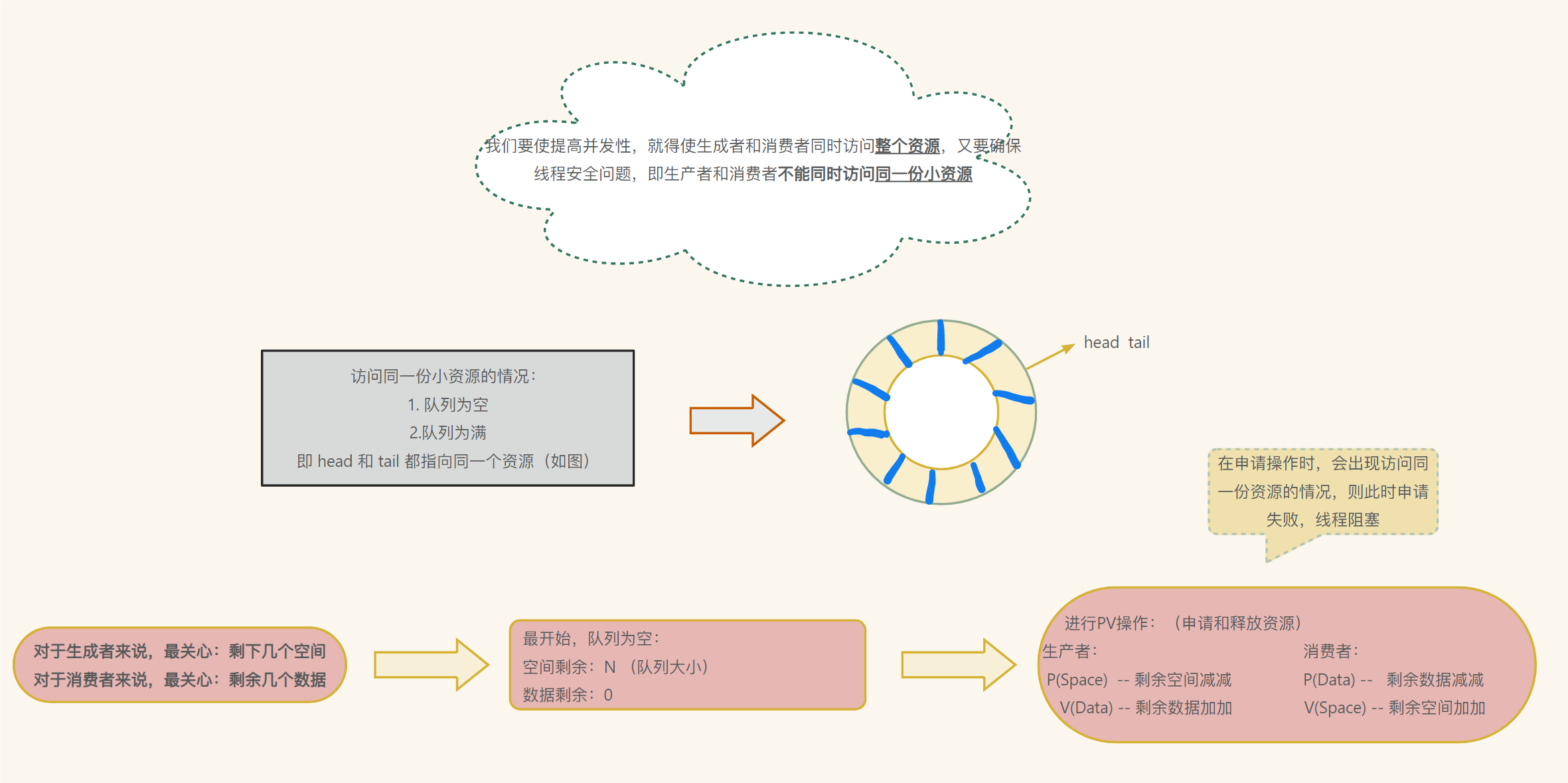
随着互联网信息爆炸式增长,获取有效数据成为决策者的重要任务。人工爬取数据不仅耗时且效率低下,因此自动化数据处理成为一种高效解决方案。本文将介绍如何使用Selenium与Excel实现数据爬取与处理,结合代理IP技术构建一个可稳定运行的数据爬取管道,专门用于从WIPO(世界知识产权组织)的Brand Database网站(branddb.wipo.int)中获取专利和技术信息。
一、项目概述
本项目的目标是从WIPO品牌数据库中抓取特定专利和技术信息,并使用Selenium进行自动化操作。为了避免被网站封锁,我们还将引入代理IP服务,例如使用爬虫代理,来提升爬取的稳定性和隐私性。最后,爬取的数据将会存储在Excel文件中,便于后续的数据分析和处理。
二、技术选型与工具简介
- Selenium:用于模拟用户操作,自动化执行浏览器行为,尤其适合处理JavaScript动态加载的网页。
- Excel (openpyxl库):用于处理数据存储,将爬取到的数据以表格的形式保存,便于后续分析。
- 代理IP技术:通过使用代理IP,避免爬取过程中过于频繁的访问而被封禁,提升数据获取的稳定性。本文将使用爬虫代理服务。
三、Selenium的基本设置
首先,我们需要安装并配置Selenium、openpyxl库和代理IP相关的设置。
pip install selenium openpyxl
接着,需要下载合适的浏览器驱动程序(如ChromeDriver)并将其配置到系统路径。
四、使用代理IP技术进行爬取
爬虫时,如果频繁访问某个网站,IP地址容易被封禁。因此,我们可以使用爬虫代理服务,通过代理IP技术隐藏真实的IP地址,从而避免被限制。
代理IP配置示例:
- 域名: proxy.16yun.cn
- 端口: 8000
- 用户名: your_username
- 密码: your_password
五、Selenium与代理IP结合
我们先来看如何将Selenium与代理IP技术相结合,以便爬取网站。
1. 配置代理IP
在启动浏览器时,通过设置代理IP来实现请求转发。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options# 设置代理IP的地址和端口 亿牛云爬虫代理 www.16yun.cn
proxy_host = "proxy.16yun.cn"
proxy_port = "8000"
proxy_user = "your_username"
proxy_pass = "your_password"# 配置代理IP
chrome_options = Options()
chrome_options.add_argument(f"--proxy-server=http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}")# 启动浏览器
driver = webdriver.Chrome(options=chrome_options)
通过这种方式,Selenium将通过代理IP访问目标网站,规避IP限制问题。
2. 使用Selenium爬取WIPO Brand Database
接下来,我们实现从WIPO品牌数据库获取数据的核心代码。
import time
from selenium.webdriver.common.by import By# 打开WIPO品牌数据库
