作者:肯梦
本文将演示如何使用事件总线(EventBridge),向量检索服务(DashVector),函数计算(FunctionCompute)结合灵积模型服务 [ 1] 上的 Embedding API [ 2] ,来从 0 到 1 构建基于文本索引的构建+向量检索基础上的语义搜索能力。具体来说,我们将基于 OSS 文本文档动态插入数据,进行实时的文本语义搜索,查询最相似的相关内容。
本文中将用到事件总线(EventBridge),它是阿里云提供的一款无服务器事件总线服务,支持阿里云服务、自定义应用、SaaS 应用以标准化、中心化的方式接入,并能够以标准化的 CloudEvents 1.0 协议在这些应用之间路由事件,帮助您轻松构建松耦合、分布式的事件驱动架构。
RAG 背景概述
大语言模型(LLM)作为自然语言处理领域的核心技术,具有丰富的自然语言处理能力。但其训练语料库具有一定的局限性,一般由普适知识、常识性知识,如维基百科、新闻、小说,和各种领域的专业知识组成。导致 LLM 在处理特定领域的知识表示和应用时存在一定的局限性,特别对于垂直领域内,或者企业内部等私域专属知识。
实现专属领域的知识问答的关键,在于如何让 LLM 能够理解并获取存在于其训练知识范围外的特定领域知识。同时可以通过特定 Prompt 构造,提示 LLM 在回答特定领域问题的时候,理解意图并根据注入的领域知识来做出回答。在通常情况下,用户的提问是完整的句子,而不像搜索引擎只输入几个关键字。这种情况下,直接使用关键字与企业知识库进行匹配的效果往往不太理想,同时长句本身还涉及分词、权重等处理。相比之下,倘若我们把提问的文本,和知识库的内容,都先转化为高质量向量,再通过向量检索将匹配过程转化为语义搜索,那么提取相关知识点就会变得简单而高效。
