【GiantPandaCV导语】Neon是手机普遍支持的计算加速指令集,是AI落地的工程利器。Neon Intrinsics 的出现,缓解了汇编语言难学难写的难题,值得工程师们开发利用。
前言
Neon是ARM平台的向量化计算指令集,通过一条指令完成多个数据的运算达到加速的目的,常用于AI、多媒体等计算密集型任务。
本文主要是一篇对ARM官方资料的导读。笔者根据自己Neon学习经历,将这些资料按照逻辑进行组织,以期减少读者的学习成本。
本文讨论的是Neon 的intrinsics,而非assembly。intrinsics是以类似调用C语言函数的方法调用Neon,并由编译器生成最终的二进制代码,assembly则是手工嵌入Neon汇编,直接生成二进制代码。如果您想了解的是Neon assembly,可以参考这篇文章:https://zhuanlan.zhihu.com/p/143328317。笔者后续也会补充assembly的内容。
1 入门
1.1 Neon介绍、简明案例与编程惯例
推荐阅读ARM官方的 Optimizing C Code with Neon Intrinsics (https://developer.arm.com/documentation/102467/0100/)
该资料以HWC转CHW(permute)操作、矩阵乘法为例子,介绍如何将普通C++实现改写为Neon Intrinsics的实现。
重点:第6小节program conventions(编程惯例)介绍了Neon输出输出的对象类型和intrinsics命名规则。Intrinsics命名规则还是比较复杂的(如下图),如果没弄清楚,后期可能会检索不到需要的intrinsics或误用intrinsics。

1.2 如何检索Intrinsics
在1.1了解改写方法后,将自己的代码用相应的Intrinsics改写,即可应用Neon加速。ARM官方制作了intrinsics检索页面 (https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics)。
以float32类型的点对点乘法intrinsics vaddq_f32(q的含义请查阅上面命名规则,了解命名规则真的很重要)为例,从上到小描述操作、对应的汇编指令、入参、出参、伪代码和支持该intrinsics 的架构。
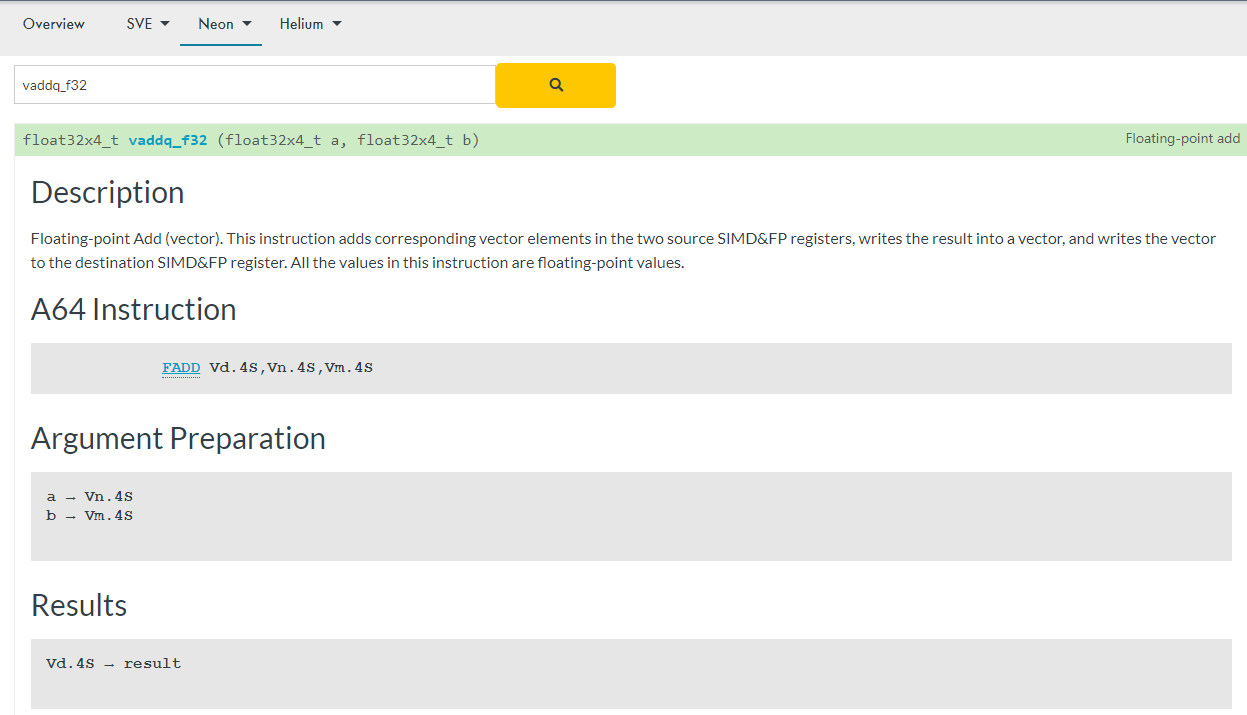

注意兼容性问题: 核查intrinsics是否能用于项目所需兼容的全部架构。例如,笔者进行的项目需要兼容新旧手机,且当前只能集成ARMv7a(新旧手机均能运行,即图中的v7)架构的so库,而Aarch64(仅新手机支持,即图中的A64)架构的so库尚不支持。如果某条intrinsics的supported architectures只有A64,那么在编译ARMv7a架构的so库时将会无法通过编译。对于这种情况,只能放弃使用这条intrinsics,改用多条intrinsics拼凑出等效实现(指令数的增加意味着性能的降低,为了兼容性这是无可奈何的事情)。
