项目:Boost 搜索引擎
1、项目背景
- 公司:百度、360、搜狗、谷歌 …
- 站内搜索:搜索的数据更垂直(相关),数据量小
2、整体框架
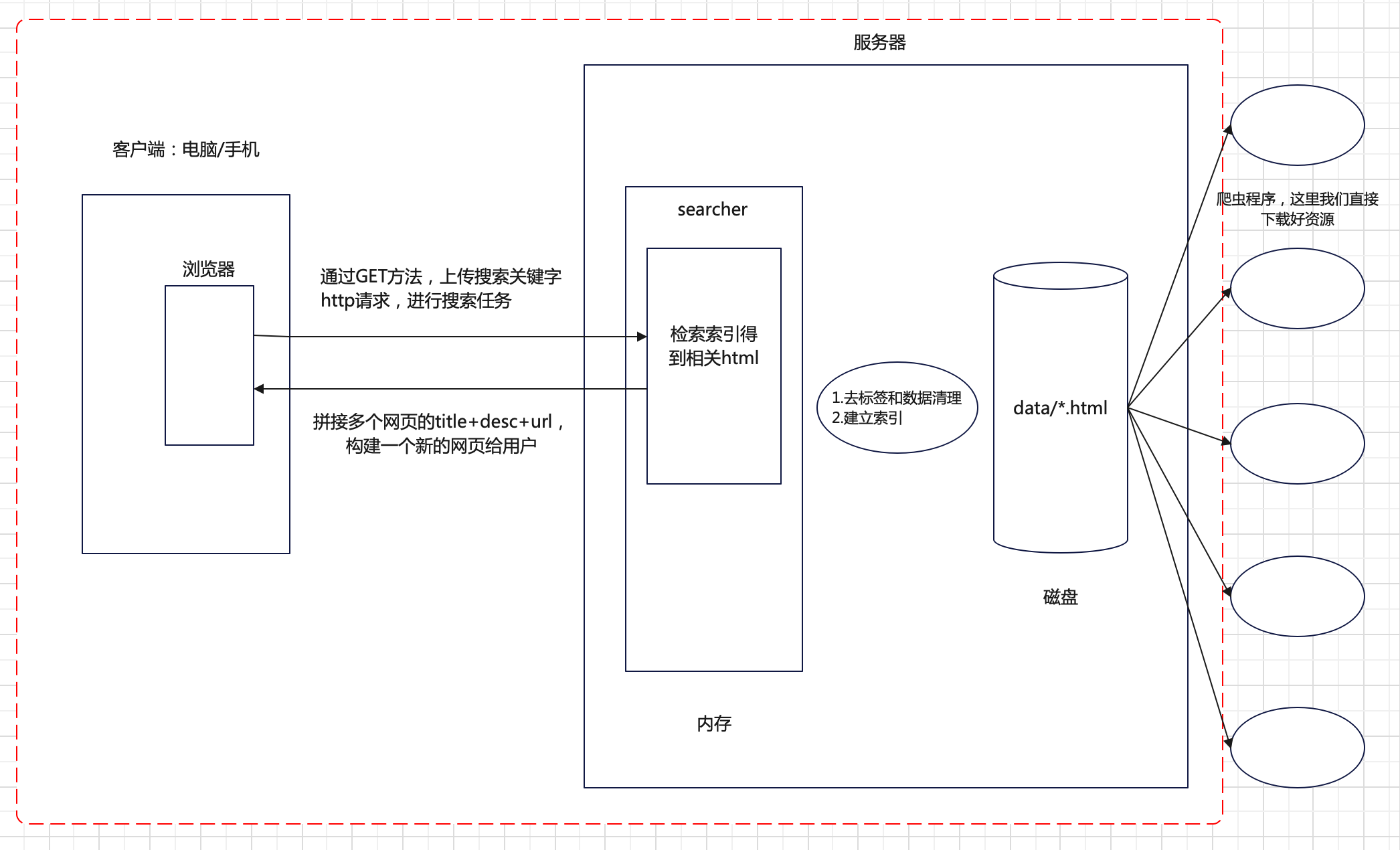
3、技术栈和项目环境
技术栈:
C/C++ C++11,STL,jsoncpp,Boost准标准库,cppjieba,cpp-httplib了解:
html5,css,js,jQuery,Ajax项目环境:
Ubuntu 20.04 云服务器,vscode
4、正排索引和倒排索引(搜索引擎具体原理)
文档一:我钓到了一条鱼
文档二:我吃了一条鲫鱼
正排索引:通过文档ID找到文档内容(文档中的关键字)
文档ID 文档内容 1 我钓到了一条鱼 2 我吃了一条鲫鱼 目标文档进行分词(方便建立倒排索引进行查找)
文档一[我钓到了一条鱼]:我/钓到/一条/鱼
文档一[我吃了一条鲫鱼]:我/吃/一条/鲫鱼
停止词:了,吗,的,a,the,一般进行分词的时候不考虑
倒排索引:根据文档内容,分词,整理不重复的关键字,对应联系到文档ID的方案
关键字(唯一) 文档ID,weight(权重) 我 1,w1 ; 2,w2 钓到 1,w3 一条 1,w4 ; 2,w5 吃 2,w6 鲫鱼 2,w7 模拟一次查找过程:一条 -> 倒排索引查找 -> 提取出文档ID(1,2) -> 根据正排索引 -> 找到文档内容 ->
title+desc+url文档结果进行摘要 -> 构建相应结果。
5、编写数据去标签和数据清洗的模块 Parser
boost官网:https://www.boost.org // 目前只需要boost_1_86_0/doc.html路径下的html文件,用来建立索引
- 保存所有html文件路径:
bool EnumFile(const std::string &search_file, std::vector<std::string> *files_list) {namespace fs = boost::filesystem;fs::path root_path(search_file);// 判断路径是否存在,不存在就直接退出if (!fs::exists(root_path)){std::cerr << search_file << " not exists!" << std::endl;return false;}// 定义一个空的迭代器,用来进行判断递归结束fs::recursive_directory_iterator end;for (fs::recursive_directory_iterator iter(root_path); iter != end; ++iter){// 判断文件是否是普通文件,html都是普通文件if (!fs::is_regular_file(*iter)){continue;}// 判断普通文件是不是html后缀if (iter->path().extension() != ".html"){continue;}// debug// std::cout << "debug : " << iter->path().string() << std::endl;// 当前路径合法// 将所有带路径的html文件放到files_list容器files_list->push_back(iter->path().string());}return true; }
- 去标签:
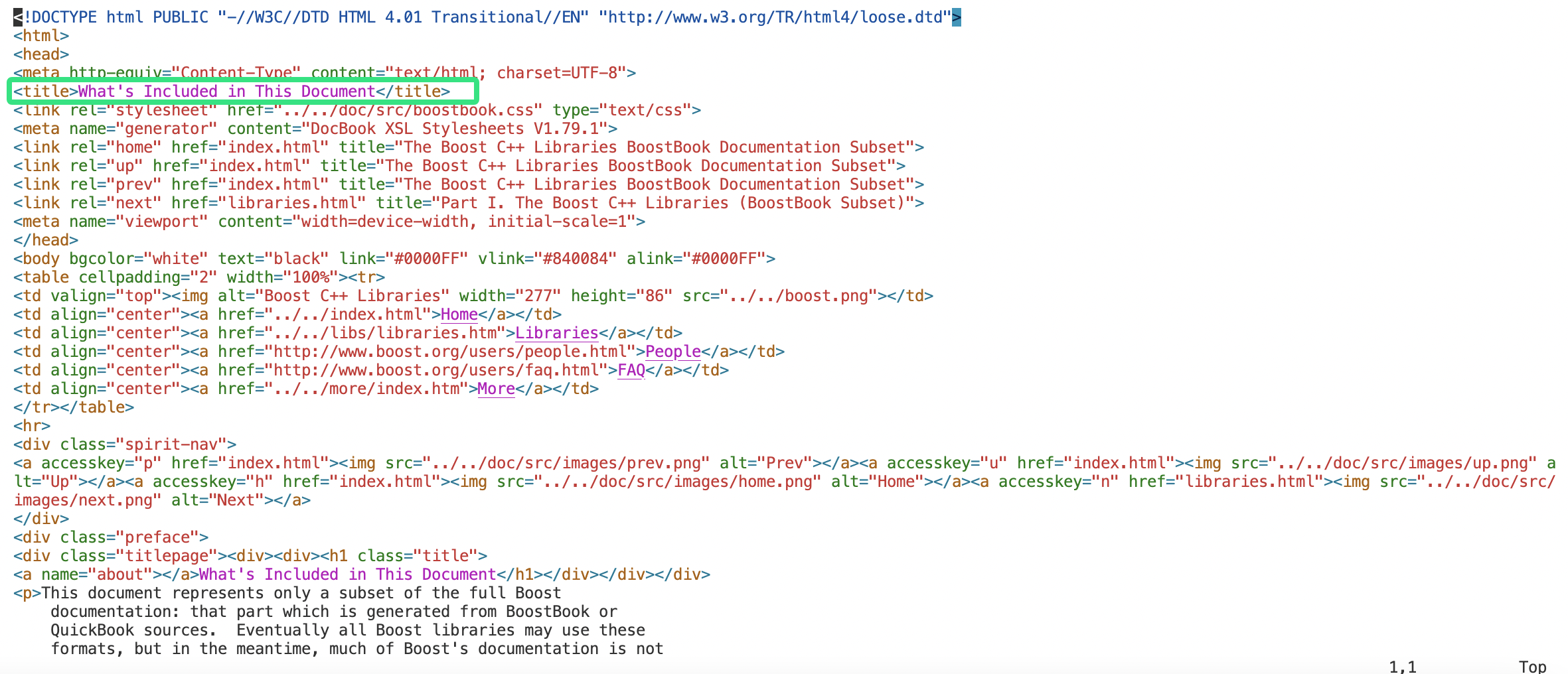
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>What's Included in This Document</title> <link rel="stylesheet" href="../../doc/src/boostbook.css" type="text/css"> <meta name="generator" content="DocBook XSL Stylesheets V1.79.1"> <link rel="home" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset"> <link rel="up" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset"> <link rel="prev" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset"> <link rel="next" href="libraries.html" title="Part I. The Boost C++ Libraries (BoostBook Subset)"> <meta name="viewport" content="width=device-width, initial-scale=1"> </head> <body bgcolor="white" text="black" link="#0000FF" vlink="#840084" alink="#0000FF"> <table cellpadding="2" width="100%"><tr> <td valign="top"><img alt="Boost C++ Libraries" width="277" height="86" src="../../boost.png"></td> <td align="center"><a href="../../index.html">Home</a></td> <td align="center"><a href="../../libs/libraries.htm">Libraries</a></td> <td align="center"><a href="http://www.boost.org/users/people.html">People</a></td> <td align="center"><a href="http://www.boost.org/users/faq.html">FAQ</a></td> <td align="center"><a href="../../more/index.htm">More</a></td> </tr></table> <hr> <div class="spirit-nav"> <a accesskey="p" href="index.html"><img src="../../doc/src/images/prev.png" alt="Prev"></a><a accesskey="u" href="index.html"><img src="../../doc/src/images/up.png" alt="Up"></a><a accesskey="h" href="index.html"><img src="../../doc/src/images/home.png" alt="Home"></a><a accesskey="n" href="libraries.html"><img src="../../doc/src/images/next.png" alt="Next"></a> </div> <div class="preface"> <div class="titlepage"><div><div><h1 class="title"> <a name="about"></a>What's Included in This Document</h1></div></div></div> <p>This document represents only a subset of the full Boostdocumentation: that part which is generated from BoostBook orQuickBook sources. Eventually all Boost libraries may use theseformats, but in the meantime, much of Boost's documentation is notavailable here. Pleasesee <a href="http://www.boost.org/libs" target="_top">http://www.boost.org/libs</a>for complete documentation.</p> <p>Documentation for some of the libraries described in this document isavailable in alternative formats:</p> <div class="itemizedlist"><ul class="itemizedlist" style="list-style-type: disc; "><li class="listitem"><a class="link" href="index.html" title="The Boost C++ Libraries BoostBook Documentation Subset">HTML</a></li></ul></div> <p></p> <div class="itemizedlist"><ul class="itemizedlist" style="list-style-type: disc; "><li class="listitem"><a href="http://sourceforge.net/projects/boost/files/boost-docs/" target="_top">PDF</a></li></ul></div> <p></p> </div> <div class="copyright-footer"></div> <hr> <div class="spirit-nav"> <a accesskey="p" href="index.html"><img src="../../doc/src/images/prev.png" alt="Prev"></a><a accesskey="u" href="index.html"><img src="../../doc/src/images/up.png" alt="Up"></a><a accesskey="h" href="index.html"><img src="../../doc/src/images/home.png" alt="Home"></a><a accesskey="n" href="libraries.html"><img src="../../doc/src/images/next.png" alt="Next"></a> </div> </body> </html>比如上述的
