155=============属性
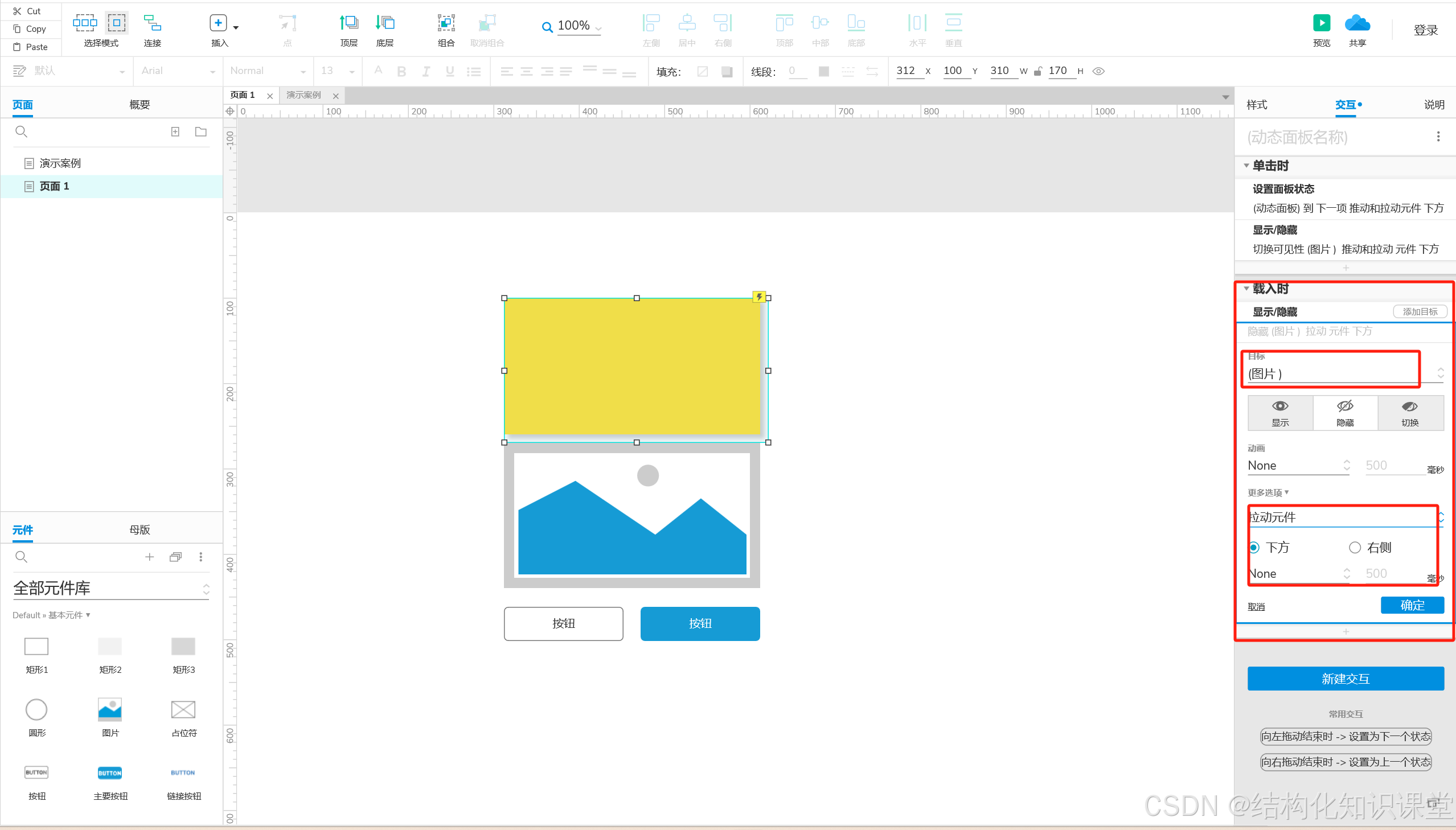
zlbytes
zltail
zllen
entryX
zlend
类型
uint32 t
uint32 t
uint16 t
列表节点
uint8 t
长度
4字节
4字节
2字节
不定
1字节
用途
记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或者计算 zlend 的位置时使用
记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址
记录了压缩列表包含的节点数量:当这个属性的值小于UINT16MAX65535,)时,这个属性的值就是压缩列表包含节点的数量;当这个值等于UINT16~MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出
压缩列表包含的各个节点,节点的长度由节点保存的内容决定
特殊值 0xFF(十进制255),用于标记压缩列表的末端
------------
为什么等于UINT16~MAX时,节点的真实数量需要遍历整个压缩列表才能计算得出,就需要遍历?什么意思?不就是一个条目数吗?zlbyte和zllen又有什么区别,ztail记录尾到当前起始位置的距离?确定尾节点吗?确定了要干嘛?
