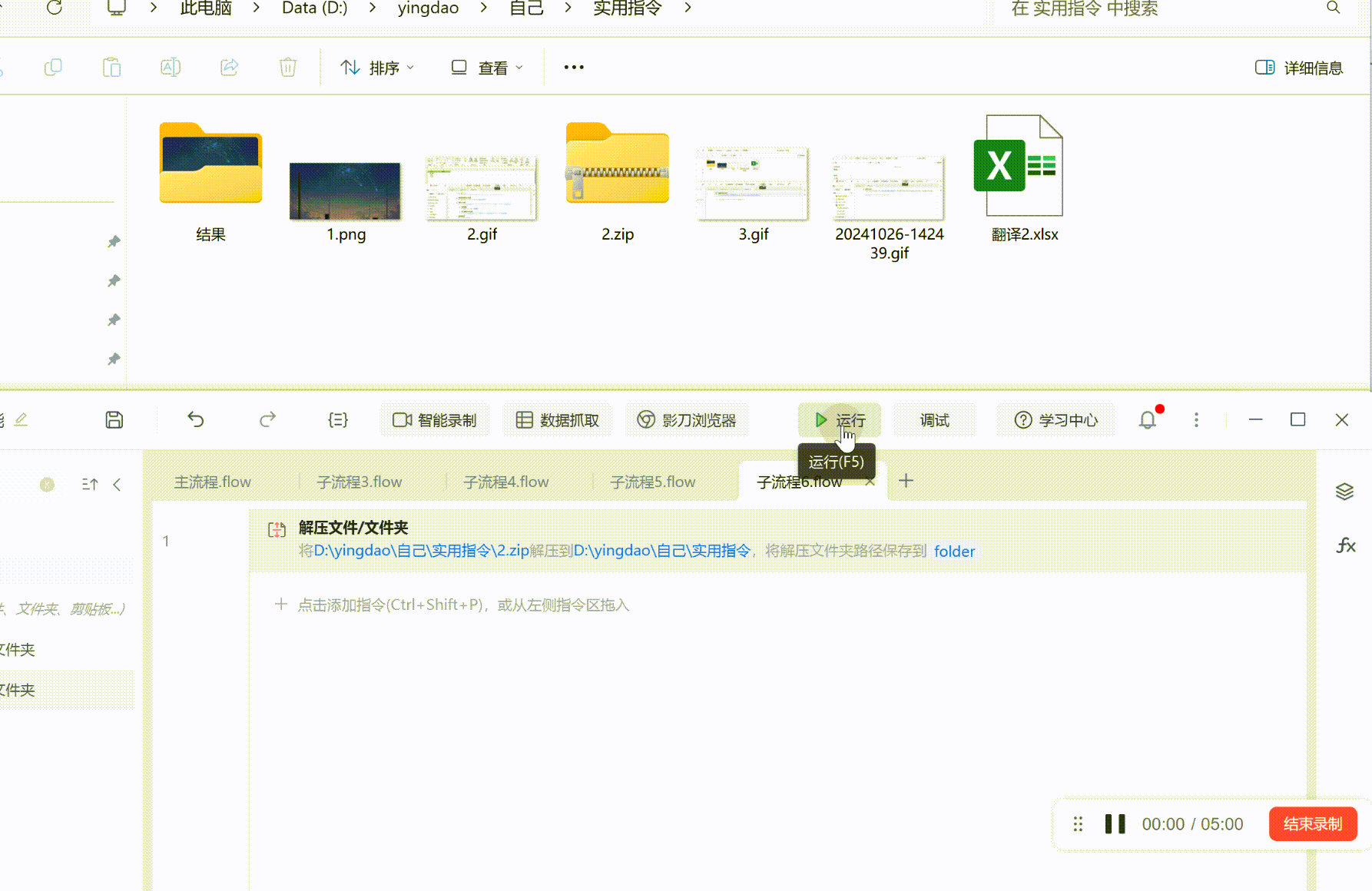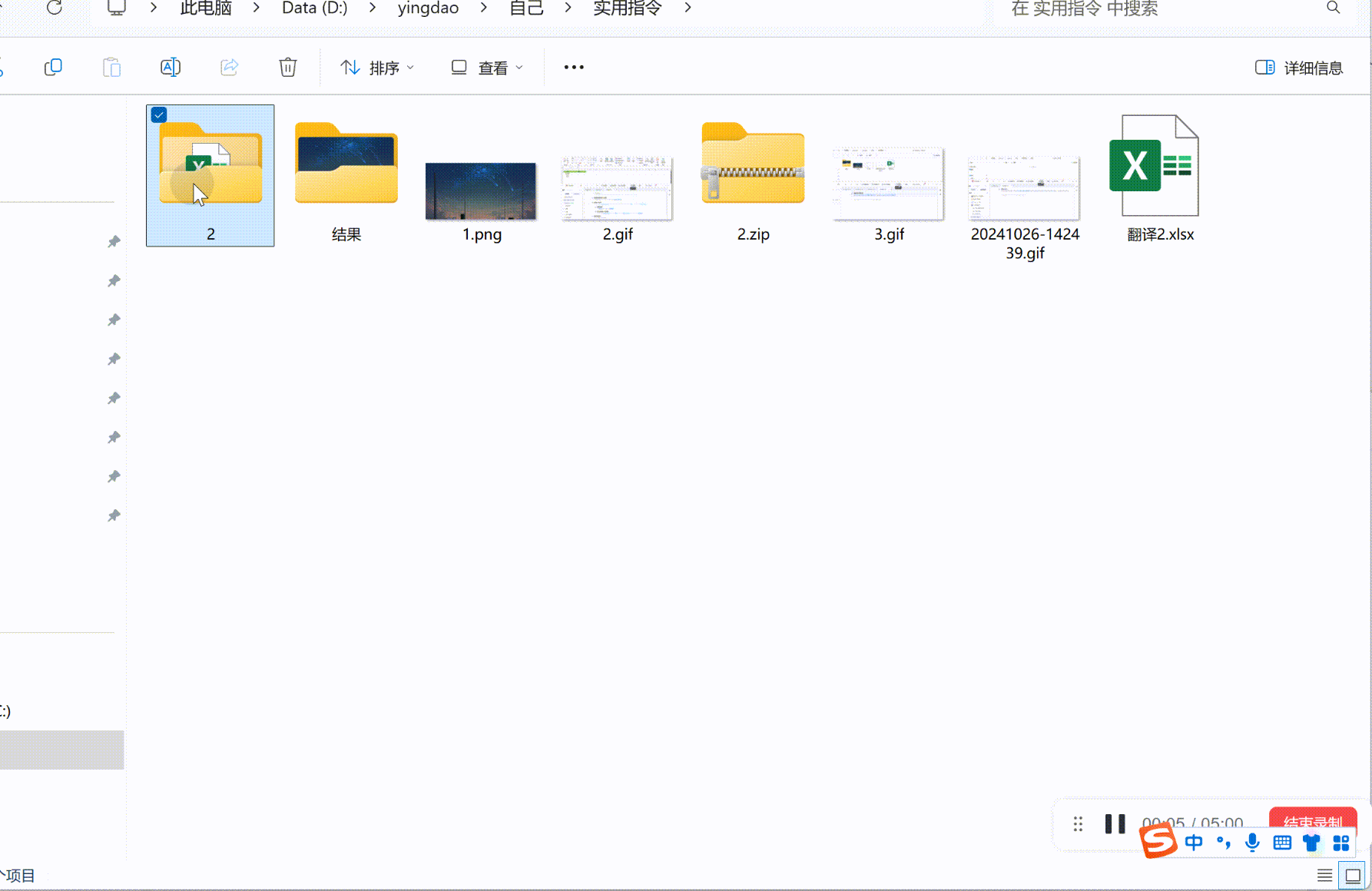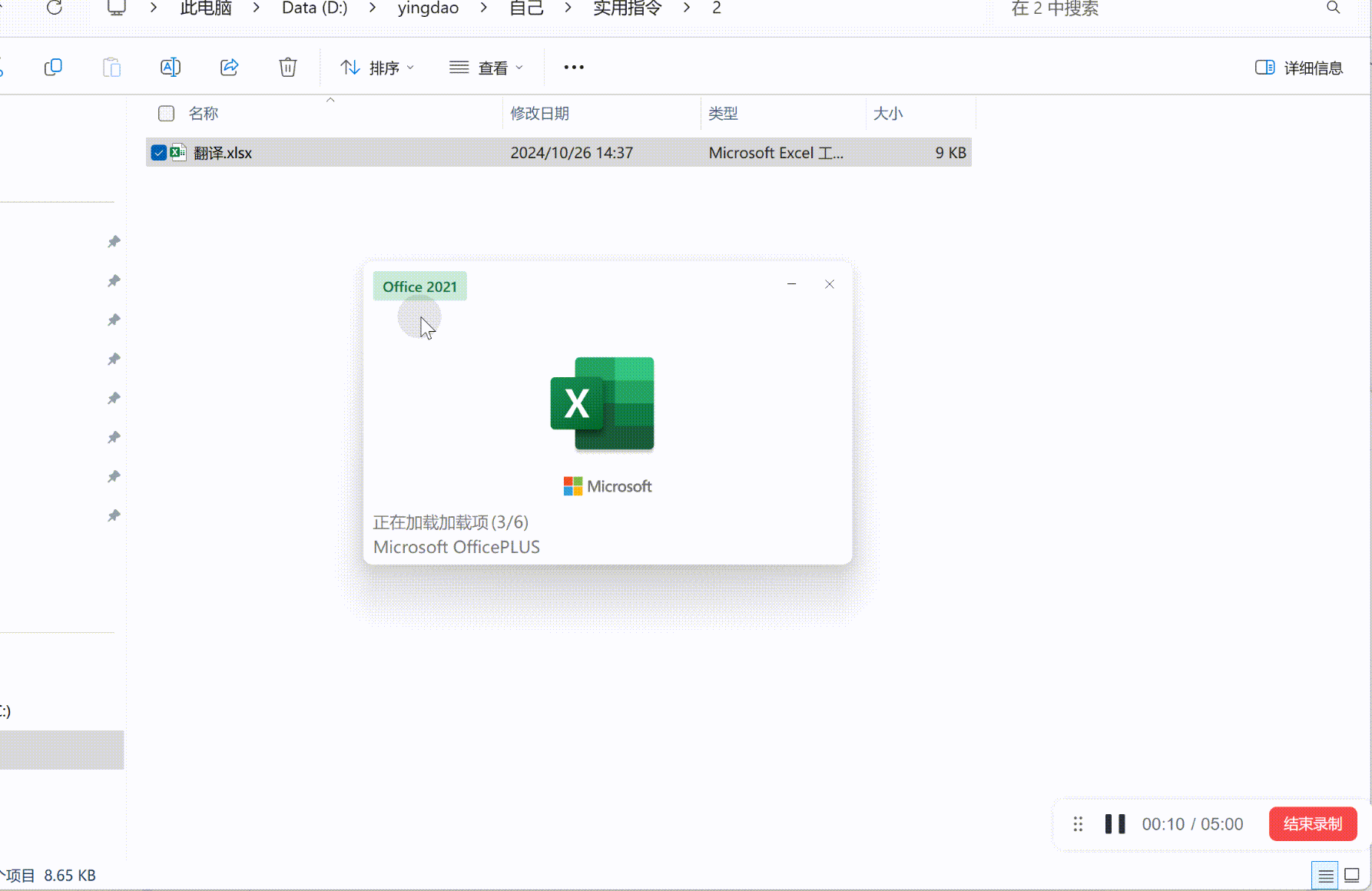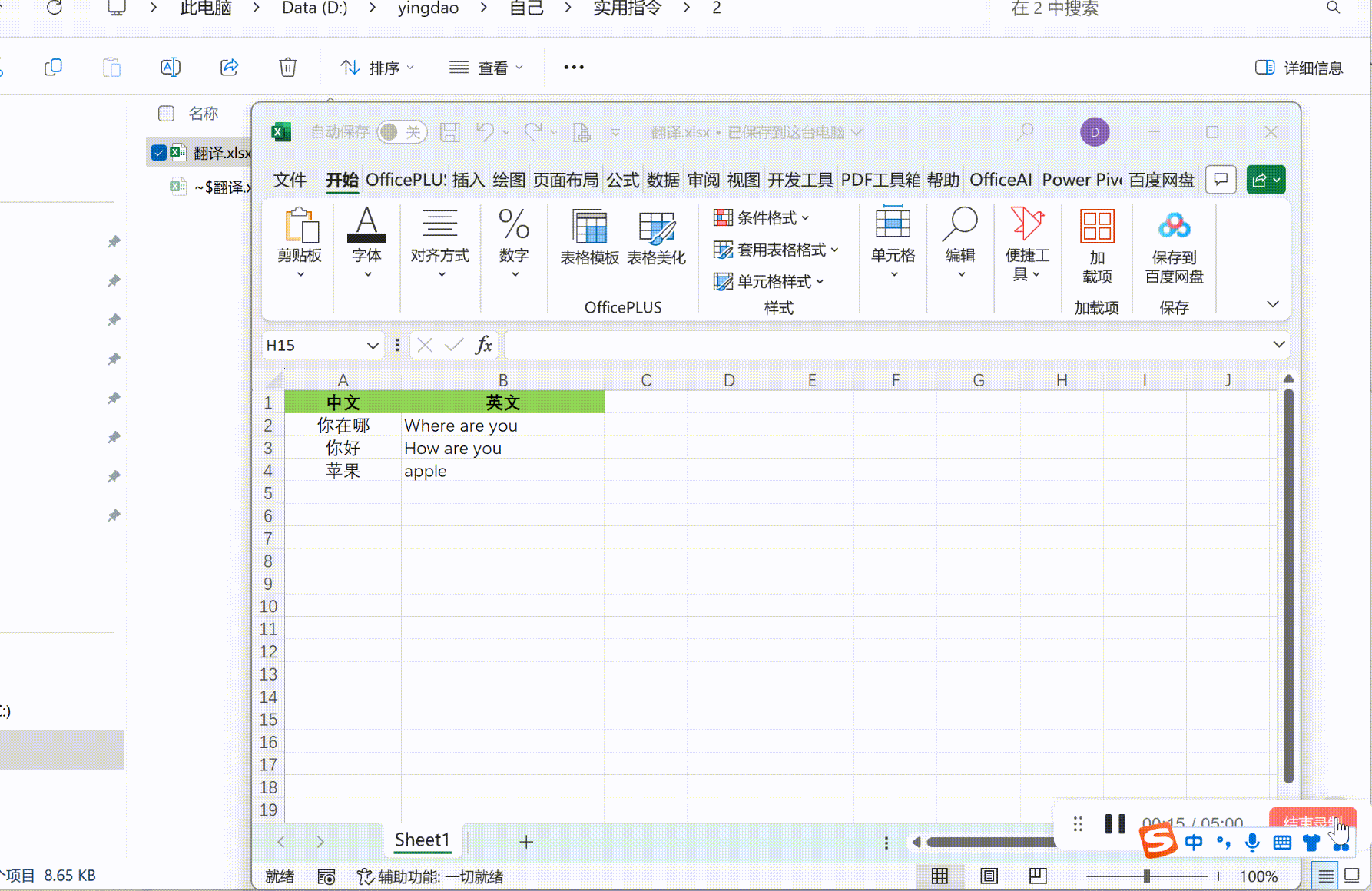
目录
18.多线程和多进程
多线程(Threading)
多进程(Multiprocessing)
19.动态类型系统深入
类型检查
鸭子类型(Duck Typing)
20. 函数式编程特性
高阶函数
匿名函数(Lambda 函数)
21.数据持久化
文件存储
使用数据库
22.元编程
元类(Metaclass)
代码动态生成
23.并发编程高级概念
异步编程(asyncio)
24.性能优化
内置函数和模块的高效使用
代码优化策略
25.正则表达式(re 模块)
基本概念
使用示例
26.国际化和本地化(i18n 和 l10n)
概念
使用示例
27.虚拟环境(Virtual Environments)
概念
使用示例
28.测试框架(unittest、pytest 等)
unittest
pytest
29.网络编程
Socket 编程
HTTP 编程
30.数据可视化(Matplotlib、Seaborn 等)
Matplotlib
Seaborn
31.深度学习框架集成(TensorFlow、PyTorch 等)
TensorFlow
PyTorch
18.多线程和多进程
多线程(Threading)
- 线程基础概念
- 线程是操作系统能够进行运算调度的最小单位。一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间等。在 Python 中,可以使用
threading模块来创建和管理线程。
- 线程是操作系统能够进行运算调度的最小单位。一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间等。在 Python 中,可以使用
- 创建线程
- 例如,以下是一个简单的多线程示例,创建两个线程分别打印数字:
import threadingdef print_numbers():for i in range(5):print(threading.current_thread().name, i)thread1 = threading.Thread(target=print_numbers, name='Thread 1')
thread2 = threading.Thread(target=print_numbers, name='Thread 2')thread1.start()
thread2.start()thread1.join()
thread2.join()
- 线程同步
- 当多个线程访问共享资源时,可能会出现数据不一致等问题。为了解决这个问题,可以使用锁(Lock)等同步机制。例如,以下是一个使用锁来保护共享资源的示例:
import threadingcounter = 0
