KMP算法是计算机科学中的一种字符串匹配算法,KMP是三个创始人名字首字母

题目
AcWing - 算法基础课
前置知识点
KMP算法是一种高效的字符串匹配算法,算法名称取自于三位共同发明人名字的首字母组合。该算法的主要使用场景就是在字符串(也叫主串)中的模式串(也叫子串)定位问题,常见的有“求子串出现的起始位置”、“求子串的出现次数”等。
前缀和后缀
假设一个字符串“ababa"
他的前缀就是a,ab,aba,abab (ababa,ababa,ababa,ababa)
他的后缀就是a,ba,aba,baba (ababa,ababa,ababa,ababa)
前缀和后缀的最大长度,是原字符串长度-1
思路
最浅显易懂的 KMP 算法讲解_哔哩哔哩_bilibili
F03【模板】KMP 算法——信息学竞赛算法_哔哩哔哩_bilibili
给定一个主串S,模式串P,求P在S中出现的位置
普通暴力枚举
一个字符一个字符的双指针枚举,一旦发现不同
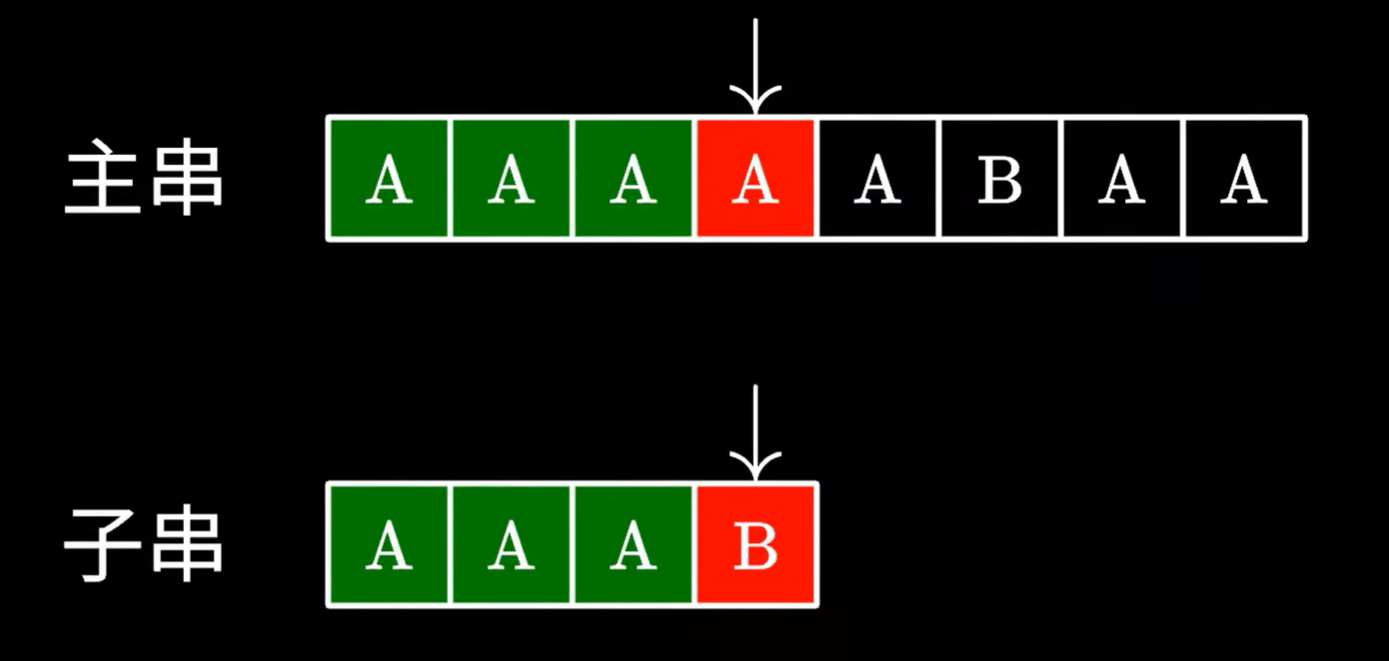
主串又要从第二个开始匹配,子串要从头开始匹配

缺点:时间复杂度太高
kmp优化思路
在比对失败时,我们已经知道曾经读过哪些字符了
