文章目录
- error处理机制
- 函数
- 函数作为参数
- 匿名函数
- 匿名函数和闭包
- 闭包运用
- 闭包与工厂模式
- 使用闭包调试
error处理机制
本篇总结的是Go中对于错误的处理机制
Go 语言的函数经常使用两个返回值来表示执行是否成功:返回某个值以及 true 表示成功;返回零值(或 nil)和 false 表示失败
而实际上来说,是需要对于第二个参数进行判断的,比如之前的这个场景
func test1() {str1 := "123"num, _ := strconv.Atoi(str1)fmt.Println(num)
}
这里实际上是忽略了对应的错误信息,只是这里确实没有错误,但是如果真的错误的话,此时给出的结果就是一个不符合预期的结果
func test2() {str1 := "abc"num, _ := strconv.Atoi(str1)fmt.Println(num)
}

由此可以看出,这个第二个参数实际上是需要被使用的,而常见的判断错误的方式是
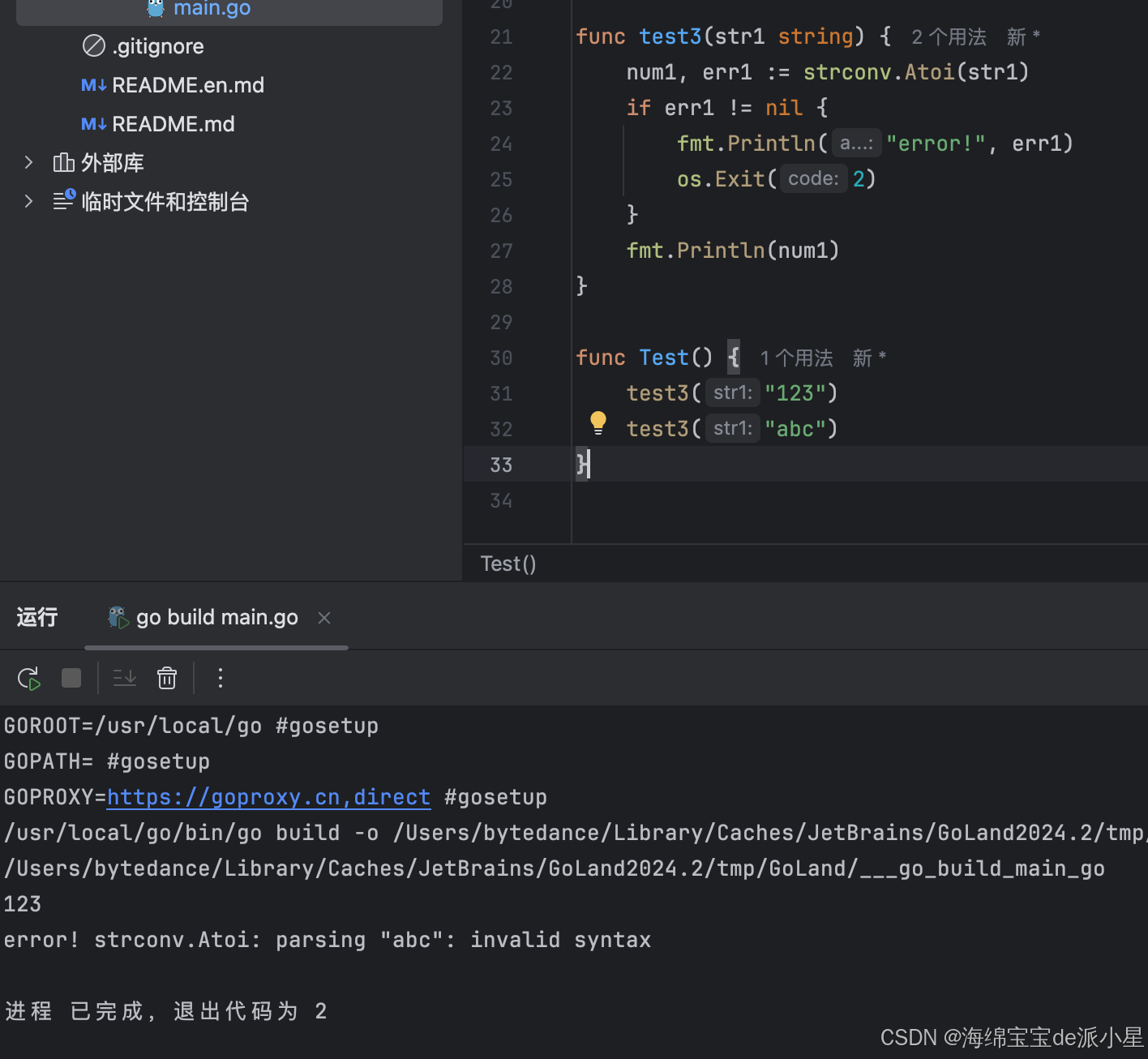
func test3(str1 string) {num1, err1 := strconv.Atoi(str1)if err1 != nil {fmt.Println("error!", err1)os.Exit(2)}fmt.Println(num1)
}
运行结果为
函数
这里很多概念和之前的内容很相似,这里就不再说了,这里重点讲述的是和前面的概念不太相同的地方,做一个举例说明
函数作为参数
package funcpackage// 定义一个加法函数
func add(a, b int) int {return a + b
}// 函数的参数是加法函数
func test1(a int, add func(int, int) int) int {// 内部调用的这个函数return add(a, 2)
}// Test 外层函数调用时,传递参数也要传这个函数
func Test(a int) int {return test1(a, add)
}
这个函数的功能就是,可以传递一个变量进来,之后会把这个参数和加法函数传递给另外一个参数,然后再进行运算返回,在这里这只是一个示例,正常来说也没人会这样进行函数参数的传递
匿名函数
匿名函数的概念并不陌生,它的基本思想就是一个没有名字的函数,比如可能是存在这样的情况
func(x, y int) int { return x + y }
那么,针对于上述的这种场景,实际上是可以直接对于这个函数进行调用的,比如它可能是要这样进行调用:
func test2(a int) int {return func(x, y int) int { return x + y }(a, 2)
}// Test 外层函数调用时,传递参数也要传这个函数
func Test(a int) int {return test2(a)
}
这样就是匿名函数的基本实现,可以理解为是在函数内部直接定义函数,然后直接进行调用,只调用一次,也可以像这样
下面是一个计算从 1 到 100 万整数的总和的匿名函数:
func() {sum := 0for i := 1; i <= 1e6; i++ {sum += i}