lock = threading.Lock()def increment_counter():global counterfor _ in range(5):with lock:counter += 1print(threading.current_thread().name, counter)thread1 = threading.Thread(target=increment_counter, name='Thread 1')
thread2 = threading.Thread(target=increment_counter, name='Thread 2')thread1.start()
thread2.start()thread1.join()
thread2.join()
多进程(Multiprocessing)
- 进程基础概念
- 进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间等资源。在 Python 中,可以使用
multiprocessing模块来创建和管理进程。
- 进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间等资源。在 Python 中,可以使用
- 创建进程
- 例如,以下是一个简单的多进程示例,创建两个进程分别打印数字:
在 Windows 系统上使用 multiprocessing模块时,将创建进程的代码放在 if __name__ == '__main__'语句块中
在 Windows 系统上,Python 的多进程启动方式与 Unix 系统不同。在 Windows 中,新进程是通过启动一个新的 Python 解释器并导入主模块来创建的。如果不在 if __name__ == '__main__'语句块中包裹进程创建的代码,那么当新进程导入主模块时,会再次尝试创建新的进程,从而导致无限递归和错误。而在 Unix 系统中,多进程通常使用 fork机制,不会出现这个问题。
import multiprocessingdef print_numbers():for i in range(5):print(multiprocessing.current_process().name, i)if __name__ == '__main__':process1 = multiprocessing.Process(target=print_numbers, name='Process 1')process2 = multiprocessing.Process(target=print_numbers, name='Process 2')process1.start()process2.start()process1.join()process2.join()- 进程间通信
- 由于进程之间是独立的,它们之间的通信需要特殊的机制。在 Python 中,可以使用队列(Queue)、管道(Pipe)等方式来实现进程间通信。例如,以下是一个使用队列来实现进程间通信的示例:
import multiprocessingdef producer(q):for i in range(5):q.put(i*2)def consumer(q):while True:item = q.get()if item is None:breakprint(multiprocessing.current_process().name, item)if __name__ == '__main__':queue = multiprocessing.Queue()producer_process = multiprocessing.Process(target=producer, name="one111:", args=(queue,))consumer_process = multiprocessing.Process(target=consumer,name="two222:", args=(queue,))producer_process.start()consumer_process.start()producer_process.join()queue.put(None)consumer_process.join()19.动态类型系统深入
类型检查
- Python 是动态类型语言,但在一些大型项目中,可能需要进行类型检查。可以使用
mypy等工具来进行类型检查。例如,安装mypy后,可以对以下代码进行类型检查:
def add_numbers(a: int, b: int) -> int:return a + b
- 如果在调用函数时传递了不符合类型要求的参数,
mypy会给出相应的提示。
鸭子类型(Duck Typing)
- 鸭子类型是 Python 动态类型系统的一个重要概念。它的意思是,如果一个对象看起来像鸭子,走起来像鸭子,叫起来像鸭子,那么它就是鸭子。也就是说,只要一个对象具有所需的方法或属性,就可以在相应的上下文中使用它,而不需要关心它的具体类型。
- 例如,以下是一个简单的示例,一个类只要实现了
__len__方法,就可以在len函数中使用:
class MyClass:def __len__(self):return 5my_object = MyClass()
print(len(my_object))20. 函数式编程特性
高阶函数
- 高阶函数是指那些接受函数作为参数或者返回函数作为结果的函数。例如,
map函数是一个高阶函数,它接受一个函数和一个可迭代对象作为参数,并将函数应用到可迭代对象的每个元素上,返回一个新的可迭代对象。例如:
def square(x):return x**2numbers = [1, 2, 3]
squared_numbers = list(map(square, numbers))
print(squared_numbers)
- 同样,
filter函数也是高阶函数,它接受一个函数和一个可迭代对象作为参数,并过滤掉那些不满足函数条件的元素,返回一个新的可迭代对象。例如:
def is_even(x):return x % 2 == 0numbers = [1, 2, 3]
even_numbers = list(filter(is_even, numbers))
print(even_numbers)
匿名函数(Lambda 函数)
- 匿名函数是一种没有名字的函数,它使用
lambda表达式来定义。例如,上述square函数可以用匿名函数表示为:lambda x: x**2。匿名函数通常用于需要简单函数的地方,如在高阶函数中作为参数使用。例如:
numbers = [1, 2, 3]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers)21.数据持久化
文件存储
- Python 可以通过文件操作来实现数据的持久化。
- 例如,可以使用
open函数打开一个文件,然后使用write函数写入数据,使用read函数读取数据。例如:
# 写入文件
with open('data.txt', 'w') as f:f.write('Hello, World!')# 读取文件
with open('data.txt', 'r') as f:content = f.read()print(content)
使用数据库
- Python 可以通过各种数据库连接库来与数据库进行交互,实现数据的持久化。
- 例如,对于 MySQL 数据库,可以使用
mysql.connector库(需要安装)。以下是一个简单的示例,连接到 MySQL 数据库,创建一个表并插入一些数据:
import mysql.connectormydb = mysql.connector.connect(host="localhost",user="root",password="your_password",database="your_database"
)mycursor = mydb.cursor()# 创建表
mycursor.execute("CREATE TABLE students (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), age INT)")# 插入数据
sql = "INSERT INTO students (name, age) VALUES (%s, %s)"
val = ("John", 25)
mycursor.execute(sql, val)
mydb.commit()mycursor.close()
mydb.close()22.元编程
元类(Metaclass)
- 概念
- 元类是创建类的类。在 Python 中,一切皆对象,类也是对象,元类就是用来创建这些类对象的模板。默认情况下,Python 使用
type作为元类来创建所有的类。
- 元类是创建类的类。在 Python 中,一切皆对象,类也是对象,元类就是用来创建这些类对象的模板。默认情况下,Python 使用
- 自定义元类
- 例如,下面是一个简单的自定义元类,它会在创建类时给类添加一个
created_by属性:
- 例如,下面是一个简单的自定义元类,它会在创建类时给类添加一个
class MyMeta(type):def __new__(cls, name, bases, attrs):attrs['created_by'] = 'MyMeta'return super().__new__(cls, name, bases, attrs)class MyClass(metaclass=MyMeta):passprint(MyClass.created_by)
代码动态生成
- Python 可以在运行时动态生成代码。例如,可以使用
eval和exec函数。eval函数用于计算并返回一个表达式的值,exec函数用于执行一段 Python 代码块。 - 例如:
x = 5
expression = "x + 3"
result = eval(expression)
print(result) code_block = """
for i in range(3):print(i)
"""
exec(code_block)23.并发编程高级概念
异步编程(asyncio)
- 基础概念
- 异步编程是一种处理并发任务的方式,它允许程序在等待某个操作完成时(比如等待网络请求返回或文件读取完成),可以继续执行其他任务,而不是像传统的同步编程那样一直阻塞等待。
- 使用示例
- 以下是一个简单的
asyncio异步编程示例,模拟了两个异步任务(这里简化为两个异步函数,分别模拟等待不同时间):
- 以下是一个简单的
import asyncioasync def task1():print('Task 1 started')await asyncio.sleep(2)print('Task 1 completed')async def task2():print('Task 2 started')await asyncio.sleep(1)print('Task 2 completed')async def main():await asyncio.gather(task1(), task2())asyncio.run(main())24.性能优化
内置函数和模块的高效使用
- Python 的一些内置函数和模块在性能上有优化。
- 例如,使用
enumerate函数来同时获取列表的索引和元素比使用传统的for循环和手动计数索引更高效。 - 例如:
my_list = ['a', 'b', 'c']
for index, element in enumerate(my_list):print(index, element)
- 另外,对于数值计算,使用
numpy模块可以大大提高计算效率。例如:
import numpy as npa = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = a + b
print(c)
代码优化策略
- 避免在循环体内进行复杂的计算或函数调用,如果可能的话,将这些计算提前到循环体外。
- 尽量使用局部变量而不是全局变量,因为访问全局变量的速度相对较慢。
