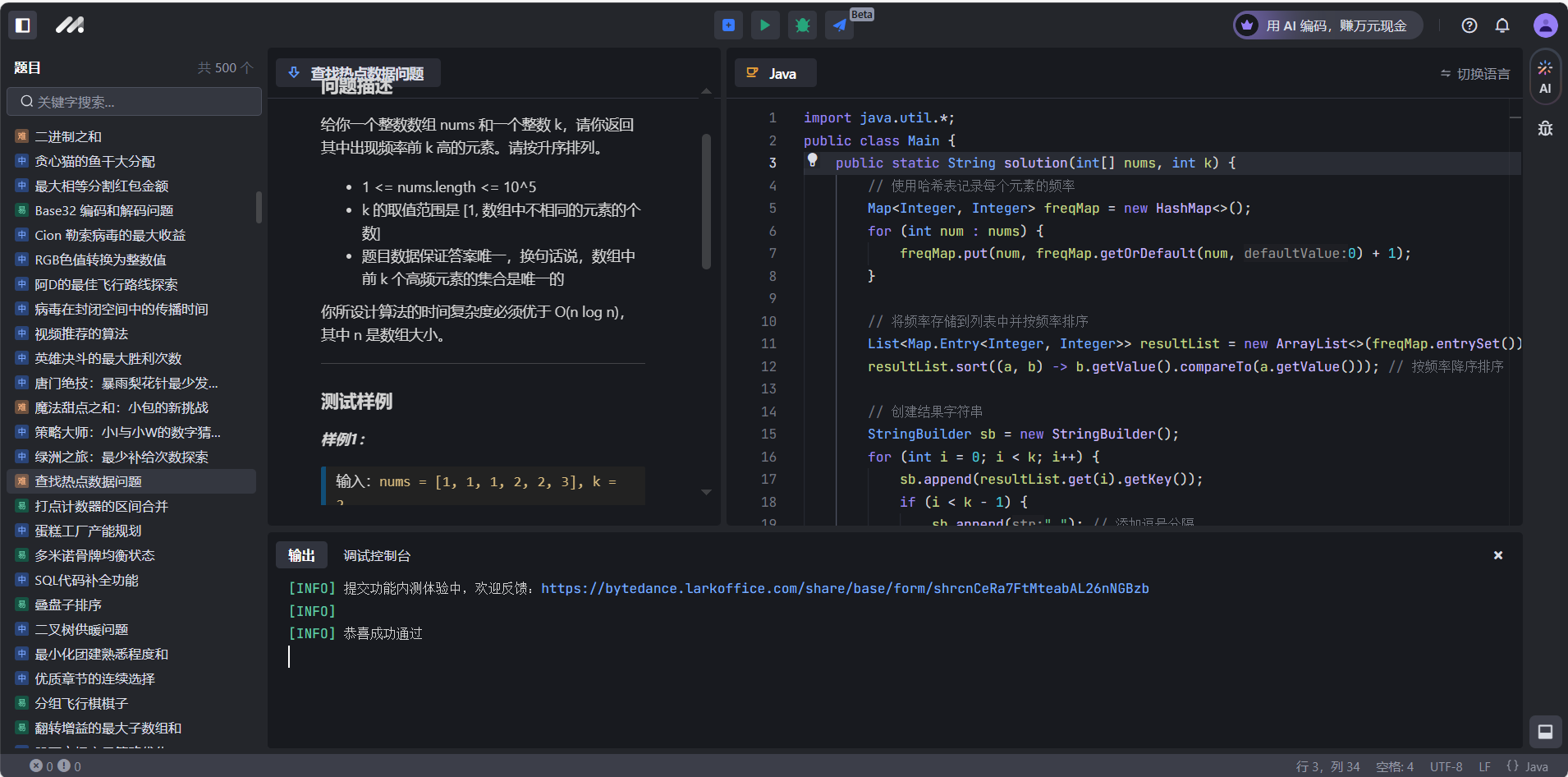
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np torch.manual_seed(1)
# 自定义数据集
class CustomDataset(Dataset):def __init__(self):# 创建一些示例数据(100个样本,每个样本包含10个特征)self.data = torch.randn(100, 10)self.labels =torch.from_numpy(np.arange(100)) # 二分类标签def __len__(self):# 返回数据集的大小return len(self.data)def __getitem__(self, idx):# 根据索引 idx 返回对应的样本和标签sample = self.data[idx]label = self.labels[idx]return sample, label# 创建数据集的实例
dataset = CustomDataset()# 使用DataLoader加载数据
# 设置batch_size=16,shuffle=True表示打乱数据顺序
dataloader = DataLoader(dataset, batch_size=100, shuffle=True)# 迭代DataLoader
for i in range(2):for batch_idx, (inputs, labels) in enumerate(dataloader):print(f"Batch {batch_idx+1}")print(f"Inputs: {inputs.size()}") # 显示当前batch中输入数据的维度print(f"Labels: {labels.size()}") # 显示当前batch中标签的维度print(labels)# 在这里你可以对数据进行训练# 例如:outputs = model(inputs)
只要是shuffle=True,每次epoch结果的顺序是不一样的,如果想每一次的结果是一样的

如果shuffle=False
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np torch.manual_seed(1)
# 自定义数据集
class CustomDataset(Dataset):def __init__(self):# 创建一些示例数据(100个样本,每个样本包含10个特征)self.data = torch.randn(100, 10)self.labels =torch.from_numpy(np.arange(100)) # 二分类标签def __len__(self):# 返回数据集的大小return len(self.data)def __getitem__(self, idx):# 根据索引 idx 返回对应的样本和标签sample = self.data[idx]label = self.labels[idx]return sample, label# 创建数据集的实例
dataset = CustomDataset()# 使用DataLoader加载数据
# 设置batch_size=16,shuffle=True表示打乱数据顺序
dataloader = DataLoader(dataset, batch_size=100, shuffle=True)# 迭代DataLoader
for i in range(2):for batch_idx, (inputs, labels) in enumerate(dataloader):print(f"Batch {batch_idx+1}")print(f"Inputs: {inputs.size()}") # 显示当前batch中输入数据的维度print(f"Labels: {labels.size()}") # 显示当前batch中标签的维度print(labels)# 在这里你可以对数据进行训练# 例如:outputs = model(inputs)
结果如下