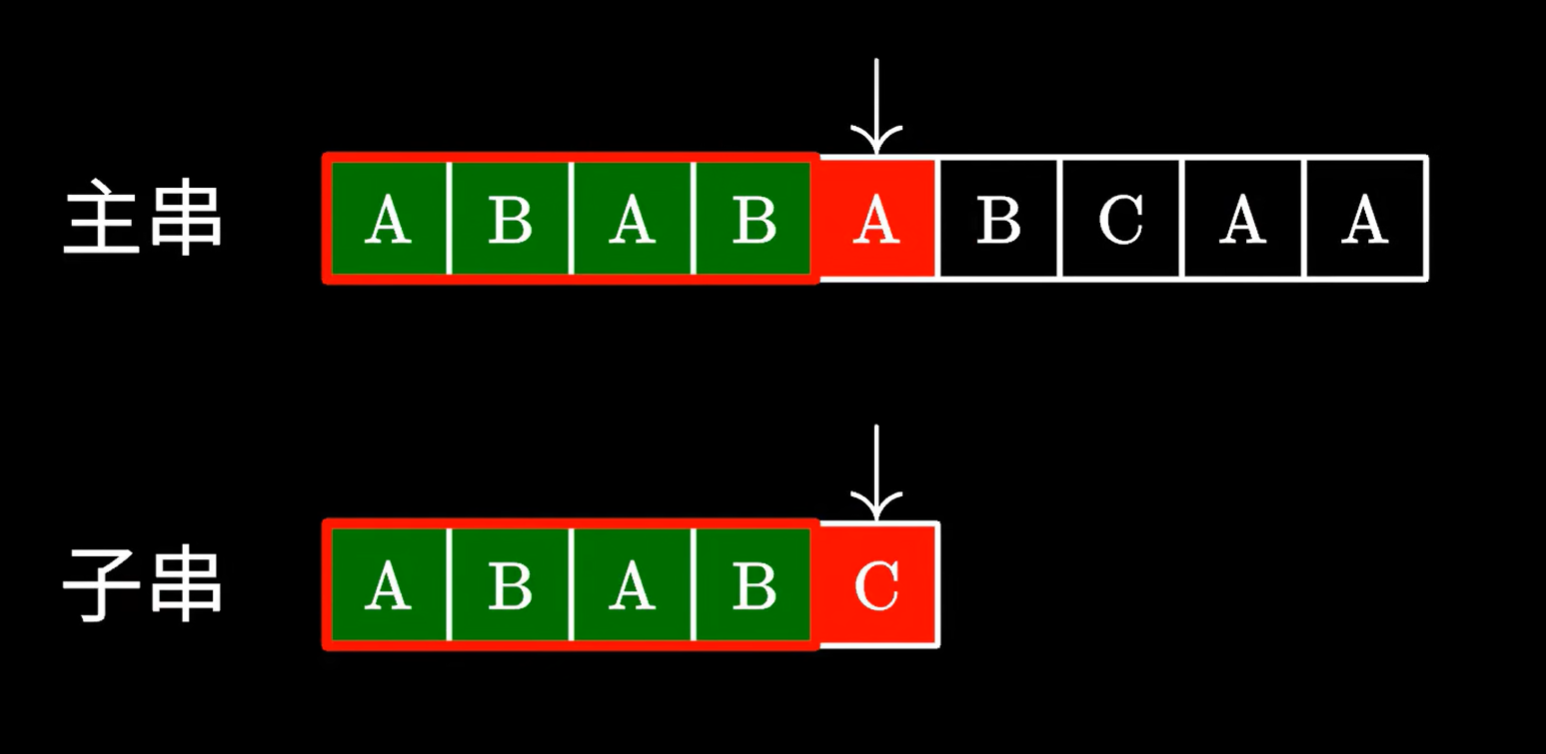
已经匹配的子串,有相同的后缀, 前缀,那我们是不是可以保留相同的前缀,再去查找不同的剩下的字符串
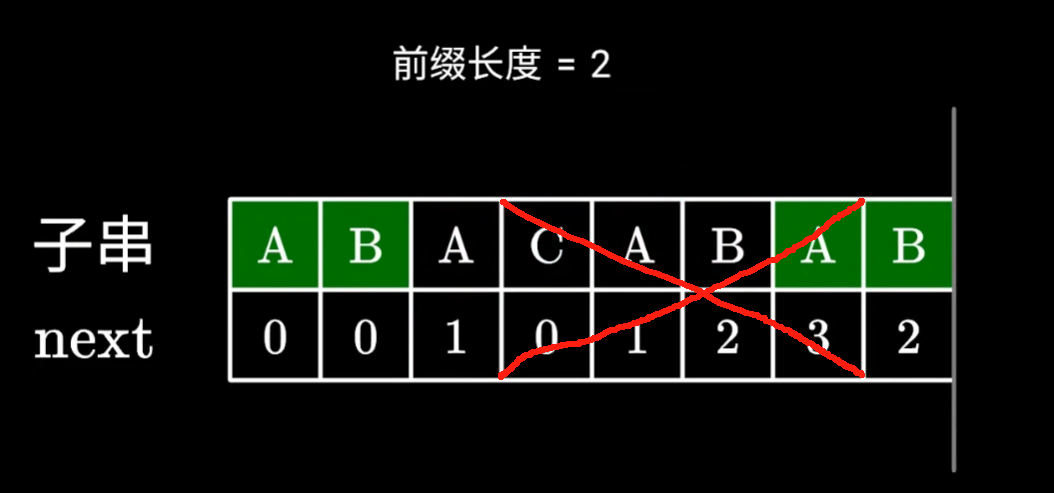
如下图,主串保留的绿色,实际上是匹配的子串的后缀,子串里保留的绿色部分,就是匹配的子串的前缀
他们是相同的,则可以把主串里匹配的子串的后缀,视为子串前缀,继续在主串查找相同前缀后面的字符串
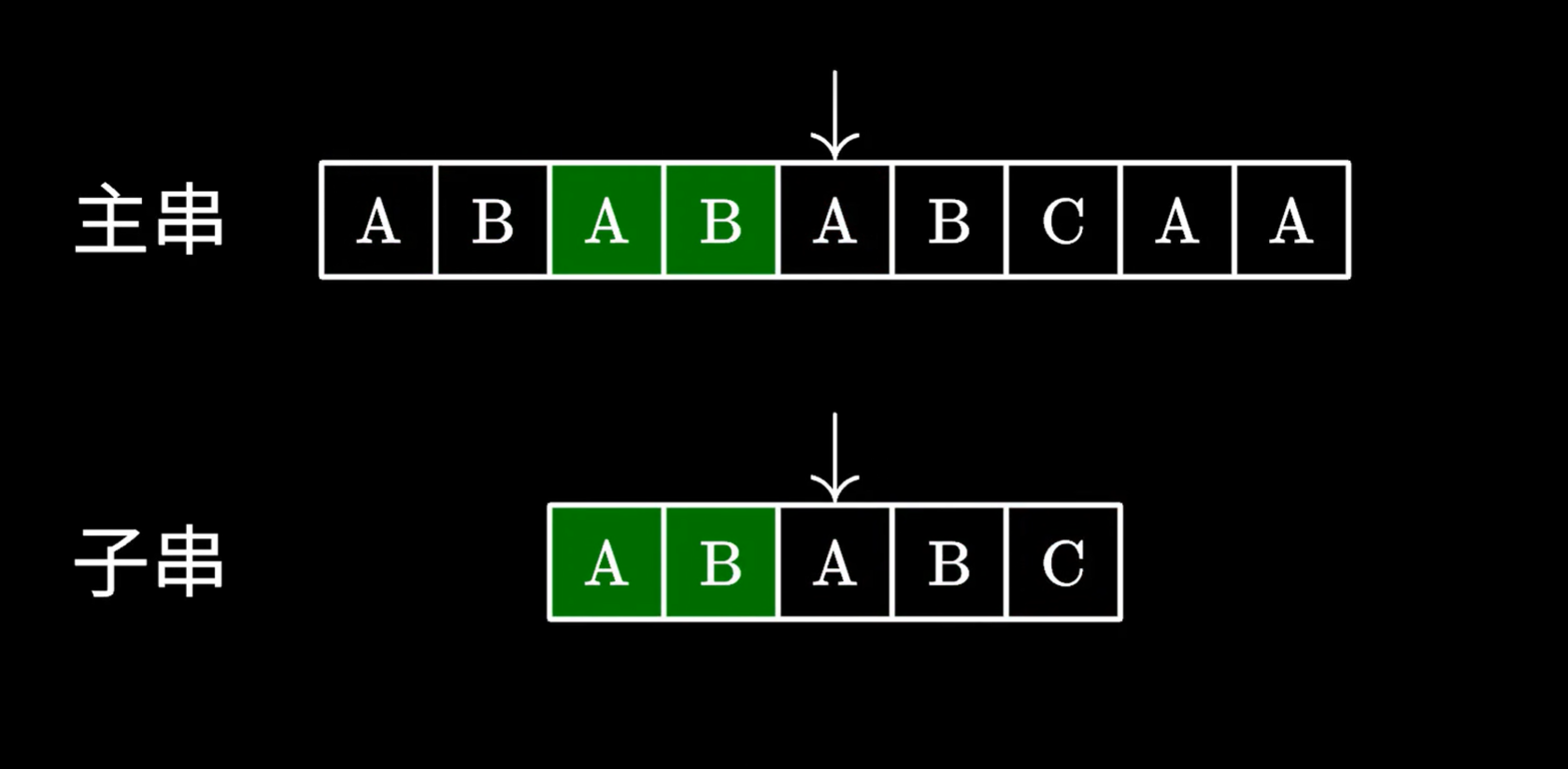
next数组使用
我们已经知道kmp的优化思路,那么如何将知道,该保留的前缀呢?再暴力双指针循环太麻烦
kmp三个人提出了next数组,我们先不看如何实现,先看如何使用,next数组功能
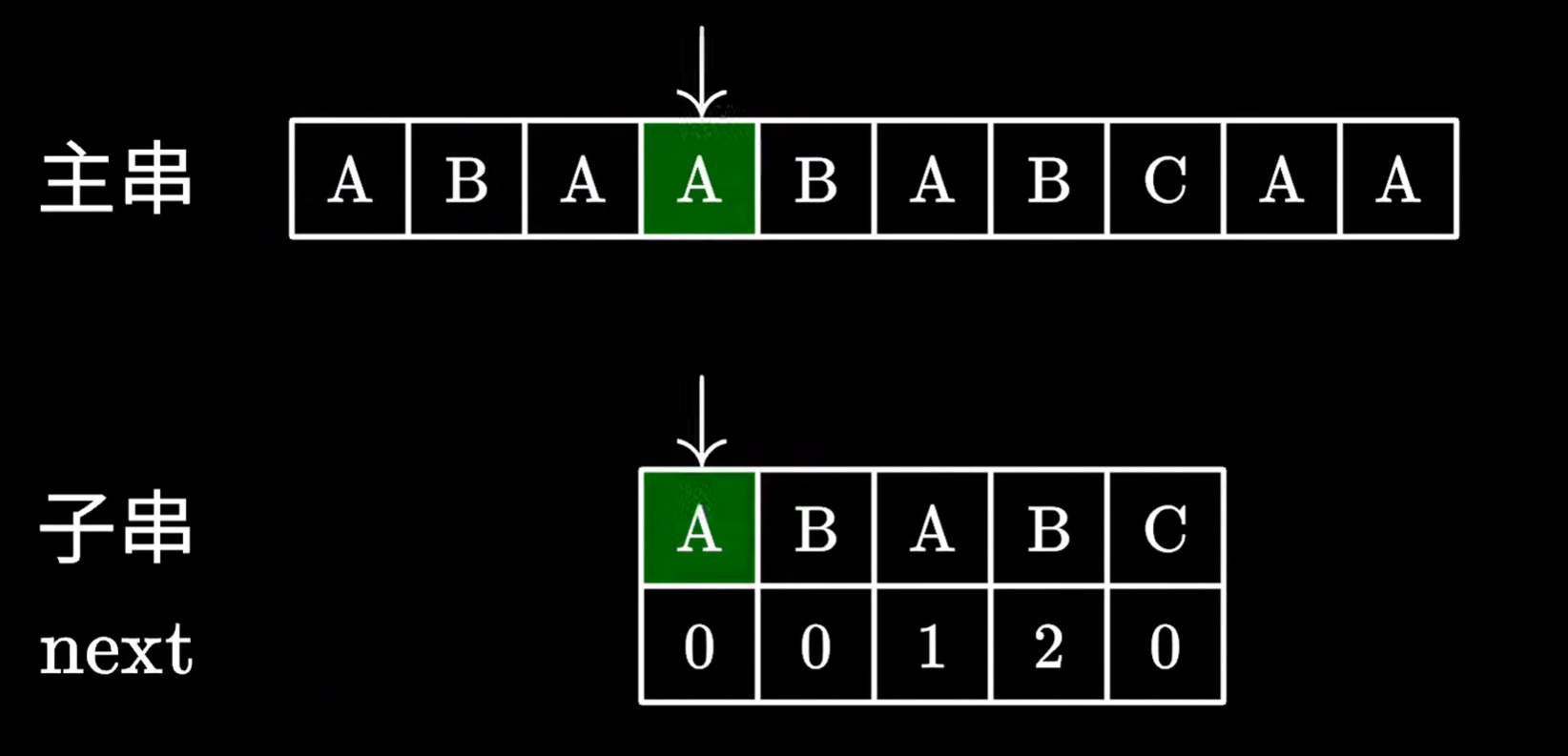
下图是一个初始状态
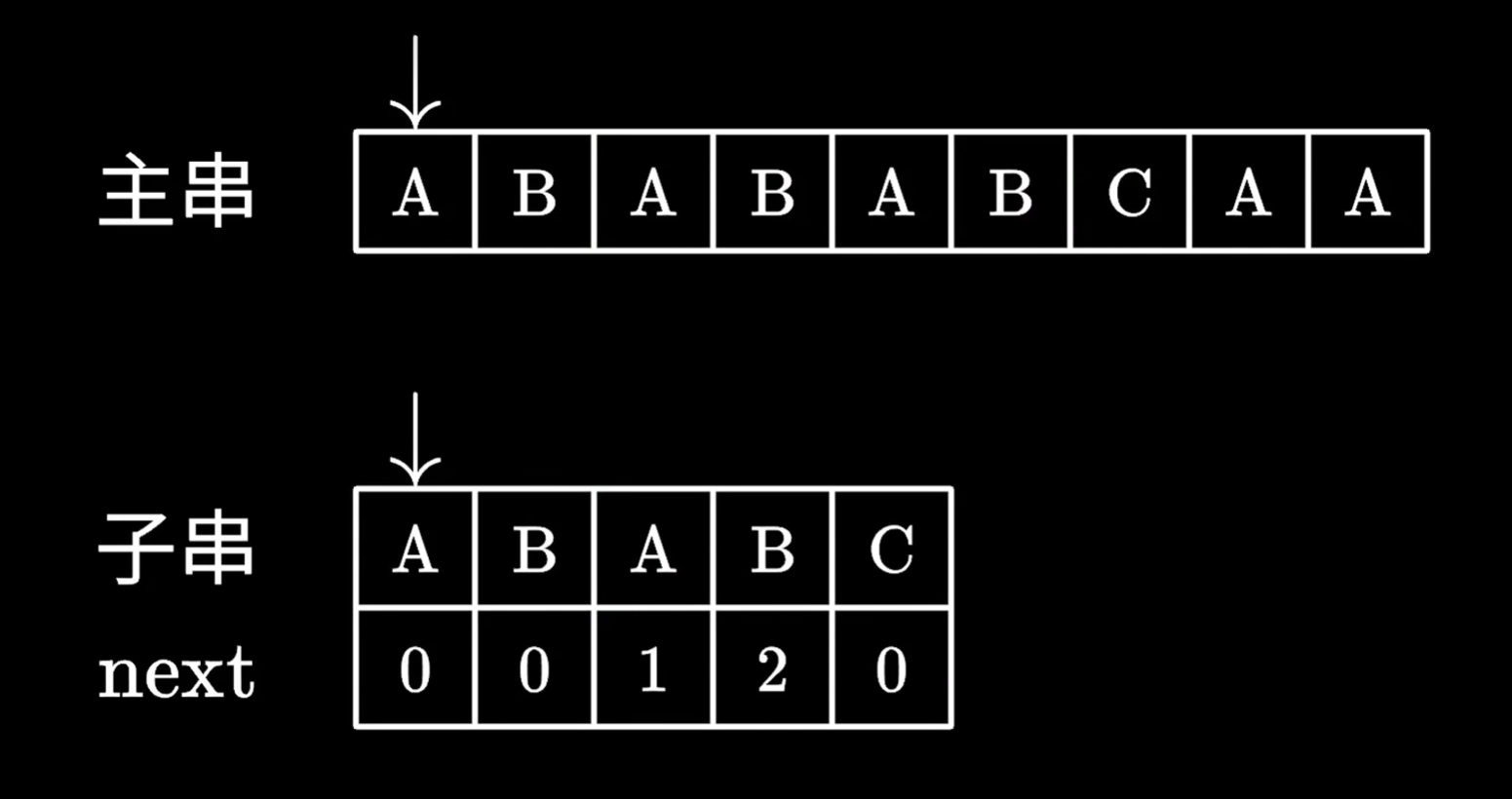
kmp算法匹配失败时,去看最后一个匹配成功的子串的字符,对应的next数组里的值

查到对应的值后,我们移动子串,跳过next数组里的值对应的字符个数,例如值是2,我们就跳过前两个字符