1.3 优化效果案例
为了应用Neon需要学那么多东东,究竟能达到怎样的效果?Intrinsics优化生成的汇编还和人工优化手写的汇编还有多少差距?别急,我们可以看下带有速度benchmark的案例,例如BBuf 写的 一份朴实无华的移动端盒子滤波算法优化笔记 (https://zhuanlan.zhihu.com/p/170611395)
直接把优化结果摘出来
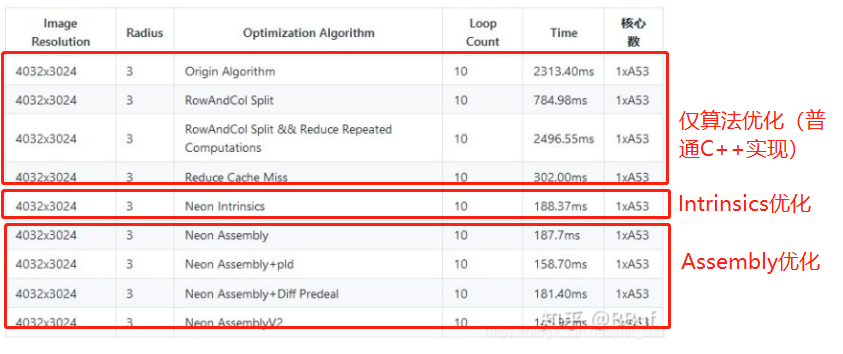
优化好算法后,普通C++实现是302.00ms(不排除编译器优化了部分运算,生成了部分Neon指令),Intrinsics实现是188.37ms,最优Assembly实现是145.92ms。Intrinsics优化和Assembly优化分别加速了约38%和约52%,Intrinsics优化生成的代码还和手工优化的Assembly存在差距。但注意到,如果仅是单纯地用Assembly改写C++,优化效果和Intrinsics一样(188.37ms VS 187.70ms),进一步的性能改进来自于额外的预取指令(pld)和对双发射流水(硬件设计)的利用。简而言之,如果项目留有足够的优化时间并且对体系结构的驾驭能力有信心(至少速度不会低于Intrinsics),选择Assembly优化,否则选择Intrinsics优化。
1.4 如何在Android应用Neon
直接参考ARM官方的Demo制作教程(还带了演示编写代码的视频):
Neon Intrinsics Getting Started on Android(https://developer.arm.com/solutions/os/android/developer-guides/neon-intrinsics-getting-started-on-android)
Neon Intrinsics on Android How to Truncate Thresholding and Convolution of A 1D Signal (https://developer.arm.com/solutions/os/android/developer-guides/neon-intrinsics-on-android-how-to-truncate-thresholding-and-convolution-of-a-1d-signal)
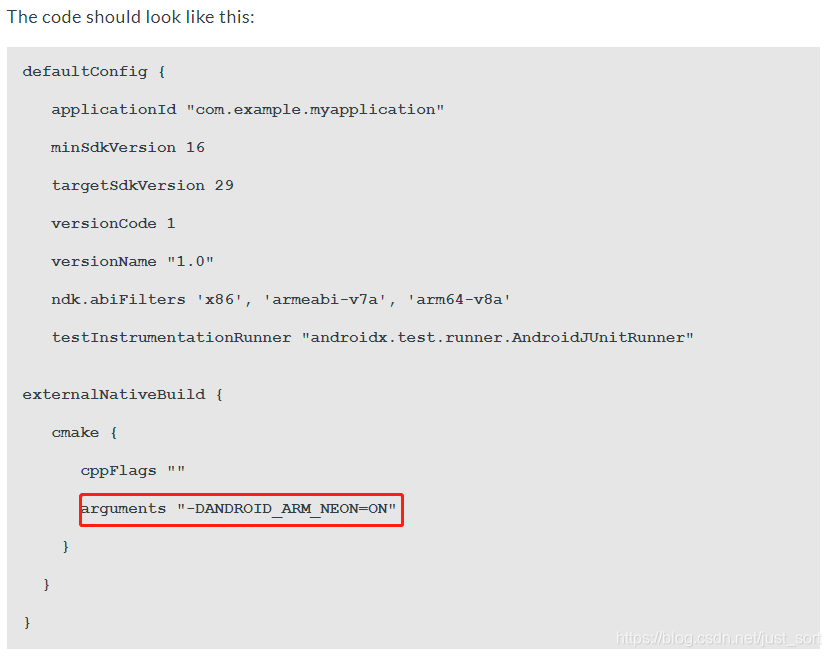
