爬虫post请求
这一篇文章, 我们开始学习爬虫当中的post请求。
在讲post请求之前, 我们先来回顾一下get请求。
get请求:
get请求的参数有三个, get(url, headers, params), 其中, params是可写可不写的。headers是请求头, 这个请求头在开发者工具里面的网络, 找到相应的请求, 然后在最后面有个user-agent, 那个就是请求头里面的内容, 也称之为伪装。
咱们正式进入正题, post请求!
post请求:
post请求, 和get请求也相似, 请求的参数也有三个, get(url, headers, data), 其中, data是必须写的。headers也是请求头, 这个请求头在开发者工具里面的网络, 找到相应的请求, 然后在最后面有个user-agent, 那个就是请求头里面的内容, 也称之为伪装。
我们举个案例:
url:https://www.bkchina.cn/product/hamburg.html
我们需要爬取这个网站的信息, 在小食栏里面爬取下面小食的名字。
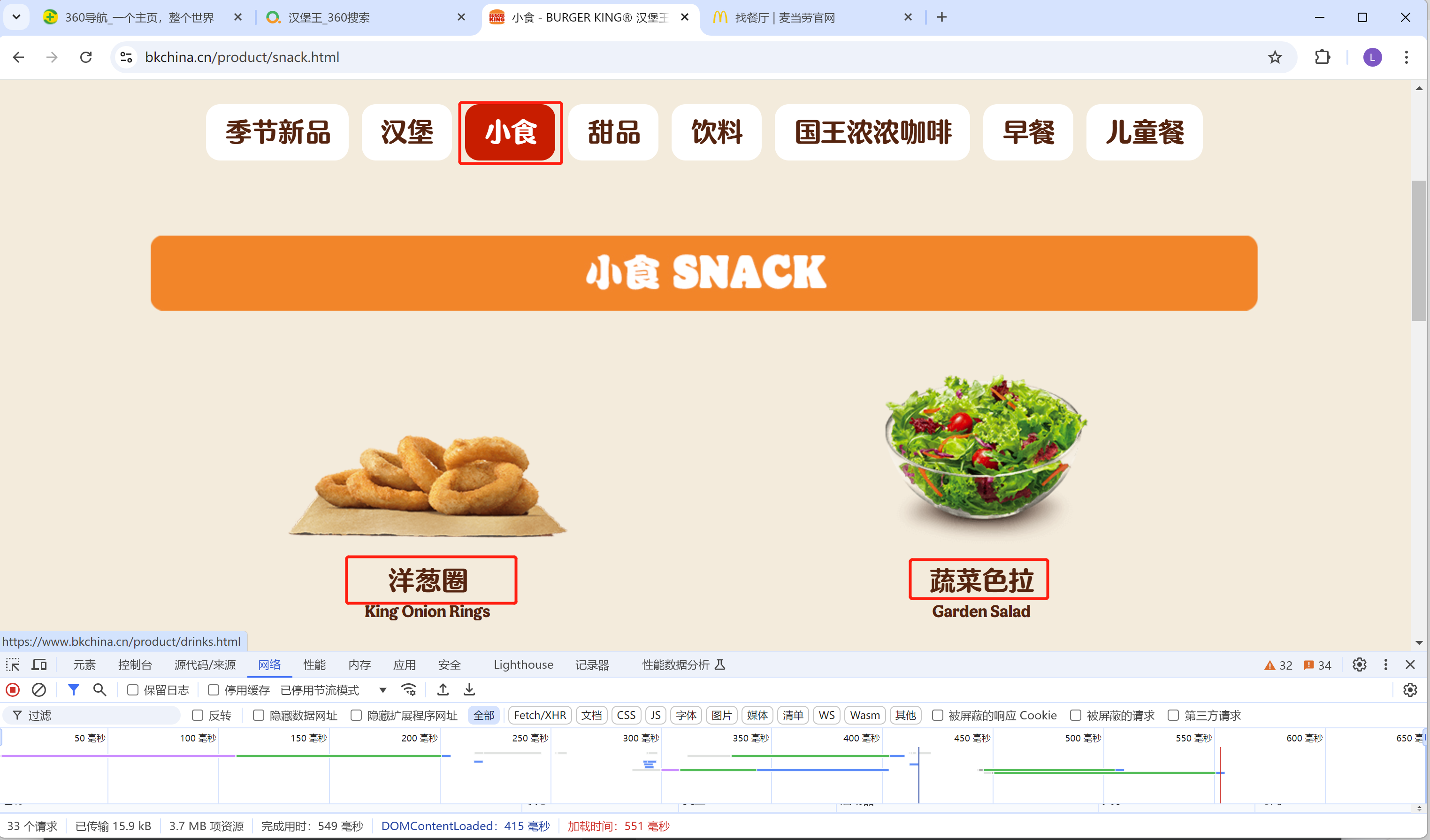
首先我们还是和往常一样, 去找到相应的请求。
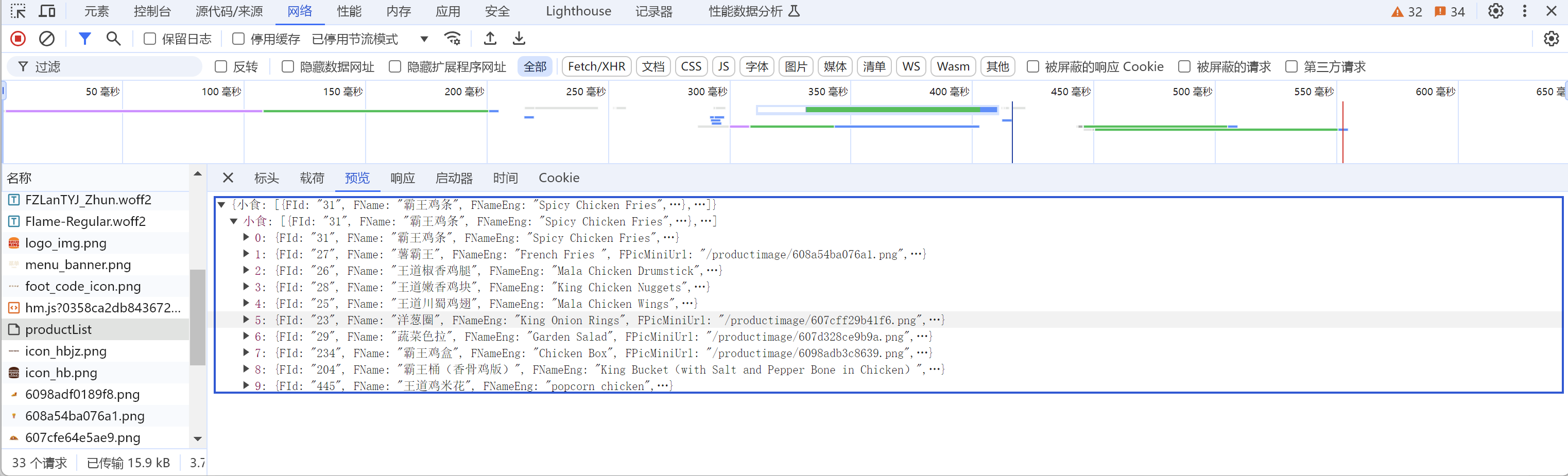
我们可以发现, 这个就是我们需要找到的请求。
这个请求的url是https://www.bkchina.cn/product/productList
好, 那我们就结合这个案例, 去讲解如何使用post请求
代码:
# 所有商品的url
url = 'https://www.bkchina.cn/product/productList'
import requests
# 第1个参数:url 目标网址
# 第2个参数:data post请求的参数
# 一般post请求都需要带上参数,参数不会直接跟在url后面
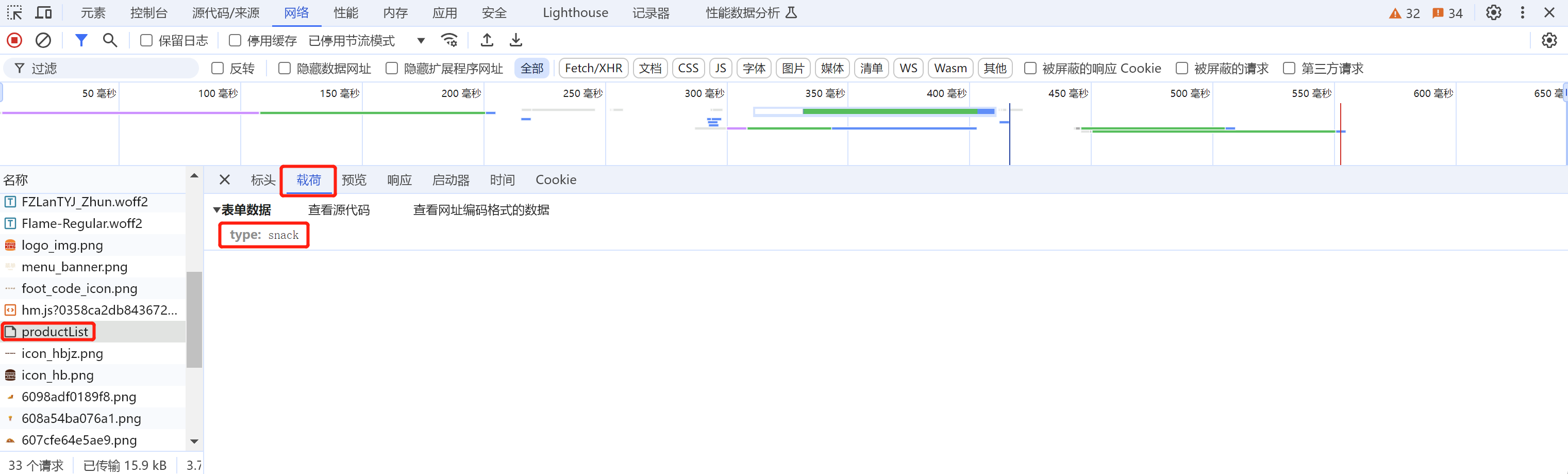