- 对于重复使用的代码片段,可以考虑使用函数或类来封装,提高代码的复用性和可维护性。
25.正则表达式(re 模块)
基本概念
- 正则表达式是一种用于匹配字符串模式的工具。它由普通字符(如字母、数字、标点符号等)和特殊字符(如
*、+、?、^、$等)组成,可以用来描述一个字符串的模式。 - 例如,
^a表示以a开头的字符串,b$表示以b结尾的字符串,a.*b表示包含a和b且中间可以有任意字符的字符串。
使用示例
- 在 Python 中,使用
re模块来操作正则表达式。例如,要查找一个字符串中是否包含以a开头的子字符串,可以使用以下代码:
import retext = "abcdef"
match = re.search('^a', text)
if match:print('找到匹配')
else:print('未找到匹配')
- 还可以使用
re.findall函数来查找所有符合模式的子字符串。例如,要查找一个字符串中所有数字,可以使用:
- 当在字符串前面加上
r(原始字符串)前缀时,Python 会将字符串中的字符按照字面意思来处理,而不会对反斜杠进行转义解释。
import re
text = "abc123def456"
numbers = re.findall(r'\d', text)
print(numbers)26.国际化和本地化(i18n 和 l10n)
概念
- 国际化(i18n)是指在设计软件时,将软件设计为能够支持不同语言和文化环境的用户使用。本地化(l10n)是指将国际化的软件根据具体的语言和文化环境进行调整,使其更适合当地用户使用。
使用示例
- 在 Python 中,可以使用
gettext模块来实现国际化和本地化。例如,以下是一个简单的示例:
import gettext# 初始化语言环境
lang = gettext.NullTranslator()
lang.install()# 定义需要翻译的文本
text = _('Hello, World!')
print(text)
- 这里的
_函数是gettext模块提供的用于获取翻译后的文本的函数。在实际应用中,需要根据不同的语言环境加载相应的翻译文件来实现真正的翻译。
27.虚拟环境(Virtual Environments)
概念
- 虚拟环境是一种用于隔离不同项目的 Python 运行环境的机制。它允许在同一台机器上创建多个独立的 Python 环境,每个环境都可以有自己独立的 Python 版本和安装的包,避免了不同项目之间的包冲突。
使用示例
- 使用
venv模块创建虚拟环境(Python 3.3+):
# 创建虚拟环境
python -m venv myenv# 激活虚拟环境(Windows)
myenv\Scripts\activate# 激活虚拟环境(Linux/macOS)
source myenv/bin/activate
- 一旦激活虚拟环境,安装的包只会安装在该虚拟环境中,不会影响系统的 Python 环境。可以使用
pip install命令安装所需的包。
