本文原文地址:GoLang协程Goroutiney原理与GMP模型详解
什么是goroutine
Goroutine是Go语言中的一种轻量级线程,也成为协程,由Go运行时管理。它是Go语言并发编程的核心概念之一。Goroutine的设计使得在Go中实现并发编程变得非常简单和高效。
以下是一些关于Goroutine的关键特性:
- 轻量级:Goroutine的创建和切换开销非常小。与操作系统级别的线程相比,Goroutine占用的内存和资源更少。一个典型的Goroutine只需要几KB的栈空间,并且栈空间可以根据需要动态增长。
- 并发执行:Goroutine可以并发执行多个任务。Go运行时会自动将Goroutine调度到可用的处理器上执行,从而充分利用多核处理器的能力。
- 简单的语法:启动一个Goroutine非常简单,只需要在函数调用前加上go关键字。例如,go myFunction()会启动一个新的Goroutine来执行myFunction函数。
- 通信和同步:Go语言提供了通道(Channel)机制,用于在Goroutine之间进行通信和同步。通道是一种类型安全的通信方式,可以在不同的Goroutine之间传递数据。
什么是协程
协程(Coroutine)是一种比线程更轻量级的并发编程方式。它允许在单个线程内执行多个任务,并且可以在任务之间进行切换,而不需要进行线程上下文切换的开销。协程通过协作式多任务处理来实现并发,这意味着任务之间的切换是由程序显式控制的,而不是由操作系统调度的。
以下是协程的一些关键特性:
- 轻量级:协程的创建和切换开销非常小,因为它们不需要操作系统级别的线程管理。
- 非抢占式:协程的切换是显式的,由程序员在代码中指定,而不是由操作系统抢占式地调度。
- 状态保存:协程可以在暂停执行时保存其状态,并在恢复执行时继续从暂停的地方开始。
- 异步编程:协程非常适合用于异步编程,特别是在I/O密集型任务中,可以在等待I/O操作完成时切换到其他任务,从而提高程序的并发性和效率。
Goroutin就是Go在协程这个场景上的实现。
以下是一个简单的go goroutine例子,展示了如何使用协程:
package mainimport ("fmt""sync""time"
)// 定义一个简单的函数,模拟一个耗时操作
func printNumbers(wg *sync.WaitGroup) {defer wg.Done() // 在函数结束时调用Done方法for i := 1; i <= 5; i++ {fmt.Printf("Number: %d\n", i)time.Sleep(1 * time.Second) // 模拟耗时操作}
}func main() {var wg sync.WaitGroup// 启动一个goroutine来执行printNumbers函数wg.Add(1)go printNumbers(&wg)// 主goroutine继续执行其他操作for i := 'A'; i <= 'E'; i++ {fmt.Printf("Letter: %c\n", i)time.Sleep(1 * time.Second) // 模拟耗时操作}// 等待所有goroutine完成wg.Wait()
}
我们定义了一个名为printNumbers的函数,该函数会打印数字1到5,并在每次打印后暂停1秒。然后,在main函数中,我们使用go关键字启动一个新的goroutine来执行printNumbers函数。同时,主goroutine继续执行其他操作,打印字母A到E,并在每次打印后暂停1秒。
需要注意的是,主goroutine和新启动的goroutine是并发执行的。为了确保所有goroutine完成,我们使用sync.WaitGroup来等待所有goroutine完成。我们在启动goroutine之前调用wg.Add(1),并在printNumbers函数结束时调用wg.Done()。最后,我们在main函数中调用wg.Wait(),等待所有goroutine完成。这样可以确保程序在所有goroutine完成之前不会退出。
协程是一种强大的工具,可以简化并发编程,特别是在处理I/O密集型任务时。
Goroutin实现原理
Goroutine的实现原理包括Goroutine的创建、调度、上下文切换和栈管理等多个方面。通过GPM模型和高效的调度机制,Go运行时能够高效地管理和调度大量的Goroutine,实现高并发编程。
Goroutine的创建
当使用go关键字启动一个新的Goroutine时,Go运行时会执行以下步骤:
- 分配G结构体:Go运行时会为新的Goroutine分配一个G结构体(G表示Goroutine),其中包含Goroutine的状态信息、栈指针、程序计数器等。
- 分配栈空间:Go运行时会为新的Goroutine分配初始的栈空间,通常是几KB。这个栈空间是动态增长的,可以根据需要自动扩展。
- 初始化G结构体:Go运行时会初始化G结构体,将Goroutine的入口函数、参数、栈指针等信息填入G结构体中。
- 将Goroutine加入调度队列:Go运行时会将新的Goroutine加入到某个P(Processor)的本地运行队列中,等待调度执行。
Goroutine的调度
Go运行时使用GPM模型(Goroutine、Processor、Machine)来管理和调度Goroutine。调度过程如下:
- P(Processor):P是Go运行时的一个抽象概念,表示一个逻辑处理器。每个P持有一个本地运行队列,用于存储待执行的Goroutine。P的数量通常等于机器的CPU核心数,可以通过runtime.GOMAXPROCS函数设置。
- M(Machine):M表示一个操作系统线程。M负责实际执行P中的Goroutine。M与P是一对一绑定的关系,一个M只能绑定一个P,但一个P可以被多个M绑定(通过抢占机制)。M的数量是由Go运行时系统动态管理和确定的。M的数量并不是固定的,而是根据程序的运行情况和系统资源的使用情况动态调整的。通过runtime.NumGoroutine()和runtime.NumCPU()函数,我们可以查看当前的Goroutine数量和CPU核心数。Go运行时对M的数量有一个默认的最大限制,以防止创建过多的M导致系统资源耗尽。这个限制可以通过环境变量GOMAXPROCS进行调整,但通常不需要手动设置。
- G(Goroutine):代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
- 调度循环:每个P会在一个循环中不断从本地运行队列中取出Goroutine,并将其分配给绑定的M执行。如果P的本地运行队列为空,P会尝试从其他P的本地运行队列中窃取Goroutine(工作窃取机制)。
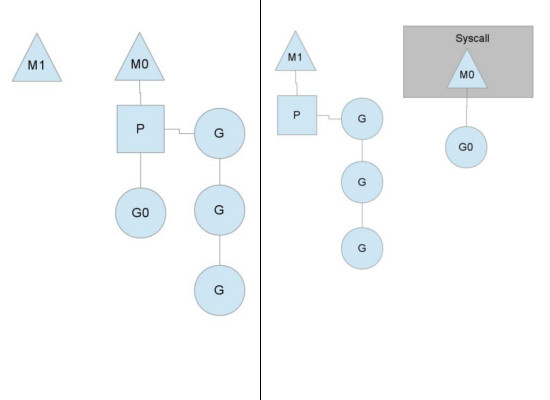
从上图中看,有2个物理线程M,每一个M都拥有一个处理器P,每一个也都有一个正在运行的goroutine。P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
P的数量可以大于器的CPU核心数?
在Go语言中,P(Processor)的数量通常等于机器的CPU核心数,但也可以通过runtime.GOMAXPROCS函数进行调整。默认情况下,Go运行时会将P的数量设置为机器的逻辑CPU核心数。然而,P的数量可以被设置为大于或小于机器的CPU核心数,这取决于具体的应用需求和性能考虑。
调整P的数量,可以使用runtime.GOMAXPROCS函数来设置P的数量。例如:
package mainimport ("fmt""runtime""sync"
)func worker(id int, wg *sync.WaitGroup) {defer wg.Done()fmt.Printf("Worker %d starting\n", id)// 模拟工作负载for i := 0; i < 1000000000; i++ {}fmt.Printf("Worker %d done\n", id)
}func main() {// 设置P的数量为机器逻辑CPU核心数的两倍numCPU := runtime.NumCPU()runtime.GOMAXPROCS(numCPU * 2)var wg sync.WaitGroup// 启动多个Goroutinefor i := 1; i <= 10; i++ {wg.Add(1)go worker(i, &wg)}// 等待所有Goroutine完成wg.Wait()fmt.Println("All workers done")
}
在这个示例中,我们将P的数量设置为机器逻辑CPU核心数的两倍。这样做的目的是为了观察在不同P数量设置下程序的性能表现。
- P的数量大于CPU核心数的影响
- 上下文切换增加:当P的数量大于CPU核心数时,可能会导致更多的上下文切换。因为操作系统需要在有限的CPU核心上调度更多的线程(M),这可能会增加调度开销。