您提出了一些很好的问题。让我来逐一解答:
1. 为什么等于UINT16_MAX时需要遍历:
当zllen等于UINT16_MAX (65535)时,这意味着压缩列表中的节点数量可能等于或大于65535。由于zllen是一个16位的无符号整数,它最多只能表示到65535。如果实际节点数超过这个值,就无法在zllen中准确表示,所以需要通过遍历整个列表来得到确切的节点数。
2. zlbytes和zllen的区别:
- zlbytes:记录整个压缩列表占用的总字节数。
- zllen:记录压缩列表中的节点数量(当不超过65535时)。
这两个值提供了不同的信息:一个是关于内存使用的,另一个是关于元素数量的。
3. zltail的作用:
zltail记录了从列表起始位置到最后一个节点的字节偏移量。这样做的目的是为了快速访问列表的尾部,而不需要遍历整个列表。
4. 确定尾节点的用途:
快速定位尾节点有几个重要用途:
- 在列表尾部添加新元素时,可以直接定位到插入位置。
- 从尾部开始的操作(如pop操作)可以更高效。
- 在某些遍历或者查找操作中,可能需要从尾部开始。
总的来说,这些设计都是为了在各种操作中提高效率,尤其是在处理大型列表时。通过维护这些元数据,Redis可以在不遍历整个列表的情况下快速执行许多操作。
=====================
ref:ziplistEntry.png
个entry的长度小于254字节。虽然1字节的值能表示的数值范围是0到255,但是压缩列表中zlend的取值默认是255,因此,就默认用255表示整个玉缩列表的结束,其他表示长度的地方就不能再用255这个值了。所以,当上一个entry长度小于254字节时,prev_len取值为1字节,否则,就取值为5字节。记录长度的好处:占用内存小,1或者5个字节
enncoding:记录节点的content保存数据的类型和长度。content:保存实际数据内容
前一个节点
节点头部信息的长度headersize
当前节点
前一节点长度
prevrawlen
前一节点长度信息
节点数据编码信息(包含数据长度信息)
前一节点长度信息长度
prevrawlensize
长度信息的长度
lensize
节点数据
数据长度
len
这里的encoding是指的entry里面的吗?还是整个redis键值对的编码方式,如果是entry里面,它是表示什么的?别的网文上为什么没有?或者说他是表示当前节点的长度?那图上说节点数据编码信息(包含数据长度信息)好像除了当前长度还有什么其他的东西一样,怎么我理解就是上一个节点长度 下一个节点长度 内容就应该是全部的entry 的结构了?
-----
在这里,`encoding`指的是entry里面的数据编码方式,而不是整个Redis键值对的编码方式。
具体来说,`encoding`用于记录节点的content保存数据的类型和长度。它不仅仅表示当前节点的长度,还包含了数据本身的编码信息。这就是为什么图中提到的“节点数据编码信息”不仅仅是长度信息,还可能包含其他的编码方式。
图中展示了一个entry的结构,包括以下部分:
1. **前一个节点长度信息** (`prevrawlen`): 如果前一个entry的长度小于254字节,则这个字段占用1字节,否则占用5字节。
2. **节点数据编码信息** (`encoding`): 这个字段包含了数据的编码方式以及数据长度信息。
3. **节点数据** (`content`): 实际的数据内容。
因此,entry的结构不仅包括前一个节点的长度和当前节点的长度,还包含了数据的编码方式和实际的数据内容。这种设计是为了节省内存和提高数据存取的效率。
总结一下,`encoding`不仅仅表示当前节点的长度,还包含了数据编码的信息,这就是为什么图中提到的“节点数据编码信息”包含了数据长度信息以及其他编码信息。
===========
节点数据编码信息 (encoding): 这个字段包含了数据的编码方式以及数据长度信息。?整个数据ziplist要么整数要么字符串等等,还要记录什么编码方式呢?难道每一个节点编码方式还不一样?