# 从载荷中看post请求的参数:
# 表单数据:定义字典,保存参数
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
# 定义字典,保存参数
data = {'type':'snack'
}
res = requests.post(url,headers=headers,data=data)
# print(res.text)
# 获取响应的内容 交给res_data保存
res_data = res.json()
count = 1
for i in res_data['小食']:print(count,i['FName'])
结果:
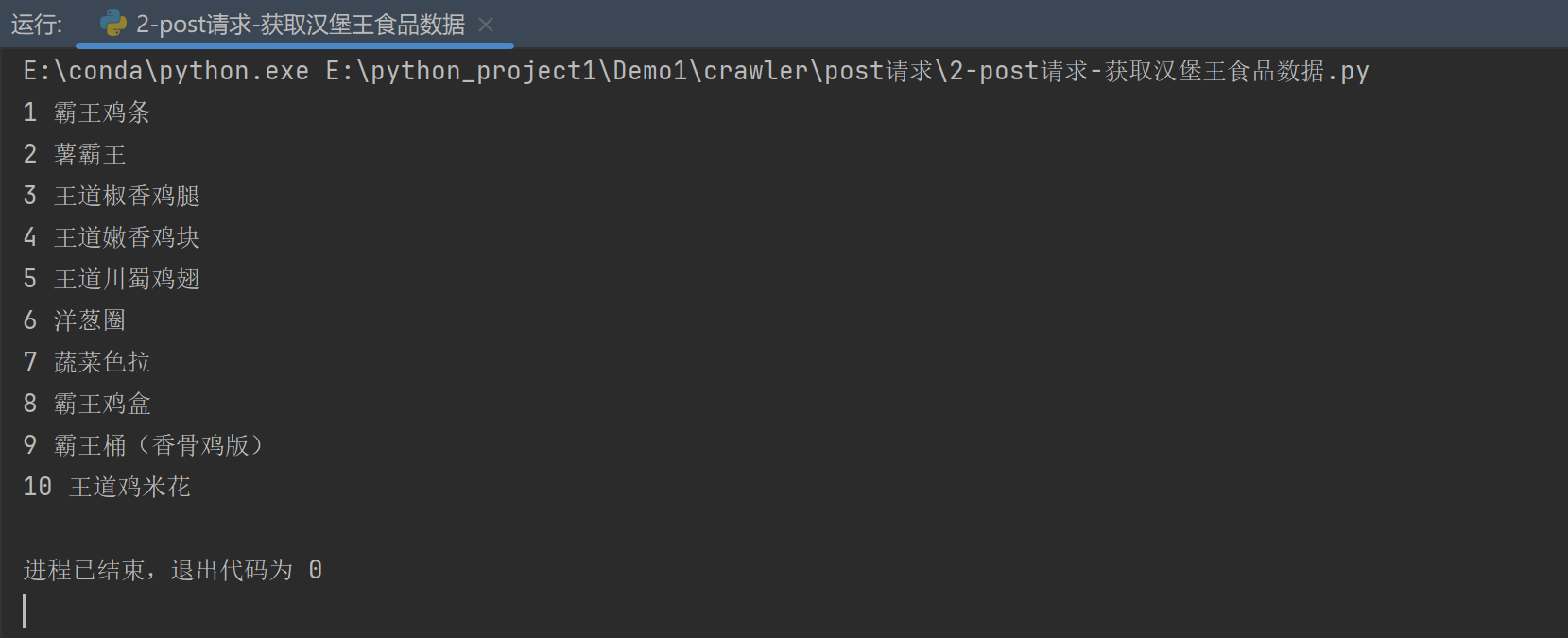
我们成功的爬取到了我们想要的数据。
解释一下那个data里面的参数是从哪里来的?
