移情别恋c++ ദ്ദി˶ー̀֊ー́ ) ——14.哈希(1)
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到== l o g 2 N log_2 N log2N==,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个 u n o r d e r m a p \color{red}{unordermap} unordermap系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是 其**底层结构不同**
1. unordered_map
unordermap文档
unordered_map:
unordered_map是一种关联容器,它存储的是键值对(key-value pairs),并且键是唯一的。它使用哈希表来快速查找键。
特点:
- 键值对存储:每个元素是一个
std::pair<const Key, T>,其中Key是键,T是对应的值。 - 无序存储:元素在哈希表中是无序存储的,插入的顺序不保证元素的顺序。
- 唯一键:同一个键只能存在一个,如果插入相同键,会覆盖原有键对应的值。
- 时间复杂度:查找、插入、删除的平均时间复杂度是O(1),但在最坏情况下,复杂度可能退化为O(n),比如在哈希冲突严重的情况下。
常用操作:
- 插入:
umap.insert({key, value})或umap[key] = value - 查找:
umap.find(key)返回迭代器,如果找不到则返回umap.end() - 删除:
umap.erase(key)或umap.erase(迭代器) - 访问元素:
umap[key]如果键不存在,会自动插入该键并赋值为T()(默认构造值) - 大小:
umap.size()返回元素个数
适用场景:
unordered_map适合需要频繁进行键值对查找、插入、删除的场景,特别是在不关心元素顺序的情况下。比如统计元素频次、缓存(cache)实现等。
2. unordered_map的接口说明
1.unordered_map的构造
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map | 构造不同格式的unordered_map对象 |
2.unordered_map的容量
| 函数声明 | 功能介绍 |
|---|---|
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
3. unordered_map的迭代器
| begin | 返回unordered_map第一个元素的迭代器 |
|---|---|
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
4.unordered_map的元素访问!!!
| 函数声明 | 功能介绍 |
|---|---|
| operator[] | 返回与key对应的value,若没有key则插入一个,并返回value默认值 |

5.unordered_map的查询
| iterator find(constK& key) | 返回key在哈希桶中的位置 |
|---|---|
| size_t count(constK& key) | 返回哈希桶中关键码为key的键值对的个数 |
注意:**key是不能重复**的,因此count函数的返回值最大为1
6.unordered_map的修改操作
| insert | 向容器中插入键值对 |
|---|---|
| erase | 删除容器中的键值对 |
| clear | 清空容器中有效元素个数 |
| void swap(unordered map&) | 交换两个容器中的元素 |

3. unordered_set:
unordered_set也是一个哈希容器,但它只存储唯一的键(没有值),也就是说它只关心元素是否存在,而不关心元素的具体值。
特点:
- 元素唯一:集合中的每个元素是唯一的,不能包含重复元素。
- 无序存储:元素以无序的方式存储,插入顺序不影响元素的排列顺序。
- 哈希表实现:与
unordered_map一样,unordered_set基于哈希表实现。 - 时间复杂度:查找、插入、删除的平均时间复杂度是O(1),但在最坏情况下也可能退化为O(n)。
常用操作:
- 插入:
uset.insert(element)插入元素 - 查找:
uset.find(element)查找元素,返回迭代器,如果找不到则返回uset.end() - 删除:
uset.erase(element)或uset.erase(迭代器) - 判断是否存在:
uset.count(element)返回元素是否存在,存在返回1,不存在返回0 - 大小:
uset.size()返回集合中元素的个数
适用场景:
unordered_set适合需要频繁进行集合操作的场景,比如元素去重、快速查找某个元素是否存在等。
4.小习题
https://leetcode.cn/problems/n-repeated-element-in-size-2n-array/description/

class Solution {
public:int repeatedNTimes(vector<int>& nums) {int length = nums.size()/2;unordered_map<int, int> it;for (auto& e : nums) {it[e]++;}for (auto e : it) {if (e.second == length) {return e.first;}}return 1;//这里只是象征性地写一个return 1,不然会报错}
};
https://leetcode.cn/problems/uncommon-words-from-two-sentences/description/

class Solution {
public:vector<string> uncommonFromSentences(string s1, string s2) {vector<string> arr;vector<string> brr;vector<string> crr;string it;it.clear();for(auto e:s1){if(e==' '||e=='\0'){arr.push_back(it);it.clear();}elseit+=e;}arr.push_back(it);it.clear();map<string,int> a1;for(auto e:arr){a1[e]++;}for(auto e:s2){if(e==' '||e=='\0'){brr.push_back(it);it.clear();}elseit+=e;}brr.push_back(it);it.clear();map<string,int> a2;for(auto e:brr){a2[e]++;}auto it1=a1.begin();auto it2=a2.begin();while(it1!=a1.end()&&it2!=a2.end()){if(it1->first!=it2->first){if(it1->first<it2->first){if(it1->second==1)crr.push_back(it1->first);it1++;}else{if(it2->second==1)crr.push_back(it2->first);it2++;}}else{it1++;it2++;}}while(it1!=a1.end())
{if(it1->second==1)crr.push_back(it1->first);it1++;
}while(it2!=a2.end())
{if(it2->second==1)crr.push_back(it2->first);it2++;
}return crr;}
};
5.底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希概念:
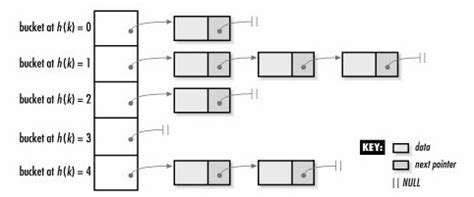
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素 时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即 O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数。 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立 一一**映射**的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
- 插入元素 根据待插入元素的关键码,以此函数==计算出该元素的
存储位置==并按此位置进行存放- 搜索元素 对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置 取元素比较,若关键码相等,则搜索成功
储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立 一一**映射**的关系,那么在查找时通过该函数可以很快找到该元素。
3. 二者的对比:
| 特性 | unordered_map | unordered_set |
|---|---|---|
| 存储内容 | 键值对(key-value pairs) | 唯一元素(unique elements) |
| 键是否唯一 | 是 | 是 |
| 值 | 有 | 无 |
| 时间复杂度 | 平均O(1)(最坏O(n)) | 平均O(1)(最坏O(n)) |
| 顺序保证 | 无序 | 无序 |
| 适用场景 | 键值对的快速查找、插入、删除 | 元素集合的快速查找、插入、删除 |
4. 小结:
- 如果需要存储键值对并希望能够通过键快速访问相应的值,
unordered_map是更好的选择。 - 如果仅需要存储唯一的元素并希望进行集合操作(如查找、插入、删除),
unordered_set更为合适。
两者的核心思想都是通过哈希函数来定位元素,从而提供快速的访问和操作。










![mybatisPlus对于pgSQL中UUID和UUID[]类型的交互](https://i-blog.csdnimg.cn/direct/cc78662826a24c98884ab47ba13026b4.png)