- 资源竞争:更多的P意味着更多的Goroutine可以同时运行,但这也可能导致更多的资源竞争,特别是在I/O密集型任务中。过多的P可能会导致资源争用,反而降低程序的整体性能。
- 并发性提高:在某些情况下,增加P的数量可以提高程序的并发性,特别是在存在大量阻塞操作(如I/O操作)的情况下。更多的P可以更好地利用CPU资源,减少阻塞时间。
- P的数量小于CPU核心数的影响
- CPU利用率降低:当P的数量小于CPU核心数时,可能会导致CPU资源未被充分利用。因为P的数量限制了同时运行的Goroutine数量,可能会导致某些CPU核心处于空闲状态。
- 减少上下文切换:较少的P数量可以减少上下文切换的开销,因为操作系统需要调度的线程(M)数量减少。这可能会提高CPU密集型任务的性能。
选择合适的P数量选择合适的P数量需要根据具体的应用场景和性能需求进行调整。以下是一些建议:
- CPU密集型任务:对于CPU密集型任务,通常将P的数量设置为等于或接近机器的逻辑CPU核心数,以充分利用CPU资源。
- I/O密集型任务:对于I/O密集型任务,可以考虑将P的数量设置为大于CPU核心数,以提高并发性和资源利用率。
- 性能测试和调优:通过性能测试和调优,找到最佳的P数量设置。可以尝试不同的P数量,观察程序的性能表现,选择最优的配置。
Goroutine的上下文切换
Goroutine的上下文切换由Go运行时的调度器管理,主要涉及以下步骤:
- 保存当前Goroutine的状态:当一个Goroutine被挂起时,Go运行时会保存当前Goroutine的状态信息,包括程序计数器、栈指针、寄存器等。
- 切换到新的Goroutine:Go运行时会从P的本地运行队列中取出下一个待执行的Goroutine,并恢复其状态信息。
- 恢复新的Goroutine的状态:Go运行时会将新的Goroutine的状态信息加载到CPU寄存器中,并跳转到新的Goroutine的程序计数器位置,继续执行。
Goroutine什么时候会被挂起?Goroutine会在执行阻塞操作、使用同步原语、被调度器调度、创建和销毁时被挂起。Go运行时通过高效的调度机制管理Goroutine的挂起和恢复,以实现高并发和高性能的程序执行。了解这些挂起的情况有助于编写高效的并发程序,并避免潜在的性能问题。
- 阻塞操作
当Goroutine执行阻塞操作时,它会被挂起,直到阻塞操作完成。常见的阻塞操作包括:
- I/O操作:如文件读写、网络通信等。
- 系统调用:如调用操作系统提供的阻塞函数。
- Channel操作:如在无缓冲Channel上进行发送或接收操作时,如果没有对应的接收者或发送者,Goroutine会被挂起。
- 同步原语
使用同步原语(如sync.Mutex、sync.WaitGroup、sync.Cond等)进行同步操作时,Goroutine可能会被挂起,直到条件满足。例如:
- 互斥锁(Mutex):当Goroutine尝试获取一个已经被其他Goroutine持有的互斥锁时,它会被挂起,直到锁被释放。
- 条件变量(Cond):当Goroutine等待条件变量时,它会被挂起,直到条件变量被通知。
- 调度器调度
Go运行时的调度器会根据需要挂起和恢复Goroutine,以实现高效的并发调度。调度器可能会在以下情况下挂起Goroutine:
- 时间片用完:Go调度器使用协作式调度,当一个Goroutine的时间片用完时,调度器会挂起该Goroutine,并调度其他Goroutine执行。
- 主动让出:Goroutine可以通过调用runtime.Gosched()主动让出CPU,调度器会挂起该Goroutine,并调度其他Goroutine执行。
- Goroutine的创建和销毁
- 创建:当一个新的Goroutine被创建时,它会被挂起,直到调度器将其调度执行。
- 销毁:当一个Goroutine执行完毕或被显式终止时,它会被挂起并从调度器中移除。
Goroutine的栈管理
Goroutine的栈空间是动态分配的,可以根据需要自动扩展。Go运行时使用分段栈(segmented stack)或连续栈(continuous stack)来管理Goroutine的栈空间:
- 分段栈:在早期版本的Go中,Goroutine使用分段栈。每个Goroutine的栈由多个小段组成,当栈空间不足时,Go运行时会分配新的栈段并链接到现有的栈段上。
- 连续栈:在Go 1.3及以后的版本中,Goroutine使用连续栈。每个Goroutine的栈是一个连续的内存块,当栈空间不足时,Go运行时会分配一个更大的栈,并将现有的栈内容复制到新的栈中。