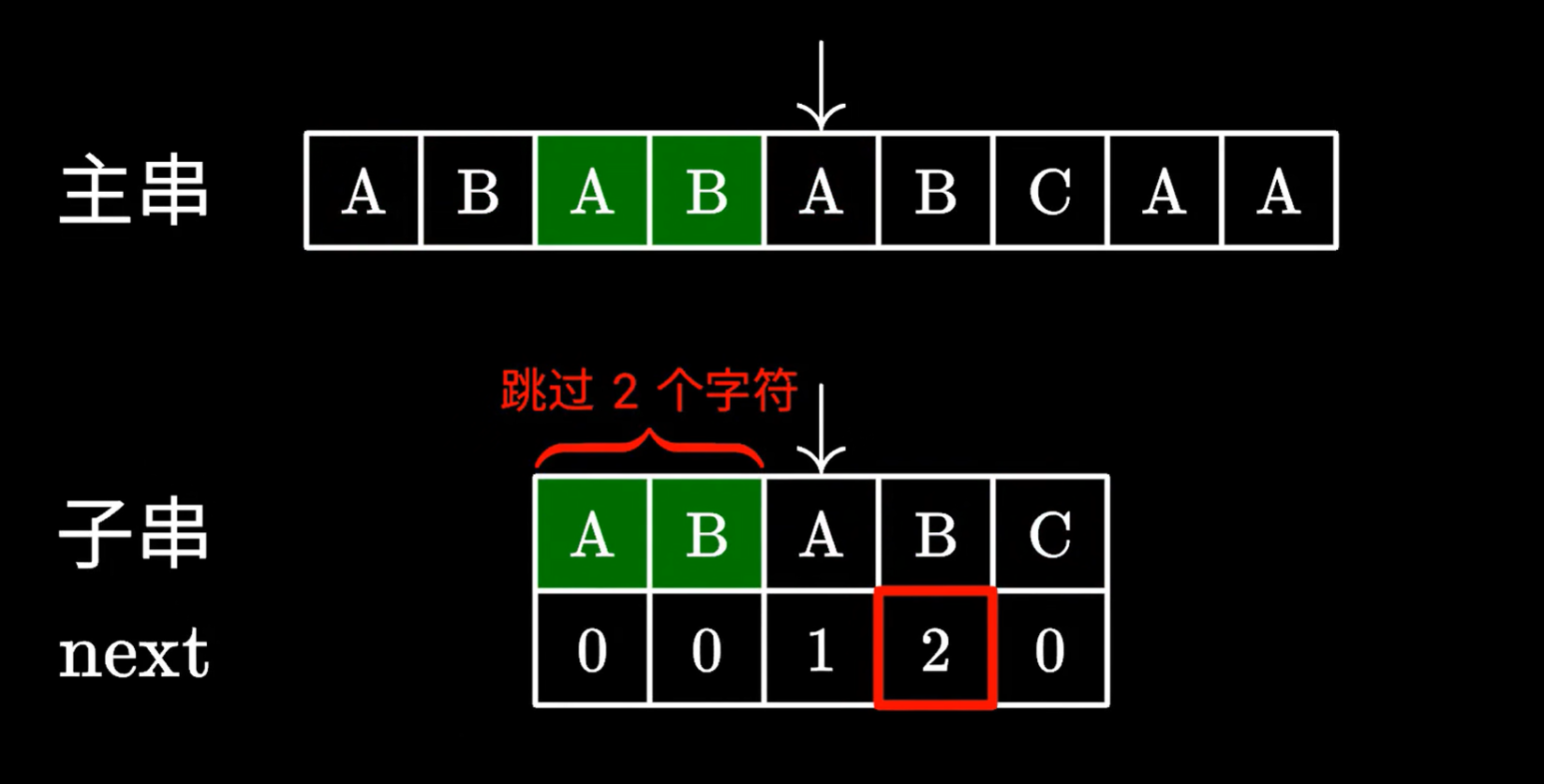
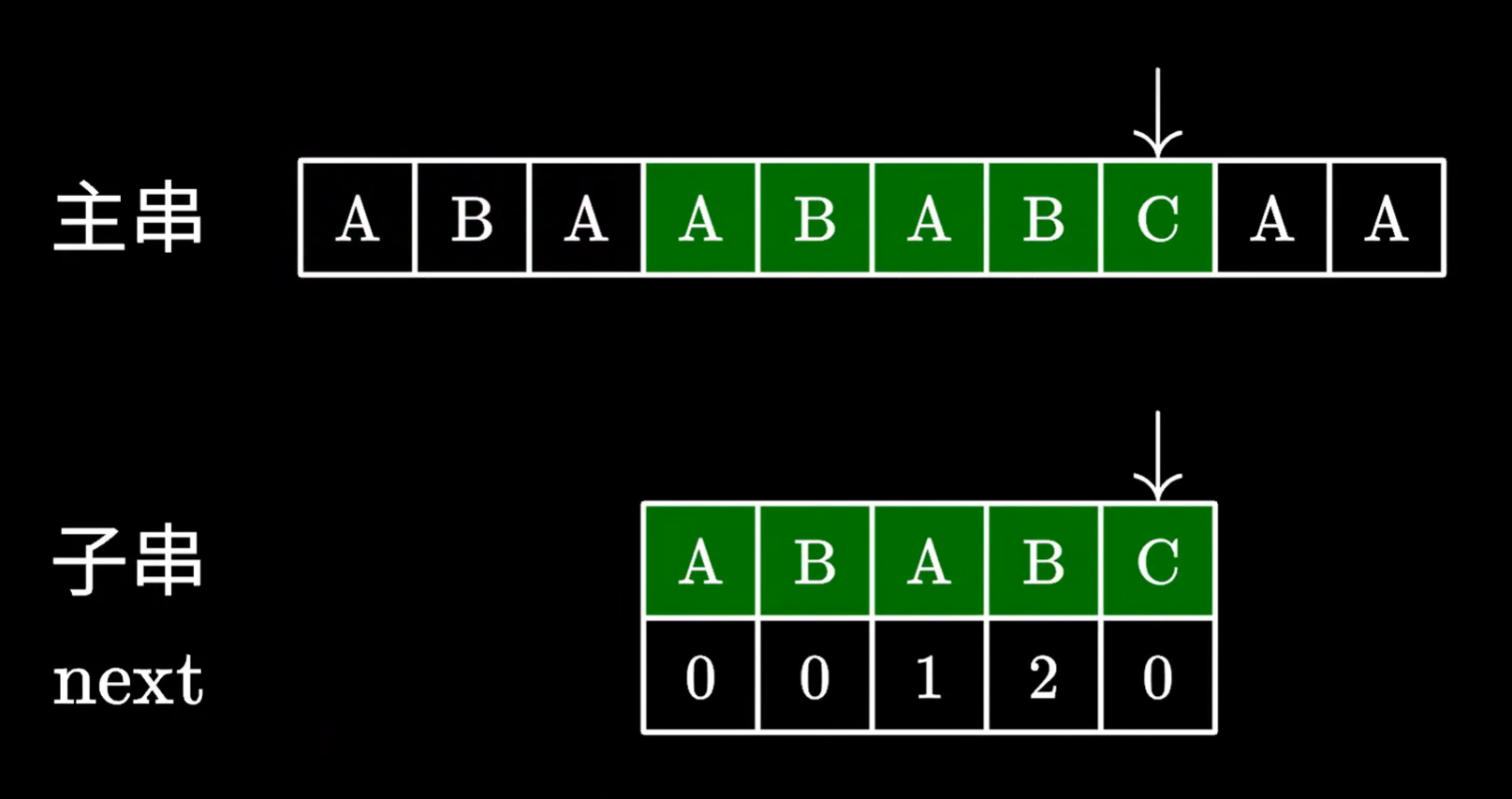
我们发现,跳过的这两个字符,确实能和主串指针指向位置前的两个字符对应
所以继续枚举即可,不需要从头枚举
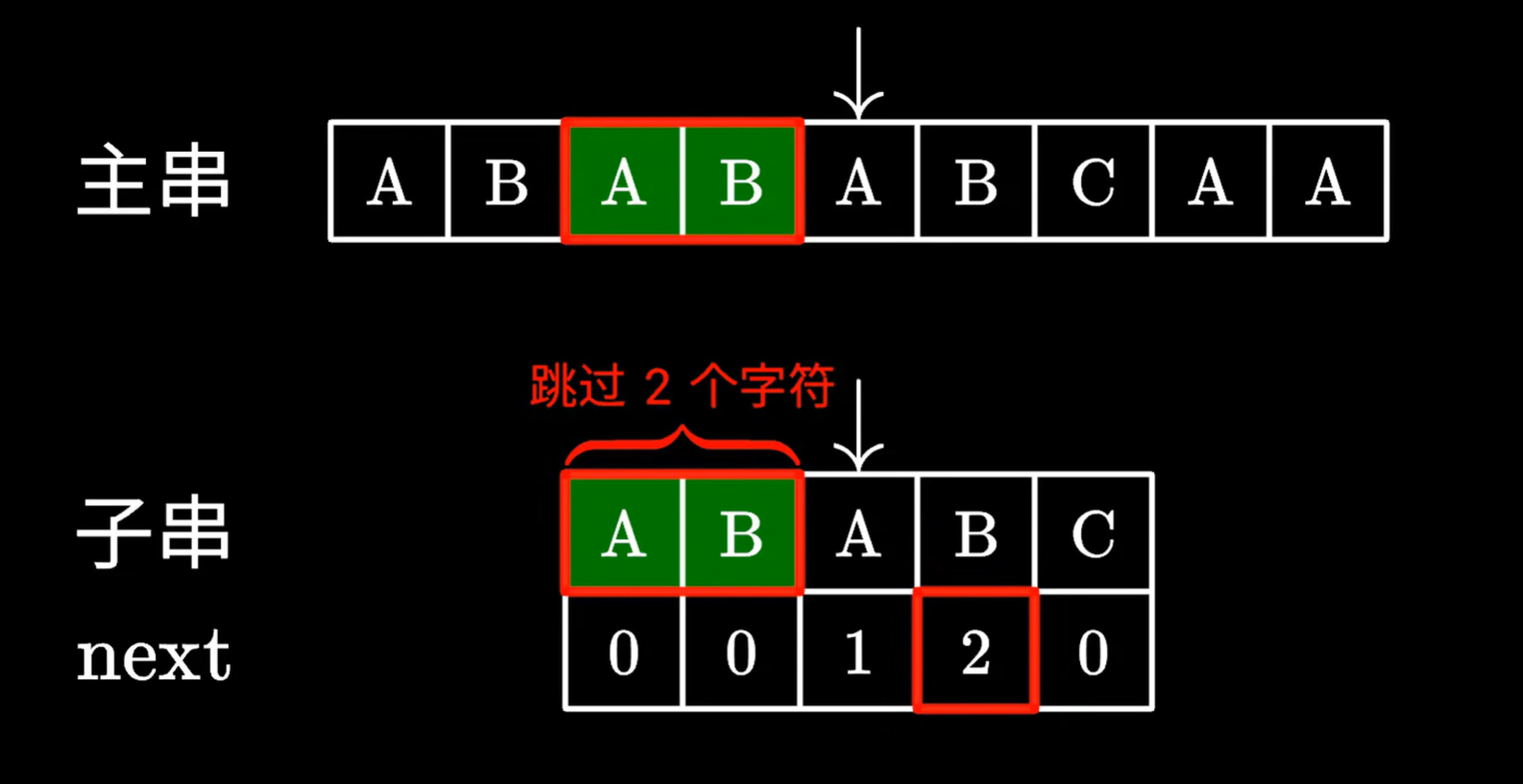
这样,我们永远不需要回退主串指针,一次遍历主串,就可以找到匹配子串
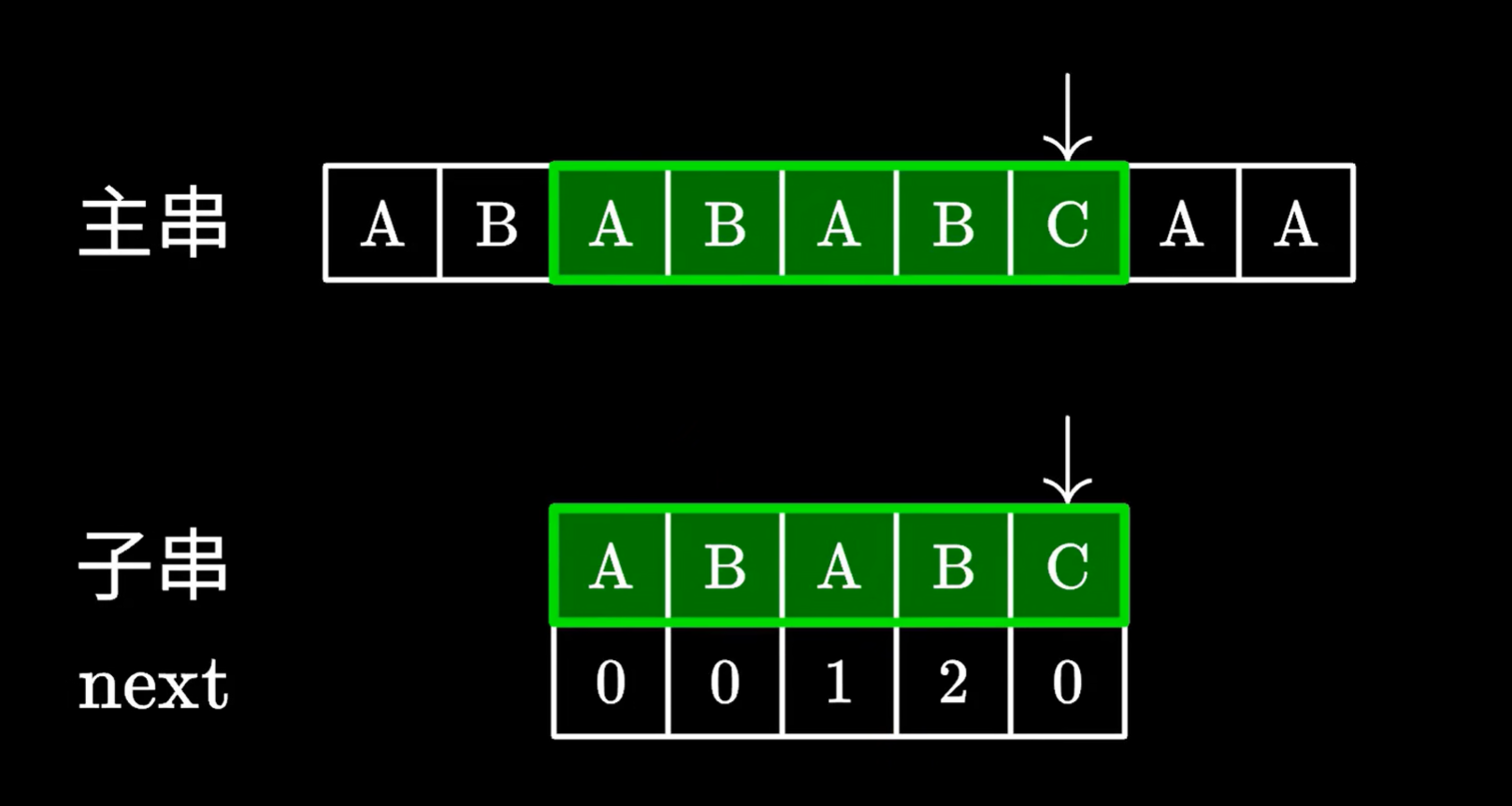
再看一下 ,如果子串对应next是0时
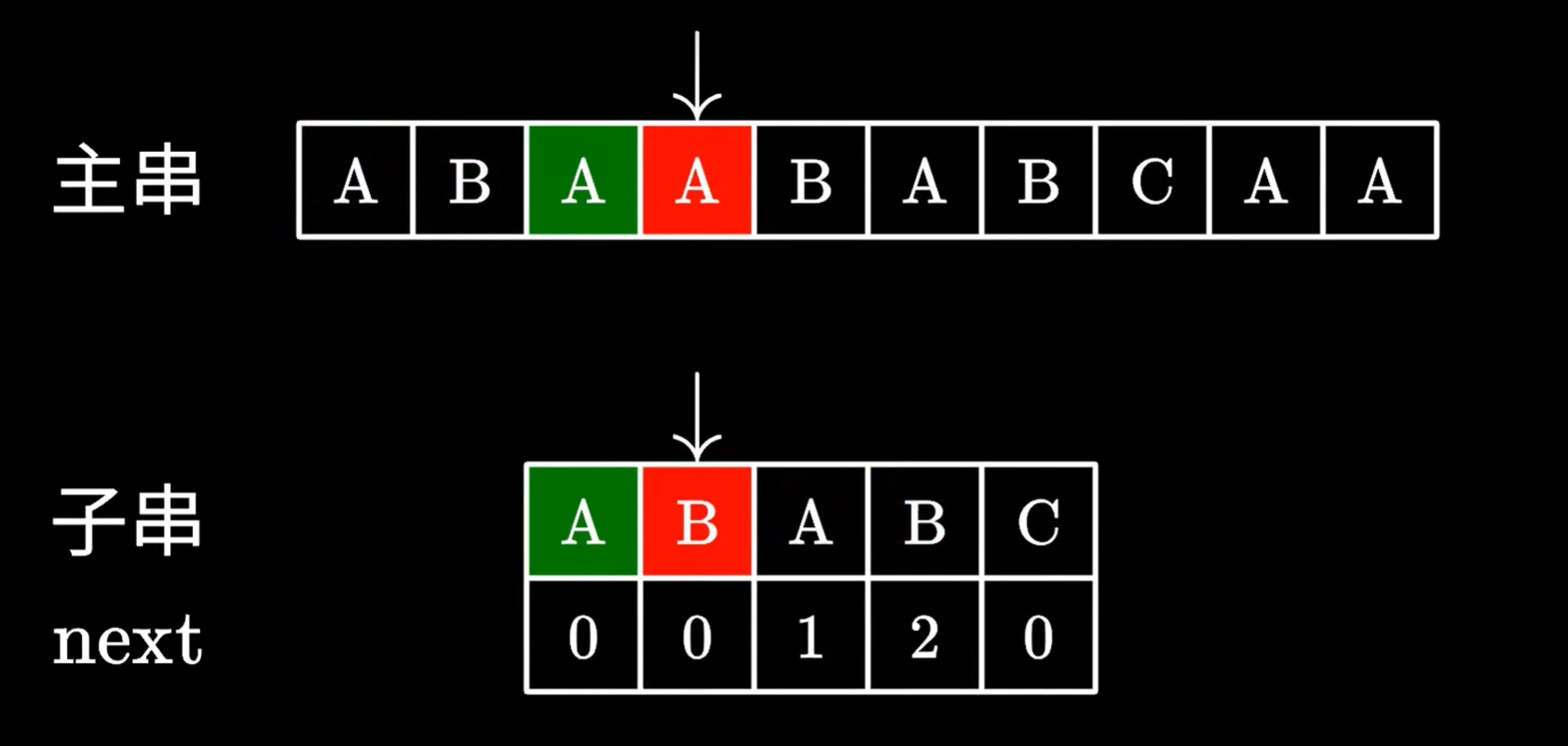
如果为0,也是从头开始匹配子串,没有相同的前缀和后缀,则子串一定不在已经遍历过的主串里有
则已经遍历过的主串里的字符,一定没有子串的子串,所以主串之前的部分可以直接舍弃,不用移动主串指针
推导next数组
next数组中的值,实际上就是,子串以当前字符串结尾,在当前字符串中,最长的前缀,后缀相同的字符串长度
如下图
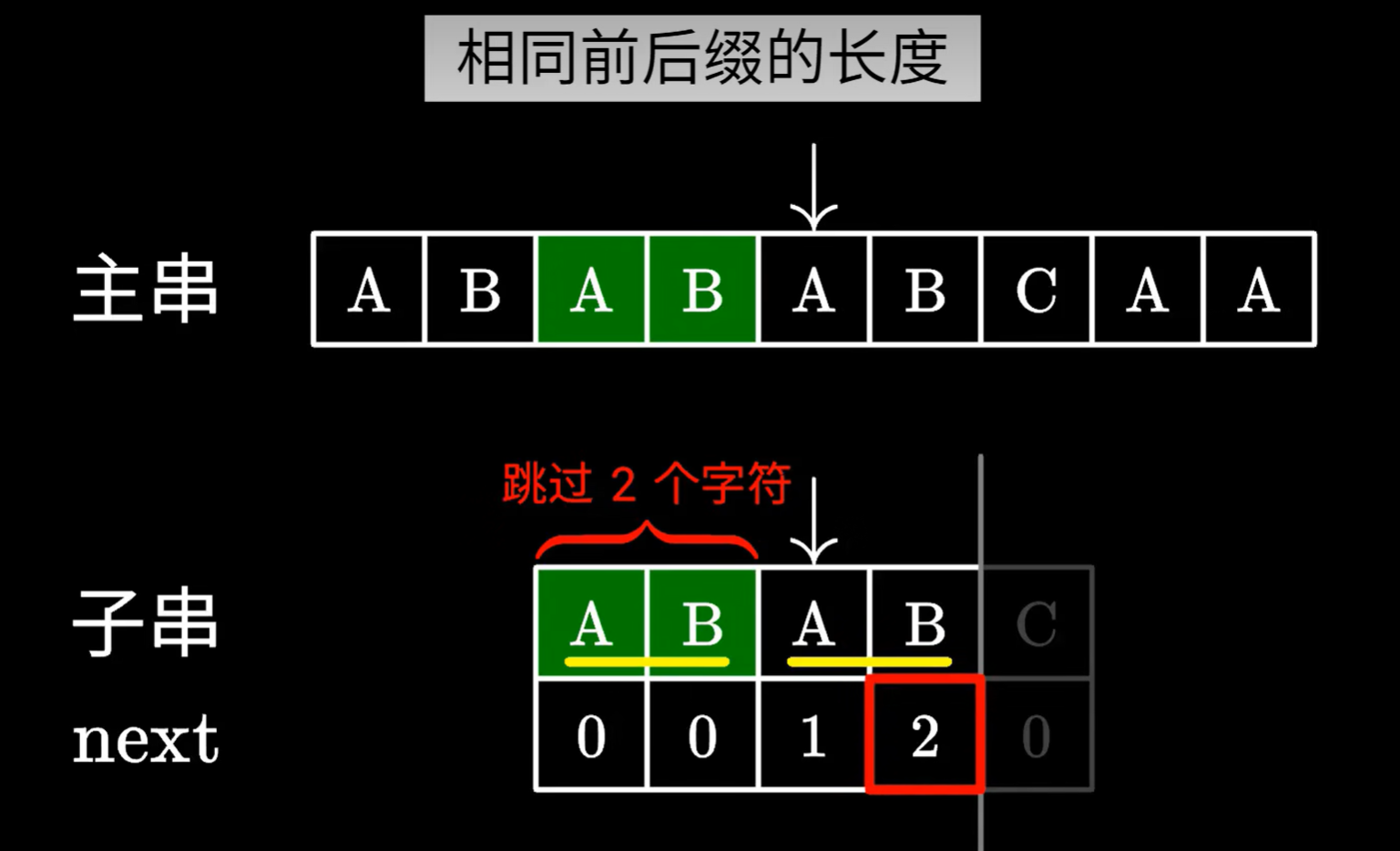
ABAB最长的相同前缀,后缀,该前缀或者后缀的长度是2
