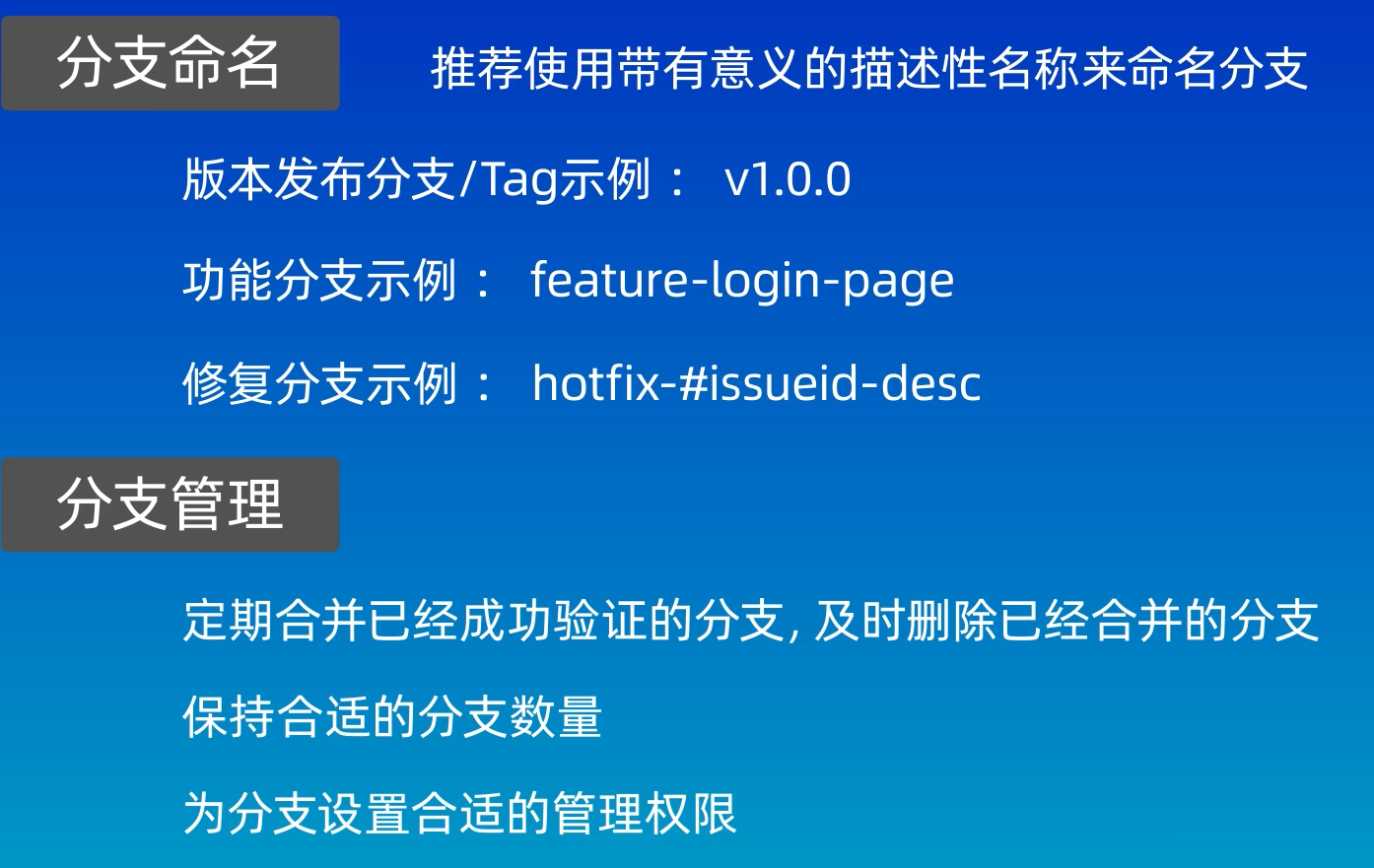
一、Hash哈希类型的基本介绍。
哈希表:之前学过的所有数据结构中,最最重要的。
1、日常开发中,出场频率非常高。
2、面试中,非常重要的考点。
Redis自身已经是键值对结构了。Redis自身的键值对就是通过哈希的方式来组织的。把key这一层组织完成之后,到了value这一层,value的其中一种类型还可以是哈希。