核心点就是,在Gradle加上Neon的启用命令(如下红框),然后在cpp引用头文件 #include ,写代码就完事了。余下的都是带Native代码的安卓开发的知识。
关于在iOS开发中启用Neon(Xcode,尝试的版本为12.3):笔者尝试过将Android的NDK代码迁移至iOS,在不修改Xcode任何设置的情况下,arm_neon.h可找到,编译可通过,那说明Xcode默认打开了Neon的启用开关,写就完事了。
2 进阶
2.1 与Neon相关的ARM体系结构
利用指令集加速,无一例外地要利用专用寄存器这种在CPU上稀少、宝贵的资源。专用寄存器用少了CPU的性能不能充分发挥,用多了则会产生寄存器溢出(Register Spilling)(https://blog.csdn.net/qq_41112170/article/details/90286091)这种对性能有明显负面影响的问题%E8%BF%99%E7%A7%8D%E5%AF%B9%E6%80%A7%E8%83%BD%E6%9C%89%E6%98%8E%E6%98%BE%E8%B4%9F%E9%9D%A2%E5%BD%B1%E5%93%8D%E7%9A%84%E9%97%AE%E9%A2%98)。因此,我们至少需要了解在编写Neon代码时,有多少个专用寄存器可供利用,这就涉及到体系结构的知识。推荐阅读ARM官方的 Introducing Neon for Armv8-A(https://developer.arm.com/documentation/102474/0100/)
重点:
(1)了解registers, vectors,lanes, elements的概念以及它们对专用寄存器的占用;
(2)新的Armv8a架构有32个128bit向量寄存器,老的ArmV7a架构有32个64bit(可当作16个128bit)向量寄存器,编码时记得数一下占用多少个专用寄存器(例如1个float32x4就占用1个128bit寄存器),别用过量了,避免寄存器溢出(Register Spilling)(https://blog.csdn.net/qq_41112170/article/details/90286091)导致的负优化%E5%AF%BC%E8%87%B4%E7%9A%84%E8%B4%9F%E4%BC%98%E5%8C%96)。
如果对ARM体系结构感兴趣,可以阅读更系统的 Cortex-A Series Programmer’s Guide(https://developer.arm.com/documentation/den0013/latest)。
2.2 对非整数倍元素个数(leftovers)的处理技巧
一条Neon指令最多可以计算4个float32,或者8个float16,或者16个int8。假设现在有3个或5个(即不是4的整数倍)float32需要计算,请问应该怎样解决呢?