28.测试框架(unittest、pytest 等)
unittest
- 基本概念
unittest是 Python 内置的标准测试框架。它基于面向对象的设计,提供了一组用于编写和运行单元测试的类和方法。
- 使用示例
- 以下是一个简单的
unittest测试用例示例,用于测试一个简单的加法函数:
- 以下是一个简单的
import unittestdef add_numbers(a, b):return a + bclass TestAddition(unittest.TestCase):def test_addition(self):result = add_numbers(3, 5)self.assertEqual(result, 8)if __name__ == '__main__':unittest.main()
pytest
- 基本概念
pytest是一个功能更强大、更灵活的第三方测试框架。它具有简洁的语法和丰富的插件生态系统,支持多种测试类型,如单元测试、功能测试、集成测试等。
- 使用示例
- 以下是一个使用
pytest测试上述加法函数的示例:
- 以下是一个使用
def add_numbers(a, b):return a + bdef test_addition():result = add_numbers(3, 5)assert result == 829.网络编程
Socket 编程
- 基础概念
- Socket 是一种用于实现网络通信的编程接口。它允许不同的计算机程序通过网络进行数据传输。在 Python 中,可以使用
socket模块进行 Socket 编程。
- Socket 是一种用于实现网络通信的编程接口。它允许不同的计算机程序通过网络进行数据传输。在 Python 中,可以使用
- 使用示例
以下是一个简单的基于 TCP 协议的 Socket 编程示例,实现了一个简单的服务器和客户端:
服务器端:
import socketserver_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('127.0.0.1', 8888))
server_socket.listen(5)while True:client_socket, client_address = server_socket.accept()data = client_socket.recv(1024)print(f"收到客户端数据: {data.decode('utf-8')}")client_socket.send(b"你好,客户端!")# client_socket.send("你好,客户端!".encode('utf-8'))client_socket.close()
客户端:
import socketclient_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect(('127.0.0.1', 8888))
client_socket.send(b"你好,服务器!")