答案: 我们在对应的请求里面找到载荷, 里面就能够看到参数了。所有data = {“type”: “snack”}是这么来的。
我们完善一下上面的代码:
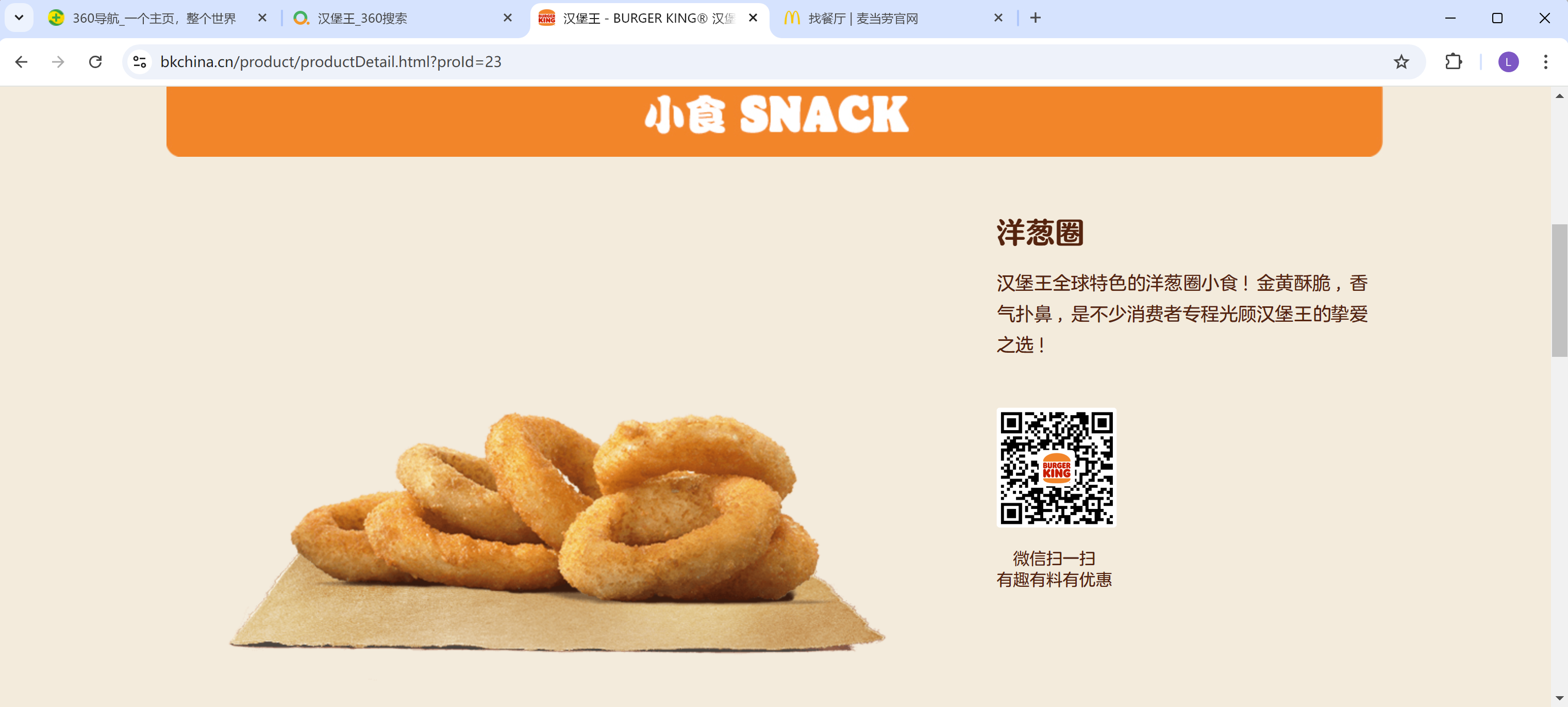
我们不仅需要爬取到小食的名称, 我们还想爬取那个食物对应的简介。
我们点击洋葱圈, 然后再页面的右边有串文字, 就是对该食品的介绍。
我们还是一样, 打开开发者工具:
找到对应的请求叫detail
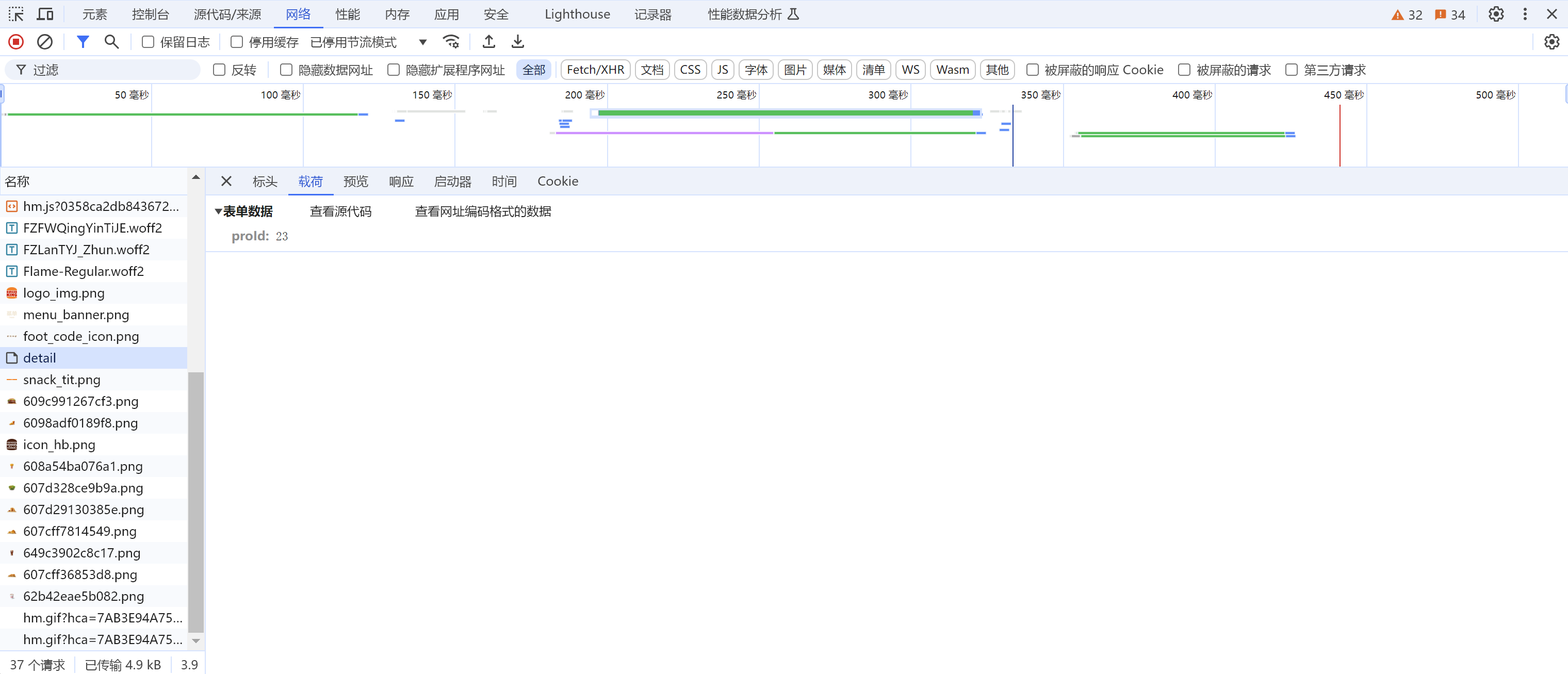
这个请求的url是https://www.bkchina.cn/product/detail
这个请求的载荷是proId: 23。那我们请求的时候就要加上data={“proId”: 23}。
代码:
# 所有商品的url
url = 'https://www.bkchina.cn/product/productList'
# 商品的详情页的url
d_url = 'https://www.bkchina.cn/product/detail'
import requests
# 第1个参数:url 目标网址
# 第2个参数:data post请求的参数
# 一般post请求都需要带上参数,参数不会直接跟在url后面
# 从载荷中看post请求的参数:
# 表单数据:定义字典,保存参数
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
# 定义字典,保存参数
data = {'type':'snack'
}
res = requests.post(url,headers=headers,data=data)