我们现在知道next的数组里的值代表什么了
那我们想一下,如何推导出next数组里的值
在后缀下一个字符,和前缀后一个字符相同时,我们只需要把next数组对应的值+1,然后填入即可

那在不同时,应该怎么办,循环遍历可以,但是时间复杂度较高
举例,上图再往下走一个
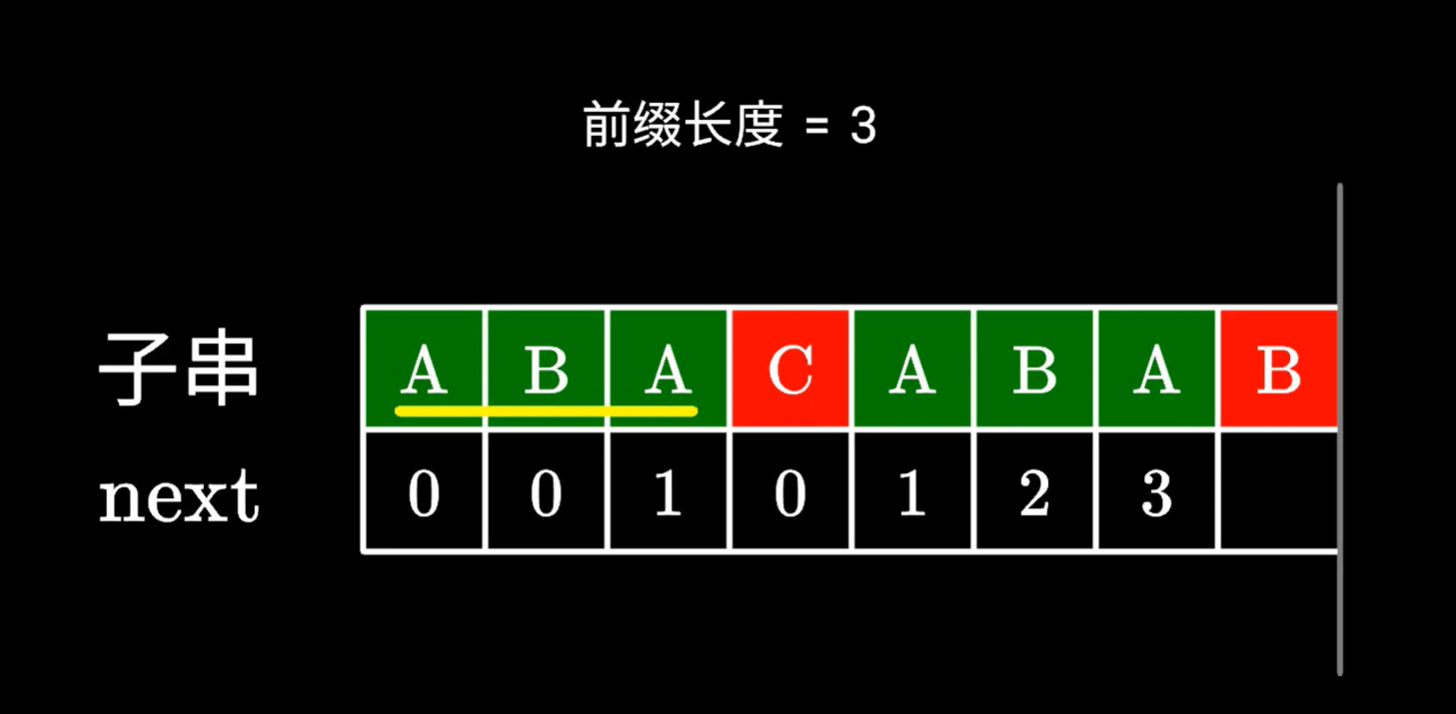
C和B不同,如何求B的对应的next值
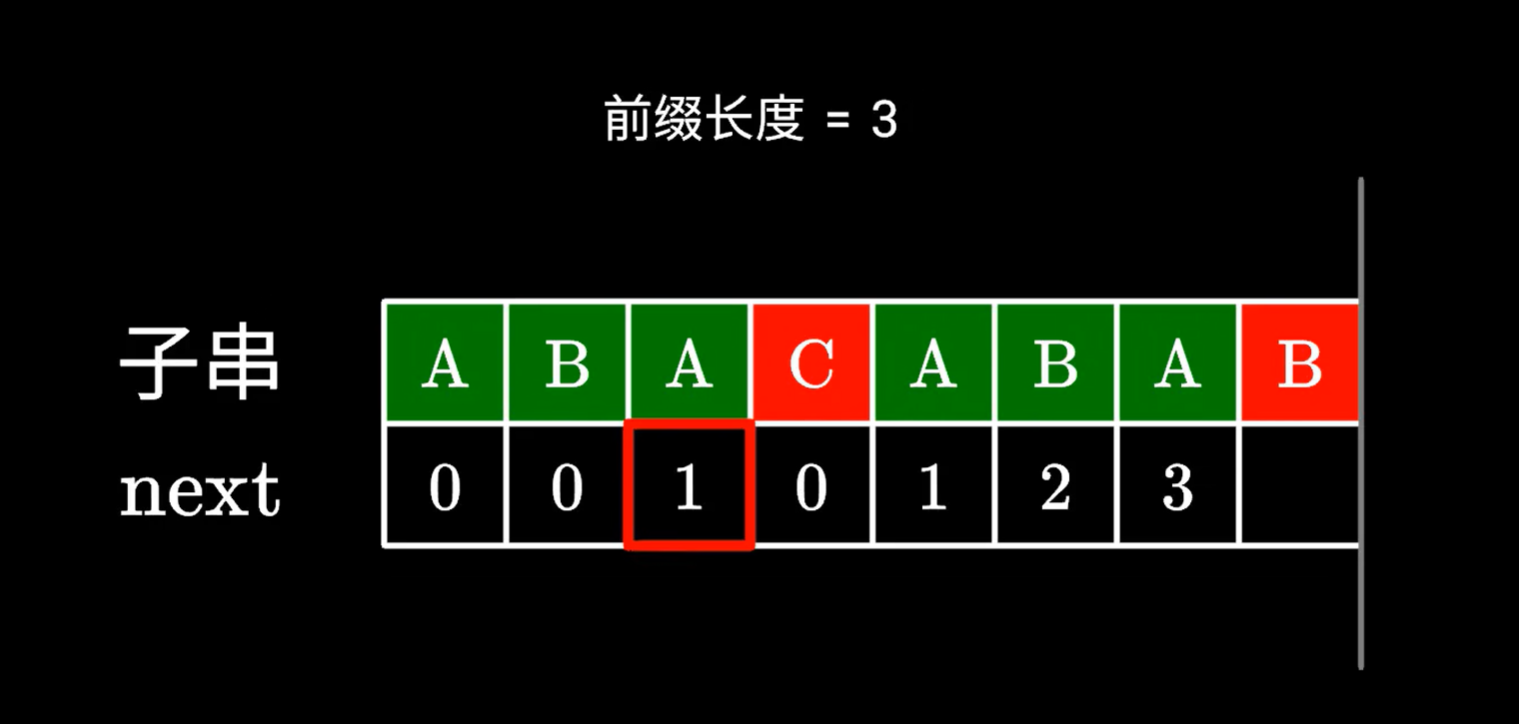
下位字符不同,没办法构成更长的相同前后缀,我们看看有没有更短的前后缀
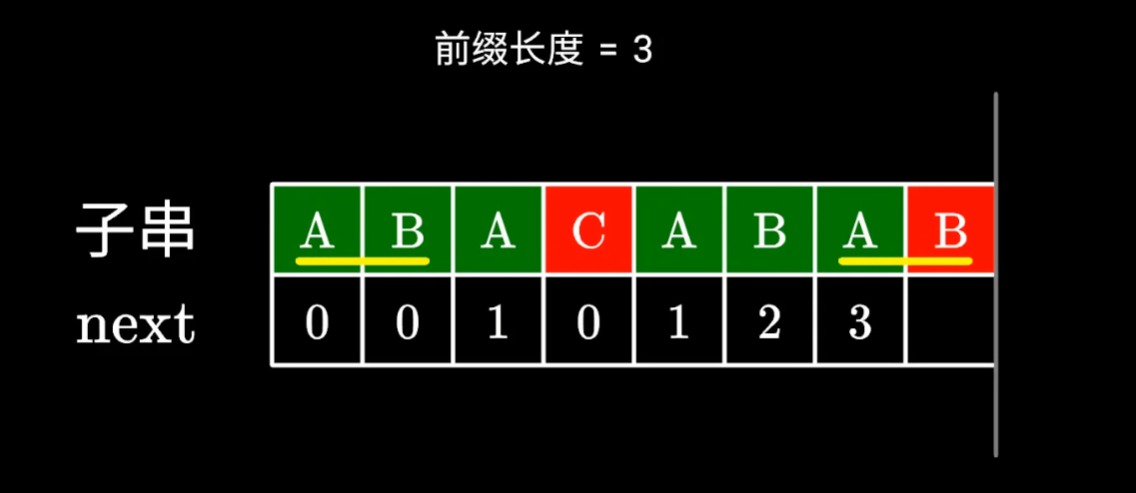
我们可以发现,确实存在更短的,两位的前后缀,但是这步在程序中如何体现,暴力求解似乎时间复杂度有点高
其实我们next数组里还有信息,也就是next[i]=3,则子串前3个数,和i-3到i,这两个字符串是相同的
字符串前三个字符,和i-3到i,就是前后缀,前三个数,和后三个数

也就是右边的后缀,其实等于左边的前缀,那我们其实可以忽略中间其他的值,直接去找到最左边
为什么不会有漏?第一,右边的后缀和左边的前缀完全相等
