自动驾驶:BEVDet
- Introduction
- Methodolo
- Data Augmentation
- Network Structure
- Scale-NMS
- 实验
Introduction
作者通过现有的算法(LSS)、独特的数据增强方案与新的NMS方案整合了一个BEV框架(BEVDet)。
如下图:
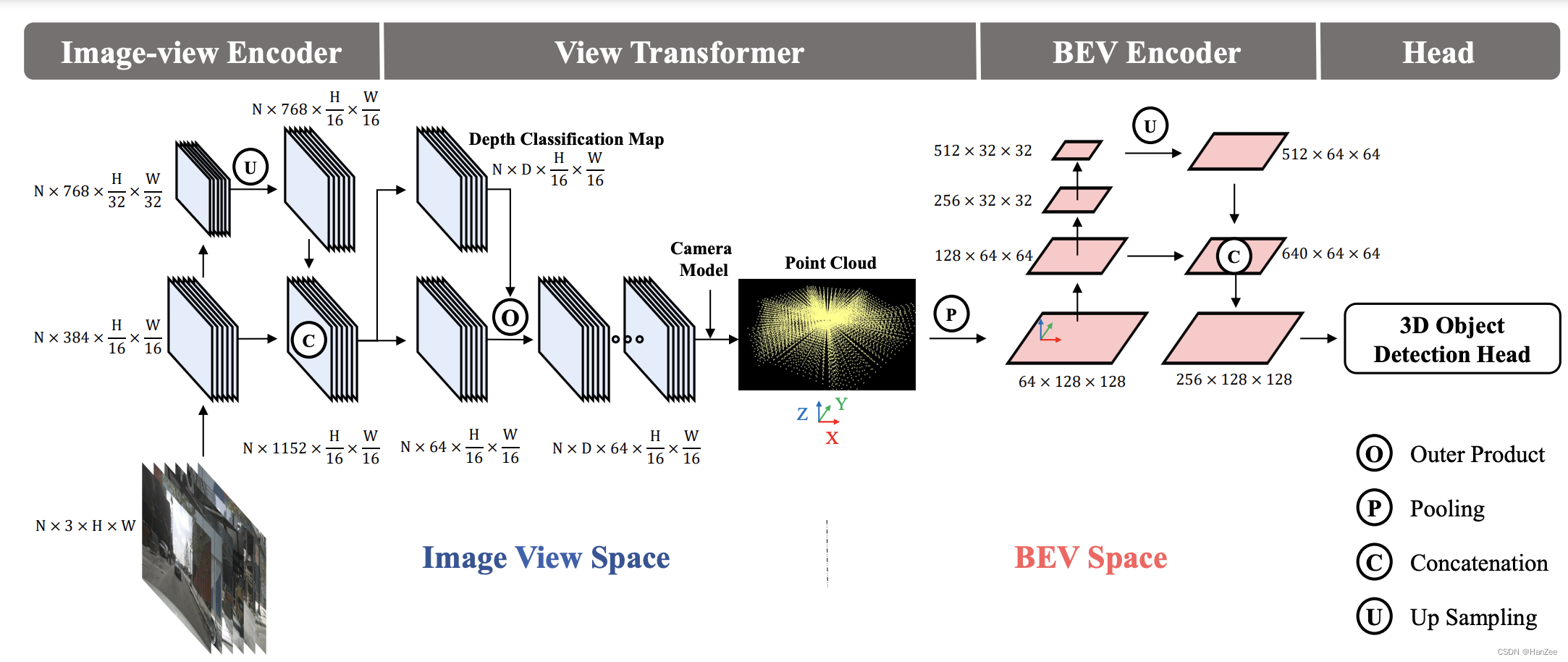
这个框架分为四部分:
- Image-view-Encoder(Backbone + neck)。
- View Transformer(这就是LSS的lift与splat)。
- BEV Encoder (得到BEV特征在通过CNN或者attention提取bev特征)。
- Head。