本文将介绍如何构建一个完全动态的 RAG 入库方案,通过 EventBridge 拉取 OSS 非结构化数据,同时将数据投递至 DashVector 向量数据库,从而实现完整的 RAG Ingestion 流程。
流程概述
数据集成(Ingestion)
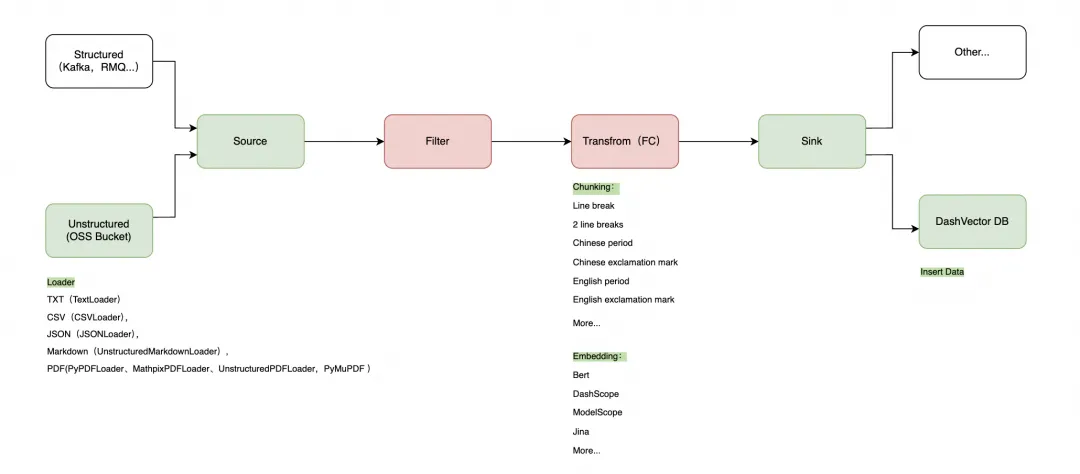
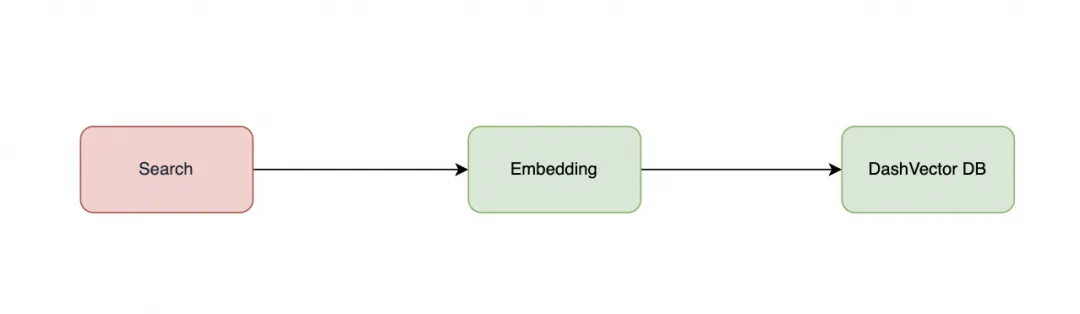
数据检索(Search)
操作流程
前提条件
- DashScope 控制台开通灵积模型服务,并获得 API-KEY 的获取与配置。
- 开通 DashVector 向量检索服务,并获得 API-KEY 的获取与配置。
- 开通 OSS 服务。
- 开通 FC 服务。
- 开通 EventBridge 服务。
开通灵积模型服务
- 点击进入 DashScope 控制台 [ 3] ,开通灵积相关服务
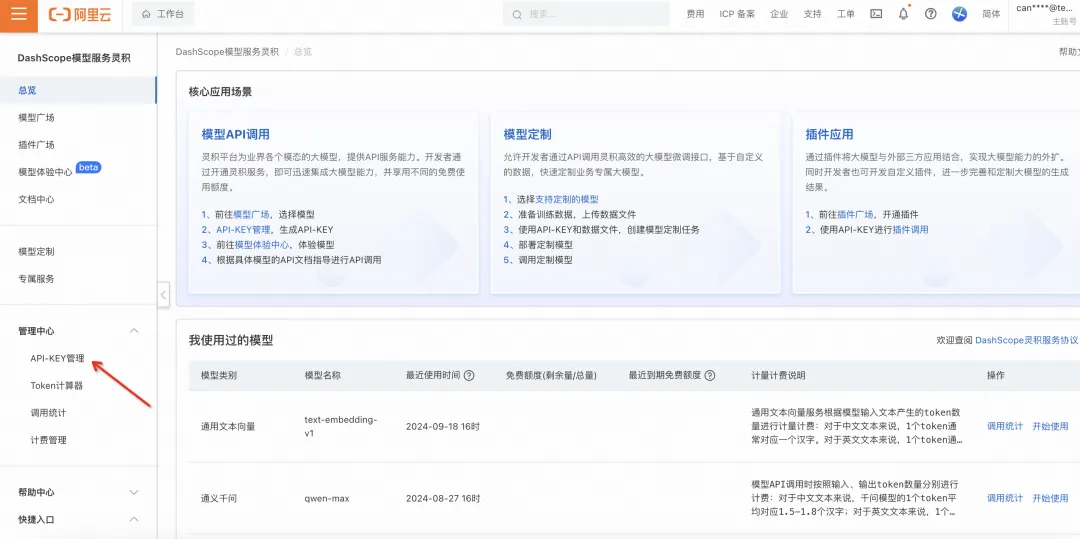
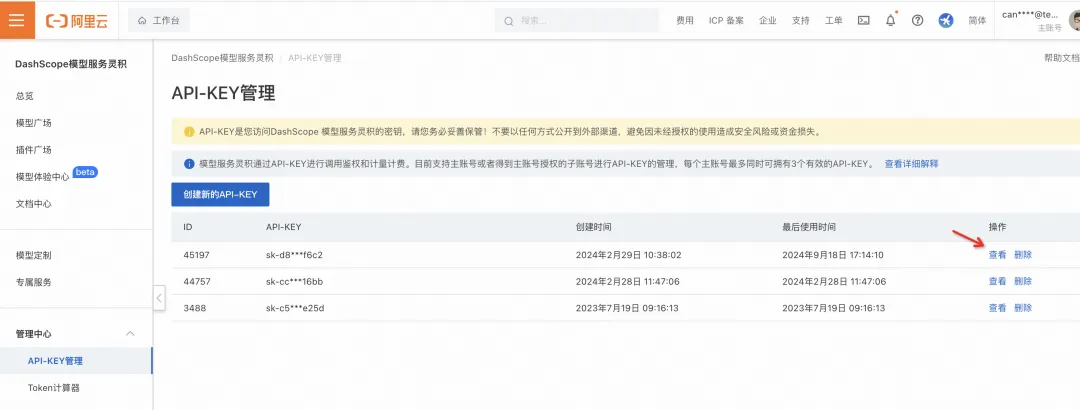
- 点击进入“API-KEY”管理,获取相关 KEY 信息
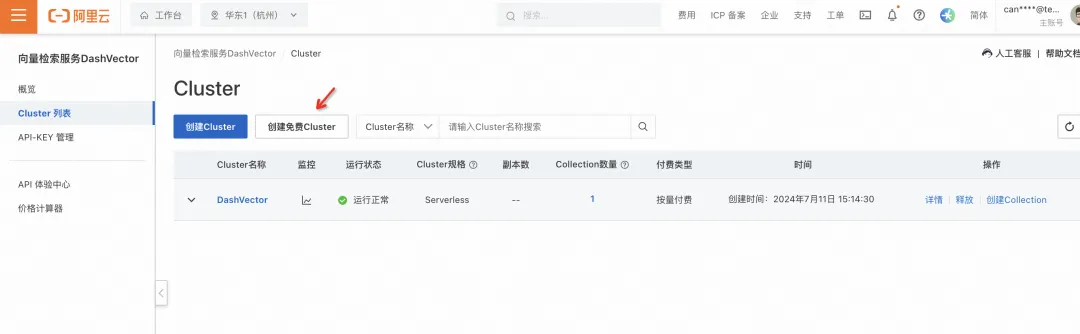
开通 DashVector 服务
- 若第一次配置,请点击“新建 DashVector Cluster [ 4] ”,跳转创建新的 Cluster;点击“创建免费 Cluster”快速体验创建向量数据库
2. 选择“立即购买”

3. 点击创建“Collection”
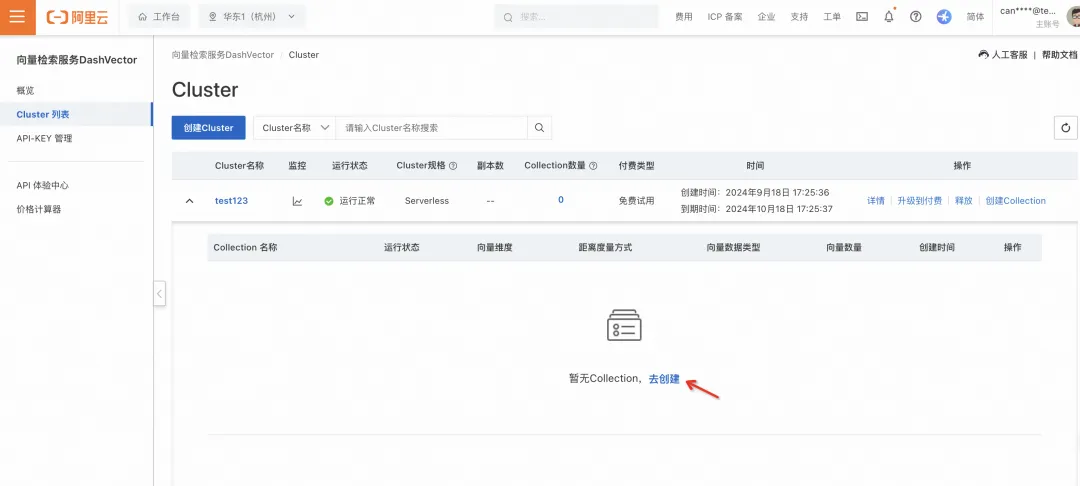
4. 填写纬度为“1536”,距离度量方式“Cosine”,点击“确认”