# print(res.text)
# 获取响应的内容 交给res_data保存
res_data = res.json()
count = 1
for i in res_data['小食']:print(count,i['FName'])count+=1# 基于每一个食物获取到它的介绍词?这个请求应该写在哪里?# 只能获取到编号为27的商品详情数据# d_data = {# 'proId':27# }# 每循环一次拿到一个商品,就需要额外获取当前循环的商品id# post请求的参数,浏览器的载荷d_data = {'proId': i['FId']}d_res = requests.post(d_url,data=d_data)# 详情页数据d_res_data = d_res.json()# 获取介绍词print(d_res_data['FDesc'])
结果:

我们来看下这串代码是怎么回事。
# post请求的参数,浏览器的载荷
d_data = {'proId': i['FId']
}
我们再打开之前请求的url
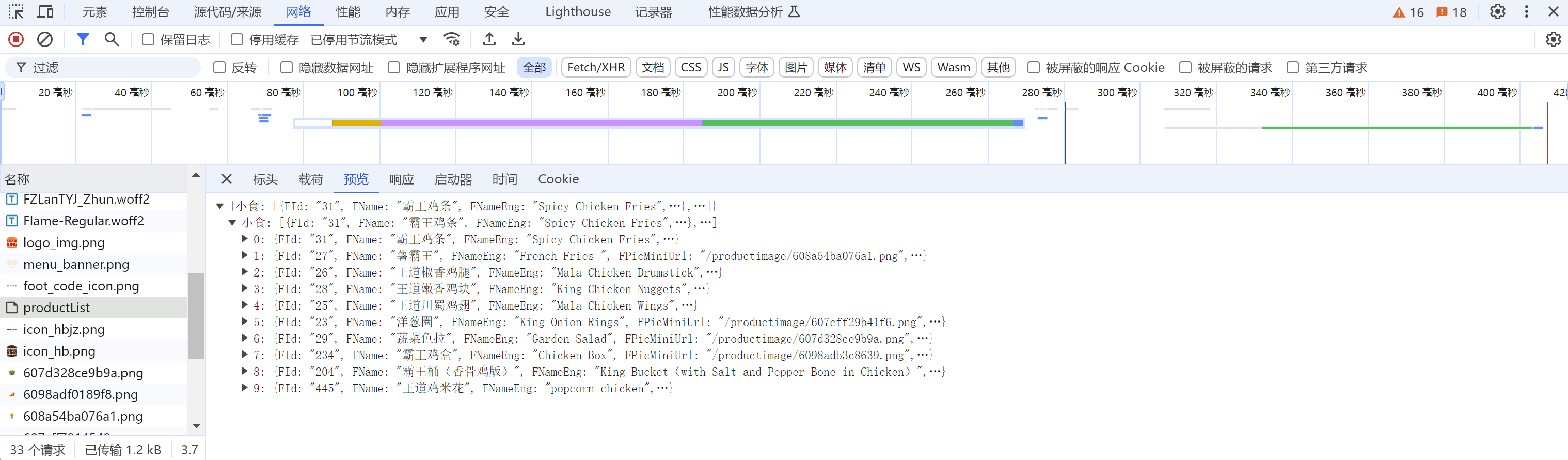
找到响应。发现里面每一个食品都有一个FId,正好我们要传入的data里面就有FId, 那我们的思路就是把每一个食品的FId全部取出来, 正好在前面一个请求的时候, 通过了一个循环, 全部取出来了。
实战:
1- 点击某个详细地址,获取当前详细地址下的所有麦当劳的餐厅
2- 完善:根据搜索的关键字获取所有详细地址下的所有麦当劳的餐厅
需要爬取的网页的网址:https://www.mcdonalds.com.cn/top/map(这是一个麦当劳餐厅)
先不要看答案, 自己尝试先做一做哦。
参考答案:
题1.