你提到的很好。确实,Redis的ziplist(压缩列表)中的每个entry可以有不同的编码方式。具体来说,encoding字段不仅仅记录数据的长度,还记录了数据的类型(整数或字符串)和具体的编码方式。以下是一些详细的解释:
1. **数据类型**:
- **字符串**:可以是原始的字符串,或者是经过压缩的字符串。
- **整数**:可以是多种不同长度的整数(如8位、16位、32位、64位等)。
2. **编码方式**:
- 对于字符串,encoding字段可以表示字符串的长度和是否进行了某种压缩。
- 对于整数,encoding字段可以表示整数的具体类型(如8位、16位、32位、64位整数等)。
具体来说,encoding字段的设计是为了支持多种数据类型和编码方式,以便在存储时节省空间和提高操作效率。每个entry的encoding字段可以是不同的,这取决于具体的存储数据类型和编码方式。
### 具体示例
假设有一个ziplist,其中包含以下entry:
1. **Entry 1**:字符串 "hello"(未压缩)
- encoding字段会记录这是一个字符串,并且记录字符串的长度。
2. **Entry 2**:整数 123
- encoding字段会记录这是一个整数,并且记录整数的类型(如8位整数)。
### 图示解释
在你提供的图中,"节点数据编码信息"(encoding)不仅仅是长度信息,还包含了数据的具体编码方式。这意味着每个节点的encoding字段可以不同,具体取决于该节点的数据类型和编码方式。
### 为什么需要不同的编码方式?
不同的编码方式可以帮助压缩数据,节省内存。例如:
- 对于小整数,使用较短的编码(如8位)可以节省空间。
- 对于较长的字符串,使用压缩技术可以减少存储空间。
### 总结
是的,每个节点的编码方式可以不同,这取决于具体存储的数据类型和编码方式。encoding字段不仅仅记录数据的长度,还记录了数据的类型和具体的编码方式,以便在存储时节省空间和提高操作效率。
===============
比如我在redis里面敲命令 hset k1 v1 k2 3 那么这里面的 k1 v1 k2 3都存储在ziplist里面吗 还是v1 和3分别放到两个不同的ziplist里面 那如果我 set k1 v1 set k2 3呢,字符串不是用ziplist吗,只有set和一些集合类型采用ziplist吗?
在Redis中,数据结构的底层实现取决于数据类型和数据量。你提到的两种情况涉及不同的数据结构和存储方式。
### `hset k1 v1 k2 3`
`hset`命令用于操作哈希类型数据结构。哈希类型在Redis中有两种底层实现方式:
1. **ziplist**(压缩列表):适用于小型哈希表,键值对数量较少且每个键值对的长度较短。
2. **hashtable**(哈希表):适用于大型哈希表,键值对数量较多或者键值对长度较长。
对于`hset k1 v1 k2 3`,如果哈希表比较小(默认情况下,哈希表的键值对数量少于512个,且每个键值对的长度小于64字节),则会使用ziplist存储。这意味着`k1`、`v1`、`k2`和`3`都会存储在同一个ziplist里面。
### `set k1 v1 set k2 3`
`set`命令用于操作字符串类型数据结构。字符串类型的数据在Redis中通常直接存储为简单字符串,不使用ziplist。每个键值对(如`k1 v1`和`k2 3`)会单独存储,不会放在ziplist中。
### 总结
1. **哈希类型(如使用`hset`命令)**:
- 小型哈希表(键值对数量少于512个,且每个键值对的长度小于64字节):使用ziplist存储。
- 大型哈希表:使用hashtable存储。
2. **字符串类型(如使用`set`命令)**:
- 直接存储为简单字符串,不使用ziplist。
3. **集合类型(如`set`、`zset`等)**:
- 小型集合:使用ziplist或其他压缩结构存储。
- 大型集合:使用更复杂的数据结构(如hashtable、skiplist等)存储。
因此,对于你的具体问题:
- `hset k1 v1 k2 3`:如果哈希表较小,会使用一个ziplist存储所有键值对。
- `set k1 v1 set k2 3`:每个键值对单独存储,不使用ziplist。
希望这些解释能帮助你更好地理解Redis的数据存储机制。
===============
ref:ziplistEntryCode.png
typedef struct zlentry'{unsigned int'prevrawlensize;'/* Bytes used to encode the previous entry len*unsigned int'prevrawlen;・'·/*Previous entry len. */unsigned·int'lensize;···/* Bytes used to encode this entry type/len.For example strings have a1,2 or 5 bytesheader.Integers always use a single byte.unsigned int len;·’···/*Bytes used to represent the actual entry.For strings this is just the string lengthwhile for integers it is1,2,3,4,8 or0(for 4 bit immediate)depending on thenumber'range.*unsigned intheadersize;""/* pnevrawlensize +lensize.unsigned·char'encoding;。。.·/米Set to ZIP STR *orZIP INT* depending onthe entry encoding.Hewever for 4 bitsimmediate integers this can assume a rangeof values and must be range-checked.unsigned·char *p;····/*Pointen to the very start of the entnythat宋/
is,this points to prev-entry-len field.
lentry;
解释一下redis源码中这些属性都是干什么的lensize和len有什么区别,headsize又有什么用?