第二,后缀第四个字符和前缀第四个字符不同,所以不会比右边的后缀,或左边的前缀更长,也就不会用更多字符

这样,就相当于是求ABAB的前后缀
第三个A对应的值是1,B是字符串ABAB后缀的第二个字符(因为A对应的是1)
比较B和前缀的第二个字符是否相等
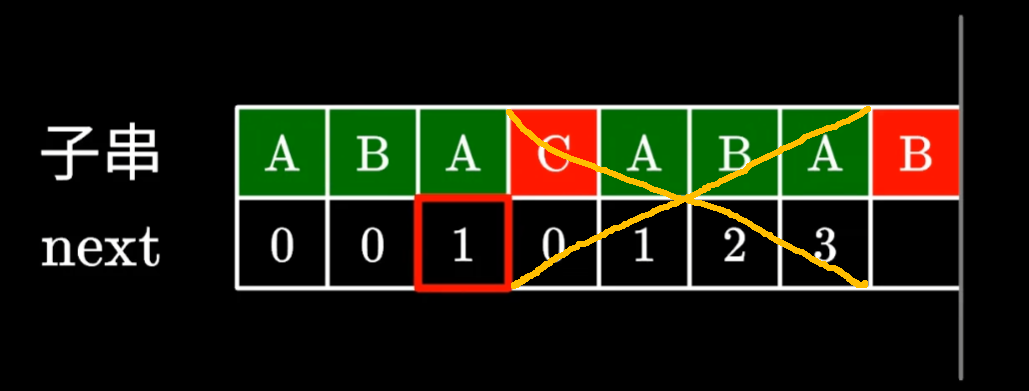
相等,则在B所处位置对应的next数组的值+1
B对应的next的数组的上一位的值,是通过第三个A获取的,但是实际上,和他组成后缀的是倒数第二个A
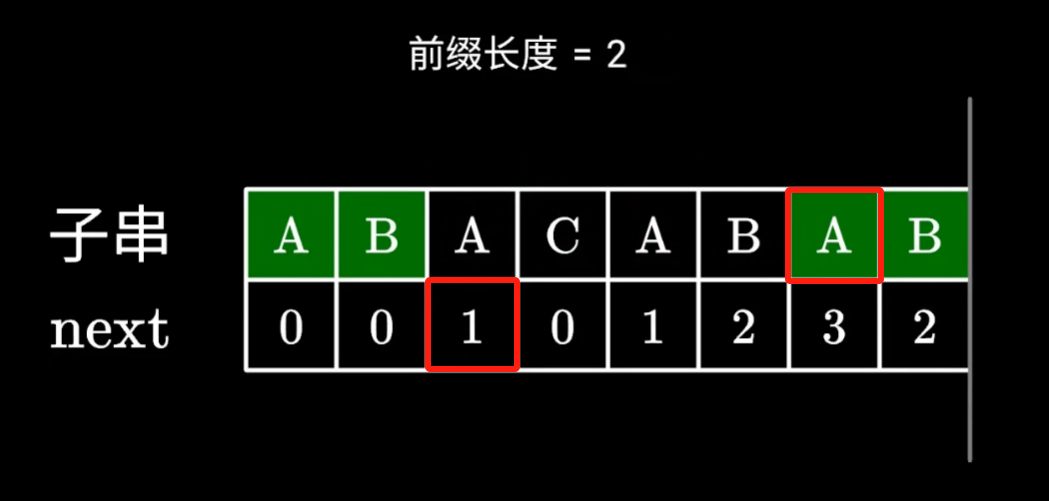
实际上是这样得到的next对应的值,抽象上是和第三个A组成的前后缀
因为倒数第二个A,对应的next的值为3,也就是和前三个字符前缀完全相等
所以可以直接拿第二个A的next计算,因为前三个字符,和后三个字符(这说的字符串next=3对应的A)完全一样
前三个有的字符,后三个都有,所以B可以和后三个字符组成的后缀,和前三个字符也可以组成相同的后缀
后三个字符代表的next值代表的前后缀相同的长度又太长,利用前三个字符代表的前后缀长度,即可完成回退
代码实现
next[i]代表子串p[1,i]相同前后缀的最大长度