在实验中,BEVDet很好的权衡了检测准确度和时间效率。在nuScenes val集上时,作为快速版本的BEVDet-Tiny的得分为31.2% mAP和39.2% NDS。与FCOS3D相比,BEVDet只需要215.3 GFLOPs 的计算开销, 是FCOS3D11%);运行速度每秒15.6帧,比FCOS3D快9.2倍。另一个高精度版本 BEVDet-Base评分为39.3% mAP和47.2% NDS, 显著地超过所有已发表的结果。在一个相当快的推理速度下,它与FCOS3D相比,mAP 提升了9.8%, NDS 提升了10.0%。
Methodolo
Data Augmentation
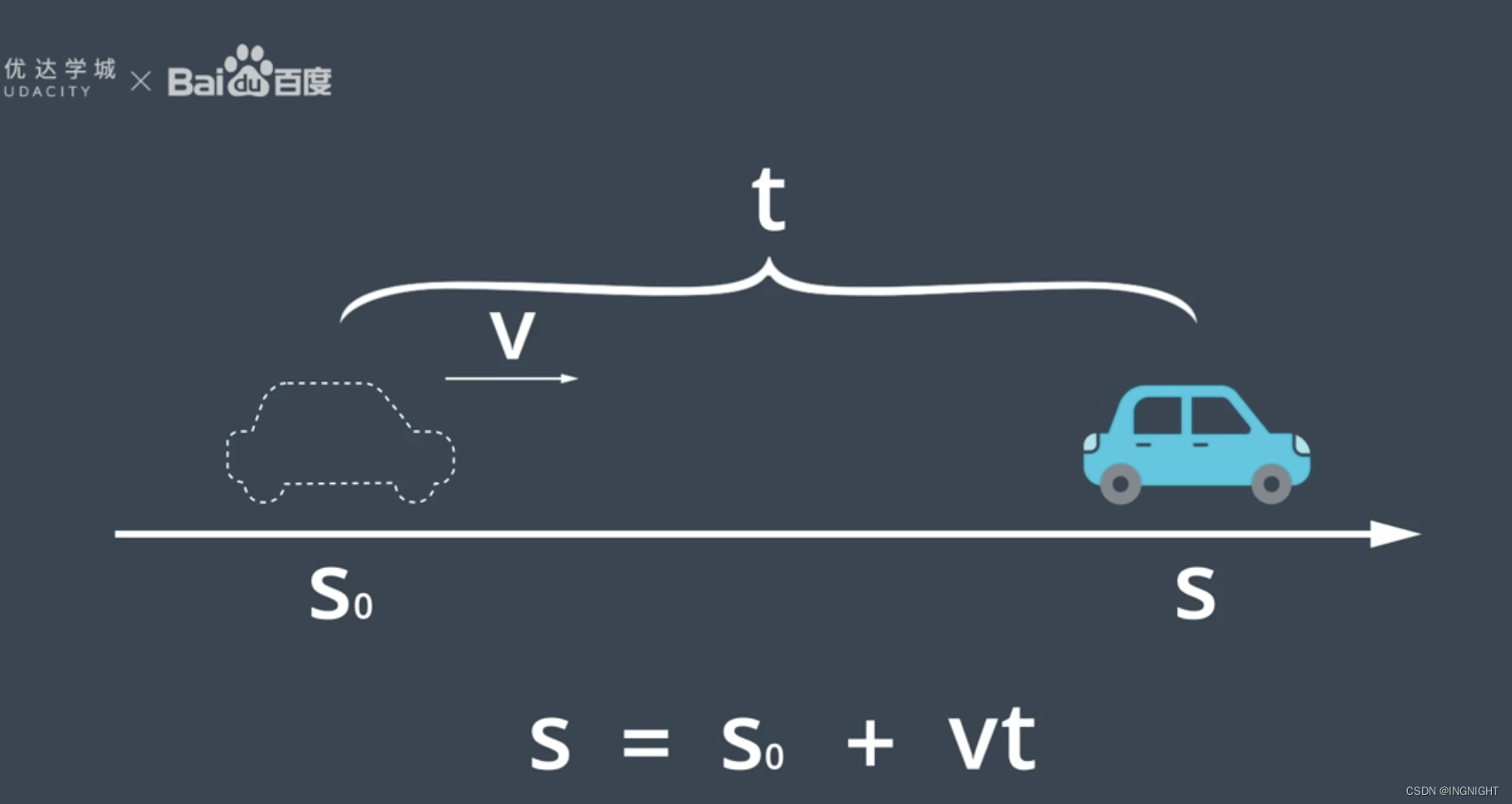
坐标转换公式:
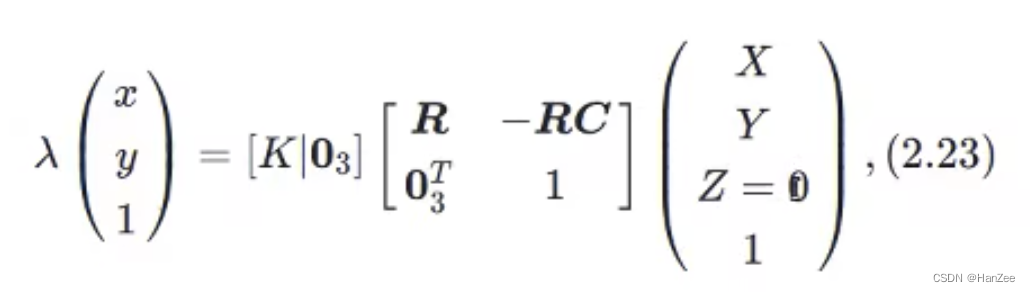