about.html文件<>内的就是标签,一般标签都是成对出现的。现在我们创建一个存储去标签文件的文件夹
raw_htmlxp2@Xpccccc:~/Items/Boost_Search_Engine/data$ mkdir raw_html xp2@Xpccccc:~/Items/Boost_Search_Engine/data$ ll total 24 drwxrwxr-x 4 xp2 xp2 4096 Oct 16 14:02 ./ drwxrwxr-x 3 xp2 xp2 4096 Oct 16 13:53 ../ drwxrwxr-x 56 xp2 xp2 12288 Oct 16 13:59 input/ # 原始html文档 drwxrwxr-x 2 xp2 xp2 4096 Oct 16 14:02 raw_html/ # 去标签文档 xp2@Xpccccc:~/Items/Boost_Search_Engine/data$目前总共有的html文件个数:8546
xp2@Xpccccc:~/Items/Boost_Search_Engine/data/input$ ls -Rl | grep -E '*.html' | wc -l 8546 xp2@Xpccccc:~/Items/Boost_Search_Engine/data/input$目标:把每个文档都去标签,然后写入同一个文件中,每个文档不需要\n,文档和文档之间用\3来分隔。
类似:XXXXXXXXXXXXX\3YYYYYYYYYYYYYY\3ZZZZZZZZZZZZZZ\3
采用下面方案:
类似:title\3content\3url\ntitle\3content\3url\ntitle\3content\3url\n,这个getline就可以每读一行就是一个文档的数据
安装boost库:
sudo apt update sudo apt install libboost-all-dev去标签:
- 获取文档标题:
static bool ParseTitle(const std::string &result, std::string *title) {std::size_t begin = result.find("<title>");if (begin == std::string::npos){return false;}std::size_t end = result.find("</title>");if (end == std::string::npos){return false;}if (begin > end)return false;begin += std::string("<title>").size();*title = result.substr(begin, end - begin);return true; }
- 获取文档内容:
static bool ParseContent(const std::string &result, std::string *content) {// 去标签,基于一个简单的状态机enum status{LABEL,CONTENT};enum status s = LABEL;for (char c : result){switch (s){case LABEL:if (c == '>')s = CONTENT;break;case CONTENT:if (c == '<')s = LABEL;else{// 我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符(*content) += c;}break;default:break;}}return true; }
- 构建url
官网指定url样例:https://www.boost.org/doc/libs/1_86_0/doc/html/accumulators.html 下载好的原文件路径:boost_1_86_0/doc/html/accumulators.html 提取html后的路径:data/input/accumulators.html 因此我们需要构建的url为,前缀:https://www.boost.org/doc/libs/1_86_0/doc/html 后缀:data/input/accumulators.html去掉data/input/即accumulators.htmlstatic bool ParseUrl(const std::string &file_path, std::string *url) {std::string url_head = "https://www.boost.org/doc/libs/1_86_0/doc/html/";std::string url_tail = file_path.substr(search_file.size()); // 文件路径去掉 data/input/ 前缀,就剩下 X.html*url = url_head + url_tail;return true; }把去完标签的所有html文件的内容放到一个文件中:
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output) { #define SEP '\3'// 二进制形式代开文件std::ofstream out(output, std::ios::out | std::ios::binary);if (!out.is_open()){std::cerr << "open " << output << " error !" << std::endl;return false;}// title\3content\3url\ntitle\3content\3url\ntitle\3content\3url\nfor (auto &item : results){std::string out_result = item.title;out_result += SEP;out_result += item.content;out_result += SEP;out_result += item.url;out_result += '\n';out.write(out_result.c_str(), out_result.size());}return true; }
parser.cc文件整体代码:#include <iostream> #include <string> #include <vector> #include <boost/filesystem.hpp> #include "utils.hpp"typedef struct DocInfo {std::string title; // 文档标题std::string content; // 文档内容std::string url; // 文档在官网的url } DocInfo_t;const std::string search_file = "data/input/"; const std::string output = "data/raw_html/raw.txt";// const &: 输入 // *: 输出 // &: 输入输出bool EnumFile(const std::string &search_file, std::vector<std::string> *files_list); bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results); bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);int main() {std::vector<std::string> files_list;// 第一步:递归式的把每个html文件名带路径,保存到files_list中,方便后期进行一个一个的文件读取if (!EnumFile(search_file, &files_list)){std::cerr << "enum file name error!" << std::endl;return 1;}std::vector<DocInfo_t> results;// 第二步:按照files_list读取每个文件的内容,并进行解析if (!ParseHtml(files_list, &results)){std::cerr << "parse html error!" << std::endl;return 2;}// 第三步:把解析好的文件,写入到output,按照\3作为每个文件的分隔符if (!SaveHtml(results, output)){std::cerr << "save html error!" << std::endl;return 3;}return 0; }bool EnumFile(const std::string &search_file, std::vector<std::string> *files_list) {namespace fs = boost::filesystem;fs::path root_path(search_file);// 判断路径是否存在,不存在就直接退出if (!fs::exists(root_path)){std::cerr << search_file << " not exists!" << std::endl;return false;}// 定义一个空的迭代器,用来进行判断递归结束fs::recursive_directory_iterator end;for (fs::recursive_directory_iterator iter(root_path); iter != end; ++iter){// 判断文件是否是普通文件,html都是普通文件if (!fs::is_regular_file(*iter)){continue;}// 判断普通文件是不是html后缀if (iter->path().extension() != ".html"){continue;}// debug// std::cout << "debug : " << iter->path().string() << std::endl;// 当前路径合法// 将所有带路径的html文件放到files_list容器files_list->push_back(iter->path().string());}return true; }static bool ParseTitle(const std::string &result, std::string *title) {std::size_t begin = result.find("<title>");if (begin == std::string::npos){return false;}std::size_t end = result.find("</title>");if (end == std::string::npos){return false;}if (begin > end)return false;begin += std::string("<title>").size();*title = result.substr(begin, end - begin);return true; }static bool ParseContent(const std::string &result, std::string *content) {// 去标签,基于一个简单的状态机enum status{LABEL,CONTENT};enum status s = LABEL;for (char c : result){switch (s){case LABEL:if (c == '>')s = CONTENT;break;case CONTENT:if (c == '<')s = LABEL;else{// 我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符if (c == '\n')c = ' ';(*content) += c;}break;default:break;}}return true; }static bool ParseUrl(const std::string &file_path, std::string *url) {std::string url_head = "https://www.boost.org/doc/libs/1_86_0/doc/html/";std::string url_tail = file_path.substr(search_file.size()); // 文件路径去掉 data/input/ 前缀,就剩下 X.html*url = url_head + url_tail;return true; }void ShowDoc(const DocInfo_t &doc) {std::cout << "Title: " << doc.title << std::endl;std::cout << "Content: " << doc.content << std::endl;std::cout << "Url: " << doc.url << std::endl; }bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results) {for (auto &file : files_list){// 1.读指定文件std::string result;if (!ns_utils::FileUtil::ReadFile(file, &result)){continue;}// 2.获取指定文件titleDocInfo_t doc;if (!ParseTitle(result, &doc.title)){continue;}// 3.获取指定文件contentif (!ParseContent(result, &doc.content)){continue;}// 4.构建指定文件urlif (!ParseUrl(file, &doc.url)){continue;}// 解析完成,放到results里results->push_back(std::move(doc)); // 有拷贝可以优化// 测试功能// ShowDoc(doc);// break;}return true; }bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output) { #define SEP "\3"// 二进制形式代开文件std::ofstream out(output, std::ios::out | std::ios::binary);if (!out.is_open()){std::cerr << "open " << output << " error !" << std::endl;return false;}// title\3content\3url\ntitle\3content\3url\ntitle\3content\3url\nfor (auto &item : results){std::string out_result = item.title;out_result += SEP;out_result += item.content;out_result += SEP;out_result += item.url;out_result += '\n';out.write(out_result.c_str(), out_result.size());}return true; }
6、编写建立索引的模块 Index
6.1、建立正排索引
主要代码:
DocInfo *BulidForwardIndex(const std::string &line){// 1.解析line,进行切分字符串std::vector<std::string> results;const std::string sep = "\3"; // 行内分隔符ns_util::StringUtil::CutString(line, &results, sep);if (results.size() != 3)return nullptr;// 2.填充DocInfo并插入到正排索引列表DocInfo doc;doc.title = results[0];doc.content = results[1];doc.url = results[2];doc.doc_id = _forward_index.size();_forward_index.push_back(std::move(doc));return &_forward_index.back(); // 当前最后一个元素的地址}
6.2、建立倒排索引
原理:
// 根据正排索引得到DocInfo对象 struct DocInfo { std::string title; // 文档标题 std::string content; // 文档内容 std::string url; // 官方对应的网址 std::uint64_t doc_id; // 文档id };// 对该文档对象里面的关键字进行统计,一个关键字(可能不同文档)可能对应很多个不同文档,因此需要有一个关键字对应文档id,权重等的unordered_map来存储对应关系std::unordered_map<std::string, InvertedList> _inverted_index; // 倒排索引struct InvertElem { std::uint64_t doc_id; // 文档id std::string word; // 关键字 int weight; // 权重 };// 倒排拉链 typedef std::vector<InvertElem> InvertedList;// 一个关键字对应一个拉链// 比如下面 // 文档 // title:吃葡萄 // content:吃葡萄不吐葡萄皮 // url:https://XXX // doc_id:123// 根据文档内容,形成一个或多个倒排拉链InvertedList // 当前我们是同一个文档,索引doc_id是一样的// 1.需要对title和content进行分词 // title:吃/葡萄(title_word) // content:吃/葡萄/不吐/葡萄皮(content_word)// 词和文档的相关性(假设title相关性高点,内容低一点) // 2.词频统计 struct word_cnt{int title_cnt;int content_cnt; };std::unordered_map<std::string,word_cnt> word_weight; for(auto & word : title_word){ word_weight[word].title_cnt++;// 吃(1)/葡萄(1)/吃葡萄(1) } for(auto & word : content_word){ word_weight[word].cnt_cnt++;// 吃(1)/葡萄(1)/吃葡萄(1)/不吐(1)/葡萄皮(1) }// 知道了在文档中,辩题和内容每个词出现的次数 // 3.自定义相关性 // 当前一个文档的 for(auto & word : word_weight){ // 具体一个词和文档123的对应关系,当有多个不同的词,指向同一个文档的时候,优先显示谁?相关性 // 一个词对应不同文档,优先显示谁?相关性 struct InvertElem elem; elem.doc_id = 123; elem.word = word.first ; elem.weight = 10 * word.second.title_cnt + word.second.content_cnt ;//相关性,这里用10:1的标题和内容关系 _inverted_index[word.first].push_back(move(elem));// 一个关键字对应的拉链(可能对应多个文档) }分词我们使用jieba分词:
下载链接:https://github.com/yanyiwu/cppjieba/issues
这里我们要主要用的是里面的include下的cppjieba文件夹。
这里我们先测试jieba分词效果:
使用里面的demo.cpp文件:
#include "cppjieba/Jieba.hpp"using namespace std;const char* const DICT_PATH = "../dict/jieba.dict.utf8"; const char* const HMM_PATH = "../dict/hmm_model.utf8"; const char* const USER_DICT_PATH = "../dict/user.dict.utf8"; const char* const IDF_PATH = "../dict/idf.utf8"; const char* const STOP_WORD_PATH = "../dict/stop_words.utf8";int main(int argc, char** argv) { cppjieba::Jieba jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH); vector<string> words; vector<cppjieba::Word> jiebawords; string s; string result;s = "他来到了网易杭研大厦"; cout << s << endl; cout << "[demo] Cut With HMM" << endl; jieba.Cut(s, words, true); cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] Cut Without HMM " << endl; jieba.Cut(s, words, false); cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "我来到北京清华大学"; cout << s << endl; cout << "[demo] CutAll" << endl; jieba.CutAll(s, words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造"; cout << s << endl; cout << "[demo] CutForSearch" << endl; jieba.CutForSearch(s, words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] Insert User Word" << endl; jieba.Cut("男默女泪", words); cout << limonp::Join(words.begin(), words.end(), "/") << endl; jieba.InsertUserWord("男默女泪"); jieba.Cut("男默女泪", words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] CutForSearch Word With Offset" << endl; jieba.CutForSearch(s, jiebawords, true); cout << jiebawords << endl;cout << "[demo] Lookup Tag for Single Token" << endl; const int DemoTokenMaxLen = 32; char DemoTokens[][DemoTokenMaxLen] = {"拖拉机", "CEO", "123", "。"}; vector<pair<string, string> > LookupTagres(sizeof(DemoTokens) / DemoTokenMaxLen); vector<pair<string, string> >::iterator it; for (it = LookupTagres.begin(); it != LookupTagres.end(); it++) {it->first = DemoTokens[it - LookupTagres.begin()];it->second = jieba.LookupTag(it->first); } cout << LookupTagres << endl;cout << "[demo] Tagging" << endl; vector<pair<string, string> > tagres; s = "我是拖拉机学院手扶拖拉机专业的。不用多久,我就会升职加薪,当上CEO,走上人生巅峰。"; jieba.Tag(s, tagres); cout << s << endl; cout << tagres << endl;cout << "[demo] Keyword Extraction" << endl; const size_t topk = 5; vector<cppjieba::KeywordExtractor::Word> keywordres; jieba.extractor.Extract(s, keywordres, topk); cout << s << endl; cout << keywordres << endl; return EXIT_SUCCESS; }我们把需要测试的文件全部放到test文件夹:
目前目录结构如下:
这里我们需要对源文件demo.cpp修改一下,不然找不到文件(需要对cppjieba/include和cppjieba/dict进行软链接)。
xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ ln -s cppjieba/include/ inc xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ ln -s cppjieba/dict/ dict xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ ls cppjieba demo.cpp dict inc xp2@Xpccccc:~/Items/Boost_Search_Engine/test$#include "./inc/cppjieba/Jieba.hpp"using namespace std;const char* const DICT_PATH = "./dict/jieba.dict.utf8"; const char* const HMM_PATH = "./dict/hmm_model.utf8"; const char* const USER_DICT_PATH = "./dict/user.dict.utf8"; const char* const IDF_PATH = "./dict/idf.utf8"; const char* const STOP_WORD_PATH = "./dict/stop_words.utf8";int main(int argc, char** argv) { cppjieba::Jieba jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH); vector<string> words; vector<cppjieba::Word> jiebawords; string s; string result;s = "他来到了网易杭研大厦"; cout << s << endl; cout << "[demo] Cut With HMM" << endl; jieba.Cut(s, words, true); cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] Cut Without HMM " << endl; jieba.Cut(s, words, false); cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "我来到北京清华大学"; cout << s << endl; cout << "[demo] CutAll" << endl; jieba.CutAll(s, words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;s = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造"; cout << s << endl; cout << "[demo] CutForSearch" << endl; jieba.CutForSearch(s, words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] Insert User Word" << endl; jieba.Cut("男默女泪", words); cout << limonp::Join(words.begin(), words.end(), "/") << endl; jieba.InsertUserWord("男默女泪"); jieba.Cut("男默女泪", words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;cout << "[demo] CutForSearch Word With Offset" << endl; jieba.CutForSearch(s, jiebawords, true); cout << jiebawords << endl;cout << "[demo] Lookup Tag for Single Token" << endl; const int DemoTokenMaxLen = 32; char DemoTokens[][DemoTokenMaxLen] = {"拖拉机", "CEO", "123", "。"