ARM官方的Coding for Neon(https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/neon-programmers-guide-for-armv8-a/coding-for-neon/),在第4节 Load and store - leftovers给了处理技巧

除了处理leftovers,文章中还有一些操作值得学习,比如一条指令完成的shifting and inserting。
2.3 算子源码学习(ncnn库,AI方向)
ncnn(https://github.com/Tencent/ncnn/tree/e16b338b136c94805bc7d0ef3756f2dc4bfa3408/src/layer)是腾讯开源,nihui维护的AI推理引擎。2017开源至今,其代码依然保持着组织结构简单、易重用的优点。ncnn实现的算子包含普通实现(无针平台的加速)和针对3种平台(arm/vulkan/x86)的指令集加速实现(注:可能有的算子有普通实现,但没有平台加速实现,毕竟做加速实现还是比较耗费精力的,致敬nihui大大)。
由于Neon实现往往跟循环展开等技巧一起使用,代码往往比较长。我们可以先阅读普通实现的代码实现了解顶层逻辑,再阅读Neon实现的代码。例如,我们希望学习全连接层(innerproduct)的Neon实现,其普通实现的位置在ncnn/src/layer/innerproduct.cpp,对应的Neon加速实现的位置在ncnn/src/layer/arm/innerproduct_arm.cpp。
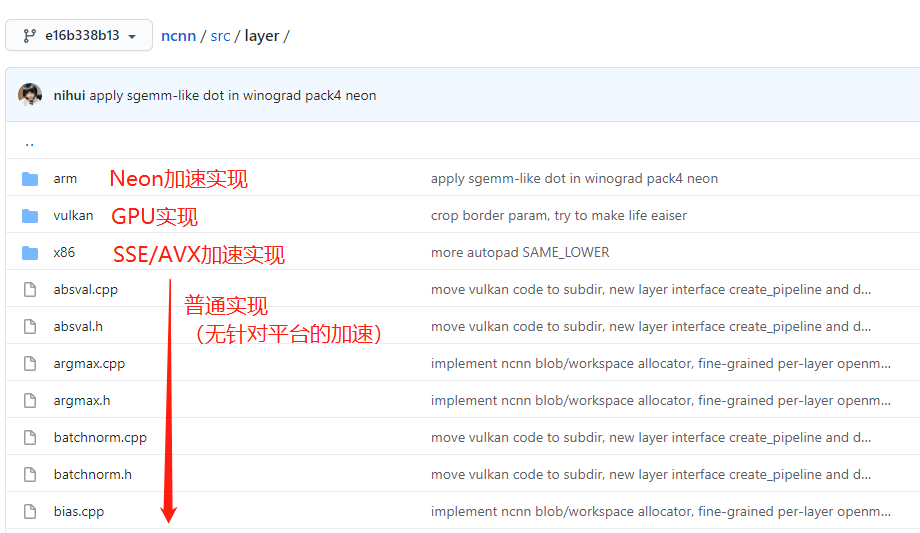
注意代码中出现较多的条件编译。原因我们上文提到过,有的intrinsics是较新Aarch64架构下专有的,为了兼容较老的ArmV7a架构,对于不能用的intrinsics只能用多条兼容的intrinsics等效替代。为了保证Aarch64下的性能同时保证对ArmV7a的兼容性,ncnn采用条件编译的方式处理不兼容的intrinsics(条件编译就是编译满足条件的分枝的代码,不满足条件的代码将不出现在最终的二进制文件中)。
如果你只关注Aarch64平台下的实现,下图#else分支的代码跳过不看即可。

2.4 算子源码学习(Nvidia carotene库,图像处理方向 )
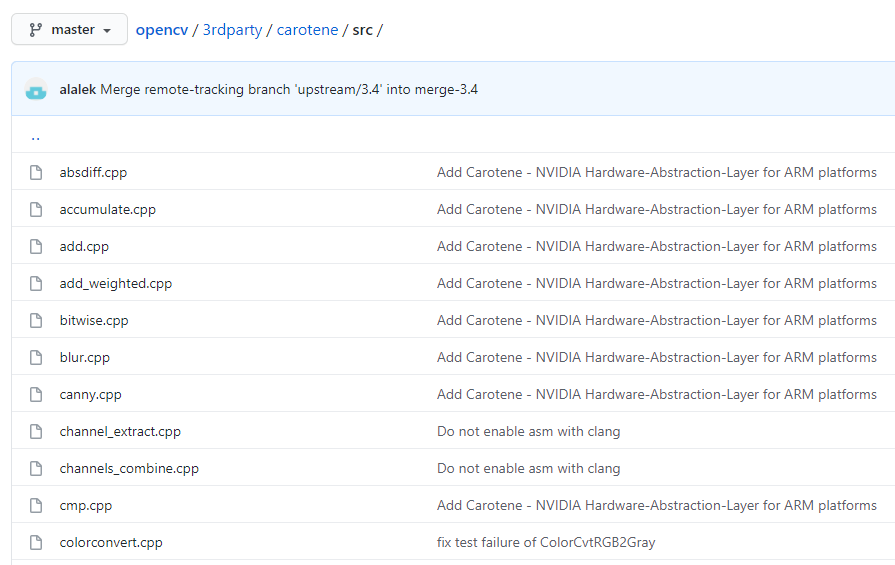
了解carotene(https://github.com/opencv/opencv/tree/master/3rdparty/carotene)库的人应该不多,但了解OpenCV的人应该不少吧?carotene能够作为OpenCV的第三方库(third party)存在,足以证明其代码质量。
carotene的组织结构同样简单,且不依赖OpenCV的数据结构,想用想学习哪个函数直接提取出来即可。如下图,里面主要用Neon实现了色彩空间转换、均值滤波、Canny边缘检测等常见的图像处理算子。
3. 学个通透