driver.get("https://branddb.wipo.int")# 等待页面加载
time.sleep(5)# 查找专利技术信息的输入框并输入关键字
search_box = driver.find_element(By.ID, "searchInput")
search_box.send_keys("technology patent") # 输入搜索关键词# 点击搜索按钮
search_button = driver.find_element(By.CLASS_NAME, "searchButton")
search_button.click()# 等待结果加载
time.sleep(10)# 抓取结果页面的专利信息
results = driver.find_elements(By.CLASS_NAME, "result-item")# 遍历结果并提取相关信息
patent_data = []
for result in results:title = result.find_element(By.CLASS_NAME, "title").textdescription = result.find_element(By.CLASS_NAME, "description").textpatent_data.append((title, description))# 关闭浏览器
driver.quit()
六、将爬取的数据存储到Excel
使用Python的openpyxl库将爬取的数据存储到Excel文件中,便于后续的分析和处理。
from openpyxl import Workbook# 创建Excel工作簿
wb = Workbook()
ws = wb.active# 写入表头
ws.append(["Title", "Description"])# 写入爬取的数据
for title, description in patent_data:ws.append([title, description])# 保存Excel文件
wb.save("WIPO_patent_data.xlsx")
通过这个代码段,我们将抓取到的专利和技术信息保存到Excel文件WIPO_patent_data.xlsx中,方便后续分析。
七、代理IP的重要性与使用技巧
在网络爬虫中,使用代理IP是一种常见的规避反爬虫机制的方法。选择合适的代理服务商(如亿牛云爬虫代理)非常重要。以下是使用代理IP时的一些注意事项:
- 稳定性:选择拥有高质量IP池的代理商,确保爬虫能持续运行。
- 并发量:检查代理IP服务商允许的并发量,确保能满足大规模爬取的需求。
- 切换频率:合理设置代理IP切换频率,避免使用同一个IP爬取大量数据。
八、总结
本文介绍了如何使用Selenium与代理IP技术相结合,构建一个稳定高效的数据爬取管道。通过Selenium实现自动化操作,配合代理IP提高爬虫的稳定性,并将爬取到的数据通过openpyxl存储到Excel中,形成完整的数据处理流程。
这套方法不仅适用于WIPO品牌数据库,其他类似的网站也可以用类似的方式进行自动化数据爬取与处理。通过这种方式,用户可以轻松地获取大量的专利与技术信息,并为后续的决策提供有力的数据支撑。
九、未来展望
随着数据量的增长和网站的反爬虫技术的升级,代理IP技术的灵活运用将显得更加重要。未来,可以考虑引入更多的防反爬策略,如设置请求间隔、使用无头浏览器等,以进一步提升爬虫的效率和稳定性。
通过合理的自动化爬取方案,数据获取将变得更加高效和智能,为决策提供更加准确的数据支持。