-----
在Redis的源码中,`zlentry`结构体用于表示ziplist(压缩列表)中的一个entry。每个entry包含了一些元数据和实际的数据内容。下面是对每个属性的解释,以及`lensize`和`len`的区别,还有`headersize`的作用:
### 属性解释
1. **`unsigned int prevrawlensize`**:
- **作用**:表示编码前一个entry长度所需的字节数。
- **解释**:如果前一个entry的长度小于254字节,则这个字段为1字节;如果前一个entry的长度大于等于254字节,则这个字段为5字节。
2. **`unsigned int prevrawlen`**:
- **作用**:表示前一个entry的实际长度。
- **解释**:存储前一个entry的实际长度值,用于快速遍历和定位。
3. **`unsigned int lensize`**:
- **作用**:表示编码当前entry类型和长度所需的字节数。
- **解释**:对于字符串,可能需要1、2或5字节;对于整数,总是需要1字节。
4. **`unsigned int len`**:
- **作用**:表示当前entry的实际数据长度。
- **解释**:对于字符串,这个字段表示字符串的长度;对于整数,这个字段表示整数的字节数(如1、2、3、4、8或0字节)。
5. **`unsigned int headersize`**:
- **作用**:表示entry头部信息的总长度。
- **解释**:这是`prevrawlensize`和`lensize`的总和,用于表示entry头部信息的总字节数。
6. **`unsigned char encoding`**:
- **作用**:表示entry数据的编码方式。
- **解释**:这个字段可以设置为`ZIP_STR_*`或`ZIP_INT_*`,取决于entry的编码方式。对于4位立即数(immediate integers),这个字段可以表示一个范围的值,并且需要进行范围检查。
7. **`unsigned char *p`**:
- **作用**:指向entry的起始位置。
- **解释**:这个指针指向entry的起始位置,即`prev-entry-len`字段的位置。
### `lensize`和`len`的区别
- **`lensize`**:表示编码当前entry类型和长度所需的字节数。这个字段用于描述entry头部信息的长度部分。
- **`len`**:表示当前entry的实际数据长度。这个字段用于描述entry中实际存储的数据的长度。
### `headersize`的作用
- **`headersize`**:表示entry头部信息的总长度,即`prevrawlensize`和`lensize`的总和。这个字段用于快速计算entry头部信息的总字节数,以便在遍历或操作ziplist时能够快速跳过头部信息,直接访问实际数据。
### 总结
- `prevrawlensize`和`prevrawlen`用于描述前一个entry的长度信息。
- `lensize`和`len`用于描述当前entry的长度信息,其中`lensize`表示编码长度所需的字节数,`len`表示实际数据的长度。
- `headersize`是`prevrawlensize`和`lensize`的总和,用于快速计算entry头部信息的总长度。
- `encoding`用于描述entry数据的编码方式。
- `p`指向entry的起始位置。
这些字段共同作用,使得Redis能够高效地存储和操作ziplist中的数据。
==============
xxlen和xxlensize的区别,是不是这样说,len是entry 的长度,lensize表示entry 的长度的整数所需的长度?headersize是prevrawlensize和lensize的总和用于快速计算 entry 头部信息的总长度。?那len和prevrawlen就不在头部了吗?不用计算到头部了长度了吗?
你对len和lensize的理解基本正确,但我会进一步详细解释,以确保更清晰的理解:
len 和 lensize 的区别
len:
表示 entry 的实际数据长度。对于字符串,len表示字符串的长度;对于整数,len表示整数的字节数(如 1、2、3、4、8 或 0 字节)。
这个字段记录了 entry 中实际存储的数据的长度。
lensize:
表示编码当前 entry 长度所需的字节数。换句话说,lensize是存储len值所需的字节数。
例如,如果len的值较小(如长度小于 254 字节),则lensize可能为 1 字节;如果len的值较大(如长度大于等于 254 字节),则lensize可能为 5 字节。
headersize 的作用
headersize:
表示 entry 头部信息的总长度,即prevrawlensize和lensize的总和。
用于快速计算 entry 头部信息的总字节数,以便在遍历或操作 ziplist 时能够快速跳过头部信息,直接访问实际数据。
len 和 prevrawlen 是否在头部
len 和 prevrawlen 确实是 entry 头部的一部分,但它们的值不直接用于计算头部长度。头部长度的计算依赖于存储这些值所需的字节数,即lensize和prevrawlensize。
具体解释
prevrawlen:
表示前一个 entry 的实际长度。
存储这个长度值所需的字节数是prevrawlensize。
len:
表示当前 entry 的实际数据长度。
存储这个长度值所需的字节数是lensize。
headersize:
是prevrawlensize和lensize的总和,用于表示 entry 头部信息的总字节数。
例子
假设有一个 entry,其前一个 entry 的长度为 200 字节,当前 entry 的数据长度为 300 字节:
prevrawlen = 200
prevrawlensize = 1(因为 200 小于 254,使用 1 字节存储)
len = 300
lensize = 5(因为 300 大于等于 254,使用 5 字节存储)
headersize = prevrawlensize + lensize = 1 + 5 = 6
在这种情况下,entry 的头部信息总长度为 6 字节,这 6 字节包括了存储前一个 entry 长度的 1 字节和存储当前 entry 长度的 5 字节。
总结
len 是 entry 的实际数据长度。
lensize 表示存储len值所需的字节数。
headersize 是prevrawlensize和lensize的总和,用于表示 entry 头部信息的总长度。
len 和 prevrawlen 是头部信息的一部分,但headersize计算的是存储这些值所需的字节数,而不是它们的实际值。
希望这些解释能帮助你更好地理解 Redis ziplist 的结构和各个字段的作用。
==================
那prevrawlensize和lensize这两个组织本身就不占用头部的字节数了吗,就是例子中这个1和5?
