一、前言
在互联网时代,数据的价值日益凸显。爬虫技术作为一种获取数据的重要手段,广泛应用于各种场景。本文将通过一个实例,介绍如何使用Python进行网站数据的抓取。
二、环境准备
- Python 3.x
- requests库
- BeautifulSoup库
三、代码实现
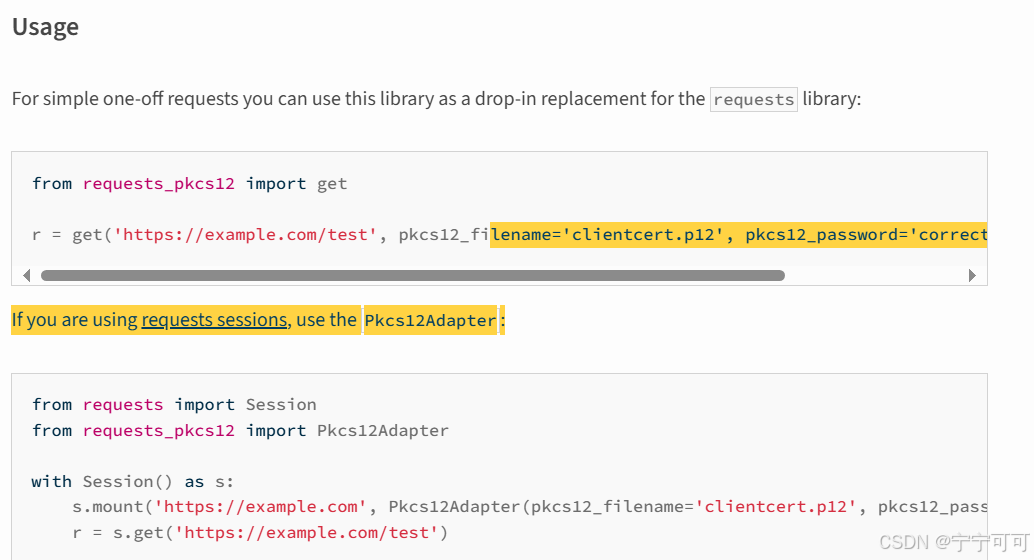
import requests
from bs4 import BeautifulSoup# 目标网址
url = 'https://example.com'# 发送请求
response = requests.get(url)# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')# 抓取需要的数据
data = soup.find_all('div', class_='data')# 输出数据
for item in data:print(item.text)
四、总结
通过以上步骤,我们成功实现了对指定网站数据的抓取。在实际应用中,爬虫技术还有许多需要注意的地方,如反爬机制、数据存储等。希望本文能对大家有所帮助。