哈希类型中的映射关系通常称为field-value,用于区分Redis整体的键值对。
Hash类型的操作命令
HSET:设置hash中指定的字段field的值value。返回值是设置成功的Hash键值对的个数。![]()
value是一个字符串。
HGET:获取hash中指定的字段field的值value。

HEXISTS 判端hash中是否又指定的字段。返回值:1代表存在,0代表不存在

HDEL 删除hash中指定的字段,返回值:本次操作删除的字段个数。

HKEYS 获取hash中的所有字段![]() 这个操作,现根据key找到对应的hash,O(1),然后再遍历hash ,O(N),注意!这个操作也是存在一定的风险的!类似于之前介绍过的keys*,主要是不知道某个hash中是否会存在大量的field。
这个操作,现根据key找到对应的hash,O(1),然后再遍历hash ,O(N),注意!这个操作也是存在一定的风险的!类似于之前介绍过的keys*,主要是不知道某个hash中是否会存在大量的field。
HVALS 获取Hash中所有的value。和hkeys相对,能够获取到hash中所有的value。

如果哈希非常大,这个操作就可能导致redis服务器被阻塞住。
HGETALL 获取hash中的所有字段以及对应的值

两两交替显示,一个field,一个value。这个操作还是有可能造成服务器的阻塞。但是多数情况下,不需要查询所有的field,可能只查其中几个field。
HMGET 类似于之前的MGET,可以一次查询多个field。

HMSET,一次设置多个field和value。并不需要使用,hset已经支持多个field。
上述hkeys,hvals,hgetall都是存在一定风险的,hash的元素个数太多,执行的耗时会比较长,从而阻塞redis。hscan遍历redis的hash,但是它属于渐进式遍历,敲一次命令,遍历一小部分。再敲一次,再遍历一小部分。连续执行多次,就可以完成整个的遍历过程。化整为零。
HLEN 获取hash中的所有字段的个数

HSETNX 类似于setnx,不存在的时候,才能甚至成功,存在则设置不成功。

hash这里的value,也可以当作数字来处理。
HINCRBY 加减整数
HINCRBYFLOAT 加减小数
由于使用频率不算很高,redis没有提供类似于incr,decr的操作。O(1)

hash命令总结


学习Redis的过程中,会涉及到大量的命令。过两天会忘了,练习 + 多查文档就可以记住了。
hash类型内部编码
ziplist压缩列表:压缩 rar,zip,gzip这是一些具体的压缩算法。压缩的本质是针对数据进行重新编码,不同的数据,有不同的特点,结合这些特点,进行精妙的设计。重新编码之后,就能够缩小体积。事实上,这些常见的压缩算法。都是精妙设计的。ziplist也是同理。内部的数据结构也是精心设计的。表示一个普通的hash表,可能会浪费一定的空间。hash首先是一个数组,数组上有些位置有元素,有些没有元素。ziplist付出的代价,进行读写元素,速度是比较慢的。如果元素个数少,慢的并不明显,如果元素个数太多了,慢就会雪上加霜。
如果哈希表中的元素个数比较少,使用ziplist表示,元素个数比较多,使用hashtable来表示。
每个value的值长度都比较短,使用ziplist表示,如果某个value的长度太长了,也会转换成hashtable。

也可以使用 hash-max-ziplist-entries配置项默认是512个,也就是说超过512个hash field就会使用hashtable来进行编码。这个配置项就是可以写到redis.conf文件中的。
hash-max-ziplist-value配置(默认是64字节)。
Hash的使用场景
作为缓存:string也是可以作为缓存使用的。存储结构化的数据,使用hash类型更合适一些