3.1 SIMD加速原理
即使到了这里,我们仍然对Neon(或类似的SIMD指令)为什么能加速我们的代码充满疑问。我们可以在这本书(计算机体系结构的圣经之一)找寻答案——《计算机体系结构:量化研究方法》。 Neon是ARM平台的SIMD(Single Instruction Multiple Data,单指令多数据流)指令集实现,书中4.1~4.3讨论了SIMD,推荐阅读。

关于这个问题,笔者的总结如下:
(1)通过加长的寄存器减少数据的读取/写入次数,从而减少将数据读入寄存器的时间开销。例如Neon可以一次性将16个int8(16 * 8=128bit)数据读入专用寄存器,这一次读取时间开销,明显少于16个int8数据一个一个地读入的时间之和。写入同理。(注意不要和cache的减少访存时间的原理混淆。从cache读取余下的第2~第16个int8数据到寄存器仍然是要花费时钟周期的)。
(2)执行SISD(single instruction, Single data,单指令流单数据流,这里可理解为标量计算)指令时,需要完成(时间开销大的)冒险(hazard)检查。既然使用SIMD指令计算,就暗示这些数据之间无依赖性,也就从指令集层面回避了不必要的时间开销。
3.2 了解硬件决定的速度极限:Software Optimization Guide
我们可能还要关心,我们所编写的Neon Intrinsics,可以将手头上硬件的性能发挥到多少水平?是否还有提升空间?这些是好问题。
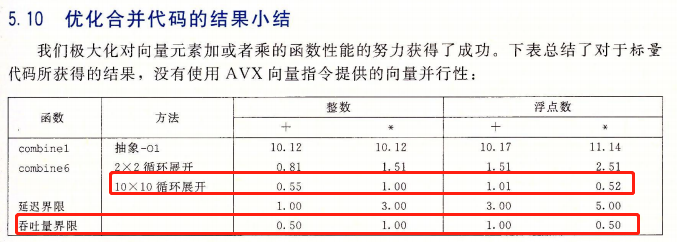
在讨论一个问题前,先插入一个使笔者拍案叫绝的相关案例:在另一本计算经典**《深入理解计算机系统》** (一般简称 CS:APP)的第5章 优化程序性能 中,该书作者考虑若干计算机硬件特性,将矩阵乘法连续优化了6个版本,直至优化到了该x86 CPU的吞吐量上限(注:对于某种指令,延迟latency 主要关注单条该指令的最小执行时间,吞吐量throughout主要关注单位时间内系统(一个CPU核)最多执行多少条该指令。因为AI计算的数据量比较大,我们更关注吞吐量)。
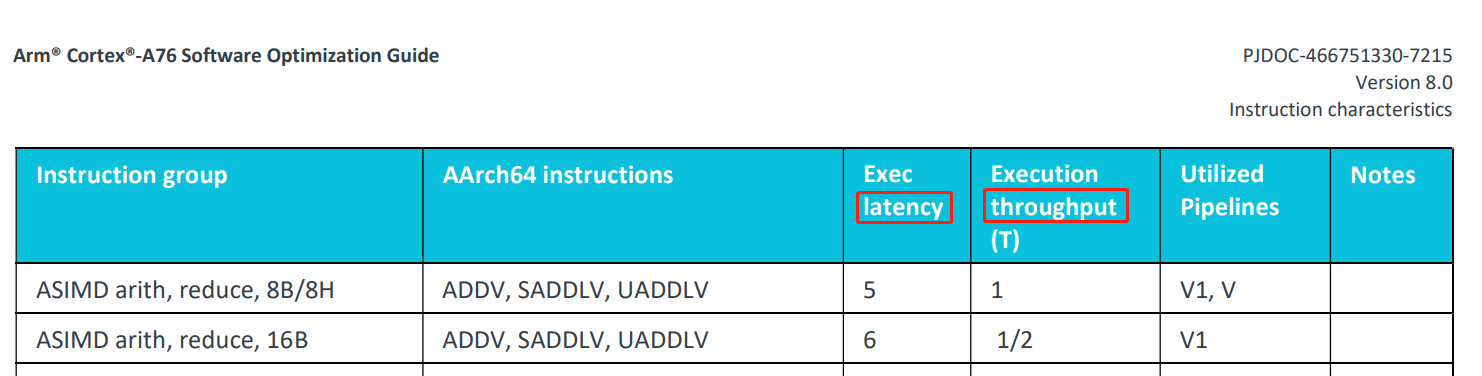
回到问题,我们需要知道我们的吞吐量上界是多少。ARM官方为每个CPU架构(手机CPU一般大核是A7X架构,小核是A5X架构)提供对应的Software Optimization Guide,里面有进行各种运算的latency和throughout。以A76架构(采用该架构作为大核架构的CPU例如骁龙855,麒麟980)为例子,从ARM官网下载对应的pdf(https://developer.arm.com/documentation/swog307215/a/?lang=en)
翻到ASIMD(Advance SIMD)那里,就能查阅各条Neon指令相应的latency和throughout。不同架构的吞吐量上界会有所不同,其他架构请自行在ARM官网文档中心下载。