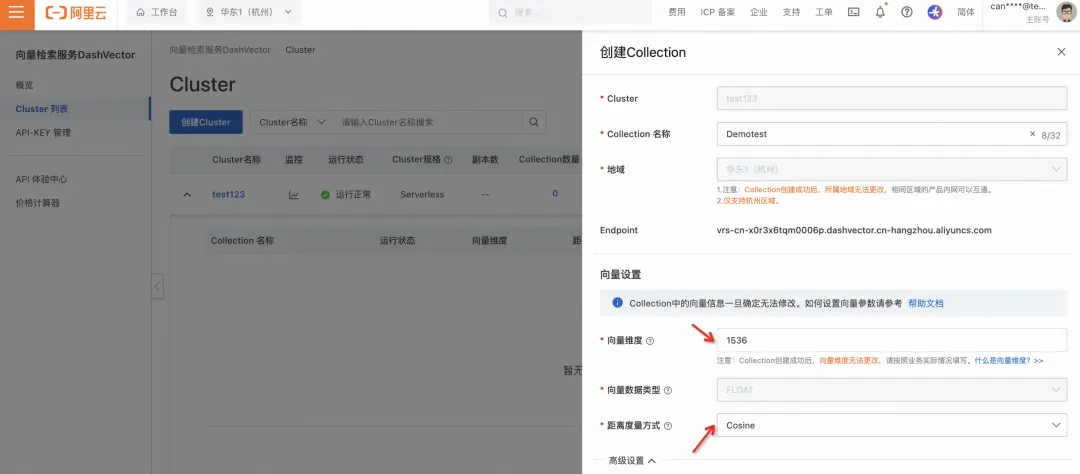
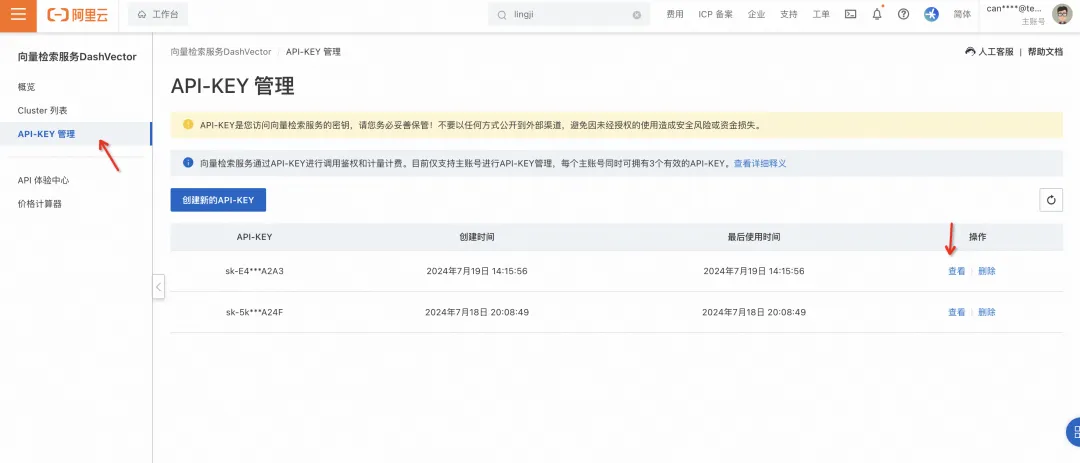
5. 点击“API-KEY 管理”,获取 DashVector 的 API KEY
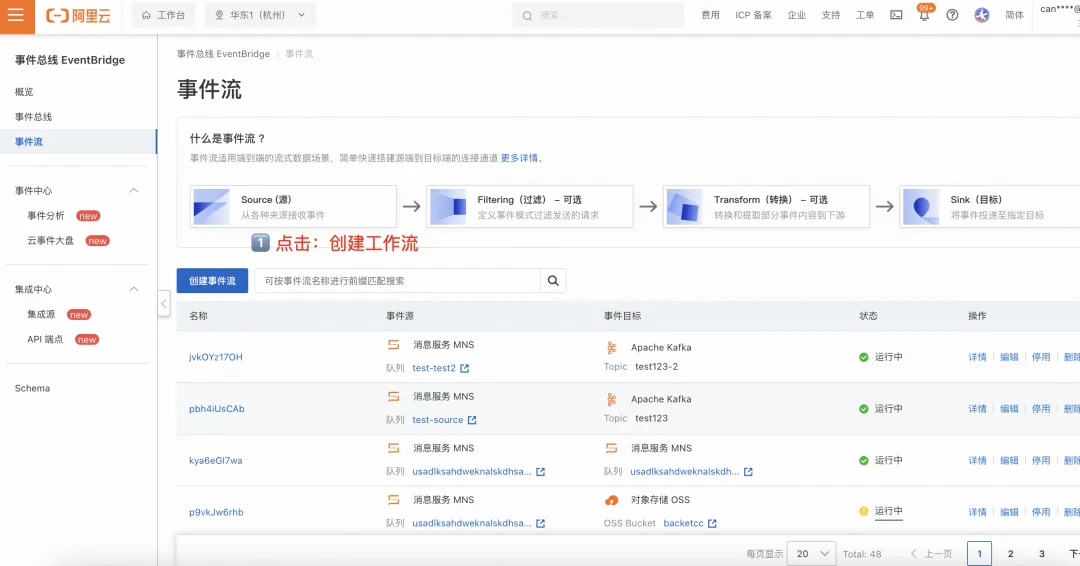
创建 Ingestion 数据集成任务
1.1 进入 EventBridge 控制台 [ 5]
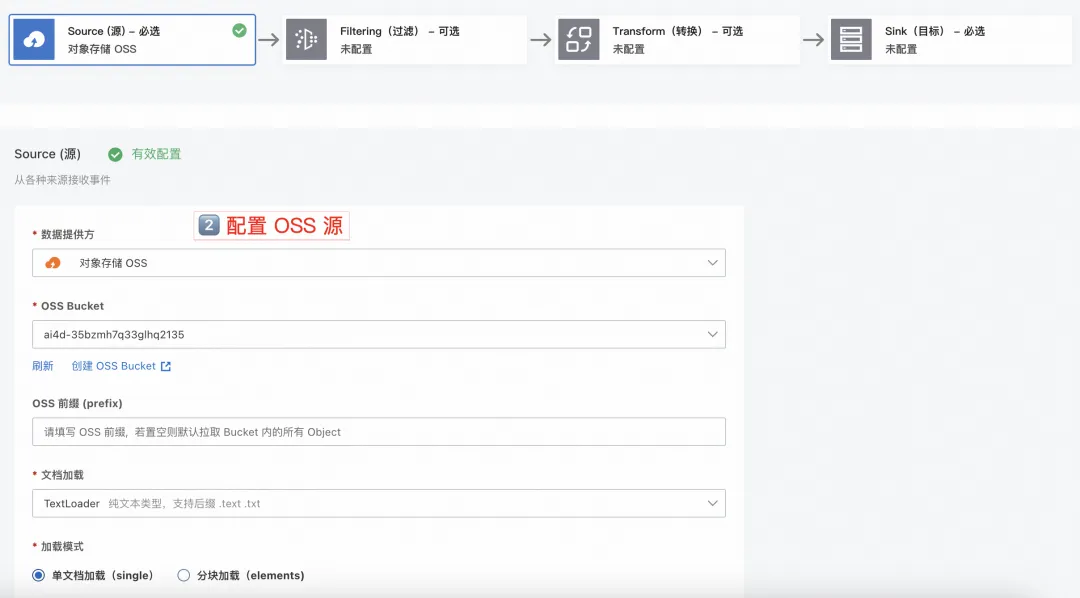
1.2 配置 OSS 源
- OSS Bucket:选择空白存储桶实验,若无请自行创建;
- OSS 前缀:该项可根据诉求填写,若无前缀 EB 将拉取整个 Bucket 内容;本次演示不配置;
- 文档加载:目前支持解析 TextLoder 作为文档加载器;
- 加载模式:“单文档加载”单个文件作为一条数据加载,“分块加载”按照分隔符加载数据;本次演示使用单文档加载。
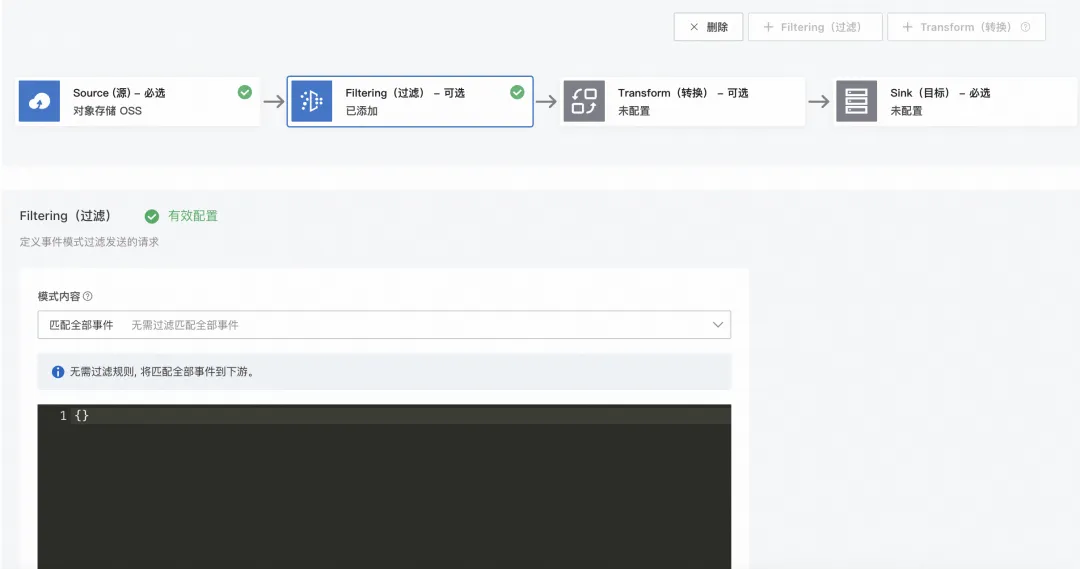
1.3 配置过滤
可根据诉求添加过滤规则,本次演示使用“匹配全部事件”。
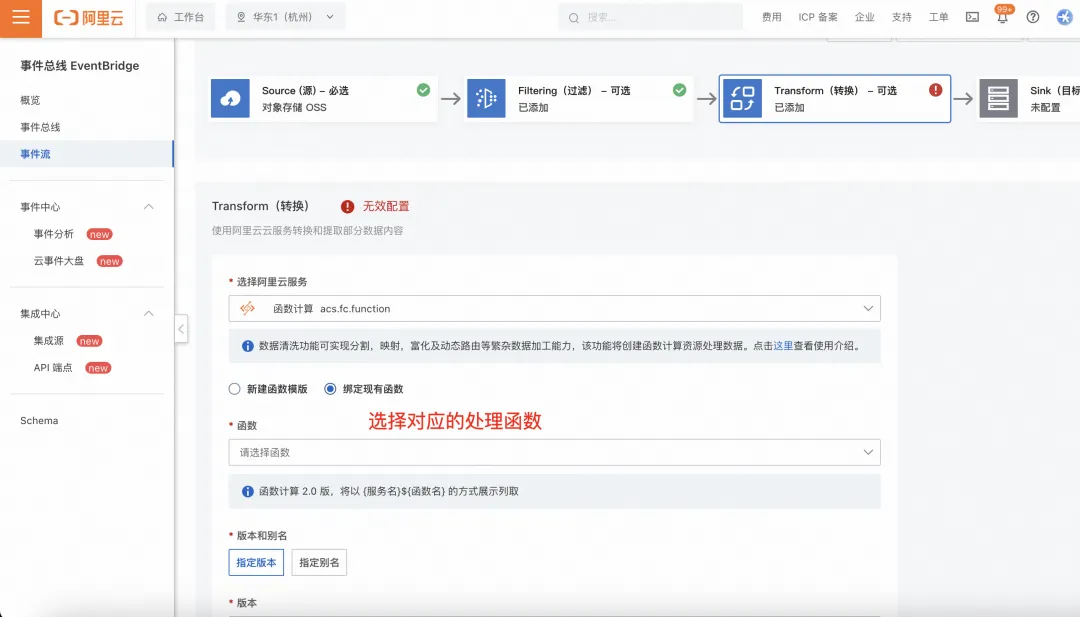
1.4 配置转换
转换部分主要是将原始数据转成向量化数据,为投递至 DashVector 做数据准备。
函数代码如下,函数环境为 Python 3.10:
# -*- coding: utf-8 -*-
import os
import ast
import copy
import json
import logging
import dashscope
from dashscope import TextEmbedding