上述场景使用string类型也能做到,就需要使用到json这样的数据格式。如果使用string的格式来表示UserInfo万一指向获取其中的某个field,或者修改某个field。就需要把整个json读出来,解析成对象,操作field,再重写转换成json字符串,再写回去。如果使用hash的方式来表UserInfo就可以使用field表示对象的每个属性。此时就可以非常方便的修改/获取任何一个属性的值了。使用hash的方式,确实读写field更直观高效,但是付出的是空间的代价。需要控制哈希再ziplist和hashtable两种内部编码的转换,可能造成内存的较大消耗。
 这种方式,相当于把同一个数据的各个属性给分散开表示了。低内聚。不推荐这样做。
这种方式,相当于把同一个数据的各个属性给分散开表示了。低内聚。不推荐这样做。
高内聚,低耦合。好的代码追求上面的六个字。
高内聚:把有关联的东西放在一起,最好放在指定的地方。
低耦合:两个模块之间的关联关系,关联关系越大,越容易相互影响。认为是耦合越大。
hash类型和关系型数据库有两点不同之处
哈希类型是稀疏的,而关系型数据库是完全结构化的。
关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询,例如联表查询、聚合查询等是不可能的,维护成本高。

二、List类型基本介绍
列表List相当于数组或者顺序表

约定最左侧元素下标是0,redis的下标支持负数下标。getrange。注意list内部的结果。并非是一个简单的数组,而是更接近于双端队列。

列表中的元素是有序的。有序的含义要根据上下文区分。有的时候谈到有序,指的是升序降序。有的时候,谈到的有序指的是顺序很关键。如果把元素位置颠倒,顺序调换,此时得到的新的List和之前的List是不等价的!
区分获取和删除的的区别:lindex能获取到元素的值,lrem也能返回被删除元素的值。
列表中的元素是允许重复的,像hash这样的类型,field是不能重复的。因为当前的LIst,头和尾都能高效的插入删除元素,就可以把这个List当作一个栈和队列来使用了。
Redis有一个典型的应用场景,就是作为消息队列,最早的时候,就是通过List类型。后来Redis又提供了一个stream类型。可以实现一个复杂的消息队列。
List的操作命令
lpush 将一个或多个元素头插到List中。
按照顺序,一次头插这几个元素,全部插入完毕,4是在最前面的!4 3 2 1。时间复杂度O(1),返回值是list的长度。如果key已经存在,并且key对应的value类型,不是list此时lpush就要报错。redis中所有的这些各种数据类型的操作,都是类似的效果。
lrange命令查看List中指定范围的元素。LRANGE Key start stop。此处描述的区间也是闭区间。下标支持负数。0 ,-1所有的范围。

此处的这个序号,是专门给结果集使用的序号。跟List下标没有关系。谈到下标,往往会关注,超出范围的情况。
C++中,下标超出范围,一般会认为这是一个未定义行为。 可能会导致程序奔溃。也可能会得到一个不合法的数据。还可能看起来合法,但是错误的数据,也有可能恰好得到一个符合要求的数据。Redis中的做法,是直接尽可能的获取到给定区间的元素,如果给定区间非法,比如超出下标,就会尽可能的获取对应的内容。

此处对于越界下标的访问。python中也有如此的操作。C++中的处理机制的缺点是程序员不一定能第一时间发现问题!优点:效率比较高。
lpushx 在key存在时,将一个或者多个元素从左侧放入。不存在就什么也不做。

rpush右侧插入,尾部插入。![]()
RPUSHX 存在就插入,不存在什么也不做。
LPOP 头删。把list左侧的元素取出来。
RPOP尾删。把list右侧的元素取出来。 时间复杂度O(1)。
LINDEX 给定下标获取对应的元素,下标非法返回的是nil,这是一个O(N)的时间复杂度。此处N指的是list中的元素的个数。