理论数据有了,至于如何通过实验测试峰值,可参考BBuf的文章 如何判断算法是否有可优化空间? (https://zhuanlan.zhihu.com/p/268925243)
3.3 反汇编分析生成代码质量
可通过反汇编的方式查看Intrinsics 生成的汇编是否满足预期,如果不满足预期则进行手写汇编优化。具体操作可参考梁德澎的文章 移动端arm cpu优化学习笔记第4弹–内联汇编入门(https://zhuanlan.zhihu.com/p/143328317)
4. 其他
余下的是相关的研讨会视频、库和案例。第一个视频帮助我建立了优化分析思维,值得推荐。
(1)研讨会视频 “Performance Analysis for Optimizing Embedded Deep Learning Inference Software,” a Presentation from Arm - Edge AI and Vision Alliance
https://www.edge-ai-vision.com/2019/07/performance-analysis-for-optimizing-embedded-deep-learning-inference-software-a-presentation-from-arm/
(2)研讨会视频 LCU14-504: Taming ARMv8 NEON: from theory to benchmark results
https://www.youtube.com/watch?v=ixuDntaSnHIwww.youtube.com
(3)研讨会视频 HKG15-408: ARM v8-A NEON optimization
https://www.youtube.com/watch?v=NYFzidaS3Z4www.youtube.com
(4)Ne10(ARM官方的计算库):
https://github.com/projectNe10/Ne10
(5)Arm Optimized Routines(ARM官方的计算、网络、字符串库):
https://github.com/ARM-software/optimized-routines
(6)Neon优化Chromium的案例
https://developer.arm.com/documentation/101964/developer.arm.com
文章来源:GiantPandaCV
推荐阅读
- DPRNN
- DeepSpeech理论与实战
- WaveNet结构与推断
更多芯擎AI开发板干货请关注芯擎AI开发板专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。












![[Linux] linux 软硬链接与动静态库](https://i-blog.csdnimg.cn/direct/165159c9c8514e89bc1c89c9cdd9d3ff.jpeg)
![[mysql]相关子查询](https://i-blog.csdnimg.cn/direct/fb31f9fab93d4e8daa0455d0002bde0f.png)