作者在训练途中遇到了严重的over- fitting ,因为在nusuense 数据集下每个场景有6个cam组成,这六个中必然会有交叉的场景重复出现。
另一方面,基于图像视图编码器的批处理大小是子序列模块的N倍。训练数据的不足也是导致在基于BEV空间中学习过拟合的一部分原因。
作者起初想用一些数据增强的方法来缓解过拟合,但是这种方法只在没有bev的时候很work,因为假如我所有的2d image 都做了翻转(所有image做了相同角度的倾斜),由于后面需要把feature融入视锥,而视锥没有倾斜,这样会导致空间分布不一致,造成不必要的噪声。
公式表示如下:
假设本来的pixel 坐标为:
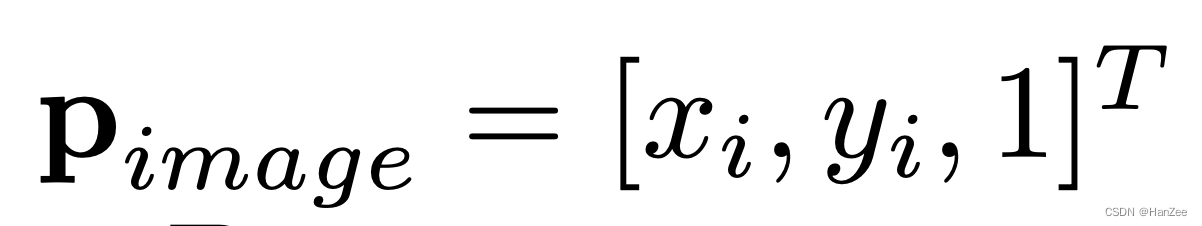
本来的 3d voxel 坐标为:
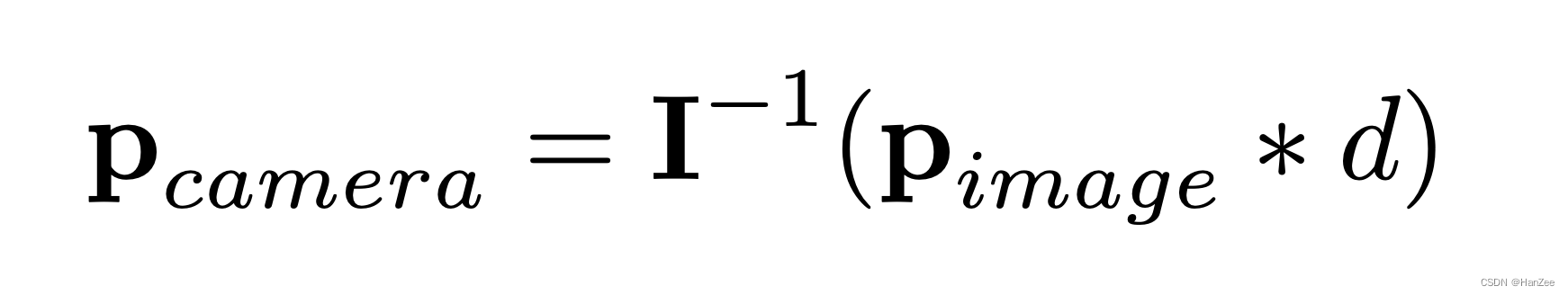
image 数据增强后:
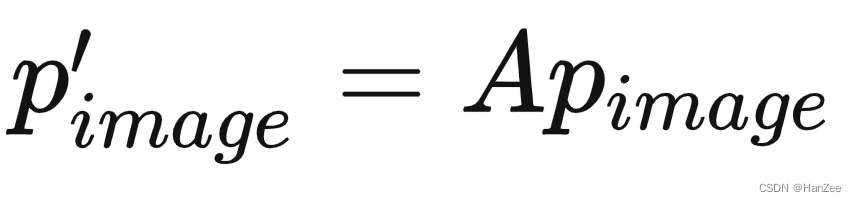
但是这是3d voxel坐标他是没发生变化的,因为它是在生成视锥是根据原图确定的,而数据增强是在训练阶段进行的,他们没有做到同步。
于是我们需要对它3d voxel 进行逆矩阵变换使得2d 3d 空间分布一致(也就是还是符合通过内外参数的光学成像对应关系), 公式如下:
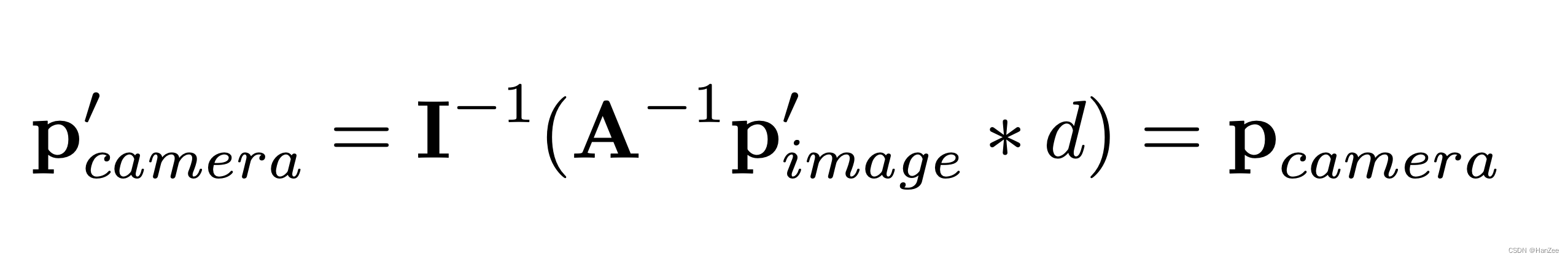
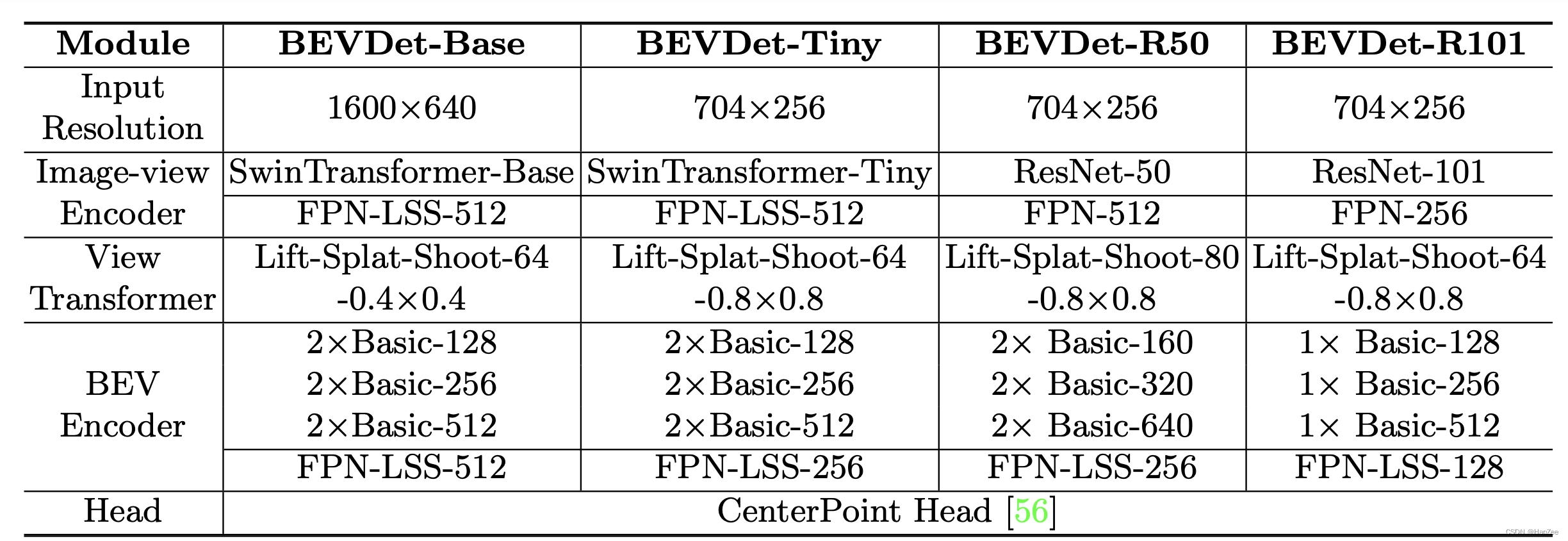
Network Structure
这里大家直接看图,简单明了。
Scale-NMS
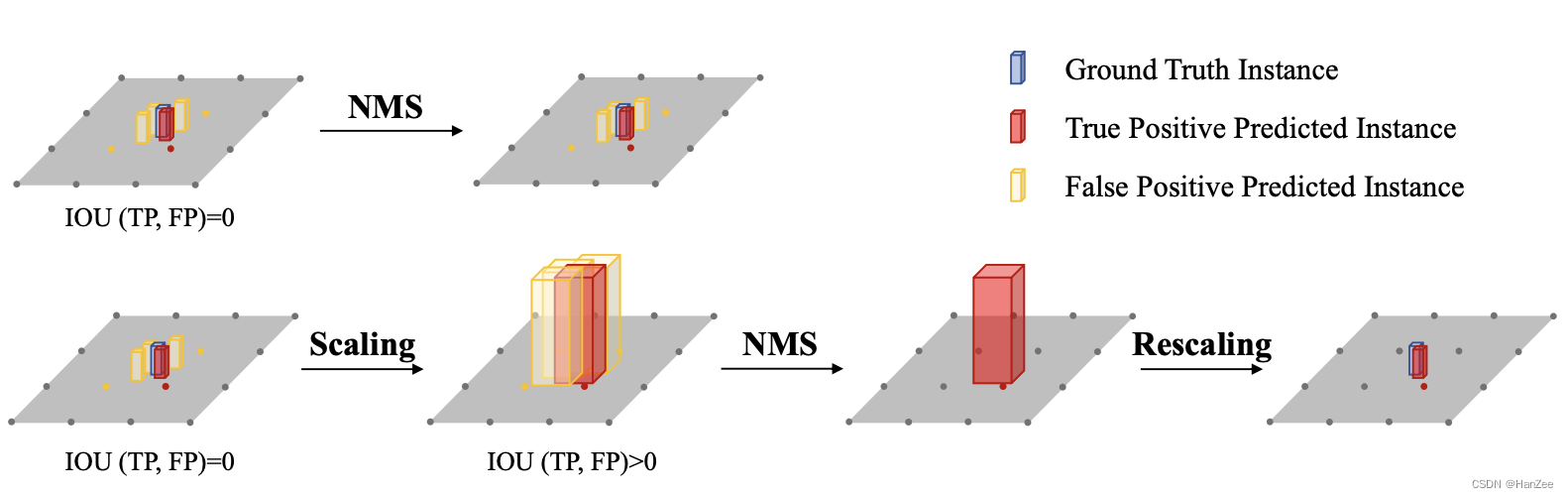
BEV空间中不同类别的空间分布与图像视图空间中的空间分布截然不同。在图像视图空间中,由于相机的透视成像机制,所有类别共享相似的空间分布。因此,对于经典的NMS策略对于不同的类别都采用相同的阈值来来筛选预测结果。(例如在2D目标检测中,任何两个实例的bounding box的IOU值总是低于0.5)
然而,在BEV空间中,各个类的占用面积本质上是不同的,实例之间的重叠应接近于零。因此,预测结果之间的IOU分布因类别而异。
比如行人和锥型交通路标在接地面上占用很小的面积,这总是小于算法的输出分辨率。常见的对象检测范式冗余地生成预测。每个物体的占地面积小,可能使冗余结果与真正结果没有交集。这将使依赖正样本和负样本之间空间关系(IOU)的经典NMS失效。
解决方法:
Scale-NMS在执行经典NMS算法之前,**根据每个对象的类别缩放其大小。**通过这种方式,调整正样例和冗余结果之间的IOU分布,以与经典NMS匹配。缩放因子是特定于类别的。它们是通过对验证集进行超参数搜索生成的。
实验