LINSERT![]() 在某个元素的之前之后插入。
在某个元素的之前之后插入。

返回值:插入之后,得到的新的list的长度。万一要插入的列表中,基准值存在多个怎么办

linsert进行插入的时候,要根据基准值,找到对应的位置,从左往右找,找到第一个符合基准值的位置即可。时间复杂度也是一个O(N)。N表示列表的长度。
LLEN 获取长度。
LREM rem其实就是remove的缩写。
![]() count 要删除的个数,element,要删除的值。时间复杂度O(N+M)。
count 要删除的个数,element,要删除的值。时间复杂度O(N+M)。
count > 0 从左往右寻找,删除count个就可以了
count < 0 从右往左寻找,删除count个就可以了
count = 0 删除所有的元素。
LTRIM 删除list中的元素。指定一个范围,保留start和stop之间区间内的元素,区间外面两边的元素就直接被删除了。

![]() 官方文档中还有这个东西,access control list 访问控制列表这是和权限相关的操作。Redis6开始支持的。都是针对6及其以上版本才有的。Redis有很多命令acl这块就把每个命令都打上一些标签,打好所有的标签之后,管理员就可以给每个redis用户配置不同的权限。允许该用户可以执行哪些标签对应的命令。这里并非是一个知识点。只不过需要用到时候要查一下配置具体怎么写。
官方文档中还有这个东西,access control list 访问控制列表这是和权限相关的操作。Redis6开始支持的。都是针对6及其以上版本才有的。Redis有很多命令acl这块就把每个命令都打上一些标签,打好所有的标签之后,管理员就可以给每个redis用户配置不同的权限。允许该用户可以执行哪些标签对应的命令。这里并非是一个知识点。只不过需要用到时候要查一下配置具体怎么写。
LSET 根据下标修改元素。![]() 也是一个O(N)的时间复杂度。
也是一个O(N)的时间复杂度。
![]()
lindex可以很好的处理下标越界的情况,直接返回nil,lset来说则会报错,不会像js那样,直接在10这个下标这里搞出个元素来。
阻塞版本的命令:阻塞,当前的线程不走了,代码不继续执行了。会在满足一定的条件之后,被唤醒。
BLPOP lpop 如果list中存在元素,blpop和brpop就和lpop以及rpop作用完全相同。如果list为空那么就会阻塞。
BRPOP rpop
以上两个命令相当于 lpop rpop,B =》block(阻塞)阻塞队列,多线程的时候,我们了解过了生产者消费者模型。使用队列来作为中间的交易场所。期望这个队列会有两个特性。1、线程安全,2、阻塞功能,如果队列为空尝试出队列就会产生阻塞。直到队列不空,阻塞解除,如果队列为满,尝试入队列,也会产生阻塞,直到队列不满,阻塞解除。
redis中的list也相当于阻塞队列一样,线程安全是通过单线程模型支持的。阻塞则只支持队列为空的情况。
使用brpop和blpop的时候,这里是可以显式设置阻塞时间的,不一定是无休止的等待!期间Redis可以执行其他命令,此处blpop和brpop看起来好像耗时很久,但是实际上并不会对redis服务器产生负面影响。
命令中如果设置了多个键,那么会从左向右进行遍历键,一旦有一个键对应的列表中可以弹出元素,命令立即返回。blpop和brpop都是可以同时去尝试获取多个key的列表的元素的。多个key对应多个list,这多个list哪个有元素了,就会返回哪个元素。
如果多个客户端同时对一个键执行pop,则最先执行命令的客户端会最先得到弹出的元素。
![]() 此处可以指定一个key或者多个key,每个key都对应一个list,如果这些list有一个非空,blpop都能够把这里的元素给获取到,立即返回。如果这些list都为空,此时就需要阻塞等待,等待其他客户端往这些list中插入元素了。此处还可以指定超时时间,单位是秒 Redis6 超时时间允许设定成小数,Redis5中,超时时间得是整数。
此处可以指定一个key或者多个key,每个key都对应一个list,如果这些list有一个非空,blpop都能够把这里的元素给获取到,立即返回。如果这些list都为空,此时就需要阻塞等待,等待其他客户端往这些list中插入元素了。此处还可以指定超时时间,单位是秒 Redis6 超时时间允许设定成小数,Redis5中,超时时间得是整数。
针对一个非空的列表进行操作。