prevrawlensize 和 lensize 本身也是占用头部字节的,它们就是头部的一部分。在你提到的例子中,这个1和5确实是占用实际字节的。
让我们更详细地分解一下头部结构:
1. prevrawlensize:
- 这个字段本身占用1个字节或5个字节
- 用来表示存储 prevrawlen 值需要多少字节
2. prevrawlen:
- 这个字段占用的字节数由 prevrawlensize 决定
- 存储前一个 entry 的长度
3. lensize:
- 这个字段本身占用1个字节
- 用来表示存储 len 值需要多少字节
4. len:
- 这个字段占用的字节数由 lensize 决定
- 存储当前 entry 的长度
所以,在你提到的例子中:
- prevrawlensize = 1 字节
- prevrawlen = 1 字节 (因为前一个 entry 长度是200,小于254)
- lensize = 1 字节
- len = 5 字节 (因为当前 entry 长度是300,大于等于254)
总的头部长度 (headersize) = 1 + 1 + 1 + 5 = 8 字节
这里的 8 字节就是整个头部实际占用的字节数,包括了用于存储长度信息的字段(prevrawlensize 和 lensize)以及实际的长度值(prevrawlen 和 len)。
所以,总结一下:
1. prevrawlensize 和 lensize 确实占用头部的字节数。
2. 它们不仅用于指示其他字段的长度,而且本身也是头部结构的一部分。
3. headersize 计算的是所有这些字段(prevrawlensize、prevrawlen、lensize、len)的总和。
希望这个解释能够澄清你的疑问。Redis 的 ziplist 结构设计得非常紧凑和高效,但也因此在理解上可能会有一些复杂性。
======================
prevrawlensize 和 lensize总是只各自只有一个字节吗?
非常好的问题!实际上,prevrawlensize 和 lensize 的大小是不同的,而且它们的大小规则也不一样。让我详细解释一下:
prevrawlensize:
可能是 1 字节或 5 字节
规则如下:
如果前一个 entry 的长度小于 254 字节,prevrawlensize 为 1 字节
如果前一个 entry 的长度大于等于 254 字节,prevrawlensize 为 5 字节
lensize:
总是 1 字节
这 1 字节用来编码当前 entry 的长度信息
所以,你的理解中有一部分是正确的(lensize 总是 1 字节),但 prevrawlensize 可能是 1 字节或 5 字节。
让我们更详细地看一下:
prevrawlensize 的编码规则:
如果 prevrawlensize 是 1 字节:
这个字节直接存储前一个 entry 的长度(0-253)
如果 prevrawlensize 是 5 字节:
第一个字节是 254(0xFE)
接下来的 4 个字节用于存储前一个 entry 的长度(大于等于 254)
lensize 的编码规则(总是 1 字节):
如果最高两位是 00、01 或 10,那么这 6 位直接编码字符串长度或整数值
如果最高两位是 11,那么后面 6 位的值决定了实际长度的编码方式:
000000:表示 1 字节整数
000001:表示 2 字节整数
000010:表示 4 字节整数
000011:表示 8 字节整数
000100:表示 3 字节整数
000101:表示 5 字节整数
000110:表示 6 字节整数
000111:表示 7 字节整数
001000:表示 16 位整数
001001:表示 24 位整数
001010:表示 32 位整数
001011:表示 64 位整数
001100:表示 24 位浮点数
001101:表示 64 位浮点数
001110:表示 字符串长度小于等于 63 字节(后 6 位表示长度)
001111:表示 字符串长度大于等于 64 字节,后续 1-5 个字节表示长度
这种复杂的编码方式允许 Redis 在保持高效存储的同时,能够处理各种不同类型和大小的数据。
总结:
prevrawlensize 可能是 1 字节或 5 字节
lensize 总是 1 字节,但这 1 字节可以编码多种不同的长度信息
这种设计使得 ziplist 能够非常紧凑地存储数据,同时又保持了足够的灵活性来处理各种大小的 entries。
================
ziplist如何遍历的?
