近期,大型语言模型(LLMs)在生成文本和执行各种自然语言处理任务方面展现出了卓越的能力,成为了强大的AI驱动语言理解和生成的基础模型。然而,仅依赖于基于文本模态的模型存在显著局限性。这促使了基于语音的生成模型的发展,使其能够更自然、直观地与人类互动。
为了实现语音交互,OpenAI前阵子发布的GPT-4o,它可以直接与用户进行低时延,高质量语音对话,并具有多种不同的能力,如对说话人的识别,语音情感的识别,甚至是生成特定风格的语音,如唱歌。语音语言模型 (SpeechLMs)正是朝着这个方向的一种尝试,近期也成为了研究热点。本文是对SpeechLMs研究的一篇全面综述。
论文链接:https://arxiv.org/abs/2410.03751
Motivation
由于基于文本的大语言模型的成功,一般的语音交互方案通常采用"自动语音识别(ASR) +大型语言模型(LLM) +文本到语音合成(TTS)"的级联式架构。这种方法需要将语音信号转换为文本,并通过LLM基于文本进行回答,最后再将回答的语音进行生成。然而,这种方法存在两大主要的局限性:
-
整个流程是基于文本语言模型的,所以首先需要将音频转换为文本再进行处理。这种方式会丢失掉很多包含在音频中但不包含在文本中的信息,导致了音频信息的部分丢失。
-
整个流程是将三个独立的模块拼接在一起的,因此三个阶段在处理时候的错误会进行累积。
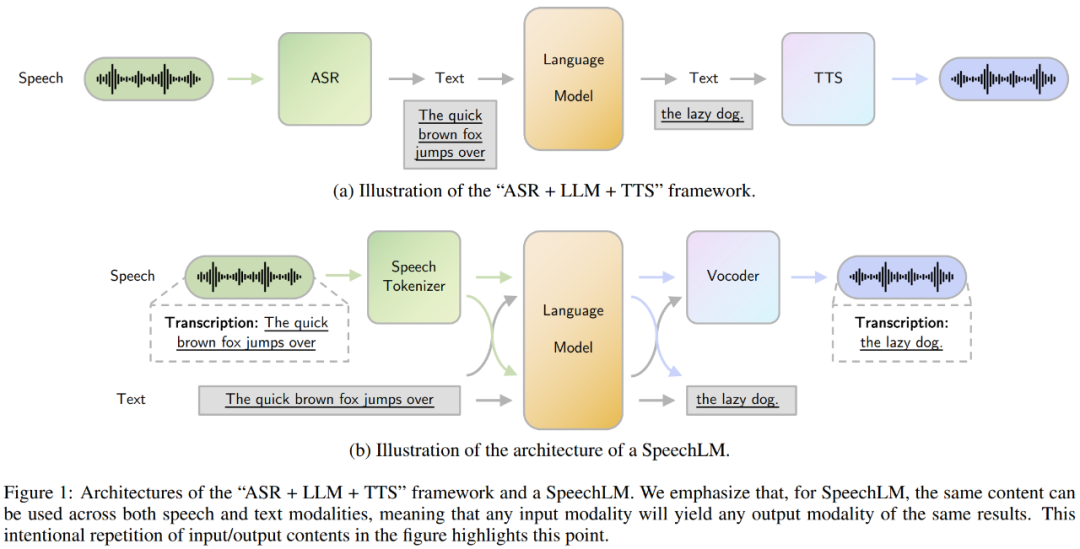
为了解决这些问题,SpeechLMs作为一种端到端的语音交互模型应运而生,它无需将语音转换为文本就能直接生成语音输出。SpeechLMs不仅可以执行传统的ASR、TTS任务,还能直接进行端到端的语音对话,以及实现更多复杂的功能,如编码说话人的音色信息和语音情感的细微差别。

那么,什么是SpeechLM呢?SpeechLM是一种自回归的基础模型(foundation model),能够处理和生成语音数据,利用上下文理解来生成连贯的序列。它通常支持语音,或语音和文本两个模态,如语音输入文本输出、文本输入语音输出或语音输入语音输出。这使其可以进行广泛的任务和具有上下文感知的能力。
以下是SpeechLMs的分类框架:

SpeechLM的组成部分
SpeechLM主要由三个核心组件构成:
-
语音分词器(Speech Tokenizer):将连续的音频信号编码为离散的token。
-
语言模型(Language Model):对语音token进行自回归建模。
-
Token到语音合成器(Vocoder):将生成的token合成为语音波形。

