundary')plt.show()# Predict classes for the test datay_pred = knn.predict(x_test)# Calculate accuracyaccuracy = np.mean(y_pred == y_test) * 100print(f"Accuracy: {accuracy:.2f}%")# Plot the training and test data (o==circle, for train) and (s==square for test)plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, s=100, cmap='jet', marker='o', label='Train (Circle)')plt.scatter(x_test[:, 0], x_test[:, 1], c=y_test, s=100, cmap='jet', marker='s', label='Test (Square)')plt.scatter(x_test[:, 0], x_test[:, 1], c=y_pred, s=150, cmap='jet', marker='x', label='Predicted Test (Cross)')plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.title(f'Train-Test, Predicted, accuracy = {accuracy}')plt.legend()plt.show()四、K 最近邻的挑战
虽然 K-最近邻 (KNN) 是一种简单有效的算法,但它也面临挑战。在本次讨论中,我们将探讨使用 KNN 时遇到的一些常见问题,并通过代码示例进行演示。通过研究 KNN 如何处理不断增加的数据集大小,我们旨在说明该算法的可扩展性限制,并阐明计算时间和内存使用之间的权衡。让我们深入研究代码以揭示这些挑战。
import time# Define a range of sample sizes to test
sample_sizes = [1000, 5000, 10000, 50000, 100000]# Lists to store time and memory usage for each sample size
execution_times = []
memory_usages = []# Loop through each sample size
for sample_size in sample_sizes:print(f"Testing with {sample_size} data points...")# Generate synthetic dataX, y = make_classification(n_samples=sample_size, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1, class_sep=1., random_state=42)# Split data into training and testing setsx_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)# Calculate memory usage for training datatrain_memory_usage = x_train.size * x_train.itemsizememory_usages.append(train_memory_usage)# Instantiate and fit the KNN modelmodel = KNN(3)model.fit(x_train, y_train)# Measure prediction time for a single test data pointstart_time = time.time()model.predict(x_test[[0], :])end_time = time.time()execution_time = end_time - start_timeexecution_times.append(execution_time)# Plotting the results
plt.figure(figsize=(10, 5))# Plot execution time
plt.subplot(1, 2, 1)
plt.plot(sample_sizes, execution_times, marker='o')
plt.xlabel('Number of Data Points')
plt.ylabel('Execution Time (seconds)')