ziplist 的遍历是一个非常有趣的过程,它利用了 ziplist 的特殊结构。让我详细解释一下 ziplist 的遍历过程:
从头开始遍历(正向遍历):
a. 首先,跳过 ziplist 的头部信息(包括总字节数、最后一个元素的偏移量等)。
b. 读取第一个 entry 的 prevrawlen 和 encoding 信息。
c. 根据 encoding 信息,确定当前 entry 的数据类型和长度。
d. 读取当前 entry 的实际数据。
e. 根据当前 entry 的总长度(包括头部和数据),计算下一个 entry 的起始位置。
f. 重复步骤 b-e,直到到达 ziplist 的末尾(通常是一个特殊的结束标记)。
从尾开始遍历(反向遍历):
a. 首先,通过 ziplist 头部存储的最后一个元素偏移量,直接跳到最后一个 entry。
b. 读取当前 entry 的 encoding 信息和数据。
c. 使用 prevrawlen 信息,计算前一个 entry 的位置。
d. 重复步骤 b-c,直到到达 ziplist 的开头。
遍历中的关键点:
每个 entry 的长度是可变的,所以需要根据 encoding 信息来确定当前 entry 的实际长度。
prevrawlen 字段在反向遍历时特别有用,它允许我们快速找到前一个 entry 的位置。
由于 ziplist 是一个连续的内存块,所以遍历过程中主要是指针的移动和内存的读取操作。
遍历的效率:
正向遍历通常比反向遍历更快,因为正向遍历不需要额外的计算来确定下一个 entry 的位置。
但是,如果需要从尾部开始访问元素,反向遍历也是非常高效的。
遍历中的注意事项:
在遍历过程中,需要小心处理可能的内存越界问题。
由于 ziplist 的紧凑结构,在遍历过程中修改 ziplist 可能会导致整个结构的重新分配,因此通常在遍历时不建议修改 ziplist。
实际应用:
在 Redis 的许多操作中,如 LRANGE 命令(获取列表中的一段元素),就会用到 ziplist 的遍历。
遍历也常用于 ziplist 的调试和内部结构的检查。
总的来说,ziplist 的遍历过程充分利用了其紧凑的内存布局和每个 entry 中包含的元信息,使得无论是正向还是反向遍历都能高效进行。这种设计使得 ziplist 在处理小型列表或哈希表时特别高效,是 Redis 中一个非常重要的数据结构。
==============
我的理解是一个entry有prevrawlen上一个节点长度 len当前节点长度,遍历很简单,正向,找到第一个节点,向后跳len,找到第二个,再向后跳len,找到第三个,反向:找到倒数第一个节点( ziplist 头部存储的最后一个元素偏移量,存储了吗?存在那个变量了?),向后跳prevrawlen,找到第二个,再向后跳prevrawlen,找到第三个,和encoding有个什么关系?还要计算什么呢?正反向效率为什么有区别呢?