i代表的指针,永远不往前回退,指向的是后缀的最后一个字符
j代表的指针,可以通过next数组回退,指向的是前缀最后一个字符
注:next在c++中有关键字,所以使用ne[]
next数组推导实现
ne[1]=0;
//两个字符串数组实际上都是从1开始
//i等于2是因为指向第二个字符即可,至少两个字符才有前后缀
//j=0,因为j从j+1开始比,也就是j=0是为了j从1开始
for(int i=2,j=0;i<=n;i++){ //j不为0,为0表示回到的子串第一个数的位置//i代表目前指到的位置,j代表相同前后缀的前缀的最后一个字符的位置//如果下位字符不同时,回退到j的值代表的前ne[j]位//上图中说前缀后缀完全相等,j回到相同的前缀的最后一个字符的位置//看ne[j]的下一位p[j+],和i指向的字符是否相等//相等结束循环,否则继续,直到相等或者j=0(回退到第一个字符串)while(j&&p[i]!=p[j+1])j=ne[j];//如果是相等,而不是j回退到了0,则j++,表示长度+1//j的值是ne[j]的值,j++= 就是 j=ne[j]+1,if(p[i]==p[j+1])j++;//记录下j的值,j现在指向的是相同前后缀的前缀的最后一个字符//代表的值是最长相同前后缀长度//把这个值加在ne[i]指针上,指向的是相同前后缀后缀的最后一个字符ne[i]=j;