# client_socket.send("你好,服务器!".encode('utf-8'))
data = client_socket.recv(1024)
print(f"收到服务器回复: {data.decode('utf-8')}")
client_socket.close()HTTP 编程
- 基础概念
- HTTP 是一种应用层协议,用于在万维网上传输超文本。在 Python 中,可以使用
urllib模块或更流行的requests模块进行 HTTP 编程。
- HTTP 是一种应用层协议,用于在万维网上传输超文本。在 Python 中,可以使用
- 使用示例
- 使用
requests模块获取网页内容:
- 使用
import requestsresponse = requests.get('https://www.example.com')
print(response.text)30.数据可视化(Matplotlib、Seaborn 等)
Matplotlib
- 基本概念
- Matplotlib 是一个 Python 的数据可视化库,它提供了丰富的绘图功能,用于创建各种类型的图表,如折线图、柱状图、饼图等。
- 使用示例
- 以下是一个简单的 Matplotlib 示例,绘制一个简单的折线图:
import matplotlib.pyplot as plt
import numpy as npx = np.arange(0, 10, 0.1)
y = np.sin(x)plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('y')
plt.title('Sin(x)函数图像')
plt.show()
Seaborn
- 基本概念
- Seaborn 是一个基于 Matplotlib 的高级数据可视化库,它提供了更简洁的语法和更美观的图表样式,用于数据分析和可视化。
- 使用示例
- 以下是一个简单的 Seaborn 示例,绘制一个散点图并添加回归直线:
import seaborn as sn
import pandas as pd
import numpy as npdata = pd.DataFrame({'x': np.arange(0, 10, 0.1),'y': np.sin(x) + np.random.normal(0, 0.1, len(x))
})g = sn.lmplot(data=data, x='x', y='y')
g.set_axis_labels('x', 'y')
g.set_title('Sin(x)函数图像及回归直线')31.深度学习框架集成(TensorFlow、PyTorch 等)
TensorFlow
- 基础概念
- TensorFlow 是一个广泛使用的深度学习框架,它提供了高效的计算图和自动微分功能,用于构建和训练深度学习模型。
- 使用示例
- 以下是一个简单的 TensorFlow 示例,构建一个简单的线性回归模型:
import tensorflow as tf# 定义输入和输出
x = tf.placeholder(tf.float32, shape=[None, 1])
y = tf.placeholder(tf.float32, shape=[None, 1])# 定义模型参数
W = tf.Variable(tf.random_normal([1, 1]))
b = tf.Variable(tf.zeros([1, 1]))# 定义模型
y_pred = tf.matmul(x, W) + b# 定义损失函数
loss = tf.reduce_mean(tf.square(y_pred - y))# 定义优化器
optimizer = tf.train.GradientDescentOptimizer(0.01)
train_op = optimizer.train_step(loss)# 训练模型
with tf.Session() as sess:sess.run(tf.global_variables_initializer())for i in 100:# 输入数据x_data = np.array([[i]]).astype(np.float32)y_data = np.array([[2 * i]]).astype(np.float32)sess.run(train_op, feed_dict={x: x_data, y: y_data})# 预测数据x_test = np.array([[10]]).astype(np.float32)y_pred_value = sess.run(y_pred, feed_dict={x: x_test})print(y_pred_value)
PyTorch
- 基础概念
- PyTorch 是另一个流行的深度学习框架,它具有动态计算图和易于使用的 API,用于构建和训练深度学习模型。
- 使用示例
- 以下是一个简单的 PyTorch 示例,构建一个简单的线性回归模型:
import torch
import torch.nn as nn
import torch.linear as Fclass LinearRegression(nn.Module):def __init__(self):super(LinearRegression, nn.Module).__init__()self.linear = nn.Linear(1, 1)def forward(self, x):return self.linear(x)model = LinearRegression()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), learning_rate=0.01)for i in range(100):# 输入数据x_data = torch.tensor([[i]], dtype=torch.float32)y_data = torch.tensor([[2 * i]], dtype=torch.float32)# 预测y_pred = model(x_data)loss = criterion(y_pred, y_data)optimizer.zero_grad()loss.backward()optimizer.step()# 预测数据
x_test = torch.tensor([[10]], dtype=torch.float32)
y_pred_value = model(x_adapter(x_test))
print(y_pred_value)