from http import HTTPStatuslogger = logging.getLogger()
logger.setLevel(level=logging.INFO)dashscope.api_key='Your-API-KEY'def handler(event, context):evt = json.loads(event)evtinput = evt['data']resp = dashscope.TextEmbedding.call(model=dashscope.TextEmbedding.Models.text_embedding_v1,api_key=os.getenv('DASHSCOPE_API_KEY'), input= evtinput )if resp.status_code == HTTPStatus.OK:print(resp)else:print(resp)return resp
🔔 注意: 需手动安装相关函数环境,相关文档参考《为函数安装第三方依赖》 [ 6] 。
pip3 install dashvector dashscope -t .
返回样例:
{"code": "","message": "","output": {"embeddings": [{"embedding": [-2.192838430404663,-0.703125,... ...-0.8980143070220947,-0.9130208492279053,-0.520526111125946,-0.47154948115348816],"text_index": 0}]},"request_id": "e9f9a555-85f2-9d15-ada8-133af54352b8","status_code": 200,"usage": {"total_tokens": 3}
}
1.5 配置向量数据库 Dashvector
选择创建好的向量数据库。
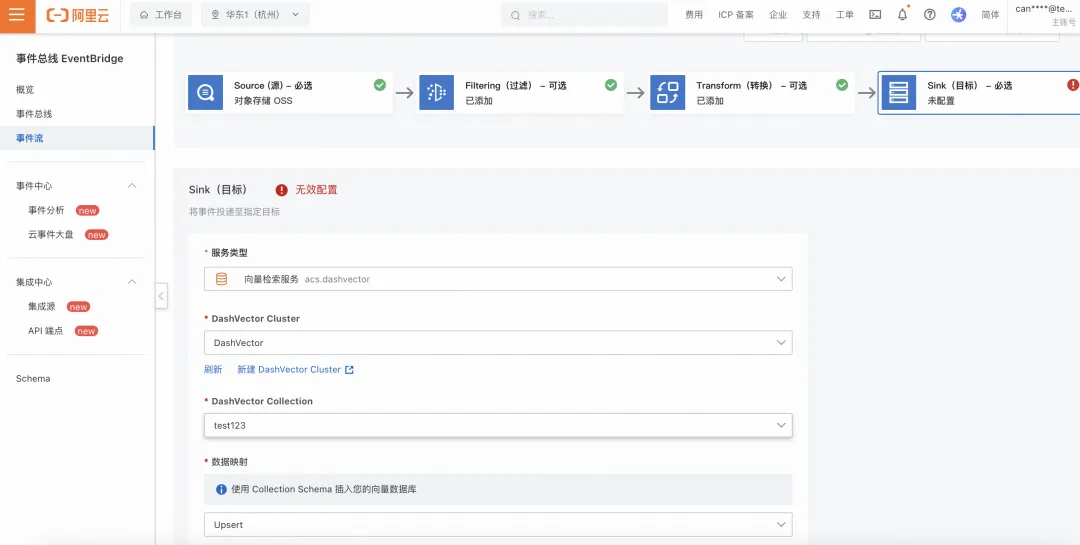
- 数据映射:选择 Upsert 方式插入;
- 向量:填写上游 Dashscope 的 TextEmbedding 投递的向量信息 $.output. embeddings[0].embedding;
- 鉴权配置:获取的 DashVector API-KEY 参数。

创建 Search 数据检索任务
在进行数据检索时,需要首先对数据进行 embedding,然后将 embedding 后的向量值与数据库值做检索排序。最后填写 prompt 模版,通过自然语言理解和语义分析,理解数据检索意图。
该任务可以部署在云端函数计算,或者直接在本地环境执行;首先,我们创建 embedding.py,将需要检索的问题进行文本向量化,代码如下所示:
embedding.py
import os
import dashscope
from dashscope import TextEmbeddingdef generate_embeddings(news):rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,input=news)embeddings = [record['embedding'] for record in rsp.output['embeddings']]return embeddings if isinstance(news, list) else embeddings[0]if __name__ == '__main__':dashscope.api_key = '{your-dashscope-api-key}'