plt.title('Execution Time vs. Number of Data Points')# Plot memory usage
plt.subplot(1, 2, 2)
plt.plot(sample_sizes, memory_usages, marker='o')
plt.xlabel('Number of Data Points')
plt.ylabel('Memory Usage (bytes)')
plt.title('Memory Usage vs. Number of Data Points')plt.tight_layout()
plt.show()运行上述代码后,我们可以看到如下图所示的情节:
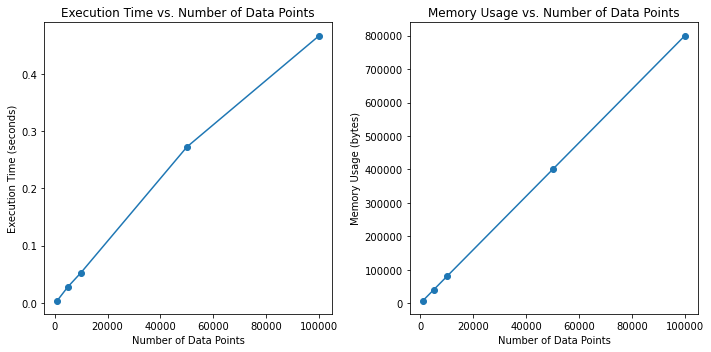
图 1. KNN 的计算时间和内存使用情况
五、KNN 回归:使用 K 最近邻进行预测建模
KNN 回归涉及通过确定每个数据点的最近邻居目标值的平均值来预测连续目标值。我想改变以前的代码并将其转换为适合回归的代码。
回归和分类代码之间的差异:
- 数据集生成:
- 上一个(分类):使用“make_classification”生成数据集以创建合成分类数据。
- 当前(回归):使用“make_regression”生成合成回归数据。
2.模型预测:
- KNN 模型预测每个数据点的离散类标签而不是连续的目标值。
3.评估指标:
- 由于这是一项回归任务,因此可以使用传统评估指标(例如均方误差(MSE)或 R 平方)来代替准确度。
4.可视化:
- 之前:使用“plot_decision_regions”可视化决策边界以说明分类区域。
- 当前:回归线可视化,以展示 KNN 模型对回归任务的预测能力。
5.标签编码:
- 回归不需要标签编码,因为目标值是连续的而不是整数。
以下是使用 KNN 进行回归的修改后的代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_splitclass KNNRegression:def __init__(self, k=3):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef euclidean_distance(self, x1, x2):return np.sqrt(np.sum((x1 - x2)**2))def predict(self, X):y_pred = [self._predict(x) for x in X]return np.array(y_pred)def _predict(self, x):distances = [self.euclidean_distance(x, x_train) for x_train in self.X_train]k_indices = np.argsort(distances)[:self.k]k_nearest_labels = [self.y_train[i] for i in k_indices]return np.mean(k_nearest_labels)if __name__ == "__main__":# Generate synthetic regression dataX, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42)# Instantiate and fit the KNN regression modelknn = KNNRegression(k=3)knn.fit(X, y)# Generate a range of feature values for plotting the regression linex_range = np.linspace(min(X), max(X), num=100).reshape(-1, 1)# Predict target values for the feature rangey_pred = knn.predict(x_range)# Plot the data points and the regression lineplt.scatter(X, y, color='blue', s=30, marker='o', label='Data')plt.plot(x_range, y_pred, color='red', linewidth=2, label='KNN Regression')plt.xlabel('Feature')plt.ylabel('Target')plt.title('KNN Regression')plt.legend()plt.show()通过平滑的回归线描绘特征和目标变量之间的关系:
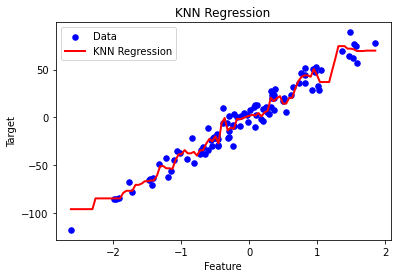
图 2. KNN 回归线
六、探索 K 最近邻 (KNN) 算法中 K 的影响:平衡过度拟合和欠拟合