}; vector<pair<string, string> > LookupTagres(sizeof(DemoTokens) / DemoTokenMaxLen); vector<pair<string, string> >::iterator it; for (it = LookupTagres.begin(); it != LookupTagres.end(); it++) {it->first = DemoTokens[it - LookupTagres.begin()];it->second = jieba.LookupTag(it->first); } cout << LookupTagres << endl;cout << "[demo] Tagging" << endl; vector<pair<string, string> > tagres; s = "我是拖拉机学院手扶拖拉机专业的。不用多久,我就会升职加薪,当上CEO,走上人生巅峰。"; jieba.Tag(s, tagres); cout << s << endl; cout << tagres << endl;cout << "[demo] Keyword Extraction" << endl; const size_t topk = 5; vector<cppjieba::KeywordExtractor::Word> keywordres; jieba.extractor.Extract(s, keywordres, topk); cout << s << endl; cout << keywordres << endl; return EXIT_SUCCESS; }这里我们还不能够编译,直接编译会出错:
xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ g++ demo.cpp -std=c++11 In file included from ./inc/cppjieba/Jieba.hpp:4,from demo.cpp:1: ./inc/cppjieba/QuerySegment.hpp:7:10: fatal error: limonp/Logging.hpp: No such file or directory 7 | #include "limonp/Logging.hpp" | ^~~~~~~~~~~~~~~~~~~~ compilation terminated. xp2@Xpccccc:~/Items/Boost_Search_Engine/test$因此需要把
cppjieba/deps/limonp文件放到cppjieba/include/cppjieba路径下
然后直接编译就可以了:
xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ g++ demo.cpp -std=c++11 xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ ./ a.out cppjieba-5.1.1/ dict/ inc/ xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ ./a.out 他来到了网易杭研大厦 [demo] Cut With HMM 他/来到/了/网易/杭研/大厦 [demo] Cut Without HMM 他/来到/了/网易/杭/研/大厦 我来到北京清华大学 [demo] CutAll 我/来到/北京/清华/清华大学/华大/大学 小明硕士毕业于中国科学院计算所,后在日本京都大学深造 [demo] CutForSearch 小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造 [demo] Insert User Word 男默/女泪 男默女泪 [demo] CutForSearch Word With Offset [{"word": "小明", "offset": 0}, {"word": "硕士", "offset": 6}, {"word": "毕业", "offset": 12}, {"word": "于", "offset": 18}, {"word": "中国", "offset": 21}, {"word": "科学", "offset": 27}, {"word": "学院", "offset": 30}, {"word": "科学院", "offset": 27}, {"word": "中国科学院", "offset": 21}, {"word": "计算", "offset": 36}, {"word": "计算所", "offset": 36}, {"word": ",", "offset": 45}, {"word": "后", "offset": 48}, {"word": "在", "offset": 51}, {"word": "日本", "offset": 54}, {"word": "京都", "offset": 60}, {"word": "大学", "offset": 66}, {"word": "日本京都大学", "offset": 54}, {"word": "深造", "offset": 72}] [demo] Lookup Tag for Single Token [拖拉机:n, CEO:eng, 123:m, 。:x] [demo] Tagging 我是拖拉机学院手扶拖拉机专业的。不用多久,我就会升职加薪,当上CEO,走上人生巅峰。 [我:r, 是:v, 拖拉机:n, 学院:n, 手扶拖拉机:n, 专业:n, 的:uj, 。:x, 不用:v, 多久:m, ,:x, 我:r, 就:d, 会:v, 升职:v, 加薪:nr, ,:x, 当上:t, CEO:eng, ,:x, 走上:v, 人生:n, 巅峰:n, 。:x] [demo] Keyword Extraction 我是拖拉机学院手扶拖拉机专业的。不用多久,我就会升职加薪,当上CEO,走上人生巅峰。 [{"word": "CEO", "offset": [93], "weight": 11.7392}, {"word": "升职", "offset": [72], "weight": 10.8562}, {"word": "加薪", "offset": [78], "weight": 10.6426}, {"word": "手扶拖拉机", "offset": [21], "weight": 10.0089}, {"word": "巅峰", "offset": [111], "weight": 9.49396}] xp2@Xpccccc:~/Items/Boost_Search_Engine/test$这里我们只需要CutForSearch的测试:
#include "./inc/cppjieba/Jieba.hpp"using namespace std;const char* const DICT_PATH = "./dict/jieba.dict.utf8"; const char* const HMM_PATH = "./dict/hmm_model.utf8"; const char* const USER_DICT_PATH = "./dict/user.dict.utf8"; const char* const IDF_PATH = "./dict/idf.utf8"; const char* const STOP_WORD_PATH = "./dict/stop_words.utf8";int main(int argc, char** argv) { cppjieba::Jieba jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH); vector<string> words; vector<cppjieba::Word> jiebawords; string s; string result;s = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造"; cout << s << endl; cout << "[demo] CutForSearch" << endl; jieba.CutForSearch(s, words); cout << limonp::Join(words.begin(), words.end(), "/") << endl;return EXIT_SUCCESS; }xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ g++ demo.cpp -std=c++11 xp2@Xpccccc:~/Items/Boost_Search_Engine/test$ ./a.out 小明硕士毕业于中国科学院计算所,后在日本京都大学深造 [demo] CutForSearch 小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造 xp2@Xpccccc:~/Items/Boost_Search_Engine/test$发现确实可以自动分割关键词!