具体来说,SpeechLM在工作时,会先将输入的音频信号通过语音分词器处理成离散的token,再通过语言模型对这些语音token进行自回归建模,生成后续的语音token。最后,这些由语言模型生成出的语音token会经过语音合成器,再恢复成语音。
接下来让我们详细了解这三个组件:
-
语音分词器:语音分词器的核心目标是如何有效的将语音信号通过离散的token进行表示。这些token需要包含语音里面的多种信息。语音分词器的设计遵循有三类目标 - 语义理解、声学生成和混合目标。
-
语义理解型分词器,如HuBERT,专注于捕捉语音内容和含义。
-
声学生成型分词器,如SoundStream,侧重保留生成高质量语音所需的声学特征。
-
混合型分词器,如SpeechTokenizer,则平衡了语义理解和声学生成。
-
-
语言模型:大多采用Transformer或Decoder-Only架构,如OPT、LLaMA等。它们以自回归方式生成语音。SpeechLM中的语言模型通常可以将语音和文本的词表进行拼接,从而联合建模文本和语音模态。
-
语音合成器:主要有GAN-based、Flow-based等多种类型。GAN-based如HiFi-GAN,是在SpeechLM中最为广泛使用的一类vocoder,因为其以快速且高保真的生成而著称。
SpeechLM的训练配方
在训练方面,SpeechLMs的"配方"包括:
建模特征:这里表示的是SpeechLM的语言模型在训练时选择使用哪一类特征进行建模。一般可分为离散特征和连续特征。
-
离散特征:这是最主要的SpeechLM所建模的特征,一般以token形式存在。这里一般主要包含语义token,副语言学(paralinguistic)token,和声学token。
-
语义token:主要包含了语音里面语义信息。
-
副语言学token:主要包含了语音里面出语义信息以外的信息,如音高,韵律等。
-
声学token:主要包含语音信号中的声学信息。这些信息有助于将token恢复出高质量高保真语音。
-
-
连续特征:当然也有极少部分SpeechLM选择对连续信号进行建模,如梅尔谱(mel-spectrogram)
训练阶段:包括语言模型预训练和指令微调两个主要阶段。
-
语言模型预训练:此阶段主要关注如何让SpeechLM中的语言模型有效学习到语音token之间的上下文关系,从而让模型能够输出上下文相关的且连贯的语音。此阶段可以选择使用随机初始化的参数开始训练,但研究人员一般会更愿意选择基于文本训练好的LLM checkpoint进行继续预训练。研究人员发现采用文本预训练的checkpoint继续预训练使得SpeechLM效果更好,且能够更快拟合。
-
语言模型指令微调:此阶段主要关注让SpeechLM中的语音模型能够有效的进行指令跟随,从而更好的与人类对话或回答人类提出的问题。
语音生成范式:除传统生成方式外,还包括实时交互和静默模式等高级语音交互技能。
-
实时交互:一般的语言模型在交互时遵循回合制(turn-based),即每一轮的输入输出需要等上一轮的输入输出结束后才能进行。然而,这并不符合人类说话(语音交互)的范式。人类语音交互时,通常可以不等待上一个人说话结束后就会说话,或者在他人说话时自己同时开始说。这催生了SpeechLM的实时交互模式的探索。
-
静默模式:静默模式指的是当模型识别到,当人类没有与其对话的时候(如在和其他人对话时),选择不进行回应的能力。
下游任务与能力

SpeechLMs能够执行多种下游任务,大致可分为三类:
-
语义相关应用:如口语对话、语音翻译、自动语音识别等;
-
说话人相关应用:如说话人识别、验证、分离等。此能力可以让SpeechLM分辨出多个说话人,从而可以处理更加复杂的场景,如在参与会议并与多人同时进行讨论;
-
语音学应用:如情感识别、语音分离、增强语音学生成等。此能力能使得SpeechLM识别并生成带有特定风格的语音,如使用不同情感说话,甚至是唱歌。
评 估
在评估方面,SpeechLMs采用自动(客观)评估和人工(主观)评估两种方法。
-
自动(客观)评估:通过自动化指标来评判SpeechLM的好坏。自动评估通常从多个角度去衡量SpeechLM的性能:
-
特征评估:衡量SpeechLM所输出的特征;
-
语言学评估:衡量SpeechLM对于词法,句法,语义的理解与生成;
-
副语言学评估:衡量SpeechLM对于副语言学特征的理解与生成质量。
-
-
人工(主观)评估:通过人工评估来评判SpeechLM的好坏。人工评估主要依赖平均意见得分(MOS)。
未来研究方向
尽管SpeechLMs展现出令人印象深刻的能力,但这一领域的研究仍处于起步阶段。未来的研究方向包括:
-
深入理解不同组件(语音分词器,语言模型,语音合成器)选择的优劣;
-
探索端到端训练方法:当前的SpeechLM在训练时通常会选择分开对三个组件训练,而将三个组件合在一起进行端到端训练的策略值得研究;
-
继续增强SpeechLM的实时语音生成能力;
-
解决SpeechLMs中的安全风险:语音生成模型中同时有与文本生成模型相似的和独立的安全风险。例如,SpeechLM可能会生成有毒性的文本(制作炸弹的教学),不合规的语音(如色情语音),和对说话人的偏见(对不同口音的语音输入产生不同的输出)。因此,解决SpeechLM中的安全风险至关重要;
-
提升在稀有语言上的表现:对于稀有语言(小语种)来说,通常在互联网上能够获取到的文本资料很少,但语音数据却相对较多。因此,研究者可以关注如何提升SpeechLM在稀有语言上的表现。
总结
SpeechLMs作为一种新兴的语音交互技术,展现出了巨大的潜力。它不仅能够克服传统ASR+LLM+TTS方案的局限性,还能实现更自然、更丰富的人机语音交互。随着研究的深入,我们有理由相信SpeechLMs将在未来的AI语音交互中扮演越来越重要的角色。








![[Redis] Redis数据持久化](https://i-blog.csdnimg.cn/direct/614e5e5702194b41b135d9811d8e00e2.png)






