前言:利用NVIDIA NIM平台提供的大模型进行编辑,通过llama-3.2-90b-vision-instruct模型进行初步的图片检测
step1:
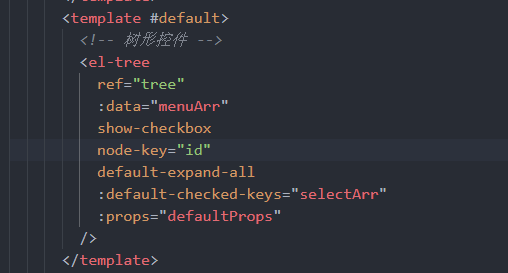
部署大模型到本地,引用所需要的库
import os
import requests
import base64
import cv2
import time
from datetime import datetimestep2:
观看官方使用文档:
import requests, base64
invoke_url = ""
stream = True
with open("image.png", "rb") as f:image_b64 = base64.b64encode(f.read()).decode()
assert len(image_b64) < 180_000, \"To upload larger images, use the assets API (see docs)"
headers = {"Authorization": "","Accept": "text/event-stream" if stream else "application/json"
}payload = {"model": 'meta/llama-3.2-90b-vision-instruct',"messages": [{"role": "user","content": f'What is in this image? <img src="data:image/png;base64,{image_b64}" />'}],"max_tokens": 512,"temperature": 1.00,"top_p": 1.00,"stream": stream
}
response = requests.post(invoke_url, headers=headers, json=payload)
if stream:for line in response.iter_lines():if line:print(line.decode("utf-8"))
else:print(response.json())其原理为将图片转换为base64后传入大模型进行识别,以及一系列参数
step3:
引入摄像头模块,并且时时进行推理,将模型的初步推理结果传入文本中,为后期的朗读进行预警
# 创建摄像头对象
cap = cv2.VideoCapture(0) # 0 是默认摄像头索引# 输出文件路径
output_file_path = "output.txt"def save_text_to_file(text):with open(output_file_path, "a", encoding="utf-8") as f: # 以追加模式打开文件timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 获取当前时间戳f.write(f"[{timestamp}] {text}\n") # 写入时间戳和文本,换行while True:ret, frame = cap.read()if not ret:print("无法获取图像")break# 将图像编码为 PNG 格式并转换为 Base64_, buffer = cv2.imencode('.png', frame)image_b64 = base64.b64encode(buffer).decode()# 构建请求负载,确保输入中文payload = {"model": 'meta/llama-3.2-90b-vision-instruct',"messages": [{"role": 'user',"content": f'请告诉我这张图片中有什么内容。<img src="data:image/png;base64,{image_b64}" />'}],"max_tokens": 512,"temperature": 1.00,"top_p": 1.00,"stream": stream}# 发送请求response = requests.post(invoke_url, headers=headers, json=payload)if response.status_code == 200:result = response.json()# 根据返回的结果处理输出print(result) # 可以进一步提取所需的信息# 获取结果中的文本内容if 'choices' in result and len(result['choices']) > 0:description = result['choices'][0]['message']['content']print(description) # 打印描述# 保存文本到文件save_text_to_file(description)else:print(f"请求失败,状态码:{response.status_code}")time.sleep(3) # 每秒捕获一帧# 释放摄像头
cap.release()
cv2.destroyAllWindows()
原理十分简单,让我们来看一下初步的结果:

在我加入翻译模块后,发现其输出结果:
'id': 'chat-51e2e604fd944de393136f7433919ad5', 'object': 'chat.completion', 'created': 1730471625, 'model': 'meta/llama-3.2-90b-vision-instruct', 'choices': [{'index': 0, 'message': {'role': 'assistant', 'content': '这里有一张中年亚洲男性 frontal director 照片。照片截图自远程视频会议ूच意识。\n\n/ Ψ οδ HistogramDescriptionBlack / 97% Colorsunnedove Gray66BetaBLUE209peach29dark brown अपन Nogran8023825444098364103281213183791565308314594581053713508413533mntileyelo \n\n.', 'tool_calls': []}, 'logprobs': None, 'finish_reason': 'stop', 'stop_reason': None}], 'usage': {'prompt_tokens': 20, 'total_tokens': 99, 'completion_tokens': 79}, 'prompt_logprobs': None}
这里有一张中年亚洲男性 frontal director 照片。照片截图自远程视频会议ूच意识。
存在乱码的情况,后续我将进行优化,加入其他大模型进行处理,并且在考虑时时状态下进行最优化解决.