建立倒排索引的代码:
// 注意:这里是某一个文档的的 bool BuildInvertedIndex(const DocInfo &doc) { // DocInfo【title,content,url,doc_id】 // 分词 // 词频统计 struct word_cnt {int title_cnt;int content_cnt;word_cnt() : title_cnt(0), content_cnt(0) {} };// 关键字的词频映射 std::unordered_map<std::string, word_cnt> word_weight;// 标题的分词 std::vector<std::string> title_words; ns_util::JiebaUtil::CutStringForSearch(doc.title, &title_words); // 标题分词 for (auto s : title_words) // 这里不要引用,防止修改了原字符串 {boost::to_lower(s); // 全部转成小写,不区分大小写word_weight[s].title_cnt++; // 插入到映射表 }// 内容分词 std::vector<std::string> content_words; ns_util::JiebaUtil::CutStringForSearch(doc.content, &content_words); for (auto s : content_words) // 这里不要引用,防止修改了原字符串 {boost::to_lower(s);word_weight[s].content_cnt++; }// 已经建立完映射表 // 现在建立倒排拉链 #define X 10 #define Y 1 for (auto &word_pair : word_weight) {InvertElem elem;elem.doc_id = doc.doc_id; // 当前文档的idelem.word = word_pair.first;elem.weight = X * word_pair.second.title_cnt + Y * word_pair.second.content_cnt; // 相关性InvertedList &inverted_list = _inverted_index[word_pair.first]; // 找到倒排拉链,再在这个倒排拉链插入元素inverted_list.emplace_back(std::move(elem)); } return true; }整体Index代码:这里使用了单例模式,也就是建立索引一次就够了。
#pragma once#include <iostream> #include <vector> #include <string> #include <fstream> #include <unordered_map> #include <mutex> #include "util.hpp"namespace ns_index {struct DocInfo{std::string title; // 文档标题std::string content; // 文档内容std::string url; // 官方对应的网址std::uint64_t doc_id; // 文档id};struct InvertElem{std::uint64_t doc_id; // 文档idstd::string word; // 关键字int weight; // 权重};// 倒排拉链typedef std::vector<InvertElem> InvertedList;class Index{private:Index() {}Index(const Index &) = delete;Index &operator=(const Index &) = delete;~Index() {}private:static std::mutex mtx;static Index *instance;public:// 单例模式static Index *GetInstance(){if (instance == nullptr){mtx.lock();if (instance == nullptr){instance = new Index();}mtx.unlock();}return instance;}public:// 根据去标签的文件/data/raw_html/raw.txt,建立正排索引和倒排索引// 根据doc_id找到文档内容bool BulidIndex(const std::string &path){std::ifstream in(path, std::ios::in | std::ios::binary);if (!in.is_open()){std::cerr << "open " << path << " file error" << std::endl;return false;}std::string line;while (std::getline(in, line)){// 构建正排索引DocInfo *doc = BulidForwardIndex(line);if (doc == nullptr){continue;}// 构建倒排排索引if (!BuildInvertedIndex(*doc)){continue;}}in.close();return true;}DocInfo *GetForwardIndex(uint64_t doc_id){if (doc_id > _forward_index.size()){std::cerr << "doc_id out of range!" << std::endl;return nullptr;}return &_forward_index[doc_id];}// 根据关键字找到文档id,即获得倒排拉链InvertedList *GetInvertedIndex(const std::string &word){auto iter = _inverted_index.find(word);if (iter == _inverted_index.end()){std::cerr << word << " not find" << std::endl;return nullptr;}return &iter->second;}private:DocInfo *BulidForwardIndex(const std::string &line){// 1.解析line,进行切分字符串std::vector<std::string> results;const std::string sep = "\3"; // 行内分隔符ns_util::StringUtil::CutString(line, &results, sep);if (results.size() != 3)return nullptr;// 2.填充DocInfo并插入到正排索引列表DocInfo doc;doc.title = results[0];doc.content = results[1];doc.url = results[2];doc.doc_id = _forward_index.size();_forward_index.push_back(std::move(doc));return &_forward_index.back(); // 当前最后一个元素的地址}// 注意:这里是某一个文档的的bool BuildInvertedIndex(const DocInfo &doc){// DocInfo【title,content,url,doc_id】// 分词// 词频统计struct word_cnt{int title_cnt;int content_cnt;word_cnt() : title_cnt(0), content_cnt(0) {}};// 关键字的词频映射std::unordered_map<std::string, word_cnt> word_weight;// 标题的分词std::vector<std::string> title_words;ns_util::JiebaUtil::CutStringForSearch(doc.title, &title_words); // 标题分词for (auto s : title_words) // 这里不要引用,防止修改了原字符串{boost::to_lower(s); // 全部转成小写,不区分大小写word_weight[s].title_cnt++; // 插入到映射表}// 内容分词std::vector<std::string> content_words;ns_util::JiebaUtil::CutStringForSearch(doc.content, &content_words);for (auto s : content_words) // 这里不要引用,防止修改了原字符串{boost::to_lower(s);word_weight[s].content_cnt++;}// 已经建立完映射表// 现在建立倒排拉链 #define X 10 #define Y 1for (auto &word_pair : word_weight){InvertElem elem;elem.doc_id = doc.doc_id; // 当前文档的idelem.word = word_pair.first;elem.weight = X * word_pair.second.title_cnt + Y * word_pair.second.content_cnt; // 相关性InvertedList &inverted_list = _inverted_index[word_pair.first]; // 找到倒排拉链,再在这个倒排拉链插入元素inverted_list.emplace_back(std::move(elem));}return true;}private:std::vector<DocInfo> _forward_index; // 正排索引std::unordered_map<std::string, InvertedList> _inverted_index; // 倒排索引};Index *Index::instance = nullptr;std::mutex Index::mtx; }

7、搜索引擎模块 searcher
基本代码结构:
#pragma once#include "index.hpp"namespace ns_searcher { class Searcher { public:Searcher() {}~Searcher() {}public:// 初始化void InitSearch(const std::string &input){// 1.获取Index对象_index = ns_index::Index::GetInstance();// 2.根据Index对象建立索引_index->BulidIndex(input);}// query:关键字查询// out:返回的json串bool Search(const std::string &query, std::string *out){// 1.分词:对query进行分词// 2.触发:根据分词后的各个词,进行index查找// 3.合并排序:汇总查找结果,按照相关性(weight)进行降序排序// 4.构建:根据查找出来的结果,构建json串 -- jsoncpp}private:ns_index::Index *_index; // 供系统进行查找的索引 }; }这里用到