例:
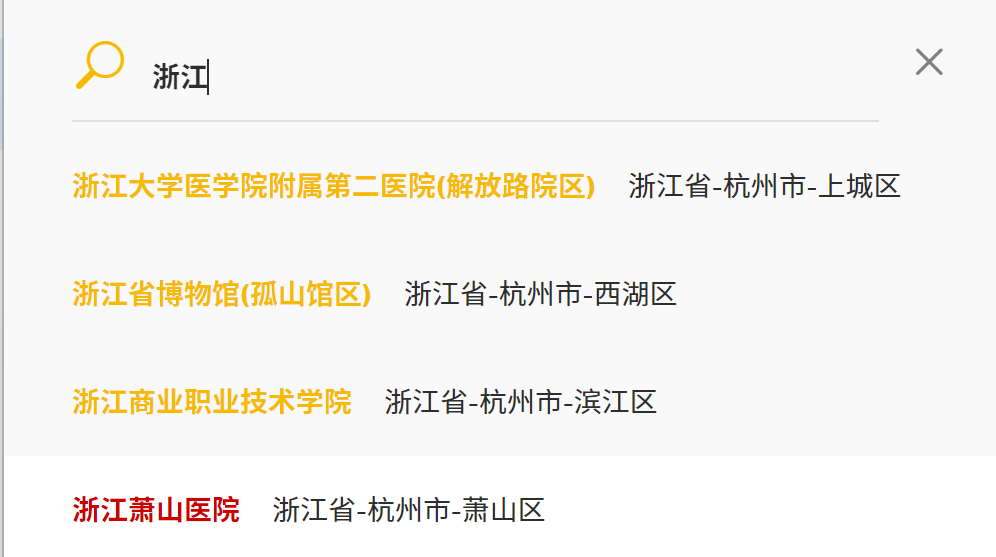
输入浙江, 浙江萧山医院点进去
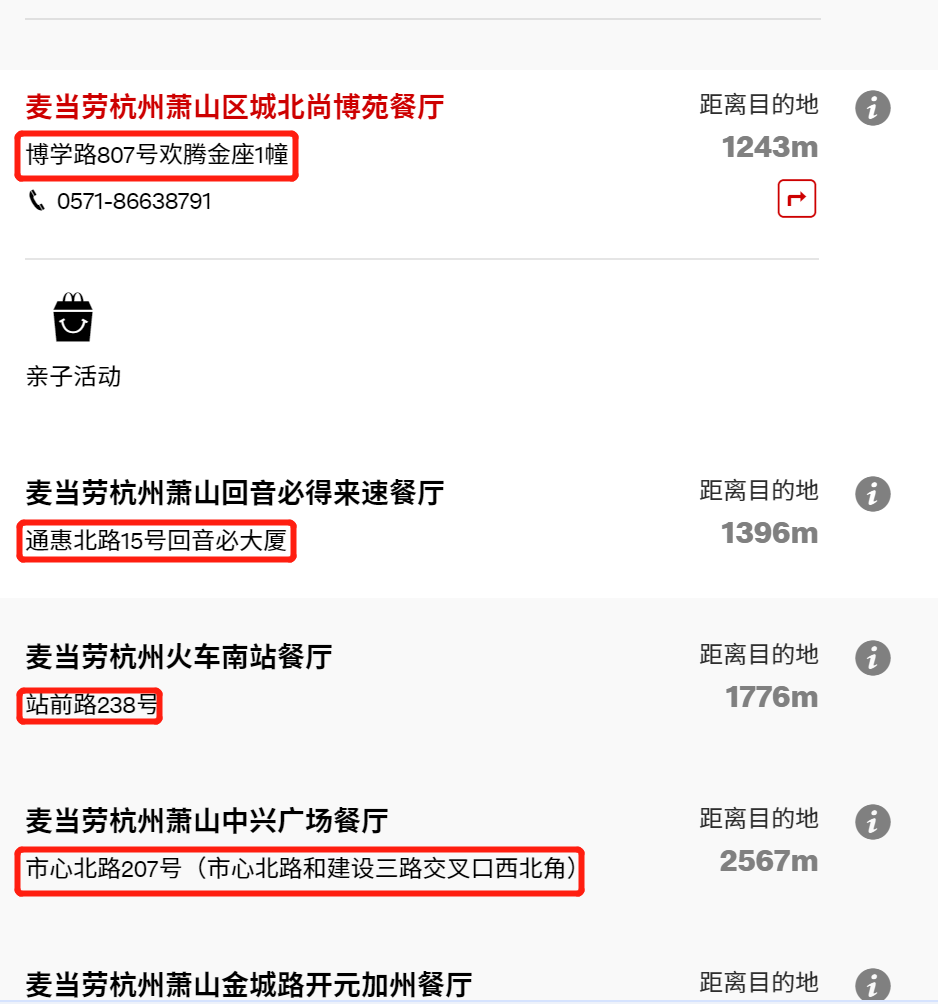
爬取红色框里面的信息(也就是麦当劳的详细地址)。
代码:
import requestsurl = 'https://www.mcdonalds.com.cn/ajaxs/search_by_point'
header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
data = {"point": "30.183907,120.279628"
}
response = requests.post(url, headers=header, data=data)
print(response.json())
res_data = response.json()
for i in res_data['data']:print(i["address"])
结果:

题2:
在控制台输入关键字地区, 返回地址(这个地址相当于在网页搜索出来的全部详细地址, 一个关键字能够搜索10个地区, 每一个地区里面都有很多个麦当劳的详细地址)。