}()
下面的例子展示了如何将匿名函数赋值给变量并对其进行调用
package mainimport "fmt"func main() {f()
}
func f() {for i := 0; i < 4; i++ {g := func(i int) { fmt.Printf("%d ", i) }g(i)fmt.Printf("type %T and has value %v\n", g, g)}
}
输出:
type func(int) and has value 0x681a80
type func(int) and has value 0x681b00
type func(int) and has value 0x681ac0
type func(int) and has value 0x681400
所以我们实际上拥有的是一个函数值:匿名函数可以被赋值给变量并作为值使用
匿名函数和闭包
defer 语句和匿名函数
关键字 defer经常配合匿名函数使用,它可以用于改变函数的命名返回值
匿名函数同样被称之为闭包(函数式语言的术语):它们被允许调用定义在其它环境下的变量。闭包可使得某个函数捕捉到一些外部状态,例如:函数被创建时的状态。另一种表示方式为:一个闭包继承了函数所声明时的作用域。这种状态(作用域内的变量)都被共享到闭包的环境中,因此这些变量可以在闭包中被操作,直到被销毁。闭包经常被用作包装函数:它们会预先定义好 1 个或多个参数以用于包装,另一个不错的应用就是使用闭包来完成更加简洁的错误检查
闭包运用
闭包的使用,这里的场景是,将函数作为返回值来进行使用,下面假设有下面的这种场景
// 无参数的函数
func add1() func(a int) int {return func(a int) int { return a + 2 }
}// 有参数的函数
func add2(b int) func(a int) int {return func(a int) int { return a + b }
}// Test 外层函数调用时,传递参数也要传这个函数
func Test() {f1 := add1()f2 := add2(10)res1 := f1(20)res2 := f2(20)fmt.Println(res1, " ", res2)
}
那么对于这个场景来说,函数add1和函数add2的区别是:
- 函数add1是无参数的,那么就意味着在调用这个函数的时候不需要传递参数,直接会返回一个可以被直接调用的匿名函数对象,而这个函数对象需要接受一个参数int
- 而对于函数add2来说是有参数的,那么就意味着在获取它的返回值的时候就需要提前先传递一个参数进去,这个参数就会绑定到这个匿名函数可调用对象当中,之后在进行调用的时候再进行一次绑定即可
再看一个有意思的调用场景
func f() func(int) int {x := 0return func(a int) int {x += areturn x}
}func test4() {t := f()fmt.Println(t(10))fmt.Println(t(20))fmt.Println(t(30))
}
运行结果实际上是10,30,60,呈现的是一种累加的效果,那为什么会展示出这样的效果呢?