然后,创建 search.py 文件,并将如下示例代码复制到 search.py 文件中,通过 DashVector 的向量检索能力来检索相似度的最高的内容。search.py
from dashvector import Clientfrom embedding import generate_embeddingsdef search_relevant_news(question):# 初始化 dashvector clientclient = Client(api_key='{your-dashvector-api-key}',endpoint='{your-dashvector-cluster-endpoint}')# 获取存入的集合collection = client.get('news_embedings')assert collection# 向量检索:指定 topk = 1 rsp = collection.query(generate_embeddings(question), output_fields=['raw'],topk=1)assert rspreturn rsp.output[0].fields['raw']
创建 answer.py 文件,我们就可以按照特定的模板作为 prompt 向 LLM 发起提问了,在这里我们选用的 LLM 是通义千问(qwen-turbo),代码示例如下:
answer.py
from dashscope import Generationdef answer_question(question, context):prompt = f'''请基于```内的内容回答问题。"```{context}```我的问题是:{question}。'''rsp = Generation.call(model='qwen-turbo', prompt=prompt)return rsp.output.text
最后,创建 run.py 文件,并将如下示例代码复制到 run.py 文件中,并最终执行 run.py 文件。(验证时,可在绑定的 OSS Bucket 上传需要被检索的知识库信息。)
import dashscopefrom search import search_relevant_news
from answer import answer_questionif __name__ == '__main__':dashscope.api_key = '{your-dashscope-api-key}'question = 'EventBridge 是什么,它有哪些能力?'context = search_relevant_news(question)answer = answer_question(question, context)print(f'question: {question}\n' f'answer: {answer}')
总结
从本文的范例中,我们可以比较方便的使用 EventBridge 提供的 OSS To DashVector 离线数据流导入能力,开箱即用的构建强大向量检索服务能力,这些能力和各个 AI 模型结合,能够衍生多样的 AI 应用的可能。同样,Transform 部分使用了函数计算能力,可以更灵活的制定想要的 Split 切分算法,提供更灵活且具备生产力的 RAG 方案。
相关链接:
[1] 灵积模型服务
https://dashscope.aliyun.com/
[2] Embedding API
https://help.aliyun.com/zh/dashscope/developer-reference/text-embedding-api-details
[3] DashScope 控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fdashscope.console.aliyun.com%2Foverview&clearRedirectCookie=1&lang=zh
[4] 新建 DashVector Cluster
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fdashvector.console.aliyun.com%2Fcn-hangzhou%2Fcluster&clearRedirectCookie=1&lang=zh
[5] EventBridge 控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Feventbridge.console.aliyun.com%2F&clearRedirectCookie=1&lang=zh
[6] 《为函数安装第三方依赖》
https://help.aliyun.com/zh/functioncompute/fc-3-0/user-guide/install-third-party-dependencies-for-a-function


![[复健计划][紫书]Chapter 7 暴力求解法](https://i-blog.csdnimg.cn/direct/737b6dbce762436990459fcdca213801.png)