} 子串位置查找实现,查找主串出现子串的起始位置
//推导子串出现位置,这次i等于1是因为,此循环判断的不是前后缀相同,而是判断是否为子串//因为两个完全一样的字符串,也互相为子串,子串第一个数有可能从i=1,j=1就开始了//所以这里要令i=1for(int i=1,j=0;i<=m;i++){//跳跃式找到主串现在指向的值,在子串中存在的位置while(j&&s[i]!=p[j+1])j=ne[j];//i指向主串的字符,和子串的字符下一个字符相等,则可以再推进走一步if(s[i]==p[j+1])j++;if(j==n)//长度一致,找到子串{cout<<i-j<<" ";//返回子串起始位置//可省略,意思是将j回退到除本身外,最大的相同前后缀长度,避免下个循环j+1越界j=ne[j];}}整合代码
AcWing - 算法基础课
#include<iostream>
using namespace std;
const int N = 100010;
char p[N],s[N*10];
int ne[N];
int n,m;
int main(){cin >> n >> p + 1 >> m >> s + 1;ne[1]=0;//推导nxet数组for(int i=2,j=0;i<=n;i++){while(j&&p[i]!=p[j+1])j=ne[j];if(p[i]==p[j+1])j++;ne[i]=j;}//推导子串出现位置for(int i=1,j=0;i<=m;i++){//跳跃式找到主串现在指向的值,在子串中存在的位置while(j&&s[i]!=p[j+1])j=ne[j];if(s[i]==p[j+1])j++;if(j==n)//长度一致,找到子串{cout<<i-j<<" ";//返回子串起始位置//可省略,意思是将j回退到除本身外,最大的相同前后缀长度,避免下个循环j+1越界j=ne[j];}}return 0;
}











![记录vite引入sass预编译报错error during build: [vite:css] [sass] Undefined variable.问题](https://i-blog.csdnimg.cn/direct/733518a0eb514899be645a5b3a9f2738.png)