代码:
import requestsurl = "https://www.mcdonalds.com.cn/ajaxs/search_by_keywords"
d_url = 'https://www.mcdonalds.com.cn/ajaxs/search_by_point'
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
location = input("请输入关键字地址:")
data = {"keywords": location,"city": "杭州市","location[info]": "OK","location[position][lng]": 120.26457,"location[position][lat]": 30.18534
}
response = requests.post(url, headers=headers, data=data)
# print(response.json())
res_data = response.json()
print(f"{location}的麦当劳餐厅的地址:")
for i in res_data['data']:# 纬度lat = i['location']['lat']# 经度lng = i['location']['lng']d_data = {"point": f"{lat},{lng}"}response = requests.post(d_url, headers=headers, data=d_data)d_res_data = response.json()for i in d_res_data['data']:# 地址print(i['address'])
结果:
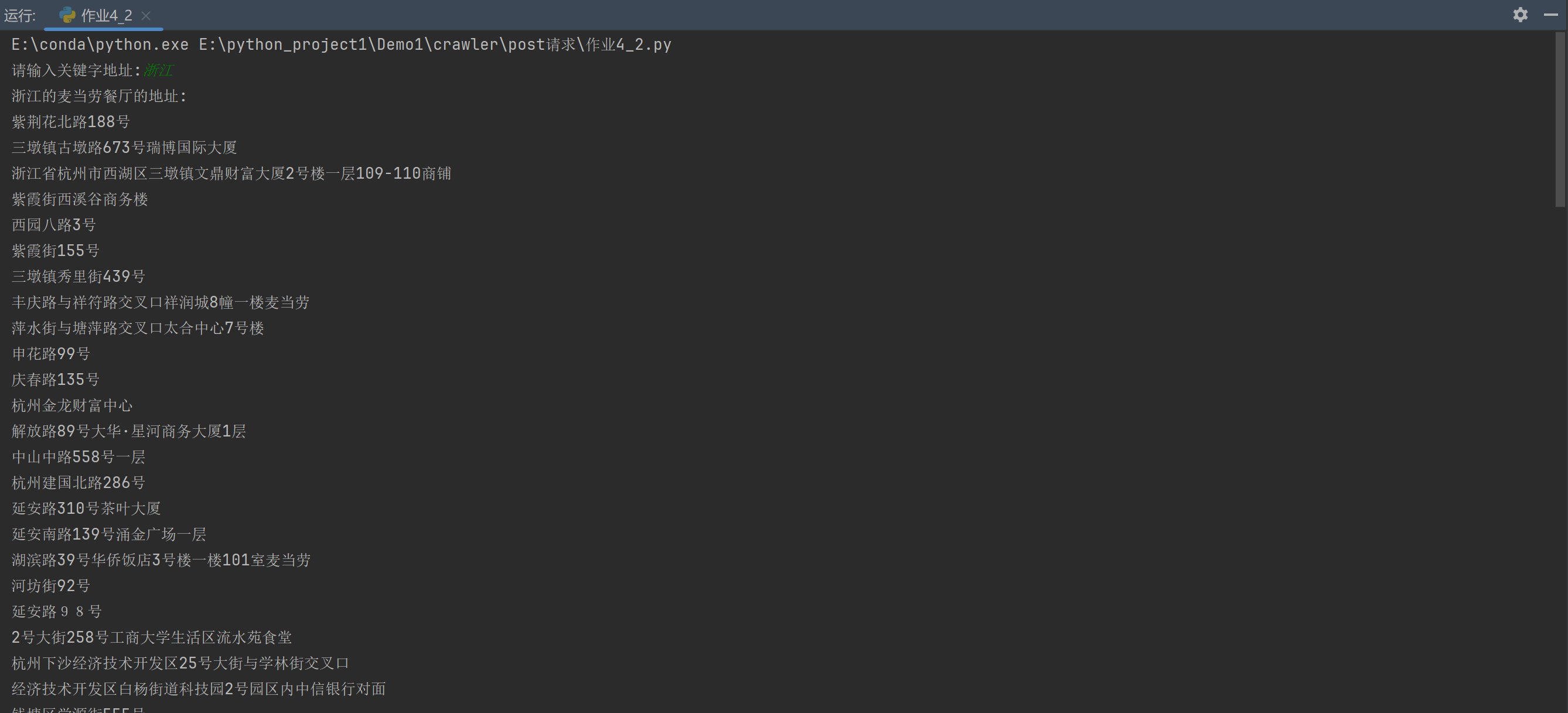
我们去对比一下, 和搜索框搜出来的所有地区以及地区所对应的详细地址是一样的, 这就说明我们成功的爬取到了每一个地区里面的麦当劳的详细地址。
对照一下网页上面搜索的详细地址信息(部分数据对比):
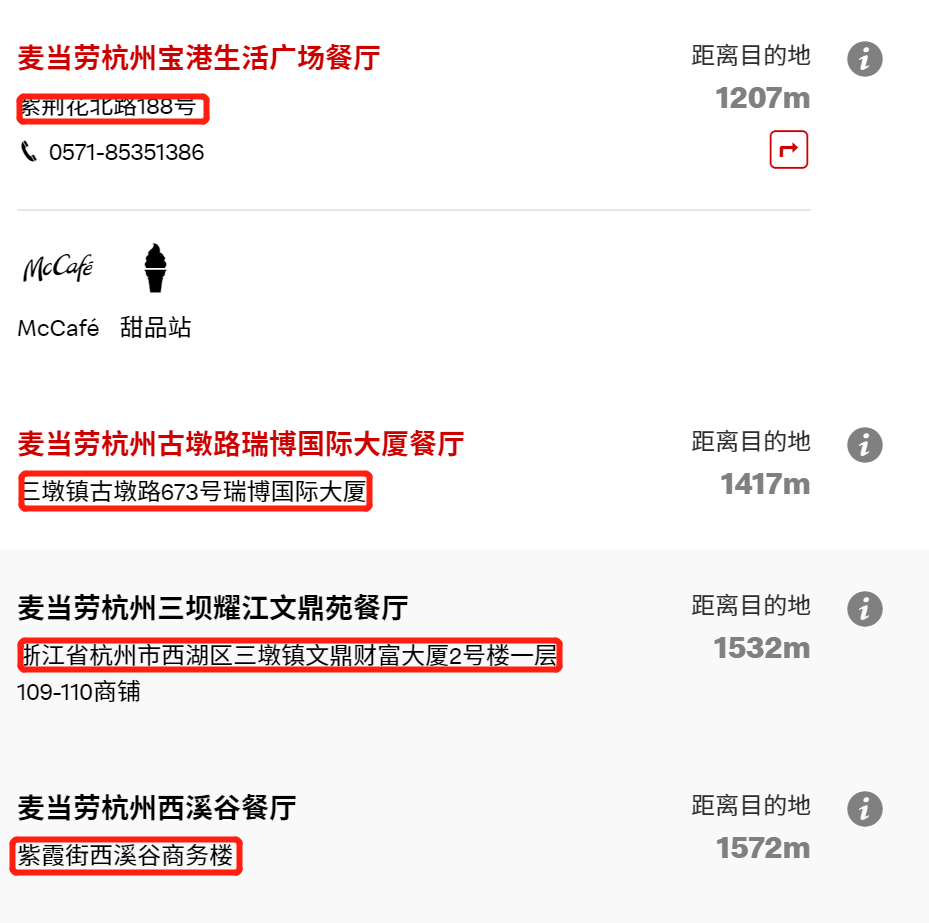
我们发现, 是一一对应的, 这就能够证明, 我们爬虫爬取到的信息是正确的。
这个实战题你写出来了吗?如果写出来的话, 给自己一个掌声哦。👏
以上就是爬虫post请求的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!