在本分析中,我们深入探讨了 K 最近邻 (KNN) 算法中参数“K”的意义及其对分类准确性、决策边界、过度拟合和欠拟合的影响。
在 K 最近邻 (KNN) 算法中,如果 K 值太小,通常就会发生过拟合。如果 K 值较小,模型就会对数据中的噪声和异常值过于敏感,从而导致决策边界过于复杂,与训练数据拟合得过于紧密。这可能会导致模型对未知数据的泛化能力较差,因为模型可能会捕捉噪声而不是底层模式。
相反,当K 值过大时,可能会出现欠拟合。如果 K 值过大,模型会对过多的邻居进行平均,导致决策边界过于简单,无法捕捉数据的真实结构。这会导致训练和测试数据集的准确率都很低,表明模型无法充分捕捉底层模式的复杂性。
通过系统地改变 K 的值并观察其对模型性能和行为的影响,我们可以深入了解所涉及的权衡,并发现基于 KNN 任务中参数选择的最佳策略,确保过度拟合和欠拟合之间的平衡。
from sklearn.metrics import mean_squared_errordef test_k_values(X_train, y_train, X_range, k_values):fig, axs = plt.subplots(2, 2, figsize=(12, 10))axs = axs.flatten()for i, k in enumerate(k_values):# The regression class that we wrote in the previous codesknn_reg = KNNRegression(k=k)# Fit the KNN regression model to the training dataknn_reg.fit(X_train, y_train)# Predict target values for the range of feature valuesy_pred = knn_reg.predict(X_range)mse = mean_squared_error(y_train, knn_reg.predict(X_train))axs[i].scatter(X_train, y_train, color='blue', s=30, marker='o', label='Data')axs[i].plot(X_range, y_pred, color='red', linewidth=2, label=f'KNN Regression (K={k}), MSE: {mse:.2f}')axs[i].set_xlabel('Feature')axs[i].set_ylabel('Target')axs[i].set_title(f'KNN Regression (K={k})')axs[i].legend()plt.tight_layout()plt.show()if __name__ == "__main__":# Generate synthetic regression dataX, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)# Generate a range of feature values for plotting the regression lineX_range = np.linspace(min(X), max(X), num=100).reshape(-1, 1)# Test different values of K and plot the resultsk_values = [1, 3, 5, 7]test_k_values(X_train, y_train, X_range, k_values)这是代码的输出:
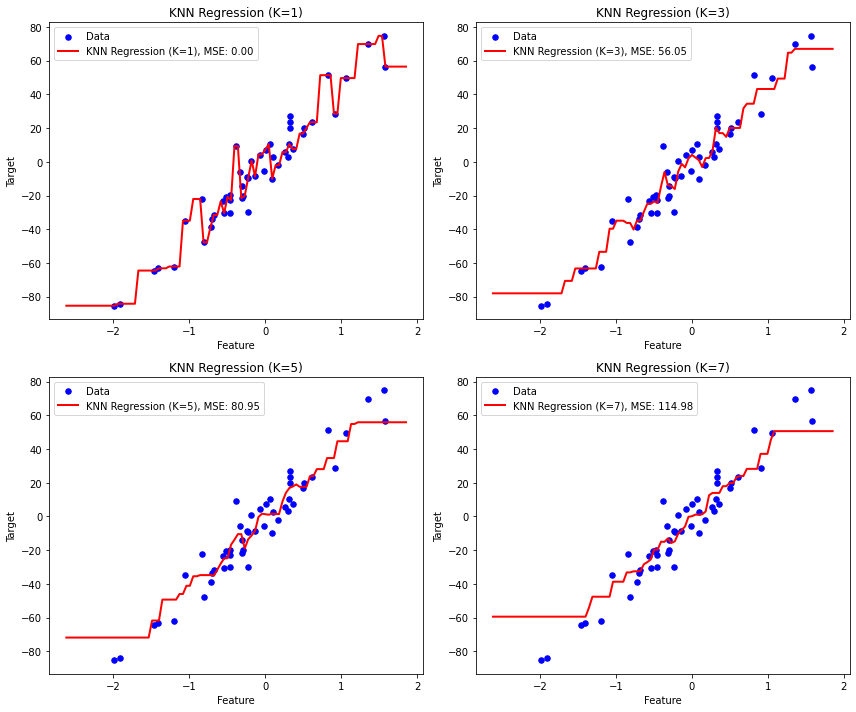
图 3. 在网格中绘制结果
概述 K 最近邻 (KNN) 的优缺点:
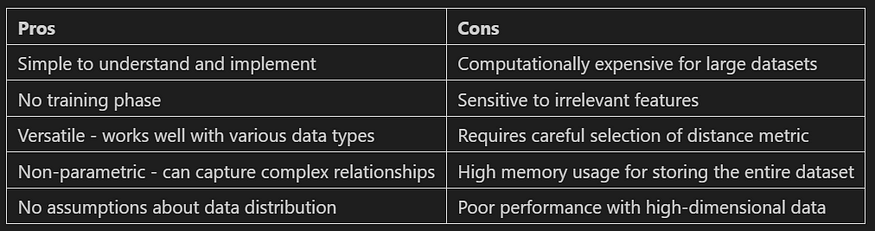
图 4. KNN 的优缺点
七、K 最近邻 (KNN) 算法的增强和扩展:解决限制并提高性能
K 最近邻 (KNN) 算法虽然简单直观,但也有其缺点。然而,研究人员和从业者已经开发出各种改进和扩展来解决这些限制。这些方法中的每一种都旨在解决算法缺点的特定方面。例如,加权 KNN 或距离加权 KNN等技术试图通过根据距离为相邻点分配不同的权重来减轻算法对不相关特征的敏感性。同样,KD 树或Ball 树等方法通过将数据组织成空间数据结构来优化算法对大型数据集的计算效率。在我们机器学习系列的下一篇中,我们将深入研究这些改进和扩展,探索它们如何增强 KNN 算法的性能和多功能性。
八、结论
在第 15 天,我们讨论了 KNN 的概念以及从头开始的分类和回归实现。在即将发布的文章《ML 系列:第 16 天 — 提高 KNN 效率:使用 KD 树和 Ball 树实现更快的算法》中,我将探讨 KNN、KD 树和 Ball 树的一些改进。