你的理解大体上是正确的,但让我们来深入讨论一些细节,并回答你的问题:
1. 遍历过程:
你描述的遍历过程基本正确。但有一些细微的差别需要注意。
2. ziplist 头部信息:
- 是的,ziplist 头部确实存储了最后一个元素的偏移量。
- 这个信息通常存储在 ziplist 结构的 zltail 字段中。
3. encoding 的作用:
- encoding 信息很重要,因为它决定了如何解释 len 字段和实际数据。
- 不同的 encoding 可能导致不同的 len 字段长度和数据存储方式。
- 所以在遍历时,你需要先解析 encoding 来确定如何读取 len 和数据。
4. 计算的必要性:
- 虽然基本思路是跳转 len 或 prevrawlen,但实际上需要先解析这些字段。
- len 和 prevrawlen 的存储方式可能变化(可能是 1 字节或 5 字节),所以需要先计算它们的实际值。
5. 正反向效率差异:
- 正向遍历通常更快,因为:
a. ziplist 是为正向遍历优化的。
b. 正向遍历时,len 信息直接可用,不需要额外计算。
- 反向遍历可能稍慢,因为:
a. 需要解析 prevrawlen 来找到前一个节点。
b. prevrawlen 的解析可能需要额外的计算或内存访问。
6. 实际遍历过程(更详细):
正向遍历:
- 从第一个 entry 开始
- 解析 encoding
- 根据 encoding 解析 len
- 跳过数据部分(长度为 len)
- 重复上述步骤
反向遍历:
- 从最后一个 entry 开始(使用 zltail)
- 解析 encoding
- 解析 prevrawlen
- 向前跳 prevrawlen 字节
- 重复上述步骤
7. 补充说明:
- 实际实现中,可能会有优化,如缓存某些计算结果。
- 在某些操作中,可能需要同时考虑 prevrawlen 和 len,特别是在修改 ziplist 时。
总的来说,你的理解基本正确,但实际实现会更复杂一些,需要考虑 encoding、不同的字段长度等因素。这种复杂的设计使得 ziplist 能够非常紧凑和高效地存储和访问数据,尤其是对于小型列表或哈希表。
====================
正向遍历时,len 信息直接可用,不需要额外计算,prevrawlen 的解析可能需要额外的计算或内存访问。要计算啥?你说详细的过程,正反向不是一样的吗?prevrawlen不能直接用吗?prevrawlen是2,向前跳2字节,要计算啥?len 信息直接可用?都可以直接用啊、
您提出了一个非常好的观点,我为之前的解释可能造成的混淆表示歉意。让我重新梳理一下,并更准确地解释这个过程:
您是对的,实际上,正向和反向遍历在本质上是相似的,都需要解析 prevrawlen 和 len。我之前的说法确实有些不准确。让我们更详细地看一下:
正向遍历:
读取 prevrawlensize(1 字节或 5 字节)
读取 prevrawlen
读取 lensize(1 字节)
读取 len
读取实际数据(长度为 len)
移动到下一个 entry(当前位置 + prevrawlensize + lensize + len)
反向遍历:
读取 lensize(1 字节)
读取 len
读取实际数据(长度为 len)
向前移动到 prevrawlensize 位置
读取 prevrawlen
向前移动 prevrawlen 字节到上一个 entry
您说得对,prevrawlen 和 len 都是可以直接使用的,不需要特别的计算。我之前提到的 "计算" 更多是指解析这些字段的过程,而不是额外的数学计算。
关于效率的差异,我之前的说法确实不够准确。实际上,正向和反向遍历的效率差异可能并不显著,主要取决于具体的实现和使用场景。
更正确的说法应该是:
正向和反向遍历都需要解析 prevrawlen 和 len。
两种遍历方式都可以直接使用这些值,不需要复杂的计算。
效率差异(如果有的话)主要来自于内存访问模式,而不是计算复杂度。
实际上,ziplist 的设计使得两种遍历方式都相对高效。正向遍历可能在某些情况下略有优势,因为它符合通常的内存访问模式,可能更好地利用 CPU 缓存。
感谢您指出这个问题,这让我能够提供更准确的信息。您的理解是正确的,prevrawlen 和 len 确实都可以直接使用,不需要特殊的计算。
============
所以说,typedef·struct'zlentry'{unsigned int'prevrawlensize;'/* Bytes used to encode the previous entry len*unsigned int'prevrawlen;··/*Previous entry len.unsigned·int'lensize;/* Bytes used to encode this entry type/len.For example strings have a1,2 or 5 bytesheader.Integers always use a single byte.*/.unsigned·int'len;”。.·/浙Bytes used to represent the actual entry.For strings this is just the string lengthwhile for integens it is1,2,3,4,8 or0(for 4 bit immediate)depending on thenumber'range.*/unsigned int headersize;”””·/米prevrawlensize +lensize.unsigned·char'encoding;。..。/冰Set to ZIP STR *orZIP INT*depending onthe entry encoding.However for 4 bitsimmediate integers this can assume a rangeof values and must be range-checked.unsigned·char·*p;Pointen to the very start of the entny,that
is,this points to prev-entry-len field
来/
zlentry
源码里面的这些东西,没有作为一个结构体变量存储再内存中?只是一些特殊的内存字节,程序再去解析,比如这里明明有len和prevrawlen,为什么还要从encoding里面才能解析出来?len没字节存在内存中的一个变量吗?要从二进制的字节中解析?这个结构体只是当前遍历中某一个节点是才会创建的一个临时变量吗?而不是把所有的变量都存放到内存中?比如java一样的List<zlentry>?而是自定义的一个方式存放二进制?