jsoncpp,我们需要下载安装:sudo apt update sudo apt install libjsoncpp-dev获取摘要代码:取关键字的前50字节和后100字节。
std::string GetDesc(const std::string &content, const std::string &word) {// 找到关键字的左边50字节,右边100字节const int prev_len = 50;const int next_len = 100;// 这里注意,content里面的内容是没有进行转小写的,而word是小写的,因此我们需要对content特殊处理来查找wordauto iter = std::search(content.begin(), content.end(), word.begin(), word.end(), [](const char c1, const char c2){ return std::tolower(c1) == std::tolower(c2); });if (iter == content.end()){return "None1";}int pos = std::distance(content.begin(), iter);int start = 0; // 如果当前关键字前面没有50字节,就用这个作为起始点int end = content.size() - 1; // 如果当前关键字后面没有100字节,就用这个作为结束点if (pos > start + prev_len)start = pos - prev_len;if (pos < end - next_len)end = pos + next_len;// 获取子串if (end <= start)return "None2";return content.substr(start, end - start); }
seacher.hpp文件完整代码:#pragma once#include <algorithm> #include <jsoncpp/json/json.h> #include "index.hpp"namespace ns_searcher {class Searcher{public:Searcher() {}~Searcher() {}public:// 初始化void InitSearch(const std::string &input){// 1.获取Index对象_index = ns_index::Index::GetInstance();std::cout << "获取index单例成功 ... " << std::endl;// 2.根据Index对象建立索引_index->BulidIndex(input);std::cout << "建立正排索引和倒排索引成功 ... " << std::endl;}// query:关键字查询// out_json:返回的json串void Search(const std::string &query, std::string *out_json){// 1.分词:对query进行分词std::vector<std::string> words;ns_util::JiebaUtil::CutStringForSearch(query, &words);// 2.触发:根据分词后的各个词,进行index查找ns_index::InvertedList inverted_list_all; // 存当前所有的关键字的拉链,拉链依次放在后面for (auto &word : words){// 查找倒排拉链boost::to_lower(word);ns_index::InvertedList *inverted_list = _index->GetInvertedIndex(word); // 存的InvertElemif (nullptr == inverted_list){continue;}// 找到了倒排拉链// 不完美!可能存在相同文档id出现两次inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end()); // 存的InvertElem}// 3.合并排序:汇总查找结果,按照相关性(weight)进行降序排序sort(inverted_list_all.begin(), inverted_list_all.end(), [](const ns_index::InvertElem &e1, const ns_index::InvertElem &e2){ return e1.weight > e2.weight; });// 4.构建:根据查找出来的结果,构建json串 -- jsoncppJson::Value root;for (auto &elem : inverted_list_all) // 已经有序{// 获取正排索引的文档idns_index::DocInfo *doc = _index->GetForwardIndex(elem.doc_id);Json::Value value;value["title"] = doc->title;value["desc"] = GetDesc(doc->content, elem.word); // GetDesc(doc->content, elem.word); // 只获取摘要value["url"] = doc->url;// for debug ,for deletevalue["doc_id"] = (int)elem.doc_id;value["weight"] = elem.weight;root.append(value);}Json::StyledWriter writer;*out_json = writer.write(root);}std::string GetDesc(const std::string &content, const std::string &word){// 找到关键字的左边50字节,右边100字节const int prev_len = 50;const int next_len = 50;// 这里注意,content里面的内容是没有进行转小写的,而word是小写的,因此我们需要对content特殊处理来查找wordauto iter = std::search(content.begin(), content.end(), word.begin(), word.end(), [](const char c1, const char c2){ return std::tolower(c1) == std::tolower(c1); });if (iter == content.end()){return "None1";}int pos = std::distance(content.begin(), iter);int start = 0; // 如果当前关键字前面没有50字节,就用这个作为起始点int end = content.size() - 1; // 如果当前关键字后面没有100字节,就用这个作为结束点if (pos > start + prev_len)start = pos - prev_len;if (pos < end - next_len)end = pos + next_len;// 获取子串if (end <= start)return "None2";return content.substr(start, end - start);}private:ns_index::Index *_index; // 供系统进行查找的索引}; }
8、网络服务 http_server 模块
我们需要把searcher模块打包成网络服务。
这里我们使用cpp-httplib库。
下载httplib.h文件:
wget https://raw.githubusercontent.com/yhirose/cpp-httplib/master/httplib.h代码:
#include "httplib.h" #include "searcher.hpp"const std::string path = "data/raw_html/raw.txt";int main() {httplib::Server svr;ns_searcher::Searcher searcher;searcher.InitSearch(path);svr.Get("/s", [&searcher](const httplib::Request &req, httplib::Response &resp){ if(!req.has_param("word")){resp.set_content("必须要有搜索关键字","text/plain;charset=utf-8");return ;}std::string word = req.get_param_value("word");// 获取提交的参数std::cout <<"用户正在搜索 "<< word << std::endl;std::string out_json;searcher.Search(word,&out_json);resp.set_content(out_json.c_str(), "application/json;charset=utf-8"); });svr.set_base_dir("./wwwroot");svr.listen("0.0.0.0", 8081);return 0; }
9、解决query中不同关键字出现在同一文档时显示多个同一文档的问题
searcher.hpp文件改为:
#pragma once#include <algorithm> #include <jsoncpp/json/json.h> #include "index.hpp"namespace ns_searcher {struct InvertedElemPrint{uint64_t doc_id;int weight; // 属于同一文档的weightstd::vector<std::string> words; // 属于同一文档的关键字InvertedElemPrint() : doc_id(0), weight(0) {}};class Searcher{public:Searcher() {}~Searcher() {}public:// 初始化void InitSearch(const std::string &input){// 1.获取Index对象_index = ns_index::Index::GetInstance();std::cout << "获取index单例成功 ... " << std::endl;// 2.根据Index对象建立索引_index->BulidIndex(input);std::cout << "建立正排索引和倒排索引成功 ... " << std::endl;}// query:关键字查询// out_json:返回的json串void Search(const std::string &query, std::string *out_json){// 1.分词:对query进行分词std::vector<std::string> words;ns_util::JiebaUtil::CutStringForSearch(query, &words);// 空格得去掉// std::cout << "debug" << std::endl;// for (auto &e : words)// {// std::cout << e << std::endl;// }// 2.