公众号作者@上杉翔二
悠闲会 · 信息检索
整理 | NewBeeNLP
上周,我们分享了对比学习的一些应用,从顶会论文看对比学习的应用!
本篇博文将继续整理一些对比学习的应用,主要是集中在MoCo和SimCLR等模型。
1、LCGNN
MoCo架构。基于标签对比编码的图分类图神经网络。
论文:Label Contrastive Coding based Graph Neural Network for Graph Classification
地址:https://arxiv.org/abs/2101.05486
一般做图分类的方法也是先学图的表示,主要有两种 ①先算node Embedding再聚合;② 直接graph Embedding,然后再做图分类。但是作者认为这些方法忽略了实例级的细粒度,而实例之间的判别式信息粒度更细有利于图分类任务。
 为了更有效、更全面地利用标签信息,提出基于标签对比编码的图神经网络(LCGNN),具体来说就是利用自监督学习中提出的标签对比损失来促进实例级的类内聚合性和类间可分性。
为了更有效、更全面地利用标签信息,提出基于标签对比编码的图神经网络(LCGNN),具体来说就是利用自监督学习中提出的标签对比损失来促进实例级的类内聚合性和类间可分性。
模型图如上图,基本上来说,LCGNN就是仿照的MoCo架构引入了动态标签存储库和动量更新编码器。
输入是key graphs和query graphs。
Graph encoder考虑两种,1是Graph Isomorphism Network(GIN),同构图就是简单GNN然后Sum聚合。2是Hierarchical Graph Pooling with Structure Learning (HGP-SL),它可以将图池化和结构学习结合到一个统一的模块中以生成图的层次表示。
后面的部分就和MoCo一致了。有一个Memory Bank,然后Momentum Update。
最后的loss有label constructive和classification组成。
这个设计本质上可以被认为是一种标签增强。然后将具有相同标签的实例拉近,而具有不同标签的实例将相互推开。
2、VideoMoCo
来自CVPR21的文章,架构也是基于MOCO,任务是无监督视频表示学习。
论文:VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
地址:https://arxiv.org/abs/2103.05905
代码:https://github.com/tinapanpt/VideoMoCo
 主要的架构如上图,也比较好理解,就是对出视频序列从两个视角改善MoCo的时间特征表示,如上图的ab或者cd,其中一个视角是通过丢弃帧来完成的,主要涉及到:
主要的架构如上图,也比较好理解,就是对出视频序列从两个视角改善MoCo的时间特征表示,如上图的ab或者cd,其中一个视角是通过丢弃帧来完成的,主要涉及到:
生成器。在时间上删除几个帧,且是自适应地丢弃不同的帧,这通过时间衰减来完成。
鉴别器。完成特征表示,无论帧移除如何。
然后对两个view进行类似MoCo的对比学习。即使用时间衰减来模拟内存队列中的键(key)衰减,其中动量编码器在键进入后进行更新,当使用当前输入样本进行对比学习时,这些键的表示能力会下降。这种下降通过时间衰减反映出来,以使输入样本进入队列中的最近键。
3、GraphCL
上一篇是MoCo思路,这一篇来自NIPS20的文章GraphCL则和SimCLR的思路一样的,即用各种各样的数据增强方法之后再对比学习。
论文:Graph Contrastive Learning with Augmentations
地址:https://arxiv.org/abs/2010.13902
代码:https://github.com/Shen-Lab/GraphCL
 动机是传统的Graph模型会有over-smoothing or information loss这种问题,所以作者认为开发预训练技术是很有必要的。完整架构如上图,基本就是SimCLR的套路了。其中而GraphCL开发了4种增强的模式:
动机是传统的Graph模型会有over-smoothing or information loss这种问题,所以作者认为开发预训练技术是很有必要的。完整架构如上图,基本就是SimCLR的套路了。其中而GraphCL开发了4种增强的模式:
节点丢弃。随机丢弃某些部分顶点及其连接。这意味着缺少部分顶点不影响图的语义。
边扰动。通过随机添加或丢弃一定比例的边来扰动图中的连接性。这意味着边的连接模式具有一定的鲁棒性。
属性掩码。使用其上下文信息(即剩余属性)恢复masked的顶点属性。基本假设是缺少部分顶点属性不会对模型预测产生很大影响。
子图。使用随机游走采样一个子图,它假设图的语义可以在局部结构中得到很大的保留。
属性增强完成后,用GNN来encoder(即图中的黄色部分),然后再Projection head,Contrastive loss,这一些就和SimCLR一样了。
4、XMC-GAN
来自CVPR 2021:
论文:Cross-Modal Contrastive Learning for Text-to-Image Generation
地址:https://arxiv.org/abs/2101.04702v2
这篇的应用场景是用于文本到图像的生成。整体的架构也和SimCLR很像。首先由于背景是跨模态图像生成,所以对于生成的图片要求输出
连贯的。文本和图片的语义要整体匹配。
清晰的。图像的局部也是可识别,且和文本的词一致。
还原度高的图片。在条件一致时生成图像应该与真实图像相似。
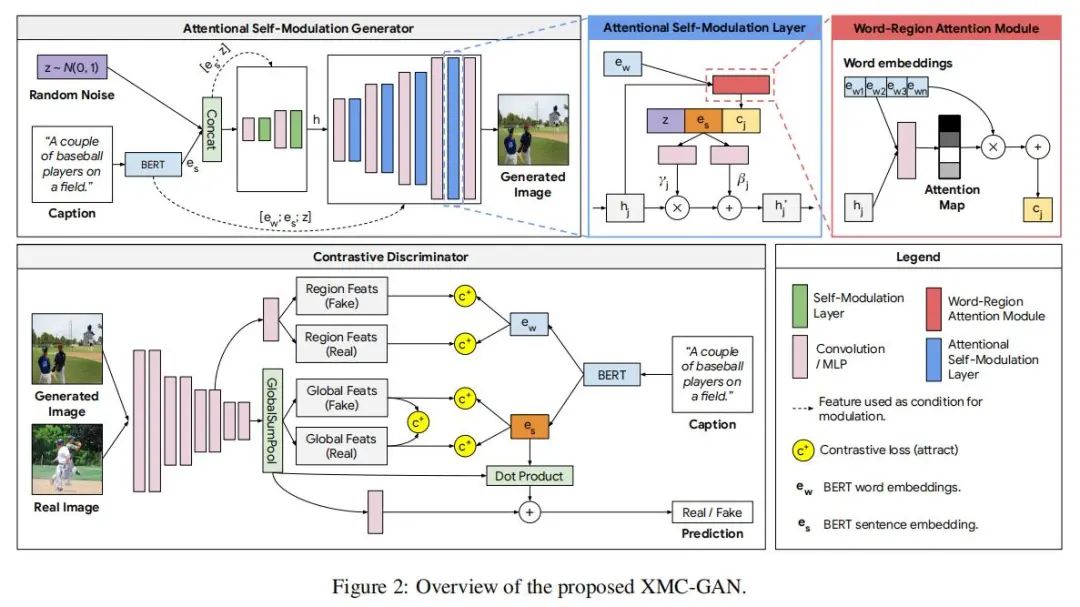 为了解决这个问题,作者提出了一个基于最大化图像和文本之间互信息的跨模态对比生成对抗网络(XMC-GAN)。具体架构如上图,XMC-GAN使用了一个注意力自调节生成器用于加强文本-图像之间的对应关系(其实就是将噪音,词注意力,整体表征融合,具体如上半部分图的套娃),同时使用了一个对比判别器用作对比学习的特征抽取器,这里设计了三种以强制对齐生成的图像和文本:
为了解决这个问题,作者提出了一个基于最大化图像和文本之间互信息的跨模态对比生成对抗网络(XMC-GAN)。具体架构如上图,XMC-GAN使用了一个注意力自调节生成器用于加强文本-图像之间的对应关系(其实就是将噪音,词注意力,整体表征融合,具体如上半部分图的套娃),同时使用了一个对比判别器用作对比学习的特征抽取器,这里设计了三种以强制对齐生成的图像和文本:从图像到句子。直接算特征的对比损失。
图像区域到单词。计算句子中所有单词与图像中所有区域之间的成对余弦相似矩阵,然后算对比损失。
图像到图像对比损失。算真图像和假图像的对比损失。
5、ContraD
论文:TRAINING GANS WITH STRONGER AUGMENTATIONS VIA CONTRASTIVE DISCRIMINATOR
地址:https://arxiv.org/abs/2103.09742
代码:https://github.com/jh-jeong/ContraD
ICLR2021的文章,把GAN和对比学习也结合起来,做一个对比形式的判别器吧。特别是关于GAN的数据增强技术是可以在一定程度上稳定GAN训练,所以看起来对比学习+GAN是很合适的搭配。
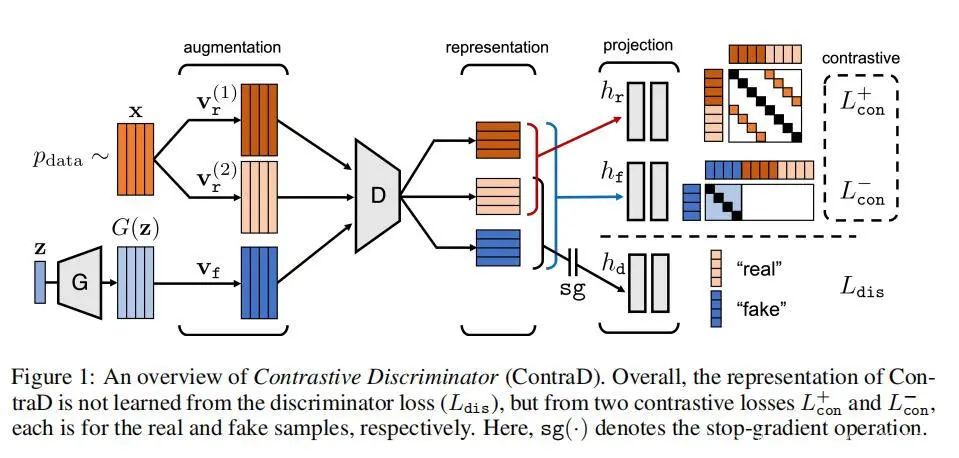 所以沿着增强的思路,这篇文章也是SimCLR的一类,模型架构如上,生成器可以得到多个样本,然后一起被送到D中,主要的贡献就是提出了Contrastive Discriminator (ContraD)。
所以沿着增强的思路,这篇文章也是SimCLR的一类,模型架构如上,生成器可以得到多个样本,然后一起被送到D中,主要的贡献就是提出了Contrastive Discriminator (ContraD)。
ContraD的主要目标不是最小化GAN的鉴别器损失,而是学习一种与GAN兼容的对比表示。这意味着目标不会破坏对比学习,而表示仍然包含足够的信息来区分真实和假样本,因此一个小的神经网络鉴别器足以对表示执行其任务。
loss的组成由两部分,一个是SimCLR的loss,同时因为需要分清正负样本仅仅对比学习也是不够的,所以仍然需要dis loss来辅助训练。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -


京东:个性化语义搜索在电商搜索中的应用
2021-11-24

KDD 2021 | 推荐系统论文集锦[持续更新]
2021-11-16

NLP 语义匹配:经典前沿方案整理
2021-11-10

高效深度学习:让模型更小、更快、更好!
2021-11-03