返回结果相当于一个pair(二元组)一方面是告诉我们当前的数据来自于哪个key,一方面告诉我们取到的数据是啥。
针对一个空的列表,多个key进行操作:

返回结果相当于一个pair(二元组)一方面是告诉我们当前的数据来自于哪个key,一方面告诉我们取到的数据是啥。brpop和blpop的阻塞机制是完全相同的。
此处的这两个阻塞命令用途主要就是用来作为消息队列。
命令总结:

list内部编码:
以前的编码方式

当前的编码方式
quicklist:ziplist和linkedlist的结合体。ziplist把数据按照更紧凑的压缩形式进行标识的,节省空间,当元素个数多了,就不适合这种了。元素个数多了就可以使用linkedlist来编码。
quicklist相当于是链表和压缩列表的结合。整体还是一个链表,链表的每个节点,是一个压缩列表,每个压缩列表,都不让它太大,同时再把多个压缩列表通过链式结构连起来。
 这样的配置已经不适用了。
这样的配置已经不适用了。
当前的配置项为![]() 还有一个挡位:
还有一个挡位:

旧版本的策略就已经不使用了,无论什么大小都会使用quick来使用
List应用场景
用list作为数组这样的结构,来存储多个元素。
mysql中,标识学生和班级信息。
student(studented, studentName, age, score, classID)
class(classID,className) 在上述表格中我们就可以知道哪些班级有哪些人了。
redis支持这样的查询功能优点困难。

学生和班级之间的联系。

使用Redis作为消息队列

使用生产者消费者模型。这个操作,是阻塞操作。当列表为空的时候,brpop就会阻塞等待,一直等到其他客户端,push了元素才会解除阻塞,来获取元素。谁先执行的brpop就会先拿到一个元素,像这样的设定,就构成一个轮询式的效果。
假设消费者执行顺序式 1 2 3,当新元素到达之后,首先消费者1拿到元素,(按照执行brpop的命令的先后顺序来决定谁获取到的)。消费者1拿到元素之后,也就从brpop中返回了。(相当于这个命令就执行完了)。如果消费者1还想继续消费,就需要重新执行brpop。 此时,再来一个新的元素过来,就是消费者2拿到该元素,也从brpop中返回,如果消费者2还想继续消费,也需要重新执行brpop。再来一个新元素,就是消费者3来获取这个元素了。
分频道的消息队列

多个列表/频道 这种场景非常常见的。日常使用的一些程序,抖音,有一个通道,来传输短视频数据。还可以有一个通道,来传输弹幕,还可以有频道,来传输点赞,转发,收藏数据,还可以有频道,来传输评论数据。搞成多个频道,就可以在某种数据发生问题的时候,不会对其他数据造成影响。达到了一个解耦合的目的。
微博timeline



当前一页中有多少数据不确定,可能会导致下面的循环比较大,从而会触发很多次的hgetall,也就是很多的网络请求。使用pipeline管道流水线。虽然咱们是多个redis命令,但是把这些命令合并成一个网络请求,进行通信。大大降低客户端和服务器之间的交互次数了。
lrange在两侧的查询速度很快,但是查询中间段是有点慢的。可以用这样的方法:假设某个用户发了1w个微博list长度就是1w,就可以把1w个微博拆成10份,每隔就是1k,如果是想要获取到5k个左右的微博。就可以加快中间位置的查询。
这里的list可以当作一个栈一端存取,一个队列两端存取。