触发:根据分词后的各个词,进行index查找// ns_index::InvertedList inverted_list_all; // 存当前所有的关键字的拉链,拉链依次放在后面std::vector<InvertedElemPrint> inverted_list_all; // 存文档id去重之后要保存的节点std::unordered_map<uint64_t, InvertedElemPrint> inverted_print; // 一个文档对应的关键字和权重for (auto &word : words){// 查找倒排拉链boost::to_lower(word);ns_index::InvertedList *inverted_list = _index->GetInvertedIndex(word); // 存的InvertElemif (nullptr == inverted_list){continue;}// 找到了倒排拉链// 不完美!可能存在关键字在同一文档出现,导致显示多个html// inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end()); // 存的InvertElemfor (auto &elem : *inverted_list){// 把关键字对应的文档放到inverted_printInvertedElemPrint &item = inverted_print[elem.doc_id];// 这里之后,item一定是doc_id相同的节点item.doc_id = elem.doc_id;item.weight += elem.weight; // 同一个doc_id的关键字就权值相加item.words.push_back(elem.word);}}// 把inverted_print的InvertedElemPrint放到inverted_list_all里面for (auto &item : inverted_print){inverted_list_all.push_back(std::move(item.second));}// 3.合并排序:汇总查找结果,按照相关性(weight)进行降序排序// sort(inverted_list_all.begin(), inverted_list_all.end(), [](const ns_index::InvertElem &e1, const ns_index::InvertElem &e2)// { return e1.weight > e2.weight; });sort(inverted_list_all.begin(), inverted_list_all.end(), [](const InvertedElemPrint &e1, const InvertedElemPrint &e2){ return e1.weight > e2.weight; });// 4.构建:根据查找出来的结果,构建json串 -- jsoncppJson::Value root;for (auto &elem : inverted_list_all) // 已经有序{// 获取正排索引的文档idns_index::DocInfo *doc = _index->GetForwardIndex(elem.doc_id);Json::Value value;value["title"] = doc->title;value["desc"] = GetDesc(doc->content, elem.words[0]); // GetDesc(doc->content, elem.word); // 只获取摘要value["url"] = doc->url;// for debug ,for deletevalue["doc_id"] = (int)elem.doc_id;value["weight"] = elem.weight;root.append(value);}Json::StyledWriter writer;*out_json = writer.write(root);}std::string GetDesc(const std::string &content, const std::string &word){// 找到关键字的左边50字节,右边100字节const int prev_len = 50;const int next_len = 100;// 这里注意,content里面的内容是没有进行转小写的,而word是小写的,因此我们需要对content特殊处理来查找wordauto iter = std::search(content.begin(), content.end(), word.begin(), word.end(), [](const char c1, const char c2){ return std::tolower(c1) == std::tolower(c2); });if (iter == content.end()){return "None1";}int pos = std::distance(content.begin(), iter);int start = 0; // 如果当前关键字前面没有50字节,就用这个作为起始点int end = content.size() - 1; // 如果当前关键字后面没有100字节,就用这个作为结束点if (pos > start + prev_len)start = pos - prev_len;if (pos < end - next_len)end = pos + next_len;// 获取子串if (end <= start)return "None2";std::string ret = content.substr(start, end - start) + " ... ";return ret;}private:ns_index::Index *_index; // 供系统进行查找的索引}; }
10、去掉暂停词
去掉关关键字中的:the is 等等。
#pragma once#include <iostream> #include <fstream> #include <string> #include <vector> #include <boost/algorithm/string.hpp> #include "cppjieba/Jieba.hpp"namespace ns_util { class FileUtil { public:static bool ReadFile(const std::string &path, std::string *out){std::ifstream in(path);if (!in.is_open()){std::cout << "open " << path << " file error" << std::endl;return false;}std::string line;while (std::getline(in, line)){(*out) += line;}in.close();return true;} };class StringUtil { public:static bool CutString(const std::string &line, std::vector<std::string> *out, const std::string &sep){// 使用boost切分splitboost::split(*out, line, boost::is_any_of(sep), boost::algorithm::token_compress_on);return true;} };const char *const DICT_PATH = "./dict/jieba.dict.utf8"; const char *const HMM_PATH = "./dict/hmm_model.utf8"; const char *const USER_DICT_PATH = "./dict/user.dict.utf8"; const char *const IDF_PATH = "./dict/idf.utf8"; const char *const STOP_WORD_PATH = "./dict/stop_words.utf8"; class JiebaUtil { private:// static cppjieba::Jieba jieba;cppjieba::Jieba jieba;std::unordered_map<std::string, bool> stop_words;JiebaUtil() : jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH) {}JiebaUtil(const JiebaUtil &) = delete;JiebaUtil &operator=(const JiebaUtil &) = delete;static JiebaUtil *instance;public:static JiebaUtil *get_instance(){std::mutex mtx;if (instance == nullptr){mtx.lock();if (instance == nullptr){instance = new JiebaUtil();instance->InitJiebaUtil();}mtx.unlock();}return instance;}void InitJiebaUtil(){std::ifstream in(STOP_WORD_PATH);if (!in.is_open()){std::cout << "打开文件失败" << std::endl;return;}std::string line;while (std::getline(in, line)){stop_words.insert({line, true});}in.close();}void CutStringForSearchHelper(const std::string &str, std::vector<std::string> *out){jieba.CutForSearch(str, *out);for (auto iter = out->begin(); iter != out->end();){auto it = stop_words.find(*iter); // 看有没有暂停词if (it != stop_words.end()){// 去掉暂停词iter = out->erase(iter);}else{++iter;}}}public:// static void CutStringForSearch(const std::string &str, std::vector<std::string> *out)static void CutStringForSearch(const std::string &str, std::vector<std::string> *out){// jieba.CutForSearch(str, *out);ns_util::JiebaUtil::get_instance()->CutStringForSearchHelper(str, out);} };// cppjieba::Jieba JiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH); JiebaUtil *JiebaUtil::instance = nullptr; }
11、整体代码
整体代码
OKOK,Boost搜索引擎就到这里。如果你对Linux和C++也感兴趣的话,可以看看我的主页哦。下面是我的github主页,里面记录了我的学习代码和leetcode的一些题的题解,有兴趣的可以看看。
Xpccccc的github主页


