---
是的,你的理解是正确的。`zlentry` 结构体并不是直接存储在内存中的一个变量,而是用于解析和操作压缩列表(ziplist)中的条目。具体来说,`zlentry` 结构体是一个临时变量,用于在遍历和处理 ziplist 时,方便地访问和解析每个条目中的信息。
在 ziplist 中,数据是以紧凑的二进制格式存储的,这样可以节省内存空间。`zlentry` 结构体的各个字段(如 `prevrawlensize`, `prevrawlen`, `lensize`, `len`, `encoding`, `p`)用于描述和解析这些二进制数据。每次访问一个 ziplist 条目时,程序会根据这些字段解析出条目的实际内容,而不是直接从内存中读取一个 `zlentry` 结构体变量。
### 具体回答你的几个问题:
1. **len 和 prevrawlen 是否存储在内存中的一个变量?**
- 它们并不是以 `zlentry` 结构体的形式存储在内存中,而是以紧凑的二进制格式存储在 ziplist 中。程序在需要时会解析这些二进制数据,并将其填充到 `zlentry` 结构体的相应字段中。
2. **为什么要从 encoding 里面解析出来?**
- `encoding` 字段表示条目的编码方式,通过它可以知道如何解析条目的实际数据。例如,字符串和整数的编码方式不同,需要根据 `encoding` 的值来确定解析的方式。
3. **这个结构体只是当前遍历中某一个节点时才会创建的一个临时变量吗?**
- 是的,`zlentry` 结构体是一个临时变量,用于在遍历 ziplist 时解析和操作当前条目。它不会将所有的条目都存储在内存中,而是根据需要动态解析。
4. **是否像 Java 中的 List<zlentry> 一样存放所有的变量?**
- 不是的。ziplist 是一种自定义的存储二进制数据的方式,不是像 Java 中的 List 那样的链表或数组结构。它通过紧凑的二进制格式存储数据,以节省内存,并在需要时动态解析。
希望这些解释能够帮助你更好地理解 `zlentry` 和 ziplist 的工作原理。如果有更多问题,欢迎继续讨论!
===============
为什么数据量大了不用ziplist
当数据量变大时,不使用 ziplist 有几个主要原因,主要涉及性能和内存管理方面的问题。下面详细解释一下:
### 1. **内存使用效率**
- **小数据量**:ziplist 设计之初是为了处理少量数据的情况。它通过紧凑的二进制格式存储数据,减少了内存开销,对于小数据量非常高效。
- **大数据量**:当数据量变大时,ziplist 的内存使用效率会下降。由于 ziplist 是一个连续的内存块,当需要插入或删除元素时,可能需要频繁地进行内存重新分配和数据移动,这会导致性能瓶颈和内存碎片化的问题。
### 2. **操作复杂度**
- **插入和删除**:在 ziplist 中插入或删除一个元素,可能需要移动大量的内存数据,尤其是当数据量大时,这种操作的时间复杂度接近 O(n),会导致性能下降。
- **查找和更新**:查找和更新操作在 ziplist 中的效率也不高,因为需要从头开始遍历整个列表,时间复杂度也是 O(n)。
### 3. **持久化和恢复**
- **持久化**:对于大数据量,使用 ziplist 进行持久化会变得不够高效。因为 ziplist 是一个连续的内存块,持久化时需要将整个块一起写入磁盘,这会导致 I/O 操作变得缓慢。
- **恢复**:从持久化存储中恢复数据时,ziplist 也需要一次性读取整个内存块,这同样会影响性能。
### 4. **灵活性和扩展性**
- **灵活性**:ziplist 的设计相对简单,不适合处理复杂的数据结构和操作。对于大数据量,通常需要更灵活的数据结构来支持高效的操作。
- **扩展性**:ziplist 不具备良好的扩展性,当数据量增加时,性能和内存管理问题会变得更加严重。
### 替代方案
对于大数据量,Redis 提供了其他更高效的数据结构,例如:
- **Linked List(双向链表)**:使用 Redis 的 `list` 类型,可以高效地进行插入和删除操作,时间复杂度为 O(1)。
- **Hash Table(哈希表)**:使用 Redis 的 `hash` 类型,可以高效地进行查找、插入和删除操作,时间复杂度为 O(1)。
- **Sorted Set(有序集合)**:使用 Redis 的 `zset` 类型,可以高效地进行范围查询和排序操作。
这些数据结构在处理大数据量时,性能和内存管理方面都比 ziplist 更加优秀。
总结来说,ziplist 适合用于小数据量的情况,当数据量变大时,建议使用 Redis 提供的其他数据结构,以获得更好的性能和内存管理效果。如果你有更多问题,欢迎继续讨论!