实际上也很好理解,因为t变量本质上是从f返回的一个返回值,也就是说一直调用的是同样的一个函数调用的栈帧,那么在这一个栈帧当中,对于x的值,每次都会进行更新,那么自然呈现出的效果就是累计增加了
闭包与工厂模式
闭包是可以和工厂模式结合的,这是Go语言可以返回函数带来的好处,看下面这样的场景
func factory(str1 string) func(str2 string) string {return func(str2 string) string {return str2 + str1}
}func test5() {func1 := factory(".jpg")func2 := factory(".bmp")fmt.Println(func1("11111"))fmt.Println(func2("22222"))
}
如上所示也是一个比较有意思的使用场景,使用者可以传递一个后缀进去,之后调用的函数都会自动添加上这个后缀
由这些用例其实也能看出,将函数返回的一个巨大好处是可以把函数内部的一些参数动态化,不必必须要提前写死,这样在工厂模式这样的场景下会有其独特的优势
可以返回其它函数的函数和接受其它函数作为参数的函数均被称之为高阶函数,是函数式语言的特点,未来会介绍更多的,与这样的场景相关的场景,Go语言在处理混合对象中尤其独特的强大能力
使用闭包调试
闭包的另外一个用处是可以用做调试,下面给出这样的例子
where := func() {_, file, line, _ := runtime.Caller(1)log.Printf("%s:%d", file, line)
}
where()
// some code
where()
// some more code
where()
先解释一下这个函数是什么意思
runtime.Caller
在 Go 语言中,runtime.Caller(1)函数用于获取调用栈信息。这段代码中的四个变量分别对应如下:
- 第一个下划线接收的变量通常是调用栈的帧数(但这里被忽略了)
- file接收当前调用点所在的文件名
- line接收当前调用点所在的行号
- 第二个下划线接收的变量通常是函数名等信息(这里被忽略了)
通过这个函数,可以在运行时获取代码的调用位置信息,这在调试、错误处理和性能分析等场景中非常有用。例如,可以在日志中记录函数的调用位置以便更好地追踪问题
runtime.Caller()函数用于返回调用栈的程序计数器、文件名和行号。它的函数签名是func Caller(skip int) (pc uintptr, file string, line int, ok bool)
这个函数会返回调用栈中特定帧的信息,通过skip参数来指定要跳过的栈帧数
skip参数的含义
- 当skip = 0时:它返回的是runtime.Caller()函数本身的调用信息。也就是说,它返回的是runtime.Caller()这个函数被调用时所在的文件、行号等信息
- 当skip = 1时:它会跳过runtime.Caller()函数的调用帧,返回调用runtime.Caller()函数的那个函数的信息。这在实际应用中非常有用,例如在一个封装的日志记录函数中,使用runtime.Caller(1)可以获取调用日志记录函数的那个函数的文件名和行号,这样就能准确地记录是在哪个函数中触发了日志记录操作。
一般来说,skip的值越大,就会跳过越多的栈帧,返回更外层(在调用栈中更早的位置)的函数的调用信息
所以,在_, file, line, _ := runtime.Caller(1)中,1的作用是跳过runtime.Caller()函数自身的调用帧,获取调用runtime.Caller()函数的那个函数的文件名和行号
因此,在实际的使用中,就可以把返回的函数当做是一个输出日志的系统
func test6() {where := func() {_, file, line, _ := runtime.Caller(1)log.Println(file, line)}where()a := 10b := 20where()fmt.Println(a, b)fmt.Println(a, b+a)where()
}
再看看输出结果,在输出结果信息中就会直接显示出对应的文件,和文件对应的行数,这对于开发者进行调试来说是很有实际的意义和价值的